
 商标分类
商标分类  商标转让
商标转让 
用于高效且精确译码的增量言语译码器组合的制作方法
 2021-01-28 16:01:36|
2021-01-28 16:01:36| 289|
289| 起点商标网
起点商标网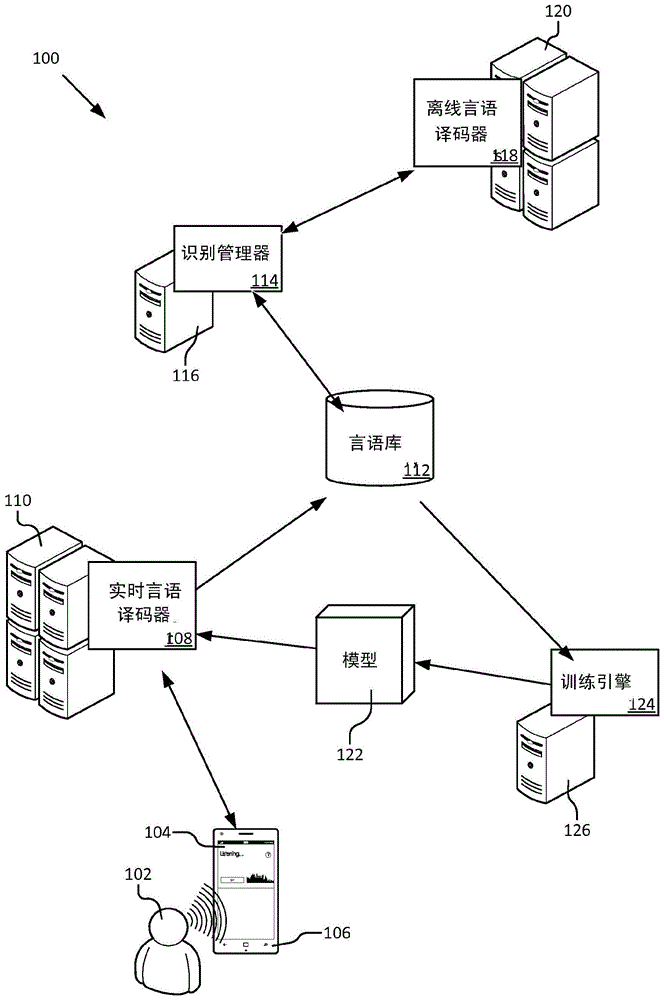
本申请是申请号为201580014680.5的中国申请“用于高效且精确译码的增量言语译码器组合”的分案申请。
背景技术:
离线(即,非实时)语言识别系统用于不要求对所讲言语进行同时回应的方案中。使用离线语言识别的示例包括生成无监督训练数据用于语言和声音建模、音频检索以及自动语言邮件转录。在没有实时约束的情况下,存在传递所讲言语通过多个言语译码器从而降低识别错误率的选择;然而,必须仍考虑资源成本。当每个所讲言语由远少于全部可用的离线言语译码器的多个离线言语译码器进行处理时,在计算力、存储、时间和其它资源方面的要求迅速变得重要。因此,甚至对于离线语言识别,必须针对使用附加系统获得识别错误率降低的益处来衡量成本。
正是针对这些以及其它考虑,做出了本发明。虽然已经论述了相对具体的问题,应当理解,本文公开的实施例不应限于解决在背景技术中提到的具体问题。
技术实现要素:
提供该概述以便以下文在详述部分中进一步描述的简化形式来引入构思的选择。该概述不意在确定权利要求主题的关键特征或主要特征,也不意在该概述用作确定权利要求主题的范围的辅助。
仅当额外的言语译码器很可能对组合结果增加显著的益处时,增量语言识别系统的实施例才使用下一言语译码器对所讲言语进行增量地译码。基于精度、性能、多样性和其它因素在系列中对多个言语译码器进行排序。识别管理引擎通过言语译码器系列协调所讲言语的增量译码,组合译码后言语,并且判定额外的处理是否很可能显著地改善结果。如果是,则识别管理引擎接合下一言语译码器且循环继续。如果结果不可能显著地改善,则结果被接受且译码停止。
可以针对注解训练数据来测试可用的言语译码器以发展用于对言语译码器排序的识别精度、系统多样性、性能或其它度量。基于该排序,言语译码器被排序成系列。言语译码器的排序是可选的以基于方案要求来提供精度与资源使用之间的权衡。
在配置之后,所讲言语由系列中的连续的言语译码器进行顺序地处理。言语译码器对所讲言语进行译码且将识别结果返回到识别管理器。如果没有可用的在先识别结果,则将当前结果处理为提议识别结果。对于对所讲言语进行译码的第二尝试和后续尝试,将新识别结果与在先识别结果组合以产生新的提议识别结果。
识别管理器基于与提议识别结果的组件关联的性能分数来确定所述提议识别结果的估计可靠性。识别结果可以包括通过言语译码器生成的译码后言语以及性能分数。在各实施例中,可利用组合结果中的每个译码后言语的诸如识别置信度的性能分数或者为统计分类器馈送与提议识别结果的组件相关联的各个分数来获得估计可靠性。
将估计可靠性与接受阈值进行比较以判定是否将额外的资源投入于识别所讲言语。如果估计可靠性值满足或超过阈值,则提议识别结果被接受最为最终识别结果,并且所讲言语的识别结束。
在正常情形下,全部可用的言语译码器需要对较少的所讲言语进行译码,但是最终的译码后言语组合将具有接近以及经常是非常接近如果用全部可用的言语译码器对所讲言语进行译码且将译码后言语组合所能得到的最大值的精度。总体来讲,增量语言识别系统能够以小的代价捕获全部的多个言语译码器组合的几乎全部益处。
附图说明
通过参考以下的附图能够最佳地理解本公开的进一步的特征、方面和优点,其中为了更清楚地显示出细节元件不是按比例绘制,并且其中相似的附图标记在全部视图中指示相似的元件:
图1示出了在典型的操作环境中对所讲言语进行增量译码以最小化资源使用的增量语言识别系统的一个实施例;
图2是增量语言识别系统的一个实施例的框图;
图3是使用最少资源在多言语译码器环境中高效地执行离线语言识别的识别管理方法的一个实施例的高级流程图;
图4是识别管理方法的替选实施例的高级流程图;
