
 商标分类
商标分类  商标转让
商标转让 
一种语音交互方法及系统与流程
 2021-01-28 16:01:25|
2021-01-28 16:01:25| 268|
268| 起点商标网
起点商标网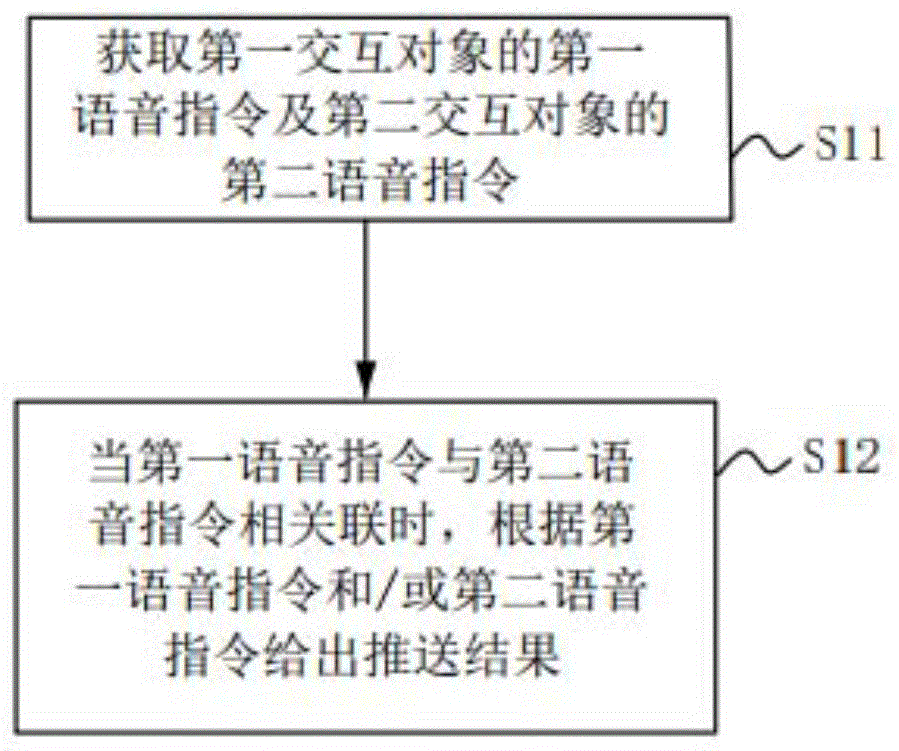
本发明涉及智能语音交互技术领域,特别是涉及一种语音交互方法及系统。
背景技术:
在机器学习与大数据的驱动下,语音产品快速发展,越来越多的语音产品对用户提供了提供多轮交互能力,以解决用户在与智能语音助手交互时,需要多次使用唤醒词进行唤醒的问题。但是,在当前语音交互中,在用户需要使用预定餐厅及酒店或其他出游预定服务时,会开启多轮语音对话,但是当前的语音产品无法与多人进行语音交互。另外,用户在唤醒语音服务时,智能语音助手也都是千篇一律的进行识别、搜索然后给予反馈,对话单调且枯燥。
技术实现要素:
本发明的目的在于提供一种语音交互方法及系统,以解决现有语音交互无记忆功能且对话单调又枯燥的问题。
本发明解决其技术问题是采用以下的技术方案来实现的。
本发明提供一种语音交互方法,包括:
获取第一交互对象的第一语音指令及第二交互对象的第二语音指令;
当所述第一语音指令与所述第二语音指令相互关联时,根据所述第一语音指令和/或所述第二语音指令推送结果。
在本发明的一个实施例中,获取第一交互对象的第一语音指令及第二交互对象的第二语音指令的步骤包括:
获取所述第一交互对象及所述第二交互对象的身份标识,根据每个交互对象的身份标识确定所述第一交互对象及所述第二交互对象的优先级。
在本发明的一个实施例中,获取第一交互对象的第一语音指令及第二交互对象的第二语音指令后还包括:
当所述第一语音指令与所述第二语音指令不相关联时,根据优先级高的交互对象的语音指令推送结果。
在本发明的一个实施例中,根据所述第一语音指令和/或所述第二语音指令推送结果的步骤包括:
预设下轮语音对话的目标意图合集;
获取与所述目标意图合集匹配的所述第一交互对象的第三语音指令和/或所述第二交互对象的第四语音指令和/或第三交互对象的第五语音指令;
根据所述第一语音指令和/或所述第二语音指令和/或所述第三语音指令和/或所述第四语音指令和/或第五语音指令推送结果。
在本发明的一个实施例中,根据所述第一语音指令和/或所述第二语音指令推送结果的步骤包括:
根据所述第一语音指令和/或所述第二语音指令预设持续语音识别状态的时长。
在本发明的一个实施例中,根据所述第一语音指令和/或所述第二语音指令预设持续语音识别状态的时长的步骤包括:
在所述持续语音识别状态的时长内未收到所述第一交互对象的第三语音指令、所述第二交互对象的第四语音指令和第三交互对象的第五语音指令时,退出语音识别状态。
在本发明的一个实施例中,退出语音识别状态的步骤之后包括:
存储历史语音交互数据;
在再次进入语音识别状态时展示是否继续进行上次语音交互的提示信息;
在接收到继续进行上次语音交互的确认信息时,根据所述历史语音交互数据推送结果。
在本发明的一个实施例中,根据所述第一语音指令和/或所述第二语音指令推送结果的步骤还包括:
根据所述第一语音指令、第一交互对象的属性信息、第一交互对象的历史语音交互数据、所述第二语音指令、第二交互对象的属性信息、第二交互对象的历史语音交互数据推送结果。
在本发明的一个实施例中,交互对象的属性信息包括交互对象的年龄、性别中的至少一项。
本发明还提供一种语音交互系统,所述语音交互系统包括存储器、处理器、语音接收装置;
所述语音接收装置用于接收第一交互对象的第一语音指令及第二交互对象的第二语音指令;
