
 商标分类
商标分类  商标转让
商标转让 
一种大数据分析语音识别方法与流程
 2021-01-28 16:01:32|
2021-01-28 16:01:32| 385|
385| 起点商标网
起点商标网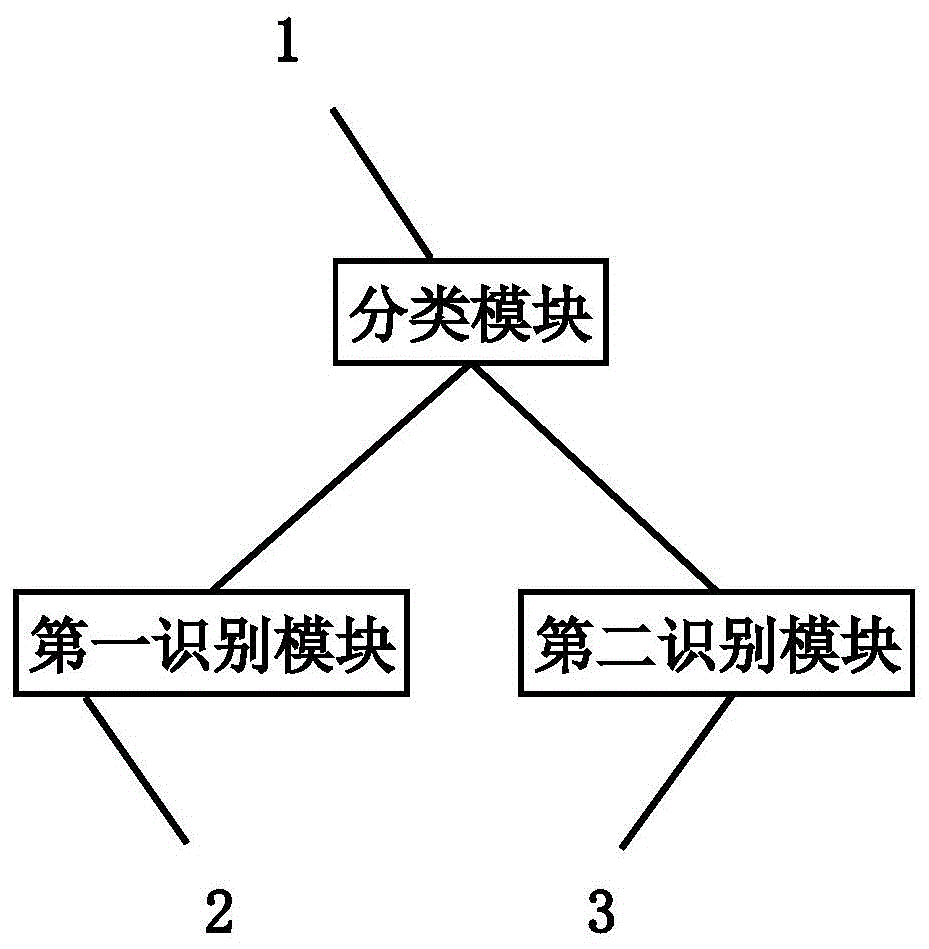
本发明涉及语音识别技术领域,尤其是一种大数据分析语音识别方法。
背景技术:
随着智能机器人技术的发展,通过语音直接控制机器人行为这一便捷的控制方式逐步普及开来。不过,由于现有语音识别技术的限制,机器人对于语音控制指令的识别速度和识别率均不高,这就导致语音控制只能作为一种辅助控制手段存在,限制了语音控制机器人的应用。
技术实现要素:
本发明要解决的技术问题是提供一种大数据分析语音识别方法,能够解决现有技术的不足,提高语音识别的速度和准确度。
为解决上述技术问题,本发明所采取的技术方案如下。
一种大数据分析语音识别方法,包括以下步骤:
a、采集待识别的语音信号后,将待识别的语音信号发送至分类模块,分类模块将待识别的语音信号分为简单词汇信号和复杂词汇信号,简单词汇信号发送至第一识别模块,复杂词汇信号发送至第二识别模块;
b、第一识别模块将简单词汇信号与数据库中的数据进行对比,得到与简单词汇信号相似度高于设定阈值的初筛数据集,将初筛数据集发送至第二识别模块;
c、第二识别模块根据初筛数据集确定识别参数,第二识别模块对复杂词汇信号进行识别后,在初筛数据集中选择与复杂词汇信号识别结果相关性最大的数据,与复杂词汇信号识别结果组成最终的识别结果。
作为优选,步骤a中,分类模块对待识别的语音信号进行傅里叶变换,在变换得到的信号频谱中检索特征频谱段,若同一时间段内存在至少两个特征频谱,则将这一时间段的语音信号定义为简单词汇信号,遍历整个待识别的语音信号后,将未定义为简单词汇信号的部分定义为复杂词汇信号。
作为优选,步骤b中,使用简单词汇信号对应的特征频谱在数据库中进行比对,对每个特征频谱设置对应的一级权重值,对同一简单词汇信号内不同的特征频谱设置统一的二级权重值,在计算相似度时首先使用一级权重值对相似度进行加权计算,然后对计算结果再通过二级权重值进行二次加权计算。
作为优选,步骤c中,第二识别模块建立神经网络模型,使用在数据库中与初筛数据集关联性大于设定阈值的数据对神经网络模型进行训练,确定模型参数;将复杂词汇信号输入神经网络模型进行计算,得到预测结果集;建立每个预测结果与其时间维度上相邻数据的关联映射,对预测结果进行调整,使关联映射全部收敛,调整后的预测结果集为复杂词汇信号识别结果。
作为优选,复杂词汇信号输入神经网络模型前,提取复杂词汇信号的非线性特征和线性特征,使用线性特征的组合代替非线性特征。
作为优选,在非线性特征两端设置接口部,接口部具有非线性特征的特征点集合。
