
 商标分类
商标分类  商标转让
商标转让 
一种基于说话人特征的个性化语音翻译方法和装置与流程
 2021-01-28 16:01:41|
2021-01-28 16:01:41| 292|
292| 起点商标网
起点商标网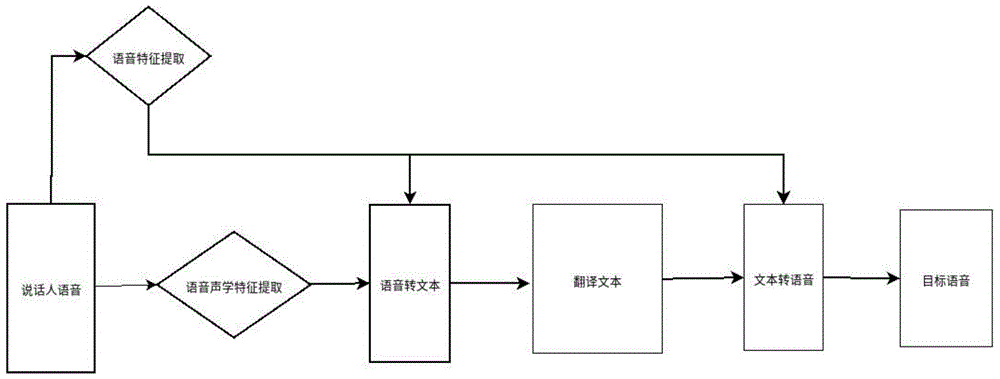
本发明涉及语音翻译技术领域,尤其涉及一种基于说话人特征的个性化语音翻译方法和装置。
背景技术:
随着全球化的发展,不同国家交流的增加,实时语音翻译的重要性越来越大,传统的语音翻译当说话人语气发生变化时,有可能无法表达说话人的意思,以及不同的地区对某些单词可能存在不同的发音,个性化翻译的重要性就体现了出来。
同时在翻译过程中,有可能出现因为说话人的口音语调的不同导致翻译出的结果跟实际的应用结果有不同的情况,比如说话者要表达的信息是“附近有卖热狗的吗?”,而经过语音识别可能会错误识别成“附近有卖芒果的吗?”,这就要求对说话人的说话特征进行区别,对不同的说话人采用不同的识别系统。
在现有技术中cn108447486提供了一种个性化翻译的方式,该方法通过提取目标发音人的声学特征,结合识别后的文本特征完成个性化翻译,使得生成的语音具有目标发音人的说话特征。但是在发音人的语音识别过程中无法避免不同人物说话口音不同所带来的翻译上的误差。
在现有技术中cn108231062a提供了一种通过说话人的发音特征进行个性化翻译的方法,该方法通过提取说话人特征结合语音识别的文本进行翻译,解决了翻译上不同人的特征问题,但是没有实现文本转语音的个性化生成。
综上所述,现有的个性化翻译技术,要么只在翻译端实现个性化,要么在合成端实现个性化,没有解决将说话人特征应用于从说话人语音到文本再到语音的整个个性化翻译系统的问题。
技术实现要素:
本发明提供了一种基于说话人特征的个性化语音翻译方法和装置,以解决现有技术中没有解决将说话人特征应用于从说话人语音到文本再到语音的整个个性化翻译系统的问题。
本发明采用的技术方案是:提供一种基于说话人特征的个性化语音翻译方法,包括以下步骤:
步骤1、采集说话人语音,提取说话人语音的语音声学特征,并转化为说话人特征向量;
步骤2、说话人特征向量结合说话人语音声学特征进行说话人文本识别;
步骤3、将说话人的文本翻译成目标语言的文本;
步骤4、将步骤3生成的目标语言的文本编码结合步骤1生成的说话人特征向量,得到带有说话人特征的目标文本向量;
步骤5、通过文本转语音模型将步骤4生成的目标文本向量生成目标语音。
优选地,步骤1中,提取说话人语音的语音声学特征的方法,包括:
说话人的声音进行加窗傅里叶变化得到线性特征,再通过梅尔滤波处理得到说话人语音声学特征。
优选地,步骤1中,说话人语音的语音声学特征转化为说话人特征向量的方法,包括:
通过不同人物语音样本训练的语音特征识别模型,该语音特征识别模型至少包括深度神经网络;
将步骤1中提取的说话人语音的语音声学特征输入所述语音特征识别模型,得到说话人特征向量。
优选地,步骤2中,根据步骤1得到的说话人特征向量与步骤1中说话人语音的语音声学特征参数进行拼接形成新的特征向量,并将其作为文本识别模型的神经网络的输入,将语音识别为对应文本。
对说话人特征向量和说话人语音声学特征分别进行特征向量化;
将说话人特征向量按照说话人语音声学特征中的帧数进行拓展并拼接到一起;
将拼接后的向量作为神经网络的输入,将语音识别为对应文本。
优选地,步骤3中,将说话人的文本翻译成目标语言的文本的方法,包括:
通过使用端到端网络,采用自注意力机制,加入了文本的位置信息作为神经网络翻译的辅助信息,实现由说话人文本翻译为目标语言文本。
优选地,步骤4中,得到带有说话人特征的目标文本向量的方法,包括:
