
 商标分类
商标分类  商标转让
商标转让 
用于估计具有视觉标记的口腔卫生装置的三维姿势的系统和方法与流程
 2021-01-10 12:01:57|
2021-01-10 12:01:57| 216|
216| 起点商标网
起点商标网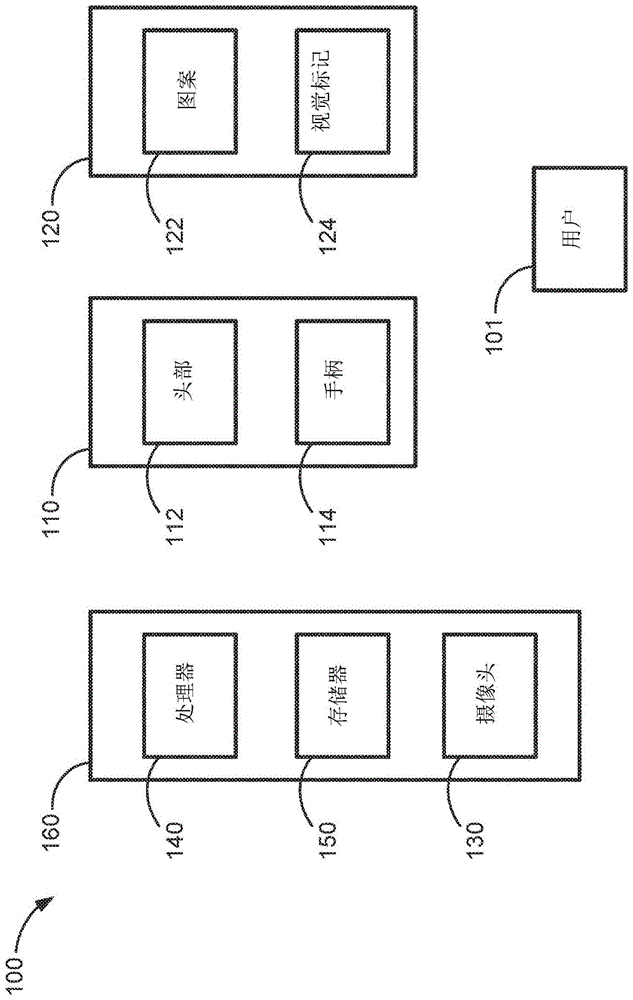
本公开大体上涉及运动跟踪,并且更具体地涉及用于估计口腔卫生装置相对于位置的姿势的系统和方法。
背景技术:
运动跟踪系统常常用于各种应用中,包括例如医疗领域、电影和电子游戏行业等中。仍然还需要新的系统和方法以使用具有有限处理能力的装置(例如,智能手机)来准确地跟踪对象在所有方向上的运动。本公开解决了这些和其他问题。
技术实现要素:
根据本公开的一些实施方式,一种用于估计口腔卫生装置相对于位置的姿势的方法,所述口腔卫生装置包括图案和多组视觉标记,所述方法包括接收可再现为所述口腔卫生装置的至少一部分的图像的图像数据。所述方法还包括:使用一个或多个处理器分析所述图像数据以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述图案的至少一部分;使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;以及获得所述口腔卫生装置的第一建议的三维姿势。所述方法还包括:验证所述口腔卫生装置的第一建议的三维姿势;以及基于经验证的第一建议的三维姿势获得所述口腔卫生装置的第二建议的三维姿势。
根据本公开的其他实施方式,一种用于估计口腔卫生装置相对于位置的姿势的方法,所述口腔卫生装置包括图案和多组视觉标记,所述方法包括:(a)接收可再现为所述口腔卫生装置的至少一部分的图像的图像数据;(b)使用一个或多个处理器分析所述图像数据以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述图案的至少一部分;(c)响应于识别所述感兴趣区域,使用所述一个或多个处理器中的至少一个处理器将所述感兴趣区域分割成多个子区域,所述多个子区域中的每一个子区域由具有共同颜色的多个像素限定;(d)使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;(e)创建所述候选视觉标记的多个不同集合;(f)选择所述候选视觉标记的多个不同集合中的第一集合;(g)选择与所述口腔卫生装置的三维模型相关联的模型标记的多个不同集合中的第一集合;(h)使用三点透视算法评估所述候选视觉标记的所选择集合和模型标记的所选择集合以获得所述口腔卫生装置的建议的三维姿势;(i)基于所述口腔卫生装置的建议的三维姿势,预测预定数量的候选视觉标记在所述感兴趣区域内的位置;(j)将所述预定数量的候选视觉标记的预测位置与所有候选视觉标记在所述感兴趣区域内的实际位置进行比较;(k)响应于确定所述预测位置的至少大部分与所述实际位置对应,验证所述建议的三维姿势;以及(1)响应于确定少于所述预测位置的大部分与所述实际位置对应,重复步骤(f)-(k)。
根据本公开的其他实施方式,一种运动跟踪系统,包括:口腔卫生装置、跟踪元件、摄像头、一个或多个处理器和存储器装置。所述口腔卫生装置包括头部和手柄。所述跟踪元件联接到所述口腔卫生装置,并包括图案和多组视觉标记。所述存储器装置存储指令,所述指令在由所述一个或多个处理器中的至少一个处理器执行时使得所述运动跟踪系统:使用所述摄像头捕获所述口腔卫生装置的至少一部分的图像;使用所述一个或多个处理器中的至少一个处理器分析所述图像以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述跟踪元件的图案的至少一部分;使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;创建所述候选视觉标记的多个不同集合;选择所述候选视觉标记的多个不同集合中的第一集合;选择与存储在所述存储器装置中的所述口腔卫生装置的三维模型相关联的模型标记的多个不同集合中的第一集合;使用三点透视算法评估所述候选视觉标记的所选择集合和模型标记的所选择集合,以获得所述口腔卫生装置的建议的三维姿势;基于所述口腔卫生装置的建议的三维姿势,预测预定数量的候选视觉标记在所述感兴趣区域内的位置;将所述预定数量的候选视觉标记的预测位置与所有候选视觉标记在所述感兴趣区域内的实际位置进行比较;以及响应于确定所述预测位置的至少大部分与所述实际位置对应,验证所述建议的三维姿势。
根据本公开的其他实施方式,一种运动跟踪元件,其被构造成联接到口腔卫生装置,所述运动跟踪元件包括:主体;图案,所述图案在所述主体的外表面上;以及在所述主体的外表面上的多组视觉标记。
本公开的以上发明内容并不意图表示本公开的每个实施例或每个方面。本公开的附加特征和益处从下文所阐述的详细描述和附图显而易见。
附图说明
图1是根据本公开的一些实施方式的运动跟踪系统的示意性图示;
图2a是根据本公开的一些实施方式的跟踪元件和口腔卫生装置的透视图;
图2b是图2a的跟踪元件的前视图;
图2c是图2a的跟踪元件的后视图;
图3是根据本公开的一些实施方式的用于估计口腔卫生装置相对于位置的姿势的方法的流程图;以及
图4是示出了获得第一建议的三维姿势的步骤和验证第一建议的三维姿势的步骤的流程图。
虽然本公开易于有各种修改和替代形式,但是在附图中以实例示出了具体实施例并在本文中对其进行详细描述。然而,应理解,本公开并不意图局限于所公开的特定形式。相反,本公开将涵盖落入本公开的精神和范围内的所有修改、等同物和替代方案。
具体实施方式
参考图1,运动跟踪系统100包括口腔卫生装置110、跟踪元件120、摄像头130、处理器140和存储器装置150。运动跟踪系统100通常用于估计口腔卫生装置110在三维空间中相对于例如摄像头130的位置的姿势。