所述存储器中存储有计算机应用程序,所述计算机应用程序在被所述处理器执行时实现如上所述的语音交互方法。
本发明提供一种语音交互方法,对获取到的第一交互对象的第一语音指令及第二交互对象的第二语音指令进行处理,当第一语音指令与第二语音指令相互关联时,根据第一语音指令和/或第二语音指令推送结果。本发明还提供一种用于实现语音交互方法的系统,包括检测模块、发送模块和接收模块。本发明提供的语音交互方法及系统,能结合多个交互对象的语音指令来推送结果,可以实现多个交互对象与语音交互系统的交互。
附图说明
图1为本发明第一实施例中语音交互方法的流程图。
图2为本发明第二实施例中语音交互的系统结构框图。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术方式及功效,以下结合附图及实施例,对本发明的具体实施方式、结构、特征及其功效,详细说明如后。
[第一实施例]
图1为本发明第一实施例中语音交互方法的流程图。请结合图1,本发明提供一种语音交互方法,包括如下流程:
s11:获取第一交互对象的第一语音指令及第二交互对象的第二语音指令。
具体地说,本实施方式应用于交互对象与终端交互过程中,具体可以是人与终端的交互过程,也可以是终端与终端的交互过程,此处不做具体限制。本实施方式以人与终端的交互过程为例进行说明,交互对象为人。
其中,终端与人进行交互的过程主要是交互对象通过语音与终端进行信息交互,根据获取到的交互对象的语音指令确定出待执行命令,并完成对应搜索等。
在一个具体的实施例中,终端来获取第一交互对象的第一语音指令及第二交互对象的第二语音指令。其中,该终端可以包括麦克风和扬声器,扬声器负责发出声音,实现语言功能;麦克风负责声音的采集,实现机器人的听觉功能。其中,终端通过麦克风进行声音信号采集之后,确定交互对象的数量,分别对每个交互对象的声音信号进行预处理。
本实施例中,获取第一交互对象的第一语音指令及第二交互对象的第二语音指令的步骤包括:
获取第一交互对象及第二交互对象的身份标识,根据每个交互对象的身份标识确定第一交互对象及第二交互对象的优先级。具体的,第一交互对象的身份标识可以但不限于通过第一语音指令的声纹特征获取,第二交互对象的身份标识可以但不限于通过第二语音指令的声纹特征获取。
s12:当第一语音指令与第二语音指令相互关联时,根据第一语音指令和/或第二语音指令推送结果。
终端在收到语音信息后,对语音信息进行内容识别以判断用户输入的指令类型,当第一语音指令和第二语音指令相关联时,根据第一语音指令和/或第二语音指令推送结果。
其中,当第一交互对象的第一语音指令与第二交互对象的第二语音指令属于同样的类型时,即第一语音指令和第二语音指令相关联,则终端根据第一语音指令和第二语音指令推送结果。例如,第一交互对象说出“订一家西餐厅”,则通过内容识别判断当前的出行服务请求属于用餐服务请求;此时,如果第二交互对象说出“我要吃牛排”,则通过内容识别判断当前的出行服务请求也为用餐服务请求。即第一语音指令和第二语音指令属于同样的类型,终端会结合第一语音指令和第二语音指令来推送结果。
实际实现时,第一交互对象的第一语音指令与第二交互对象的第二语音指令也可能会属于不同的类型时,即第一语音指令与第二语音指令不相关联。例如,第一交互对象说出“订一家西餐厅”,则通过内容识别判断当前的出行服务请求属于用餐服务请求;此时,如果第二交互对象说出“订一家酒店”,则通过内容识别判断当前的出行服务请求为住宿请求,则第一交互对象的第一语音指令与第二交互对象的第二语音指令属于不同的类型,不相关联。此时,终端根据第一语音指令或第二语音指令来推送结果。