图5是示出可以实现本发明的实施例的计算设备的物理组件的一个实施例的框图;
图6a和6b是示出可以实现本发明的实施例的移动计算设备的简化框图;以及
图7是示出用于将如本文所述的增量语言识别功能提供给一个或多个客户端设备的系统的体系结构的一个实施例的分布式计算系统的简化框图。
具体实施方式
下文参考构成了各个实施例的一部分的附图来更全面地描述各个实施例,附图显示出具体的示范性的实施例。然而,实施例可通过多种不同的形式来实现,而不应解释为限于本文阐述的实施例;相反,这些实施例被提供以使本公开将是全面的以及完整的,并且将向本领域技术人员充分传达实施例的范围。实施例可以实现为方法、系统或设备。因此,实施例可以呈现为硬件实现方式、全软件实现方式或者组合软件和硬件方面的实现方式的形式。下面的详细说明因此不应在限制的意义上考量。
在本文中描述了以及在附图中图示出增量语言识别系统的实施例。仅当额外的言语译码器很可能对组合结果增加显著益处时,增量语言识别系统才使用额外的言语译码器对所讲言语进行增量地译码。基于精度、性能、多样性和其它因素按系列对可用的言语译码器进行排序。识别管理引擎通过言语译码器系列协调所讲言语的译码,组合译码后言语,以及判定额外的处理是否很可能显著地改善识别结果。如果是,则识别管理引擎接合下一言语译码器且循环继续。如果精度不能得到显著改善,则结果被接受且译码停止。因此,获得精度接近该系列的最大值的译码后言语,而不使用该系列中的全部言语译码器对所讲言语进行译码,从而最小化资源使用。
图1示出了在典型的操作环境中将所讲言语进行增量地译码以最小化资源使用的增量语言识别系统的一个实施例。增量语言识别系统100从言语源获得所讲言语。所讲言语是指讲话者所发出的且以适合与言语译码器一起使用的形式(例如,音频文件或流)采集到的一种或多种声音。例如,所讲言语可从与运行于客户端设备106上的语言使能应用104交互的用户102采集。适合的客户端设备的示例包括但不限于,膝上型计算机、桌面式计算机、移动电话、个人数字助理、智能手机、智能手表、视频游戏系统、智能电器(例如,智能电视机)、导航系统以及汽车娱乐系统(例如,汽车无线电)。应当意识到,客户端设备可以将多个组成设备(例如,音频游戏系统和电视机)组合来提供最小功能。
图示的实施例的操作环境描绘了改进实时语言识别的语言识别模型训练方案。用于所讲言语的音频数据可以传递到实时(即,在线)言语译码器108,言语译码器108将语言转换(即,识别或译码)成文本(即,译码后言语)。在图示的实施例中,实时言语译码器运行于远程计算设备110上。在其它实施例中,言语译码器可以运行于客户端设备上且本地地处理所讲言语。实时言语译码器将音频数据译码且将译码后言语返回语言使能应用。
所讲言语可以添加到存储在言语库112中的言语历史,以便离线使用,诸如但不限于,生成无监督训练数据,用于语言和声音建模、音频检索和自动语音邮件转录。
运行于计算设备116上的识别管理器114对运行在一个或多个计算设备120上的多个离线言语译码器118的操作进行定序。每个言语译码器可用于独立地对所讲言语进行译码且由于诸如语言模型、声音模型和译码引擎配置的一些系统组件的差异而提供可能不同于其它言语译码器的结果。
言语译码器排序为系列。在各个实施例中,识别管理器将每个言语译码器进行增量地且选择性地接合且组合结果直至发生停止条件。当返回了具有规定可靠性(例如,精度水平)的译码后言语或者已经通过该系列中的全部言语译码器对译码后言语进行译码时,发生停止条件。言语译码器的次序反映了通过组合来自全部可用言语译码器的译码后言语所能获得的最大精度与通过前述使用多个言语译码器或者使用仅一些可用的言语译码器所能获得的最小资源使用之间的折中。