口腔卫生装置110包括头部112和手柄114。头部112联接至手柄114的第一端,并且包括用于刷牙的多根刷毛。头部112和手柄114可以是整体的或单件式的,或者替代地,头部112可以可移除地联接到手柄114,使得手柄114(例如,与更换头部)可互换。手柄114具有大致圆柱形的形状,但更一般地可以是任何合适的尺寸和形状。手柄114可包括人体工程学抓握以帮助用户抓握手柄114。口腔卫生装置110可以包括电动机(未示出),以振动和/或振荡头部112或以其他方式向该头部提供运动以帮助刷牙。更一般地,口腔卫生装置110可以是任何手动牙刷或电动牙刷。
跟踪元件120可以(直接地或间接地)可拆卸地联接到、固定地或刚性地(直接地或间接地)联接到口腔卫生装置110的手柄114,或者与所述口腔卫生装置的手柄一体地形成。此外,跟踪元件120可以联接到口腔卫生装置110的手柄114,使得跟踪元件120的轴线与手柄114的轴线对应或与该手柄的轴线同轴。跟踪元件120包括图案122和多个视觉标记124。跟踪元件120通常由柔性材料制成。例如,跟踪元件120可以由非导电材料,诸如橡胶或弹性体材料、聚合物材料或其任何组合制成。
摄像头130是数码摄像头,其通常用来捕获口腔卫生装置110和跟踪元件120的至少一部分的静止图像、视频图像或两者。通常,口腔卫生装置110位于用户101与摄像头130之间,使得摄像头130的视场涵盖口腔卫生装置110的至少一部分和跟踪元件120的至少一部分。
处理器140通信地耦合到摄像头130和存储器装置150。处理器140执行存储在存储器装置150中的指令(例如,相关联的应用程序),以控制其通信地耦合到的系统100的各种部件。
在一些实施方式中,系统100还包括外壳160。在此类实施方式中,摄像头130、处理器140、存储器装置150或其任何组合可集成在外壳160中。例如,外壳160可以是智能手机。替代地,所述各种部件中的一些或全部可以彼此分离,并且一些可以包括在口腔卫生装置110的基站(未示出)中。
参考图2a-2c,与口腔卫生装置110相同或相似的口腔卫生装置210联接到跟踪元件220,该跟踪元件与上文描述的跟踪元件120相同或相似。
口腔卫生装置210包括头部(未示出)和手柄214。头部联接到手柄214的第一端,跟踪元件220联接到手柄214的与头部相对的第二端。
跟踪元件220包括上部部分222、下部部分226、图案230、第一组视觉标记241、第二组视觉标记242和第三组视觉标记243。上部部分222具有大体上圆柱形的构造并且包括腔224。腔224的尺寸和形状被设计成在其中接收口腔卫生装置210的手柄214,以使用压配合或干涉配合将跟踪元件220可移除地联接到手柄214。例如,上部部分222可由呈套筒形式的弹性体材料形成,并且被构造和布置成接收并贴合手柄214的第二端。可替代地,可以使用其他机构,例如,螺纹连接、粘合剂连接、钩环紧固件、突片和孔口系统、压配合或干涉配合连接、卡扣配合连接、力配合连接、扭锁连接等,或其任何组合将跟踪元件220联接到手柄214。替代性地,在一些实施方式中,跟踪元件220包括凸形附接特征并且手柄214的第二端可以包括与腔224相似的腔,其尺寸和形状被设计成在其中接收凸形附接特征的至少一部分。在此类实施方式中,跟踪元件220的凸形附接特征和手柄214的腔可以使用上述紧固机构中的任一个联接。有利地,在该构造中,如果用户在给定的刷牙过程期间不希望使用跟踪元件220,则可以从口腔卫生装置210移除跟踪元件220。此外,例如,当用户在使用寿命结束时更换口腔卫生装置210,或者在另一个用户希望在另一个口腔卫生装置上使用跟踪元件220时,跟踪元件220可以从口腔卫生装置210移除并联接到第二口腔卫生装置。替代性地,跟踪元件220和手柄214可以是整体的和/或单件式的。
如图2a-2c所示,跟踪元件220的下部部分226可以具有大体上球形构造,但是其他尺寸和形状是可能的。如图所示,图案230形成在其外表面上并且与下部部分226的外表面齐平,并且包括背景232和多个指示器234。
如图所示,多个指示器234中的每一个指示器具有大体上为圆形或椭圆形的无定形形状。图2a-2c中所示的多个指示器234的形状是优选的,因为这种形状使得在捕获口腔卫生装置210和跟踪元件220的图像时与他们的运动相关联的模糊降至最低。替代性地,多个指示器234中的一个或多个指示器可具有大致三角形形状、大致矩形形状、多边形形状或其任何组合。虽然多个指示器234中的每一个指示器示出为具有相同形状和大小,但多个指示器234中的每一个指示器可具有不同大小或基本上相同大小(例如,直径)。
多个指示器234中的每一个指示器具有第一颜色,背景232具有与第一颜色不同的第二颜色。在一个实例中,背景232是橙色,多个指示器234中的每一个指示器是黑色。替代性地,背景232可为黑色,多个指示器234中的每一个指示器可为大体上橙色,但背景232和多个指示器234的其它颜色是可能的(例如,红色、绿色、蓝色、黄色、橙色、紫色等)。一般来说,背景232与多个指示器234中的每一个指示器的颜色之间的高对比度是优选的,以便清楚地限定多个指示器234中的每一个指示器。在跟踪元件220上限定图案230的多个指示器234可具有在约十个指示器和约一百个指示器之间、在约二十个指示器和约六十个指示器之间、在约三十五个指示器和约四十五个指示器之间,或任何合适数目的指示器。
图案230的多个指示器234和背景232可使用多种机制形成。例如,图案230的多个指示器234中的至少一些和/或背景232可印刷或压印在跟踪元件220的外表面上。替代性地,多个指示器234中的至少一些和/或背景232可与下部部分226成一体。
参考图2a-2c,第一组视觉标记241、第二组视觉标记242和第三组视觉标记243联接到下部部分226的外表面且从其突出。如图所示,视觉标记241、242、243的组中的每个视觉标记具有大致卵形、穹顶状或半球形形状。第一组视觉标记241、第二组视觉标记242和第三组视觉标记243可使用例如粘合剂连接或更一般地任何其它合适的机制联接到下部部分226的外表面。替代性地,每个视觉标记可以与跟踪元件220的下部部分226是整体的和/或单件式的。