实际实现时,第一交互对象的第一语音指令与第二交互对象的第二语音指令即使属于相同的类型,第一语音指令与第二语音指令也可能不相关联。例如,第一交互对象说出“订一家西餐厅”,则通过内容识别判断当前的出行服务请求属于用餐服务请求;第二交互对象说“我现在不想吃饭”,则通过内容识别判断当前的服务请求属于拒绝用餐服务请求,即第一语音指令与第二语音指令虽然均与用餐服务相关,但是两者的用餐意愿完全相反,则判定,第一语音指令与第二语音指令可能不相关联。此时,终端根据第一语音指令或第二语音指令来推送结果。
具体地,当第一交互对象的第一语音指令与第二交互对象的第二语音指令不相关联时,终端会根据发出语音指令的交互对象的优先级来推送结果。
实际实现时,在确认第一语音指令和第二语音指令是否相关联前,还可以包括以下步骤:
判断语音信息是否包含唤醒语音交互功能的关键词;
若是,则根据语音信息的身份标识来识别用户身份;
若识别成功,则启动语音交互功能,并进入确认第一语音指令和第二语音指令是否相关联的步骤。
其中,用户可以通过一次语音输入同时完成唤醒语音交互功能、身份识别、出行服务请求指令输入的操作。终端首先判断语音信息是否包含唤醒语音交互功能的关键词,例如包含语音助理的名称“小e”、包含招呼语“你好”等,在确认包含唤醒语音交互功能的关键词后,根据语音信息的声纹特征识别用户身份,如语音信息的声纹特征与预设用户的声纹特征相符,则身份识别成功,此时,启动语音交互功能,并自动进入判断语音信息的内容是否包含出行服务请求的关键词的步骤,若确认语音信息的内容包含出行服务请求的关键词,则确认语音信息为出行服务请求的语音指令。通过这种方式,用户例如说出“小e,订一家餐厅”,即可同时完成唤醒语音交互功能、身份识别、出行服务请求指令输入的操作,无需多次唤醒语音交互功能,提高交互的效率。
在本实施例中,根据第一语音指令和/或第二语音指令推送结果的步骤还包括:
预设下轮语音对话的目标意图合集;
获取与目标意图合集匹配的第一交互对象的第三语音指令和/或第二交互对象的第四语音指令和/或第三交互对象的第五语音指令;
根据第一语音指令和/或第二语音指令和/或第三语音指令和/或第四语音指令和/或第五语音指令推送结果。
在开启语音对话后,下轮终端实际操作将与当前场景强关联,在具体实施例中,如当一个目标用户(第一交互对象)向终端发送的第一语音指令为“我想看电影”,另一个目标用户(第二交互对象)向终端发送的第二语音指令为“我想看李雷主演的电影”时,终端会返回由李雷主演的多个影片序列供目标用户选择并用语音播报,此时语音交互开启,目标用户下一轮指令可以是选择电影操作或者放弃选择电影操作,将选择电影意图和放弃选择电影意图加入到预设目标意图合集中。当目标用户发出其他出行服务请求时,也同样采取上述操作。例如,当语音指令包括订餐服务请求、出游服务请求、预定酒店服务服务等中的任一种出行服务请求时,同样采取上述操作。当语音指令包括拨打电话、发送短信、弹出小程序等执行性服务请求时,则不需要预设下轮语音对话的目标意图合集。
