
 商标分类
商标分类  商标转让
商标转让 
一种基于人工智能技术的语音智能质检字典配置方法与流程
 2021-01-28 16:01:18|
2021-01-28 16:01:18| 493|
493| 起点商标网
起点商标网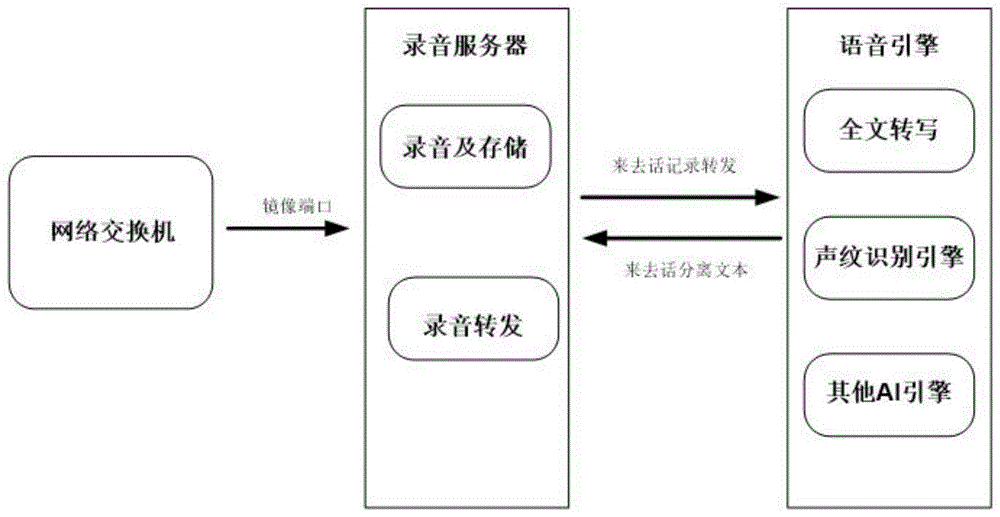
本发明涉及语音识别处理技术领域,具体为一种基于人工智能技术的语音智能质检字典配置方法。
背景技术:
在联络中心引入智能语音引擎后,利用引擎的语音识别技术将联络中心海量的非结构化录音数据转化为结构化文本数据,并提供elasticsearch搜索引擎,用来存储文本索引,但为了对文本内容进行语义解析、关键词识别,并且利用语音分析得出的文本结果可以实现综合查询、热点分析、模型管理、业务聚类等智能化需求,因此需要统计哪些词出现的频率比较高,哪些词可以不需要进行统计,哪些词可以作为关键词进行查询,并需要对这些词语进行配置管理。
技术实现要素:
本发明所解决的技术问题在于提供一种基于人工智能技术的语音智能质检字典配置方法,以解决上述背景技术中提出的问题。
本发明所解决的技术问题采用以下技术方案来实现:一种基于人工智能技术的语音智能质检字典配置方法,包括以下步骤:
步骤(1).部署录音服务程序在服务器端,对通话进行录音,并且进行来去话分离录制存储;
步骤(2).录音服务器将来去话录音转发给语音分析引擎,通过声学模型转换为对应的汉语音标符号、音标信息,再通过超大词汇网络的语言模型识别出最终对应的文本内容并存储在elasticsearch中;
步骤(3).部署智能质检程序在服务器端,在智能质检系统的参数配置模块进行字典配置,包括扩展词、停用词、白名单、黑名单;录音服务器在收到引擎返回的文本并写入elasticsearch的同时,elasticsearch的分词器就会按照已有的扩展词、停用词进行分词,把一段语句划分成若干关键字;
步骤(4).利用配置的扩展词设置标签、质检策略,利用标签进行文本打标,利用策略进行全量评分;通过关键词进行文本搜索,并高亮展示搜索的关键词。
所述步骤(1)中包括通过网络交换机的镜像功能,收取ip话机通话过程中产生的语音载波流和呼叫控制信令,利用服务器的cpu和内存资源,将线路的语音数据软解成用户定义的语音格式,录音系统将话音采集后,通过数字压缩处理将语音信息以数字信号方式先存储在本地硬盘上,再按设定的时间间隔自动备份到存储中心。
所述步骤(2)中包括在录音服务器上部署语音转发接口,通过转发接口将来去话分离的语音数据转发给语音引擎,语音引擎首先将分离后的语音通过声学模型转换为对应的汉语音标符号,音标信息再通过超大词汇网络的语言模型识别出最终对应的结构化文本内容,文本内容包括来去话分离的文字,时长,语速信息,再返回给录音系统进行存储在elasticsearch中。
与现有技术相比,本发明的有益效果是:本发明可以更高效准确的按关键词进行查询,可以使语音文本按扩展词进行正确分词,可以按扩展词设置标签,并进行智能打标、评分。
附图说明
图1为本发明的录音及转发分析过程示意图。
图2为本发明的语音引擎全文转写过程示意图。