参考图2b和图2c,第一组视觉标记241包括第一视觉标记241a、第二视觉标记241b、第三视觉标记241c和第四视觉标记241d。手柄214具有前表面214a和后表面214b。头部(未示出)上的清洁元件(例如,刷毛)从手柄214的前表面214a延伸。为了图示所有视觉标记,图2b是口腔卫生装置210的前视图(即,包括前表面214a),图2c是口腔卫生装置210的后视图(即,包括后表面214b)。
在一些实施方式中,第一组视觉标记241沿着靠近上部部分222和手柄214的下部部分226的第一周向长度延伸。如图所示,第一组视觉标记241中的每一个视觉标记沿着第一周向长度彼此均匀地间隔开。
第二组视觉标记242包括第一视觉标记242a、第二视觉标记242b、第三视觉标记242c和第四视觉标记242d。第二组视觉标记242沿着与第一周向长度间隔开的下部部分226的第二周向长度延伸。如图所示,第二组视觉标记242中的每一个视觉标记沿着第一周向长度彼此均匀地间隔开,但从第一组视觉标记241中的视觉标记周向地偏移。具体地,第一视觉标记242a位于第一组视觉标记241的第一视觉标记241a与第二视觉标记241b之间(图2b),第二视觉标记242b位于第一组视觉标记241的第二视觉标记241b与第三视觉标记241c之间(图2b),第三视觉标记242c位于第一组视觉标记241的第三视觉标记241c与第四视觉标记241d之间(图2c),第四视觉标记242d位于第一组视觉标记241的第四视觉标记241d与第一视觉标记241a之间(图2d)。
第三组视觉标记243包括第一视觉标记243a、第二视觉标记243b、第三视觉标记243c和第四视觉标记243d。第三组视觉标记243沿着与第二周向长度间隔开并且远离上部部分222和手柄214的下部部分226的第三周向长度延伸。第一周向长度、第二周向长度和第三周向长度彼此均匀间隔开,使得第一组视觉标记241、第二组视觉标记242和第三组视觉标记243彼此均匀间隔开。
第三组视觉标记243包括第一视觉标记243a、第二视觉标记243b、第三视觉标记243c和第四视觉标记243d。第一视觉标记243a与第一组视觉标记241的第一视觉标记241a对齐,使得第一视觉标记243a位于第二组视觉标记242的第四视觉标记242d与第一视觉标记242a之间。第二视觉标记243b与第一组视觉标记241的第二视觉标记241b对齐,使得第二视觉标记243b位于第二组视觉标记242的第一视觉标记242a与第二视觉标记242b之间。第三视觉标记243c与第一组视觉标记241的第三视觉标记241c对齐,使得第三视觉标记243c位于第二组视觉标记242的第二视觉标记242b与第三视觉标记242c之间。第四视觉标记243d与第一组视觉标记241的第四视觉标记241d对齐,使得第四视觉标记243d位于第二组视觉标记242的第三视觉标记242c与第四视觉标记242d之间。
第一组视觉标记241、第二组视觉标记242和第三组视觉标记243中的每个视觉标记具有不同颜色。例如,在第一组视觉标记241中,第一视觉标记241a具有第一颜色,第二视觉标记241b具有第二颜色,第三视觉标记241c具有第三颜色,第四视觉标记241d具有第四颜色。第一颜色、第二颜色、第三颜色和第四颜色全部彼此不同。优选地,第一颜色、第二颜色、第三颜色和第四颜色是沿色谱分开的单独且不同的颜色。例如,每种颜色可以与其它颜色在色谱中间隔约150nm波长到15nm波长之间、在色谱中约100nm波长到在色谱中约25nm波长之间,或在色谱中约75nm波长到在色谱中约50nm波长之间等。例如,第一颜色、第二颜色、第三颜色和第四颜色可以是沿着色谱基本上均等地散开的蓝色、绿色、紫色、黄色、红色或橙色。
在一个实例中,参照第一组视觉标记241,第一视觉标记241a为紫色,第二视觉标记241b为蓝色,第三视觉标记241c为黄色,第四视觉标记241d为绿色。参照第二组视觉标记242,第一视觉标记242a为黄色,第二视觉标记242b为绿色,第三视觉标记241c为蓝色,第四视觉标记241d为紫色。参照第三组视觉标记243,第一视觉标记243a为绿色,第二视觉标记243b为紫色,第三视觉标记243c为蓝色,第四视觉标记243d为黄色。在此构造中,在各组视觉标记中四种颜色(蓝、绿、紫和黄)中的每一种颜色均匀分布并且彼此间隔开。例如,黄色视觉标记不与另一个黄色视觉标记直接相邻,并且蓝色视觉标记不与另一个蓝色视觉标记直接相邻。
在上述实例中,有三个紫色视觉标记、三个蓝色视觉标记、三个黄色视觉标记和三个绿色视觉标记(即,具有四种不同颜色的标记)。虽然第一组视觉标记241、第二组视觉标记242和第三组视觉标记243中的每一组示出为包括四个视觉标记,但更一般地讲,附件220可包括含有至少一个视觉标记的任何数量的视觉标记组。例如,附件220可包括第一组视觉标记、第二组视觉标记、第三组视觉标记和第四组视觉标记,每组含有至少一个视觉标记。另外,每组中的至少一个视觉标记具有与其他组中的视觉标记不同的颜色。另外,虽然附件220(图2a-2b)示出为包括在第一组241、第二组242和第三组243之间组合的十二个视觉标记,但是应理解,附件220可包括具有四种或更多种不同颜色(例如,四种不同颜色、六种不同颜色、十种不同颜色、二十种不同颜色等)的任何数量的视觉标记(例如,四个视觉标记、六个视觉标记、十个视觉标记、二十个视觉标记、五十个视觉标记等)。如本文将更详细地讨论的,具有四个或更多个具有不同颜色的视觉标记是优选的以准确地且有效地跟踪跟踪元件220的运动。此外,虽然第一组视觉标记241、第二组视觉标记242和第三组视觉标记243各自沿着下部部分226的周向长度定位并且彼此均匀地间隔开,但是视觉标记可以在下部部分226的外表面上以任何适当的布置(例如,随机地)相对于彼此定位。