在任一极端处的结果将会不尽如人意。使用每个可用的言语译码器必然涉及到最大资源使用。通过使用全部可用的言语译码器所实现的精度增益相对于实现那些增益所耗费的额外资源的成本是不值得的。相反,最小资源使用将最大精度约束到单个言语译码器的能力。虽然当使用单个言语译码器时资源成本较低,但是显著的精度增益可通过组合来自少数几个言语译码器的结果来实现。在许多情况下,接近通过组合来自全部可用的言语译码器的译码后言语所能获得的最大精度的可接受精度可利用少于全部可用的言语译码器来获得。然而,获得期望的精度水平所需的言语译码器的数量对于不同的所讲言语是变化的。
在接合言语译码器之后,识别管理器将当前译码后言语与在先结果组合且评估所得到的译码后言语组合的精度。如果实现了选定的精度水平,则译码后言语组合被接受作为该所讲言语的译码后言语,并且不接合额外的言语译码器。在一些实施例中,如果好像没有可用的言语译码器能够精确地译码所讲言语,识别管理器也结束译码。然后,最终译码后言语与言语库中的所讲言语相关联。
存储的所讲言语和关联的译码后言语可供用于各种任务。在图示的实施例中,所讲言语和关联的译码后言语用于训练新一代译码模型122(例如,声学或语言学模型)以与实时言语译码器一起使用。当已经精确地译码了适当数量的所讲言语,所讲言语和关联的译码后言语可以传递到运行于计算设备126上的训练引擎124。在其它实施例中,关联的译码后言语可以是发送到语音邮箱接收者或者以其它方式为语音邮箱接收者所能访问的语音邮件消息(即,所讲言语)的自动转录。
一些或全部的言语译码器和识别管理器可以在同一计算机系统上或者在单独的计算机系统(即,分布式系统)上执行。计算机系统可以实现为单个的计算设备(例如,服务器)或计算设备群(例如,服务器群)。分布式计算机系统可以经由一个或多个网络通信,上述网络例如但不限于因特网、广域网、局域网和个域网。
图2是增量语言识别系统的一个实施例的框图。言语译码器118将注解训练数据202(例如,转录的所讲言语)译码以生成表示能用于对言语译码器进行排序和定序的特性的基准度量204。基准度量可以包括识别精度度量,诸如但不限于,文字错误率(wer)和/或句子错误率(ser)。另外,可以针对性能度量,诸如译码速度、存储器使用量和其它资源使用相关特性,评估言语译码器。可以基于言语译码器的算法、声学模型、语言模型和其它特性的相似度和/或差别来生成多样性度量,同时由言语译码器使用训练数据生成的译码后言语结果的相似度和/或差异(例如,同意率)可用作评估言语译码器之间的多样性的因素。
基于排序按系列对言语译码器进行定序,并且配置识别管理器114。配置206还可以包含额外的信息,诸如但不限于语言识别组件的序列化,接合语言识别组件所需的调用(例如,进入点和任何变量),以及用于评估识别结果的参考值。参考值可特定于每个言语译码器或者可以是全局的。
译码器接口208处理识别管理器与言语译码器之间的交互。译码器接口从待译码的所讲言语212的集合中选择所讲言语210并且调用下一言语译码器。在各个实施例中,识别管理器将所讲言语装载到存储器中并且将音频数据流式传输到言语译码器。替代地,在存储音频数据的存储器可供言语译码器访问的情况下,识别管理器可以将音频数据对象的指针传递到言语译码器。在其它实施例中,识别管理器将诸如所讲言语的音频文件或数据库记录索引的均匀命名公约(unc)或操作具体路径的参考传递到言语译码器,该言语译码器装载音频文件或者直接访问记录。
在所讲言语已经被译码后,译码器接口接受来自当前言语译码器的译码后言语214和关联的性能分数216。组合器218将当前译码后言语与先前译码后的言语组合220(如果这些存在)组合。估计器222使用与构成了译码后言语组合的译码后言语相关联的性能分数来估计当前译码后言语组合的可靠性分数224。可靠性分数是对译码后言语组合的精度以及额外的系统组合可进一步减少错误的可能性的度量。在一些实施例中,利用使用来自通过配置的言语译码器系列对训练数据进行译码的结果构建的统计分类器226来估计可靠性分数。