将目标语音文本进行通过音素字典查找文本的数字序号并进行编码,产生目标文本特征向量和步骤1得到的说话人特征向量结合,得到带有说话人特征的目标文本向量;
根据文本中单词的位置得到文本的位置特征,并转化为文本位置特征向量;
步骤1产生的的说话人特征向量按照说话人语音文本中的音素数量进行拓展,每个目标文本向量对应一个说话人特征向量;
将目标文本向量、文本位置特征向量和说话人特征向量按照声学特征帧数进行拓展并结合,输入端到端网络。
优选地,步骤5中,所述文本转语音模型至少包括端到端的神经网络,并使用注意力机制进行解码,得到输出端的音频线性预测系数,将音频线性预测系数生成目标语音声学特征,用端到端网络和对抗神经网络声码器串联实现个性化语音生成,声码器通过不同样本的声学特征作为输入,样本的音频编码作为输出训练得到。
一种基于说话人特征的个性化语音翻译装置,其特征在于,包括:
说话人音频特征提取单元,用于训练语音特征提取模型,并提取语音特征向量;
说话人语音识别单元,用于根据目标的语音特征选择语音转文本模型,并将语音识别为文本;
翻译单元,用于将说话人的语言翻译成目标语言;
编码器单元,将目标语言结合说话人语音特征进行编码;
端到端文本特征转音频特征单元,用于通过文本转语音模型合成目标语音。
本发明的有益效果是:通过加入说话人特征提取网络,可以将不同说话人语气语调加入语音识别和文本转语音的过程中,帮助更加精确的翻译说话人的意思,表达说话人的心情,同时通过语音到文本再到语音可以实现同声传译的功能,本发明可应用于语音个性化翻译领域,但不仅限于该领域。
附图说明
图1为本发明公开的一种基于说话人特征的个性化语音翻译方法流程图;
图2为本发明公开的一种基于说话人特征的个性化语音翻译装置结构示意图;
图3为本发明公开的端到端网络示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步详细描述,但本发明的实施方式不限于此。
实施例1:
参见图1-3,一种基于说话人特征的个性化语音翻译方法,包括以下步骤:
步骤1、采集说话人语音,提取说话人语音声学特征,并转化为说话人特征向量;
提取说话人语音声学特征的方法,具体为对说话人的声音进行加窗傅里叶变化的得到线性特征,再通过梅尔滤波器处理得到说话人语音声学特征。
通过采集不同语调特征的人提取的说话人语音声学特征输入深度语音识别模型中,再用深度学习网络训练,得到不同说话人语音声学特征对应的说话人特征向量模型。
将说话人提取的说话人语音声学特征输入之前通过不同人物语音样本训练的说话人特征向量模型中,采用深度学习网络,得到说话人语音声学特征对应的说话人特征向量。
步骤2、说话人特征向量和说话人语音声学特征进行拼接形成新的特征向量进行说话人文本识别;
根据训练的语音说话人特征向量结合说话人语音声学特征作为文本识别模型的神经网络输入,神经网络通过深度学习训练的模型,将语音识别为对应文本。对说话人特征向量和说话人语音声学特征分别进行特征向量化;将说话人特征向量按照说话人语音声学特征中的帧数进行拓展并拼接到一起;将拼接后的向量作为神经网络的输入,进行文本识别,得到说话人文本;增加了语音说话人特征提高了语音识别的精确度,适应了不同发音习惯的人。
语音转文本模型通过不同样本人物的声学特征作为输入,对应文本作为输出,经过训练的得到。
步骤3、将说话人的文本翻译成目标语言的文本;
翻译模型通过自然语音处理中的端到端模型实现,根据说话人文本和文本中的单词的位置,采用自注意力机制,生成对应目标文本。
翻译模型通过由说话人语言文本产生的训练样本作为输入,目标语言文本产生的训练样本作为输出训练得到,端到端模型提高了训练的效率,自注意力机制减少了训练的误差。
步骤4、将步骤3生成的目标语言的文本进行编码并结合步骤1生成的说话人特征向量,得到带有说话人特征的目标文本向量;