参考图3,用于估计口腔卫生装置210相对于位置的姿势的方法300包括例如第一步骤310、第二步骤320、第三步骤330、第四步骤340、第五步骤350和第六步骤360。
第一步骤310包括从与上述摄像头130(图1)相同或类似的摄像头接收图像数据,该图像数据可再现为口腔卫生装置210的至少一部分和跟踪元件220的至少一部分的图像。例如,图像数据可以是由摄像头捕获的视频图像的一帧。如上所述,摄像头相对于用户(例如,用户101)定位,使得口腔卫生装置210和跟踪元件220定位在摄像头与用户之间。由于摄像头的视场涵盖口腔卫生装置210、跟踪元件220和用户的至少一部分,所以捕获的视频或静止图像包括所有这三者的至少一部分和摄像头的视场内的用户后面的背景。
第二步骤320包括分析来自第一步骤310的图像数据以识别图像内的感兴趣区域。通常,感兴趣区域是在第一步骤310期间接收的包括跟踪元件220的图像的区域。如上所述,在第一步骤310期间捕获的图像包括用户的至少一部分和用户后面的背景。通过将感兴趣区域限制在跟踪元件220周围的区域,可以减少方法300的后续步骤的处理要求。
为了分析图像数据并识别感兴趣区域,使用与上文描述的处理器140(图1)相同或类似的一个或多个处理器来使用多个滤波器识别跟踪元件220(图2a)的图案230。所述多个滤波器包括运动滤波器、滤色器和形状滤波器。运动滤波器检测或识别图像内的移动。通常,运动滤波器通过区分图像中的移动区域与图像的静止区域来检测移动。运动滤波器利用图案230可能由于口腔卫生装置210和跟踪元件220的相应移动而移动的事实,通过消除图像的静止背景来缩小可能是感兴趣区域(即,包含图案230的至少一部分)的图像的潜在区域。滤色器和形状滤波器识别背景232与多个指示器234之间的颜色对比以及多个指示器234中的每一个指示器的形状。已检测到包含图案230的图像区域后,感兴趣区域被定义为该区域并且不可包括图像的剩余部分。
识别高分辨率或高清晰度图像中的感兴趣区域需要大量处理/计算时间。为了降低识别感兴趣区域的处理要求,在第二步骤320期间分析的图像优选地是低分辨率图像。接着对于方法300的步骤的其余部分,可以将感兴趣区域扩大到较高分辨率图像。
在一些实施方式中,可以使用机器学习算法或人工智能算法过滤或检测跟踪元件220的图案230以识别感兴趣区域。机器学习算法可采用多种形式。例如,方法300可利用更基本的机器学习工具,诸如决策树(“dt”)或人工神经网络(“ann”)。dt程序由于其简单性和易于理解而被普遍使用。dt是将输入数据与在决策树中每个连续步骤询问的问题进行匹配的分类图。dt程序基于问题的回答向下移动树的“分支”。例如,第一分支可以询问图像的一部分是否正在移动。如果是,第二分支可以询问图像的该部分是否包括图案230。在其它实例中,可以使用深度学习算法或其它更复杂的机器学习算法,例如卷积神经网络。
机器学习算法(例如,haar级联)需要训练数据以识别被设计成检测的感兴趣特征。例如,可以利用各种方法来形成机器学习模型,包括为网络应用随机分配的初始权重,并且使用反向传播来应用梯度下降以用于深度学习算法。在其他实例中,在不使用这种技术进行训练时,可以使用具有一个或两个隐藏层的神经网络。在一些实例中,将使用被标记的数据或表示特定特征、特定动作或特性(包括特定颜色或特定形状)的数据,训练机器学习算法。
第三步骤330包括识别在第二步骤320期间识别的感兴趣区域中的候选视觉标记。通常,候选视觉标记是感兴趣区域的子区域,其可以是在跟踪元件220上的实际视觉标记(例如,图2a-2c中的各组视觉标记241、242或243中的一个视觉标记)。为了识别候选视觉标记,使用颜色分割算法将感兴趣区域分割成多个子区域。每个子区域由具有共同颜色的感兴趣区域的多个像素限定。
通常,颜色分割算法假设对象被不同地着色,并且试图识别图像中的相邻像素之间的总色差。颜色分割算法使用l*a*b颜色空间,其根据光度(“l”)限定颜色,其中颜色落在红-绿轴(“*a”)上,并且其中颜色落在蓝-黄轴(“*b”)上。因此,如果需要,在第二步骤320中识别的感兴趣区域从rgb颜色空间转换为l*a*b颜色空间以执行颜色分割算法。使用阈值,颜色分割算法将具有不同颜色的相邻像素彼此分离以形成多个子区域。然后计算多个子区域中的每一个子区域的l*a*b颜色空间中的平均颜色。
如上文所论述,第一组241、第二组242和第三组243中的视觉标记的颜色优选为蓝色、绿色、紫色、黄色、红色或橙色中的一种。因此,具有蓝、绿、紫或黄颜色的感兴趣区域的子区域可以是候选视觉标记。虽然感兴趣区域限于包围跟踪元件220的区域,但感兴趣区域仍可包括用户的一部分或用户后面的背景,这可能对于候选视觉标记产生假阳性。例如,用户可能正穿着具有与视觉标记相同或相似颜色中的一种或多种颜色的衣服。
为了提高识别候选视觉标记的准确性,第三步骤330还包括形状滤波器和尺寸滤波器。第一组视觉标记241、第二组视觉标记242和第三组视觉标记243(图2a-2c)的视觉标记具有大致穹顶状或半球形形状。当在诸如感兴趣区域的二维图像中观察时,这些视觉标记具有大致圆形形状。形状滤波器和尺寸滤波器用于检测感兴趣区域中的大致圆形形状的视觉标记。这些滤波器帮助区分视觉标记与例如用户的衣服。
第四步骤340包括获得口腔卫生装置210的第一建议的三维姿势。一般来讲,第一建议的三维姿势包括口腔卫生装置210相对于摄像头的位置和取向(旋转和平移)。如将在本文中更详细地论述的,在一些实施方式中,在第三步骤330期间识别出至少四个候选视觉标记之前,第四步骤340将不会初始化。如果在第三步骤330期间识别出少于四个候选视觉标记,则重复方法300直到识别出至少四个候选视觉标记。
参考图4,第四步骤340包括第一子步骤342、第二子步骤348、第三子步骤348和第四子步骤348。
第一子步骤342包括将在第三步骤330(图3)期间识别出的候选视觉标记分组成候选视觉标记的离散集合。优选地,候选视觉标记的离散集合中的每一个集合包括四个候选视觉标记。