评估器228将可靠性分数与对应于当前离线译码器的参考值进行比较。参考值可以包括接受阈值230,在接受阈值230或之上,译码后言语可接受,并且在一些实施例中,包括放弃阈值232,在该放弃阈值之下所讲言语被视为不可译码的。换言之,放弃阈值对应于表明所讲言语可能过难而不能通过现有的言语译码器正确译码的水平。在任何情况下,无需浪费对该所讲言语的额外译码。在各个实施例中,接受阈值代表了认为所讲言语被正确译码所需的最小精度水平。训练数据的译码可用于调谐接受阈值和/或放弃阈值。
增量语言识别系统的实施例可选地基于来自评估器的决策来参考所讲言语进行音频处理。因此,增量语言识别系统可以包括提供音频文件或数据的辅助助理的一个或多个音频处理器234。各音频处理器可以按所讲言语中的自然中断(例如,对话中的转音或显著暂停)将音频数据分块成单元,将音频标准化(例如,音量调准),增强音频(例如,强调或不强调音频中的选定频率),去除或减少离散噪声(例如,嘶嘶声,砰然声),去除或减少在恒定频率或恒定频率范围内的背景声音或噪声(例如,风噪声)。
例如,如果可靠性分数降至放弃阈值以下,译码器接口可以接合音频处理器以整理或增强所讲言语,然后将处理后的所讲言语重新提交给当前的言语译码器进行重新译码。如果在音频处理完成后译码持续失败,则该所讲言语的译码被放弃。音频处理参考决策可基于其它标准,诸如在接受分数以下但是在接受分数的某百分比以内的可靠性分数,或者具体定义的参考阈值。
在各个实施例中,音频处理器可以集成到言语译码器系列中或者放置在单独的系列中并且以与言语译码器相同的方式被增量地调用。因此,与音频处理器相关联的资源成本还可以通过仅在需要时使用音频处理器以及仅使用需要数量的音频处理器来实现令人满意的结果来最小化。
译码历史存储器236存储有关所讲言语的译码的信息,诸如每个言语译码器所返回的译码后言语和关联的性能分数以及译码后言语组合和关联的估计可靠性或其它导出值的组合。当获得可接受的最终译码后言语组合238时,其链接到对应的所讲言语且存储在例如言语库112中。
在通常情形下,将需要通过全部可用言语译码器对很少的所讲言语进行译码,但是最终译码后言语组合将具有接近以及经常非常接近通过用全部可用言语译码器对所讲言语进行译码以及将译码后言语组合所能获得的最大值的精度。总体来讲,增量语言识别系统能够以小的代价来捕获完整的多个言语译码器组合的几乎全部益处。
图3是使用最少资源在多言语译码器环境中高效地执行离线语言识别的识别管理方法的一个实施例的高级流程图。识别管理方法300包括配置操作302。在配置期间,可以针对注解训练数据来测试可用的言语译码器以形成识别精度、系统多样性、性能或其它(例如,导出)度量,这些可用于对言语译码器进行排序。
基于该排序,言语译码器被定序成系列。言语译码器的定序是可选的以便基于方案要求来提供精度和资源使用之间的权衡。在简单的实施例中,序列化可以基于单个特性,诸如文字错误率。在一些实施例中,序列化可以基于多个标准,诸如识别精度和系统多样性度量的组合。例如,产生不同结果的言语译码器很可能具有更多的协同作用且产生更佳质量的组合结果。为了利用该协同作用,在选定了具有最低文字错误率的言语译码器作为系列中的第一个言语译码器之后,其余的言语译码器可以按每个言语译码器的文字错误率和对第一言语译码器结果的同意率的加权和来定序。在导出度量的示例中,错误率与处理速度之比用于序列化。该导出度量可用于对在系列中较靠前的、具有良好但不一定是最佳的识别精度度量的较快言语译码器给予偏好。
在配置之后,增量语言识别对处理未注解的所讲言语准备就绪。言语译码操作304将所讲言语传递到系列中的下一言语译码器。言语译码器将所讲言语译码且将识别结果(即,译码后言语)和一个或多个性能分数返回到识别管理器。
在先结果决策306判定所讲言语的在先识别结果是否可用。如果没有可用的在先识别结果,则当前的结果被独自处理为提议识别结果。
可靠性估计操作308基于与提议识别结果的组件关联的一个或多个性能分数来确定提议识别结果的估计可靠性。根据言语译码器,识别结果可以包括译码后言语以及由言语译码器生成的性能分数。例如,言语译码器可以为译码后言语提供识别置信度分数。一些言语译码器可以返回每个所讲言语的替代假设。替代假设可以通过n-best列表、识别网格以及其它类似的布置的形式来呈现。每个替代假设可以包含替代译码后言语的实例以及与该替代译码后言语相关联的识别置信度。另外,替代假设可以包含额外的信息和性能分数,包括但不限于,语言模型和/或声学模型分数。当替代假设存在时,可靠性估计操作可利用顶层结果(例如,n-best列表中的第一个结果)来工作。