根据文本中单词的位置得到文本的位置特征,并转化为文本位置特征向量;
将目标语音的文本通过音素字典查找文本的数字序号并进行编码,通过神经网络产生的编码表,找到每个音素对应的512维编码信息,产生目标文本特征向量和步骤1得到的说话人特征向量以及文本位置特征向量合并,得到带有说话人特征的目标文本向量。
步骤5、通过文本转语音模型将步骤4生成的目标文本向量生成目标语音;
文本转语音模型将步骤4生成的带有说话人特征的目标文本向量生成目标语音,包括如图3文本转语音模型合成目标语音的方法,采用文本转语音神经网络,将上一步生成的带有说话人特征的目标文本向量作为输入,并在文本转语音端到端网络中使用了限定范围的注意力机制,结合后的特征根据注意力机制得到权重进行解码,得到输出端的目标语音声学特征。文本转语音端到端网络模型通过不同语音特征的语音样本结合文本训练得到。
文本转语音模型将步骤4生成的说话人特征目标文本向量生成目标语音,包括用个性化后的文本转语音端到端网络和声码器串联实现个性化语音生成,声码器通过不同样本的声学特征结合样本的音频编码采用对抗神经网络训练得到,提高了声码器合成的速度,声码器的输入声学特征采用用之前文本转语音端到端模型生成的目标语音声学特征。
根据本方法,将说话人语音声学特征通过说话人特征向量模型生成说话人特征向量,通过与说话人语音声学特征结合,通过文本识别模型进行音频转文字,翻译过后再将目标语言文本结合说话人特征向量进行文本转语音,通过这种方法提高了识别的准确性,并降低了网络拟合的难度,丰富了合成语音的自然度。
实施例二
本实施例中,一种基于说话人特征的个性化语音翻译装置,包括说话人音频特征提取单元、说话人语音识别单元、翻译单元、编码器单元、端到端文本特征转音频特征单元。
说话人音频特征提取单元,该单元对说话人的声音进行加窗傅里叶变化的得到线性特征,再通过梅尔滤波器处理得到说话人语音声学特征,将目标语音声学特征输入说话人特征向量模型,得到说话人特征向量。
说话人语音识别单元,该单元根据说话人特征向量结合说话人语音声学特征作为文本识别模型的神经网络输入,将语音识别为对应文本。
翻译单元,用于将说话人的语言翻译成目标语言,该单元翻译通过自然语音处理中的端到端模型实现,根据文本和文本中的单词的位置,采用自注意力机制,生成对应目标文本。
编码器单元,将目标语言结合说话人语音特征进行编码,该单元将目标语音文本进行通过音素字典查找文本的数字序号并进行编码,产生目标文本特征向量和说话人特征向量结合,得到带有说话人特征的目标文本特征向量。
端到端文本特征转音频特征单元,用于通过文本转语音模型合成目标语音,该单元采用端到端的神经网络,将上一步生成的说话人特征目标文本向量作为输入,并在端到端网络中使用了限定范围的注意力机制,结合后的特征根据注意力机制得到权重进行解码,得到文本转语音端到端模型生成的声学特征,再将文本转语音端到端模型生成的声学特征输入声码器实现个性化语音生成。
通过本发明实施例二提供的一种基于说话人特征的个性化语音翻译装置,声音的音频通过提取特征在混合模型的基础上,合成的声音的mos(meanopinionscore)高达4.2左右。
需要说明的是,本实施例中的各模块(或单元)是逻辑意义上的,具体实现时,多个模块(或单元)可以合并成一个模块(或单元),一个模块(或单元)也可以拆分成多个模块(或单元)。
本领域普通技术人员可以理解,实现上述实施例方法中的全部或部分流程是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中,该程序在执行时,可包括如上各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