类似地,第二子步骤348包括将来自口腔卫生装置210和跟踪元件220的三维模型的模型标记分组成离散步骤。三维模型存储在存储器装置中,所述存储器装置与上文所描述的存储器装置150相同或类似(图1)。三维模型是实际口腔卫生装置210和跟踪元件220的表示。具体地,三维模型包括第一组视觉标记241、第二组视觉标记242和第三组视觉标记243的表示。在模型标记的离散集合中的每个集合中的模型标记的数量等于在第一步骤342期间分组在一起的候选视觉标记的第一离散集合中的候选视觉标记的数量(例如,四个候选视觉标记和四个模型标记)。
第三子步骤348包括选择候选视觉标记的第一离散集合和模型标记的第一离散集合。候选视觉标记的第一离散集合包括四个视觉标记,并且模型标记的第一离散集合包括四个模型标记。
第四子步骤348包括将候选视觉标记的第一离散集合和在第三子步骤348期间选择的模型标记的第一离散集合输入到三点透视(“p3p”)算法中。p3p算法基于余弦定律并且用于估计相对于摄像头放置的对象姿势(旋转和平移)。
通常,p3p算法将从图像获得的二维点与从三维模型获得的三维点进行比较。为了求解p3p方程组,提供了在图像坐标系中限定的四个二维点和在三维模型坐标系中限定的四个三维点。点的三个集合(每个集合包括二维点和三维点)用于求解p3p方程组,并且确定二维点与摄像头的光学中心之间的距离的最多四个可能集合。距离的这四个集合被转换成四个姿势配置。然后,2d/3d点的第四集合用于针对四种建议选择最佳或最正确的姿势配置。用于求解p3p方程组并获得估计的三维姿势的方法有很多种。例如,laurentkneip等人于2011年7月在ieeeconferenceoncomputervisionandpatternrecognition(cvpr)上发表的文章“anovelparametrizationoftheperspective-three-pointproblemforadirectcomputationofabsolutecamerapositionandorientation”解释了一种此类方法,该文章在此以全文引用的方式并入本文中。
将候选视觉标记的第一离散集合和模型标记的第一离散集合输入到p3p算法中并且求解方程组得到口腔卫生装置210的第一建议的三维姿势。第一建议的三维姿势包括口腔卫生装置210的旋转位置和平移位置,其准许确定口腔卫生装置210相对于摄像头的位置。如上文所论述,在一些实施方式中,在第三步骤330期间识别出四个候选视觉标记之前,第四步骤340将不会初始化。这是因为求解p3p算法需要四个候选视觉标记和四个模型标记。如果在第三步骤330中识别出少于四个候选视觉标记,则如果没有更多数据通常就无法求解p3p算法方程组。
第五步骤350(图3)包括验证在第四步骤340期间确定的口腔卫生装置210的第一建议的三维姿势。在子步骤348中选择的候选视觉标记的第一离散集合和模型标记的第一离散集合可能得到不正确的建议的三维姿势(例如,物理上不可能的姿势)。因此,第五步骤350通常用于验证或拒绝在第四步骤340期间获得的建议的三维姿势。
参考图4,第五步骤350包括第一子步骤352、第二子步骤354、第三子步骤356和第四子步骤358。第一子步骤352包括预测候选视觉标记在感兴趣区域内的位置。基于在第四步骤340期间计算出的第一建议的三维姿势以及来自口腔卫生装置210和跟踪元件220的三维模型的视觉标记的已知位置,可以预测视觉标记在感兴趣区域内的位置。换句话说,所预测的位置指示如果第一建议的三维姿势正确,候选视觉标记应位于感兴趣区域中的位置,以及候选视觉标记不应位于感兴趣区域中的位置。例如,可以预测,如果口腔卫生装置210与第一建议的三维姿势具有相同姿势,则在感兴趣区域中将有六个视觉标记是可见的。从口腔卫生装置的三维模型确定这六个视觉标记在感兴趣区域中相对于彼此的位置。
第二子步骤354包括将在感兴趣区域中识别出的候选视觉标记与视觉标记的预测位置进行比较。更具体地,将候选视觉标记的数量和位置与视觉标记的预测数量和预测位置进行比较(第五步骤350的第一子步骤354)。如果确定预定数量的候选视觉标记的位置对应于预测位置,则第一建议的三维姿势被验证(子步骤356)。如果少于预定数量的候选标记对应于预测位置,则第一建议的三维姿势被拒绝(子步骤358)。
为了举例说明,第一子步骤352预测六个候选视觉标记在感兴趣区域中将是可见的,并且预测这六个候选视觉标记中的每一个相对于彼此的位置。第三步骤330识别出感兴趣区域内的十个候选视觉标记。例如,如果候选视觉标记对应于这六个预测的视觉标记中的五个,则第一建议的三维姿势被验证(子步骤356)且第五步骤350完成。其他四个候选视觉标记仅被视为噪声或不准确的。替代性地,如果在第三步骤330期间识别出三十个候选视觉标记,且例如三十个中的二十五个与预测位置不对应,那么可拒绝所建议的三维姿势。
验证建议的三维姿势所需的预定数量的对应性可以表示为百分比,并且可以是视觉标记的预测位置的至少约50%对应于候选视觉标记的位置,视觉标记的预测位置的至少约60%对应于候选视觉标记的位置,视觉标记的预测位置的至少约70%对应于候选视觉标记的位置,视觉标记的预测位置的至少约80%对应于候选视觉标记的位置,视觉标记的预测位置的至少约90%对应于候选视觉标记的位置,或视觉标记的预测位置的100%对应于候选视觉标记的位置。在一些实施方式中,预定数量是统计上的有效数字,使得可以适当的统计确定性确定第一建议的三维姿势是正确的(例如,95%统计确定性、85%统计确定性、75%统计确定性等)。
如果第一建议的三维姿势被拒绝(子步骤358),则重复第四步骤340的第二子步骤348(图4)。在重复子步骤348期间,选择候选视觉标记的第二离散集合和模型标记的第二离散集合。候选视觉标记的第二离散集合和模型标记的第二离散集合中的至少一者包括候选视觉标记或模型标记的一个集合,其与候选视觉标记的第一离散集合和/或模型标记的第二离散集合不同。然后在子步骤348中将这些集合输入到p3p算法中,以获得口腔卫生装置210的第二建议的三维姿势。接着在第五步骤350期间验证或拒绝第二建议的三维姿势。重复步骤348到354,直到验证建议的三维姿势(子步骤356)。