在各个实施例中,可以利用识别置信度来获得估计可靠性。对于来自初始译码操作的提议识别结果,可靠性估计操作可以简单地采用识别置信度或者由初始言语译码器返回的其它单个性能分数(例如,语言或声学模型分数)中的一个。替代地,可靠性估计操作可以从诸如但不限于识别置信度、语言模型分数、声学模型分数、b-best列表或识别网格尺寸以及n-best列表项或识别网格项多样性的识别结果的各特征来导出估计可靠性。例如,小的n-best列表尺寸和/或n-best列表项之间的有限的多样性表明了结果的更大的置信度。
可靠性估计操作的实施例可以使用利用训练数据来训练的统计分类器,从而利用与组合结果中的译码后言语相关联的各分数作为输入来预测组合结果的精度以及额外的系统组合会进一步减少错误的可能性。在一些实施例中,可靠性估计操作汇编了与提议识别结果中的每个识别结果相关联的一个或多个性能分数和/或导出值、来自交叉系统比较的值和/或在先估计可靠性值,用作统计分类器的输入。
可靠性评估操作310将针对提议识别结果的估计的可靠性与接受阈值进行比较以判定是否将额外的资源投入于识别所讲言语。在各个实施例中,接受阈值是针对对应分数的阈值(例如,可靠性或识别置信度值)。对应于不同的言语译码器的全局值或单值可被配置用于接受阈值和其它参考值(例如,放弃阈值或参考阈值)。
如果估计可靠性值满足或超过阈值,则结果接受操作312接受提议识别结果作为最终识别结果,并且对所讲言语的识别结束。换言之,没有投入另外的资源来改善所讲言语的识别结果。
如果提议识别结果被判定为不具有足够的可靠性,则可选的译码操作314可以将一个或多个性能分数与对应的失败指示符(例如,放弃阈值)进行比较以判定是否投入额外的资源在识别所讲言语中。在各个实施例中,失败指示符是指示译码所讲言语的高难度级别的参考值。该高难度级别对应于所讲言语不能被系列中的任意其它言语译码器可接受地译码的高的概率。例如,低的声学模型分数可以表明,所讲言语的音频品质如此之差以至于使得所讲言语不能识别。在各个实施例中,如果没有由适当的分数来满足放弃阈值,则所讲言语的识别被放弃,并且不将另外的资源投入到识别所讲言语的尝试。
当识别结果既没有被接受为精确的也没有被拒绝为不可识别的,该方法返回言语译码操作304以试图使用系列中的下一言语译码器对所讲言语进行可接受地译码。
在所讲言语进行译码的第二次和后续的尝试中,在先识别结果存在,并且在先结果决策分支到组合操作316。组合操作将新译码的言语与在先识别结果合并以产生新的/更新的提议识别结果。一般地,可以使用任何用来组合多个识别结果的技术来生成提议识别结果。例如,可利用言语水平重排序或识别器输出投票错误减少来组合识别结果。
当使用组合结果作为提议识别结果时,可靠性估计操作308仍具有生成提议识别结果的估计可靠性值的任务,但是估计可靠性值是基于多个识别结果的。换言之,可靠性估计操作可以将与在先识别结果关联的在先估计可靠性值与针对当前识别结果确定的估计可靠性进行组合。在最简单的情况下,当每个单个的言语译码器产生了相同的识别结果时,估计可靠性可以是来自单个言语译码器中的每一个的置信度值或其它识别精度度量的均值。
图4是识别管理方法的替代实施例的高级流程图。一般地,替选的识别管理方法400以类似于之前所述的识别管理方法300的方式操作;然而,替选的识别管理方法将可选的音频处理并入管理序列中。在图示的实施例中,可译码性操作还做出了音频处理参考决策402。在其它实施例中,音频处理参考决策可以包含在估计可靠性操作或单独的操作中。音频处理参考决策的结果用于选择性地触发对音频处理操作404的应用,以尝试并且改善所讲言语的音频品质。例如,当具有良好的一般精度的言语译码器未能识别来自单个所讲言语的大量词语时,音频数据可以进行音频增强和/或降噪处理。一旦处理,可在重新译码操作406中使用相同的言语译码器来尝试重新识别。替选地,音频处理可以是系列中的单独的分支的一部分,其包括针对有问题的识别情况被优化的言语译码器。音频处理器还可以仅当某个言语译码器需要时才接合。