图3为本发明的es分词示意图。
具体实施方式
为了使本发明的实现技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明,在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以两个元件内部的连通。
实施例1
如图1~3所示,一种基于人工智能技术的语音智能质检字典配置方法,包括以下步骤:
步骤(1).部署录音服务程序在服务器端,对通话进行录音,并且进行来去话分离录制存储;
步骤(2).录音服务器将来去话录音转发给语音分析引擎,通过声学模型转换为对应的汉语音标符号、音标信息,再通过超大词汇网络的语言模型识别出最终对应的文本内容并存储在elasticsearch中;
步骤(3).部署智能质检程序在服务器端,在智能质检系统的参数配置模块进行字典配置,包括扩展词、停用词、白名单、黑名单;录音服务器在收到引擎返回的文本并写入elasticsearch的同时,elasticsearch的分词器就会按照已有的扩展词、停用词进行分词,把一段语句划分成若干关键字;
步骤(4).利用配置的扩展词设置标签、质检策略,利用标签进行文本打标,利用策略进行全量评分;通过关键词进行文本搜索,并高亮展示搜索的关键词。
所述步骤(1)中包括通过网络交换机的镜像功能,收取ip话机通话过程中产生的语音载波流和呼叫控制信令,利用服务器的cpu和内存资源,将线路的语音数据软解成用户定义的语音格式,录音系统将话音采集后,通过数字压缩处理将语音信息以数字信号方式先存储在本地硬盘上,再按设定的时间间隔自动备份到存储中心。
所述步骤(2)中包括在录音服务器上部署语音转发接口,通过转发接口将来去话分离的语音数据转发给语音引擎,语音引擎首先将分离后的语音通过声学模型转换为对应的汉语音标符号,音标信息再通过超大词汇网络的语言模型识别出最终对应的结构化文本内容,文本内容包括来去话分离的文字,时长,语速信息,再返回给录音系统进行存储在elasticsearch中。
本发明通过预先配置扩展词,利用elasticsearch的分词算法,可以使语音文本按扩展词进行正确分词,可以更高效准确的按关键词进行查询;通过预先配置扩展词,利用elasticsearch的分词算法,可以使语音文本按扩展词进行正确分词,可以按扩展词设置标签,并进行智能打标、评分;通过设置停止词,利用elasticsearch的分词算法,可以使停用词被过滤掉,不会被进行索引,加快建立索引的速度,减小索引库文件的大小;对于联络中心比较关注的词语,在设置为白名单后,在首页的热词统计中必然会出现,可以清楚看到关注的词语出现的频率以及出现在哪些录音文本中;对于不太重要的词语,在设置为黑名单后,在首页的热词统计中必然不会出现,即使该词语在文本中出现的频率比较高。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明的要求保护范围由所附的权利要求书及其等效物界定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