在重复上述步骤以验证建议的三维姿势期间,可以将候选视觉标记和模型标记的许多离散集合输入到p3p算法中,直到验证建议的姿势为止。因为在图2a-2c中所示的实例中,第一组视觉标记241、第二组视觉标记242和第三组视觉标记243(图2a-2c)之间总共存在十二个视觉标记,所以如果忽视视觉标记的颜色,则存在四个视觉标记的469种可能的组合。换句话说,存在四个模型标记的469种可能的离散集合。例如,如果在感兴趣区域中识别出十六个候选视觉标记(在步骤330期间),忽视颜色的话,则存在四个候选视觉标记的1,820种组合(即,候选视觉标记的1,820种可能的离散集合)。这意味着在一个建议的三维姿势被验证之前,可能存在可确定的超过900,000个建议的三维姿势,从而需要大量的处理/计算时间。然而,如上文所述,第一组视觉标记241、第二组视觉标记242和第三组视觉标记243中的每一组包括四个视觉标记,并且每组中的四个视觉标记中的每一个具有不同颜色。然后可进一步调节候选视觉标记和模型标记的分组,使得每个组不仅限于四个视觉标记,而且四个组中的每个视觉标记具有不同颜色。以此方式,可能需要在验证建议的三维姿势(子步骤356)之前输入到p3p算法(子步骤348)中的可能组合的数量从例如几十万个减少到几百个。这降低了处理/计算要求,使得可以在例如具有有限处理能力的智能手机上实施该方法。
第六步骤360包括基于口腔卫生装置210的经验证的第一建议的三维姿势获得口腔卫生装置210的第二建议的三维姿势。以与在第五步骤350期间计算第一建议的三维姿势类似的方式计算口腔卫生装置210的第二建议的三维姿势。如上文所论述,在第五步骤350的第一子步骤352期间,预测感兴趣区域中的每个视觉标记的位置。还如上文所论述,由于来自背景的噪声或颜色分割算法中涉及的不准确性,在第三步骤330期间识别的候选视觉标记的数量可能比预测的视觉标记的量更大。为了获得更加精确的姿势估计,第六步骤360仅选择与预测的视觉标记对应的候选视觉标记(“正确候选视觉标记”),而忽略基于预测位置不正确的候选视觉标记。然后,使用迭代姿势估计算法和线性回归,将这些正确的候选视觉标记与口腔卫生装置210的三维模型的模型标记进行比较,以获得口腔卫生装置210的第二建议的三维姿势。口腔卫生装置210的第二建议的三维姿势通常比第一建议的三维姿势(第四步骤340)更准确,但需要更多的处理/计算时间来确定。
参考图3,在完成第六步骤360之后,方法300可以重复一次或多次。在方法300的第二次迭代中,第一步骤310重复并且包括接收可再现为口腔卫生装置210和跟踪元件220的至少一部分的第二图像的图像数据。例如,第二图像可以是在方法300的初始迭代期间使用的图像之后拍摄的视频图像的第二帧。
接着重复第二步骤320以识别在第一步骤310期间接收的第二图像中的第二感兴趣区域。然而,在方法300的第二次迭代中,绕过检测跟踪元件220的图案230以识别感兴趣区域这一操作。而是,使用第二三维姿势估计(第六步骤360)选择第二感兴趣区域,并且第二感兴趣区域被定义为跟踪元件220的至少一部分所位于的第二图像的区域。因为方法300的第二次迭代中的第二步骤320不需要使用多个滤波器检测图案230,所以完成第二步骤320所需的处理/计算时间减少。
然后使用上述颜色分割算法重复第三步骤330以识别第二感兴趣区域中的所有候选视觉标记。通常,口腔卫生装置210将在浴室中使用,该浴室可具有明亮或强烈的照明,该照明可以通过浴室镜子中的反射进一步放大。此外,口腔卫生装置210的移动可能使感兴趣区域中的照明条件基于口腔卫生装置相对于光源的位置而改变(例如,在特定姿势用户可以在口腔卫生装置210的一部分上投射阴影)。口腔卫生装置210的照明条件和/或移动可能影响从跟踪元件220的视觉标记反射的光的量。例如,可能难以在强烈或明亮的照明条件或黑暗的照明条件下辨别蓝色与紫色。通过使用在第六步骤360期间获得的第二三维姿势估计,可以基于在方法300的第一次迭代的第六步骤360中获得的三维姿势估计来调整颜色分割算法中区分颜色的阈值。随后,在重复方法300时,每次完成第三步骤330时就更新此阈值。
然后以与上述相同或相似的方式重复第四步骤340、第五步骤350和第六步骤360,以获得口腔卫生装置210的另一第二三维姿势估计。
然后,可以在上述第二次迭代之后重复步骤310至360多次(例如,十次、五十次、一百次、一千次等),以跟踪口腔卫生装置210的运动。第六步骤360将在重复方法300时输出口腔卫生装置210的一系列估计的三维姿势,其随后可以用于跟踪口腔卫生装置210随时间推移的移动。方法300的这种重复可用于跟踪口腔卫生装置210在例如用户正在刷牙的刷牙过程期间的运动。可以基于运动数据来收集和分析与用户刷牙质量或用户的牙齿的总体牙科健康状况相关的数据。例如,可确定刷子行程类型(例如,侧对侧行程、角行程或圆行程)。
在一些实施方式中,系统100还可用于确定用户面部的位置和取向。例如,使用摄像头104,系统100接收用户面部的至少一部分的图像。使用处理器140和存储器150以及面部识别算法,可确定面部的位置和取向。例如,系统100可以使用例如多个滤波器、机器学习算法等来确定用户的眼睛、嘴或鼻子(或其任何组合)的位置。在一个实例中,可基于用户的眼睛的位置以及用户的眼睛与嘴之间的距离来估计用户的嘴的位置。
通过确定用户面部的位置和取向,口腔卫生装置210的位置不仅可以相对于摄像头还可以相对于用户的嘴来确定。因此,口腔卫生装置相对于用户的牙齿的位置因此被确定,并且可以确定用户是否已经刷了牙齿的某个部分。
在一些实施方式中,方法300还包括初始校准步骤以确定跟踪元件220相对于口腔卫生装置210的旋转位置。例如,使用上述技术,校准步骤可以最初确定跟踪元件220在口腔卫生装置210上的旋转位置,并且传送该位置以调节三维模型,使得跟踪元件220在三维模型中的旋转位置与在实际口腔卫生装置210上的旋转位置对应。在其他实施方式中,方法300不知道跟踪元件220联接到口腔卫生装置210的手柄214的方式。