各种类型的用户接口和信息可经由板上计算设备显示器或者经由与一个或多个计算设备相关联的远程显示单元来显示。例如,各种类型的用户接口和信息可以在与投射了各种类型的用户接口和信息的壁面被显示以及交互。与可以实现本发明的实施例的多个计算系统的交互包括击键输入、触摸屏输入、语音或其它音频输入、相关的计算设备配备有检测(例如,照相机)功能用于捕获和解释用于控制计算设备功能的用户姿势的姿势输入,等等。
图5-7和相关的描述提供了可以实现本发明的实施例的各种操作环境的论述。然而,所图示和论述的设备和系统是为了举例和说明的目的,而不是限制可用于实现本文所述的本发明的实施例的大量的计算设备配置。
图5是示出可以实现本发明的实施例的计算设备500的物理组件(即,硬件)的一个实施例的框图。下文描述的计算设备组件可适于具体实施计算设备,包括但不限于,个人计算机、平板式计算机、表面计算机和智能手机、或者本文所述的任何其它计算设备。在基本配置中,计算设备500可以包括至少一个处理单元502以及系统存储器504。根据计算设备的配置和类型,系统存储器504可以包括但不限于易失性存储设备(例如,随机存取存储器)、非易失性存储设备(例如,只读存储器)、闪速存储器或这些存储器的任意组合。系统存储器504可以包括操作系统505以及适合于运行诸如识别管理器114和言语译码器118的软件应用520的一个或多个程序模块506。例如,操作系统505可以适合于控制计算设备500的操作。此外,本发明的实施例可以与图形库、其它操作系统或者任何其它应用程序相结合实现,而不限于任何特定的应用或系统。该基本配置是由虚线508内的那些组件图示出的。计算设备500可以具有额外的特征或功能。例如,计算设备500还可以包括额外的数据存储设备(可移除的和/或非可移除的),诸如例如磁盘、光盘或磁带。这些额外的存储设备由可移除存储设备509和非可移除存储设备510来图示出。
如上所述,多个程序模块和数据文件可以存储在系统存储器504中。在处理单元502上执行的同时,软件应用520可以执行处理,包括但不限于,识别管理方法300的一个或多个阶段。其它可以根据本发明的实施例使用的程序模块可以包括垫子邮件和通讯录应用,文字处理应用、电子表格应用、数据库应用、幻灯片演示应用、绘图应用等。
此外,可以在电路中实现各个实施例,包括离散电子元件,包含逻辑门的封装或集成电子芯片,使用微处理器的电路,或者包含电子元件或微处理器的单个芯片。例如,可以通过片上系统(“soc”)实现本发明的各个实施例,其中所示的每个组件或多个组件可以集成到单个集成电路中。该soc设备可以包括一个或多个处理单元、图形单元、通信单元、系统虚拟化单元以及各应用功能,全部这些都集成(或“烧”)到芯片基板上作为单个集成电路。当经由soc操作时,本文针对软件应用520所述的功能可以经由与单个集成电路(芯片)上的计算设备/系统500的其它组件集成的专用逻辑来操作。本发明的实施例还可以利用其它能够执行诸如例如与(and)、或(or)和非(not)的逻辑运算的技术来实现,包括但不限于机械技术、光学技术、流体技术和量子技术。另外,实施例可以实现在通用计算机或者任何其它电路或系统内。
计算设备500还可以具有输入设备512,诸如键盘、鼠标、笔、声音输入设备、触摸输入设备等。还可以包括输出设备514,诸如显示器、扬声器、打印机等。上述设备是示例,可以使用其它设备。计算设备500可以包括允许与其它计算设备518通信的一个或多个通信连接516。适合的通信连接516的示例包括但不限于rf发射器、接收器和/或收发器电路系统;通用串行总线(usb)、并行端口和/或串行端口。