具体实施例中,第一交互对象和第二交互对象均为目标用户,当第一语音指令为“我想看电影”,第二语音指令为“我想看李雷主演的电影”时,终端会返回多个李雷主演的影片序列供目标用户选择并用语音播报,目标用户的第三语音指令和第四语音指令可以是选择电影操作或者放弃选择电影操作,将选择电影意图和放弃选择电影意图加入到预设目标意图合集中。在获取第一交互对象的第三语音指令和/或第二交互对象的第四语音指令时,当目标用户发送除了选择电影意图和放弃选择电影意图之外的指令时,例如目标用户发送“我要订餐”时,终端将判定第一交互对象的第三语音指令和/或第二交互对象的第四语音指令无效,并重复指引用户选择电影或者放弃看电影。要完成当前语音交互,目标用户只需发送“第一个”、“第一部”等选择电影指令或“退出”等强制退出指令即可。其中,发送“第一个”、“第一部”等选择电影指令或“退出”等强制退出指令的目标用户可以是第一交互对象和/或第二交互对象和/或第三交互对象,终端获取的语音指令可以是第一交互对象的第三语音指令和/或第二交互对象的第四语音指令和/或第三交互对象的第五语音指令。
在判断第三语音指令和第四语音指令及第五语音指令是否与预设的目标意图合集匹配后,如果第三语音指令和第四语音指令及第五语音指令中至少有一个语音指令与预设的目标意图合集中有相匹配的,则判断为是,此时,当前语音交互完成。如果第三语音指令和第四语音指令以及第五语音指令与预设的目标意图合集中没有相匹配的,则判断为否,此时,继续获取目标用户的下一语音指令。
本实施例中,根据第一语音指令和/或第二语音指令推送结果的步骤还包括:据第一语音指令和/或第二语音指令预设持续语音识别状态的时长。具体地,在持续语音识别状态的时长内未收到第一交互对象的第三语音指令、第二交互对象的第四语音指令和第三交互对象的第五语音指令时,退出语音识别状态。
本实施例中,退出语音识别状态的步骤之后包括:
存储历史语音交互数据;
在再次进入语音识别状态时展示是否继续进行上次语音交互的提示信息;
在接收到继续进行上次语音交互的确认信息时,根据历史语音交互数据推送结果。
本实施例中,根据第一语音指令和/或第二语音指令推送结果的步骤还包括:
根据第一语音指令、第一交互对象的属性信息、第一交互对象的历史语音交互数据、第二语音指令、第二交互对象的属性信息、第二交互对象的历史语音交互数据推送结果。其中,交互对象的属性信息包括交互对象的年龄、性别、口味偏好及兴趣爱好中的至少一项。通过对不同属性的用户反馈不同的语音信息,可以避免语音交互系统对目标用户进行千篇一律的回应,从而可以增加趣味性。
[第二实施例]
本发明还提供一种语音交互系统,语音交互系统包括存储器、处理器、语音接收装置;语音接收装置用于接收第一交互对象的第一语音指令及第二交互对象的第二语音指令;
存储器中存储有计算机应用程序,计算机应用程序在被处理器执行时实现如上所述的语音交互方法。
本实施例中,语音接收装置还可以用于接收第三交互对象的语音指令。
本发明提供一种语音交互方法,对获取到的第一交互对象的第一语音指令及第二交互对象的第二语音指令进行处理,当第一语音指令与第二语音指令相互关联时,根据第一语音指令和/或第二语音指令推送结果。本发明还提供一种用于实现语音交互方法的系统,包括存储器、处理器、语音接收装置。本发明提供的语音交互方法及系统,能结合多个交互对象的语音指令来推送结果,可以实现多个交互对象与语音交互系统的交互。
在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,除了包含所列的那些要素,而且还可包含没有明确列出的其他要素。
在本文中,所涉及的前、后、上、下等方位词是以附图中零部件位于图中以及零部件相互之间的位置来定义的,只是为了表达技术方案的清楚及方便。应当理解,所述方位词的使用不应限制本申请请求保护的范围。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