有利地,跟踪元件220可以用于使用方法300(或其他类似方法)跟踪口腔卫生装置210的运动,而不需要跟踪元件220中的任何电子器件或传感器(例如,加速度计)。虽然在一些实施方式中跟踪元件220可以包括这样的传感器,以帮助跟踪口腔卫生装置210的运动,但是这样的传感器可以例如增加跟踪元件220的成本,要求跟踪元件220在使用之前定期充电,或者增加跟踪元件220的重量并且因此假如在口腔卫生装置210的端部增加重量时干扰用户的(例如,儿童的)刷牙。
虽然系统100和方法300已经在本文中被示出并且描述为用于跟踪口腔卫生装置(例如,口腔卫生装置210)的运动,但是系统100和方法300可以用来跟踪联接到跟踪元件220的任何其他物体的运动。例如,与跟踪元件220相同或相似的跟踪元件可以联接到具有与口腔卫生装置210相似的形状的物体(诸如,棒球拍、曲棍球棒、高尔夫球棒等)的端部。此外,类似于跟踪元件220的跟踪元件可更一般地附接到具有任何其他形状的对象以跟踪该对象的运动。
虽然本公开易于有各种修改和替代形式,但是具体实施例及其方法已在附图中通过实例示出并在本文中详细描述。然而,应理解,其并不意图将本公开限于所公开的特定形式或方法,而是相反地,意图是涵盖落入本公开的精神和范围内的所有修改、等同物和替代方案。
所选实施例
尽管以上描述和所附的权利要求书公开了多个实施例,但在以下另外的实施例中公开了本公开的其他替代方面。
实施例1.一种用于估计口腔卫生装置相对于位置的姿势的方法,所述口腔卫生装置包括图案和多组视觉标记,所述方法包括:接收可再现为所述口腔卫生装置的至少一部分的图像的图像数据;使用一个或多个处理器分析所述图像数据以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述图案的至少一部分;使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;获得所述口腔卫生装置的第一建议的三维姿势;验证所述口腔卫生装置的第一建议的三维姿势;以及基于经验证的第一建议的三维姿势获得所述口腔卫生装置的第二建议的三维姿势。
实施例2.根据实施例1所述的方法,其中响应于识别所述感兴趣区域,使用所述一个或多个处理器中的至少一个处理器将所述感兴趣区域分割成多个子区域,所述多个子区域中的每一个子区域由具有共同颜色的多个像素限定。
实施例3.根据实施例1和2实施例中任一项所述的方法,其中获得所述口腔卫生装置的第一建议的三维姿势包括:创建所述候选视觉标记的多个不同集合;选择所述候选视觉标记的多个不同集合中的第一集合;选择与所述口腔卫生装置的三维模型相关联的模型标记的多个不同集合中的第一集合;以及使用三点透视算法从与所述口腔卫生装置相关联的三维模型评估所述候选视觉标记的集合和模型标记的集合以获得所述口腔卫生装置的所述建议的三维姿势。
实施例4.根据实施例1-3中任一项所述的方法,其中验证所述第一建议的三维姿势包括:基于所述口腔卫生装置的建议的三维姿势,预测预定数量的候选视觉标记在所述感兴趣区域内的位置;以及将所述预定数量的候选视觉标记的预测位置与所述感兴趣区域内的所有候选视觉标记的实际位置进行比较;以及确定所述预测位置的至少大部分与所述实际位置对应。
实施例5.根据实施例1-4中任一项所述的方法,其中分析所述第一图像数据包括使用一个或多个滤波器,所述一个或多个滤波器包括运动滤波器、滤色器、形状滤波器或其任何组合。
实施例6.根据实施例1-5中任一项所述的方法,其中识别所有候选视觉标记是基于所述多个子区域中的每一个子区域的形状和颜色。
实施例7.根据实施例1-6中任一项所述的方法,其中所述候选视觉标记的多个不同集合中的每一个集合包括至少四个候选视觉标记,并且所述模型标记的多个不同集合中的每一个集合包括至少四个模型标记。
实施例8.根据实施例1-7中任一项所述的方法,还包括:接收可再现为所述口腔卫生装置的至少一部分的第二图像的图像数据的第二集合;基于所述口腔卫生装置的经验证的三维姿势识别所述第二图像内的第二感兴趣区域。
实施例9.根据实施例1-8中任一项所述的方法,还包括:基于所述口腔卫生装置的所述经验证的三维姿势调整用于分割所述第二感兴趣区域的阈值,以帮助识别所述第二感兴趣区域中具有不同颜色的像素。
实施例10.一种用于估计口腔卫生装置相对于位置的姿势的方法,所述口腔卫生装置包括图案和多组视觉标记,所述方法包括:(a)接收可再现为所述口腔卫生装置的至少一部分的图像的图像数据;(b)使用一个或多个处理器分析所述图像数据以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述图案的至少一部分;(c)响应于识别所述感兴趣区域,使用所述一个或多个处理器中的至少一个处理器将所述感兴趣区域分割成多个子区域,所述多个子区域中的每一个子区域由具有共同颜色的多个像素限定;(d)使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;(e)创建所述候选视觉标记的多个不同集合;(f)选择所述候选视觉标记的多个不同集合中的第一集合;(g)选择与所述口腔卫生装置的三维模型相关联的模型标记的多个不同集合中的第一集合;(h)使用三点透视算法评估所述候选视觉标记的所选择集合和模型标记的所选择集合以获得所述口腔卫生装置的建议的三维姿势;(i)基于所述口腔卫生装置的所述建议的三维姿势,预测预定数量的候选视觉标记在所述感兴趣区域内的位置;(j)将所述预定数量的候选视觉标记的预测位置与所有候选视觉标记在所述感兴趣区域内的实际位置进行比较;(k)响应于确定所述预测位置的至少大部分与所述实际位置对应,验证所述建议的三维姿势;以及(1)响应于确定少于所述预测位置的所述大部分与所述实际位置对应,重复步骤(f)-(k)。