本文所使用的术语计算机可读介质可以包括计算机存储介质。计算机存储介质可以包括以任何用于存储诸如计算机可读指令、数据结构或程序模块的信息的方法或技术实现的易失性的和非易失性的、可移除的和非可移除的介质。系统存储器504、可移除存储设备509和非可移除存储设备510都是计算机存储介质实例(即,存储器存储)的示例。计算机存储介质可包括随机存取存储器(ram)、只读存储器(rom)、电可擦除只读存储器(eeprom)、闪存或其他存储器技术、压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)或其他光学存储、磁盒、磁带、磁盘存储或其他磁存储设备、或任何其他能够用于存储信息且能够由计算设备500访问的制品。任何这样的计算机存储介质可以是计算设备500的部分。
图6a和6b是示出了可以实现本发明的实施例的移动计算设备的简化框图。适合的移动计算设备的示例包括但不限于,移动电话、智能电话、平板计算机、表面计算机和膝上型计算机。在基本配置中,移动计算设备600是具有输入元件和输出元件的手持式计算机。移动计算设备600典型地包括显示器605以及允许用户输入信息到移动计算设备600的一个或多个输入按钮610。移动计算设备600的显示器605还可以充当输入设备(里人,触摸屏显示器)。如果包含,可选的侧部输入元件615允许另外的用户输入。侧部输入元件615可以是旋转开关、按钮或任何其它类型的手动输入元件。在可选的实施例中,移动计算设备600可以包含更多或更少的输入元件。例如,在一些实施例中显示器605可以是触摸屏。在又一替选实施例中,移动计算设备600是便携式电话系统,诸如蜂窝电话。移动计算设备600还可以包括可选的键板635。可选的键板635可以是物理键板或产生于触摸屏显示器上的“软”键盘。在各个实施例中,输出元件包括用于示出图形用户界面的显示器605、可视指示符620(例如,发光二极管)和/或音频换能器625(例如,扬声器)。在一些实施例中,移动计算设备600包含了用于为用户提供触反馈的振动换能器。在又一实施例中,移动计算设备600可包含了输入端口和/或输出端口,诸如音频输入(例如,麦克风插口)、音频输出(例如,耳机插口)以及视频输出(例如,hdmi端口),用于发送信号到外部设备或者从外部设备接收信号。
图6b是示出了移动计算设备的一个实施例的体系结构的框图。也即,移动计算设备600可以包含实现一些实施例的系统(即,体系结构)602。在一个实施例中,系统602实现为能够运行一个或多个应用(例如,浏览器、电子邮件客户端、记事本、通讯录管理器、消息传递客户端、游戏和媒体客户端/播放器)的智能手机。在一些实施例中,系统602集成为计算设备,诸如集成的个人数字助理(pda)以及无线电话。
一个或多个应用程序665可以装载到存储器662中以及运行于操作系统664上或者与操作系统664关联。应用程序的示例包括电话拨号程序、电子邮件应用、个人信息管理(pim)程序、文字处理程序、电子表格程序、因特网浏览器程序、消息传递程序等。系统602还包括位于存储器662内的非易失性存储区668。非易失性存储区668可用于存储在系统602掉电的情况下不应丢失的永久性信息。应用程序665可使用信息且存储信息于非易失性存储区668中,诸如电子邮件应用使用的电子邮件或其它消息,等等。同步应用(未示出)也位于系统602上并且被编程与与位于主机上的对应的同步应用交互以保持存储在非易失性存储区668中的信息与存储在主机中的对应信息同步。应当意识到,其它应用可以装载到存储器662中且运行于移动计算设备600上,包括本文所述的软件应用。
系统602具有电源670,电源670实现为一个或多个电池。电源670可能还包括外部电源,诸如ac适配器或为电池补电或再充电的电力对接拖座。