采用上述技术方案所带来的有益效果在于:本发明利用特征频谱对语音信号进行快速分类,实现对于简单词汇信号的快速比对识别,然后,开创性的对特征频谱赋予两级权重,实现对相似度计算时的多维度加权。对于复杂词汇信号,采用神经网络模型对其进行预测。为了提高预测准确度,本发明专门使用数据库中于与初筛数据集具有高关联性的数据对神经网络进行训练。对于预测结果建立其收敛的关联映射,利用预测结果之间语义之间的内在关联对预测结果进行修正,从而进一步提高预测结果的准确性。此外,为了简化神经网络的运算量,在对复杂词汇信号进行计算前,通过对其进行非线性特征进行替代,以减少非线性特征对于神经网络运算过程带来的额外的训练量。
附图说明
图1是本发明一个具体实施方式的结构图。
图中:1、分类模块;2、第一识别模块;3、第二识别模块。
具体实施方式
参照图1,本发明一个具体实施方式包括以下步骤:
a、采集待识别的语音信号后,将待识别的语音信号发送至分类模块1,分类模块1将待识别的语音信号分为简单词汇信号和复杂词汇信号,简单词汇信号发送至第一识别模块2,复杂词汇信号发送至第二识别模块3;
b、第一识别模块2将简单词汇信号与数据库中的数据进行对比,得到与简单词汇信号相似度高于设定阈值的初筛数据集,将初筛数据集发送至第二识别模块3;
c、第二识别模块3根据初筛数据集确定识别参数,第二识别模块3对复杂词汇信号进行识别后,在初筛数据集中选择与复杂词汇信号识别结果相关性最大的数据,与复杂词汇信号识别结果组成最终的识别结果。
步骤a中,分类模块1对待识别的语音信号进行傅里叶变换,在变换得到的信号频谱中检索特征频谱段,若同一时间段内存在至少两个特征频谱,则将这一时间段的语音信号定义为简单词汇信号,遍历整个待识别的语音信号后,将未定义为简单词汇信号的部分定义为复杂词汇信号。
步骤b中,使用简单词汇信号对应的特征频谱在数据库中进行比对,对每个特征频谱设置对应的一级权重值,对同一简单词汇信号内不同的特征频谱设置统一的二级权重值,在计算相似度时首先使用一级权重值对相似度进行加权计算,然后对计算结果再通过二级权重值进行二次加权计算。
步骤c中,第二识别模块3建立神经网络模型,使用在数据库中与初筛数据集关联性大于设定阈值的数据对神经网络模型进行训练,确定模型参数;将复杂词汇信号输入神经网络模型进行计算,得到预测结果集;建立每个预测结果与其时间维度上相邻数据的关联映射,对预测结果进行调整,使关联映射全部收敛,调整后的预测结果集为复杂词汇信号识别结果。
复杂词汇信号输入神经网络模型前,提取复杂词汇信号的非线性特征和线性特征,使用线性特征的组合代替非线性特征。在非线性特征两端设置接口部,接口部具有非线性特征的特征点集合。在对非线性特征进行代替时,首先将非线性特征分段,针对每段非线性特征设计与其对应的线性特征组合,且相邻的线性特征组合之间具有部分重复部分。这中代替过程可以提高代替前后的信号一致性,且可以有效减少代替后出现新的非线性特征的几率。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