实施例11.根据实施例10中任一项所述的方法,还包括响应于所述建议的三维姿势被验证,使用算法比较所有候选视觉标记和所有模型标记以获得所述口腔卫生装置的第二建议的三维姿势。
实施例12.根据实施例10和实施例11中任一项所述的方法,其中分析所述第一图像数据包括使用一个或多个滤波器,所述一个或多个滤波器包括运动滤波器、滤色器、形状滤波器或其任何组合。
实施例13.根据实施例10-12中任一项所述的方法,其中识别所有候选视觉标记是基于所述多个子区域中的每一个子区域的形状和颜色。
实施例14.根据实施例10-13中任一项所述的方法,其中所述候选视觉标记的多个不同集合中的每一个集合包括至少四个候选视觉标记,并且所述模型标记的多个不同集合中的每一个集合包括至少四个模型标记。
实施例15.根据实施例10-14中任一项所述的方法,还包括:接收可再现为所述口腔卫生装置的至少一部分的第二图像的图像数据的第二集合;基于所述口腔卫生装置的经验证的三维姿势识别所述第二图像内的第二感兴趣区域。
实施例16.根据实施例15中任一项所述的方法,还包括:基于所述口腔卫生装置的所述经验证的三维姿势调整用于分割所述第二感兴趣区域的阈值,以帮助识别所述第二感兴趣区域中具有不同颜色的像素。
实施例17.一种运动跟踪系统,包括:口腔卫生装置,所述口腔卫生装置包括头部和手柄;联接到所述口腔卫生装置的跟踪元件,所述跟踪元件包括图案和多组视觉标记;摄像头;一个或多个处理器;以及存储指令的存储器装置,所述指令在由所述一个或多个处理器中的至少一个处理器执行时使得所述运动跟踪系统:使用所述摄像头捕获所述口腔卫生装置的至少一部分的图像;使用所述一个或多个处理器中的至少一个处理器分析所述图像以识别所述图像内的感兴趣区域,所述感兴趣区域中包括所述跟踪元件的图案的至少一部分;使用所述一个或多个处理器中的至少一个处理器识别所述感兴趣区域内的所有候选视觉标记;创建所述候选视觉标记的多个不同集合;选择所述候选视觉标记的多个不同集合中的第一集合;选择与存储在所述存储器装置中的所述口腔卫生装置的三维模型相关联的模型标记的多个不同集合中的第一集合;使用三点透视算法评估所述候选视觉标记的所选择集合和模型标记的所选择集合,以获得所述口腔卫生装置的建议的三维姿势;基于所述口腔卫生装置的建议的三维姿势,预测预定数量的候选视觉标记在所述感兴趣区域内的位置;将所述预定数量的候选视觉标记的所述预测位置与所有候选视觉标记在所述感兴趣区域内的实际位置进行比较;以及响应于确定所述预测位置的至少大部分与所述实际位置对应,验证所述建议的三维姿势。
实施例18.根据实施例17中任一项所述的系统,其中所述跟踪元件包括腔,以用于在所述腔中接收所述口腔卫生装置的手柄的一部分。
实施例19.根据实施例17和实施例18中任一项所述的系统,其中所述跟踪元件的图案与所述跟踪元件的外表面齐平,并且所述多组视觉标记从所述跟踪元件的外表面突出。
实施例20.根据实施例19中任一项所述的系统,其中所述多组视觉标记中的每一组的视觉标记具有大致穹顶状形状。
实施例21.根据实施例17-20中任一项所述的系统,其中所述跟踪元件的图案包括具有第一颜色的背景和覆盖在所述背景上的多个指示器,所述多个指示器具有与所述第一颜色不同的第二颜色。
实施例22.根据实施例17-21中任一项所述的系统,其中所述多组视觉标记中的第一组包括具有第一颜色的第一视觉标记、具有第二颜色的第二视觉标记、具有第三颜色的第三视觉标记和具有第四颜色的第四视觉标记。
实施例23.根据实施例17-22中任一项所述的系统,其中所述多组视觉标记中的第一组包括具有第一颜色的第一视觉标记、具有所述第一颜色的第二视觉标记、具有所述第一颜色的第三视觉标记和具有所述第一颜色的第四视觉标记。
实施例24.根据实施例17-23中任一项所述的系统,还包括移动装置,所述移动装置包括外壳,其中,所述摄像头、所述一个或多个处理器、所述存储器装置或其任何组合至少部分地设置在所述移动装置的外壳内。
实施例25.一种运动跟踪元件,其被构造成联接到口腔卫生装置,所述运动跟踪元件包括:主体;在所述主体的外表面上的图案;以及在所述主体的外表面上的多组视觉标记。
实施例26.根据实施例25所述的运动跟踪元件,其中所述主体包括第一部分和第二部分。
实施例27.根据实施例25和实施例26中任一项所述的运动跟踪元件,其中所述主体的第一部分被构造成联接到所述口腔卫生装置。
实施例28.根据实施例25-27中任一项所述的运动跟踪元件,其中所述主体的第二部分具有大致球形形状。
实施例29.根据实施例25-28中任一项所述的运动跟踪元件,其中所述多组视觉标记从所述主体的外表面突出。
实施例30.根据实施例25-29中任一项所述的运动跟踪元件,其中所述图案印刷在所述主体的外表面上。
实施例31.根据实施例25-30中任一项所述的运动跟踪元件,其中印刷的图案包括多个指示器和背景。
实施例32.根据实施例25-31中任一项所述的运动跟踪元件,其中所述背景具有第一颜色并且所述多个指示器具有与所述第一颜色不同的第二颜色。
实施例33.根据实施例25-32中任一项所述的运动跟踪元件,其中所述多组视觉标记包括至少第一组视觉标记、第二组视觉标记、第三组视觉标记和第四组视觉标记,所述第一组视觉标记中的一个或多个视觉标记具有第一颜色,所述第二组视觉标记中的一个或多个视觉标记具有第二颜色,所述第三组视觉标记中的一个或多个视觉标记具有第三颜色,并且所述第四组视觉标记中的一个或多个视觉标记具有第四颜色。
实施例34.根据实施例25-33中任一项所述的运动跟踪元件,其中所述第一颜色、所述第二颜色、所述第三颜色和所述第四颜色是彼此不同且有差别的。
实施例35.根据实施例25-34中任一项所述的运动跟踪元件,其中所述第一颜色、所述第二颜色、所述第三颜色和第四颜色中的每一者是蓝色、绿色、紫色、黄色、红色、橙色或其任何组合。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