系统602还可以包括执行发送和接收射频通信的功能的无线电672。无线电672促进系统602与外界之间经由通信载波或服务提供商之间的无线连接。向无线电672发送以及从无线电672接收是在操作系统664的控制下进行的。换言之,由无线电672接收到的通信可以经由os664散播到应用程序665,反之亦然。
可视指示器620可以用于提供可视通知,和/或音频接口674可用于经由音频换能器625产生可听的通知。在图示的实施例中,可视指示器620是发光二极管(led),音频换能器625是扬声器。这些设备可以直接与电源670耦合,从而当被激活时,它们在通知机制所规定的持续期间内保持接通,即使处理器660和其他组件可能为了节约电池电力而关闭。led可以被编程以保持无限接通直至用户采取措施来指示设备的加电状态。音频接口674用来提供可听信号到用户以及从用户接收可听信号。例如,除了与音频换能器625耦合之外,音频接口674还可以与麦克风耦合以接收可听输入,例如促进电话对话。根据本发明的实施例,麦克风还可以充当音频传感器以促进通知的控制,如下文将要说明的。系统602可还包括使得板上照相机630的操作能够记录静像、视频流等的视频接口676。
实现系统602的移动计算设备600可以具有额外的特征或功能。例如,移动计算设备600还可以包括额外的数据存储设备(可移除的和/或非可移除的),诸如磁盘、光盘或磁带。该额外的存储由非易失性存储区668图示。
通过移动计算设备600生成或捕获以及经由系统602存储的数据/信息可以本地地存储在移动计算设备600上,如上所述,或者数据可以存储在可由设备经由无线电672或者经由移动计算设备600与关联移动计算设备600的单独的计算设备(例如,诸如因特网的分布式计算网络中的服务器计算机)之间的有线连接访问的任意数量的存储介质上。应当理解的是,这些数据/信息可以通过移动计算设备600经由无线电672或者经由分布式计算网络来访问。类似地,根据公知的数据/信息传输和存储手段,包括电子邮件和协作数据/信息共享系统,这些数据/信息可轻易地在计算设备之间传输以便存储和使用。
图7是示出用于向一个或多个客户端设备提供如本文所述的增量语言识别功能的系统的体系结构的一个实施例的分布式计算系统的简化框图。与软件应用710关联地开发的内容、交互的内容或编辑的内容可以存储在不同的通信信道或其它存储类型。例如,可利用目录服务722、web入口724、邮箱服务726、即时消息传递库728或社交网站730来存储各个文档。软件应用710可使用这些类型的系统等中的任一种用于实现数据利用,如本文所述。服务器720可以提供软件应用710给客户端。作为一个示例,服务器720可以是通过web提供软件应用710的web服务器。服务器720可以通过网络715将web上的软件应用720提供给客户端。通过示例的方式,客户端计算设备可以实现为计算设备500且具体实施在个人计算机702a、平板计算机702b和/或移动计算设备(例如,智能电话)702c中。客户端设备的这些实施例中的任意实施例可以从库716获得内容。
在本申请中提供的一个或多个实施例的说明和图示意在向本领域技术人员提供主题的整个范围的全面且完整的公开,而不意在以任何方式限制或限缩如权利要求的发明的范围。在该申请中提供的实施例、示例和细节被视为足以传达所有权以及使得其他技术人员能够实现和使用权利要求的发明的最佳分方式。本领域技术人员视为公知的结果、资源、操作和动作的说明可以简要或省略以免使得本申请的主题的不太已知或独特的方面不清楚。权利要求的发明不应解释为限于在本申请提供的任何实施例、示例或细节。无论是组合地或者单独地显示和描述,各个特征(结构上的和方法上的)都意在被选择性地包含或省去以产生具有特定特征集合的实施例。此外,所显示或描述的任意或全部的功能和动作可以按任何次序或者同时地执行。在被提供了本申请的描述和示例后,本领域技术人员可以设想落入在本申请实施的总的发明构思的较宽方面的精神内的、没有背离权利要求的发明的较宽范围的变型例、修改例和可选的实施例。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



