
 商标分类
商标分类  商标转让
商标转让 
基于深度学习的语音关键信息分离方法与流程
 2021-01-28 15:01:04|
2021-01-28 15:01:04| 354|
354| 起点商标网
起点商标网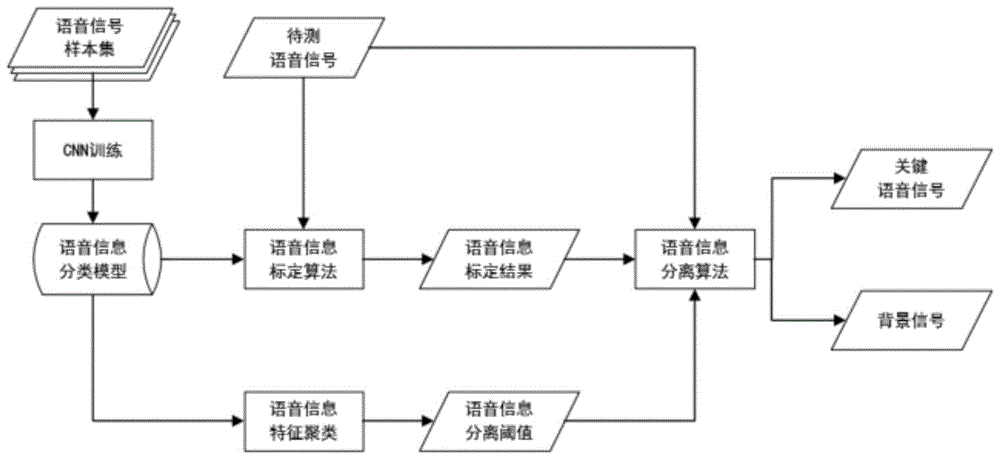
本发明涉及语音处理技术,具体的说是指基于深度学习的语音关键信息分离方法。
背景技术:
语音作为关键的多媒体数据,在信息表达、存储、人机交互中有着重要作用,语音信号中包含着丰富的信息,语音信息检索是目前的重要研究热点。
目前的语音智能检索,常用手段为关键词检索、句子检索、文档检索。现有的检索手段大多依赖语音中的语义分析,检索方法步骤繁多,流程复杂,导致误差累积,准确率下降。
技术实现要素:
本发明提供的是基于深度学习的语音关键信息分离方法,其主要目的在于克服现有语音检索方法步骤繁多、流程复杂,导致误差累积,准确率下降的问题。
为了解决上述的技术问题,本发明采用如下的技术方案:
基于深度学习的语音关键信息分离方法,包括以下步骤:
s1、cnn训练:将语音信号样本集作为训练数据,以待测关键信息为标签,利用cnn卷积神经网络对语音信号样本集进行训练,以获取一个语音信息分类模型,训练后获取的语音信息分类模型可以区分出不同语音信号中是否包含需要关注的关键信息;
s2、语音信息标定:基于训练好的语音信息分类模型,将待测语音信号经过语音信息分类模型,采用反向梯度激活平均算法及特征加权激活映射算法,在语音信号中自动标定所关注的信息;
s3、语音信息特征聚类:将待测的同类语音信号均通过语音信息标定算法分别生成语音信息标定向量,从而形成语音信息标定向量集;然后对语音信息标定向量集采用密度聚类方法,计算出聚类质心向量,即该类别语音信息典型特征分布向量;最后利用统计分析方法,计算语音信息典型特征分布向量中相邻峰值跃迁幅度,找出峰值跃迁幅度最大的两个峰值,计算语音信息分离阈值;
s4、语音信息分离:将目标语音信号序列与语音信息标定序列对齐,基于深度学习进行语音信号标定的过程中,生成语音信息标定序列时,采用插值填充的方法将语音信息标定序列拉伸至与原目标语音信号的相同长度,并将二者对齐;然后根据语音信息典型特征聚类计算得到的分离阈值,结合语音信息标定序列,设计滤波器,对目标语音信号逐点进行分离,将语音信号分离为包含所检索关键信息的关键语音信号和背景信号。
所述cnn卷积神经网络包括多个卷积层、多个池化层及全连接层,每个卷积层对应一个池化层,每个卷积层包括依次信号连接的一维卷积核conv1d、批标准化层bn及relu激活层,所述relu激活层与对应的池化层信号连接,所述多个卷积层和多个池化层按照卷积层→池化层的重复顺序排布,所述全连接层与最后一个池化层连接。
所述反向梯度激活平均算法用于计算待测信号中语音信息特征分布,其计算公式为
(1)k—语音信息特征向量个数(通道数);
(2)z—语音信息特征向量的长度;
(3)c—语音信息的类别个数;
(4)ak—第k个语音信息特征向量;
(5)
(6)yc—语音信息类别c的分类得分;
(7)
所述特征加权激活映射算法用于计算语音信息特征标定向量,其计算公式为:
至此,得到的语音信息初始标定向量的长度为z,即特征向量ak的长度,由于经过cnn卷积神经网络的逐层抽取,初始分布向量的长度小于被测语音信号长度,为了能从被测语音信号中准确标定出信息所在区域,还需要将初始分布向量等比例拉伸至被测语音信号的尺寸,如下式:
由上述对本发明的描述可知,和现有技术相比,本发明具有如下优点:本发明基于深度学习和聚类的人工智能方法,可以在尽可能减少人工干预的情况下,自动分离语音信号中关键语音信号。在此过程中,并不涉及语义分析,可避免传统语音分离处理流程中的累积误差,也可将本方法作为传统方法预处理手段,进一步提升语音分离效果。
附图说明
图1为本发明的分离流程图。
图2为本发明的语音信息分离效果图。
图3为本发明的语音信息标定算法流程图。
图4为本发明cnn卷积神经网络的系统框图。
具体实施方式
参照图1至图4,基于深度学习的语音关键信息分离方法,包括以下步骤:
s1、cnn训练:将语音信号样本集作为训练数据,以待测关键信息为标签,利用cnn卷积神经网络对语音信号样本集进行训练,以获取一个语音信息分类模型,训练后获取的语音信息分类模型可以区分出不同语音信号中是否包含需要关注的关键信息,如判定一段语音中是否存在“身份证”相关信息。
s2、语音信息标定:基于训练好的语音信息分类模型,将待测语音信号经过语音信息分类模型,采用反向梯度激活平均算法及特征加权激活映射算法,在语音信号中自动标定所关注的信息。
s3、语音信息特征聚类:将待测的同类语音信号,如包含“身份证”信息的所有语音样本集,均通过语音信息标定算法分别生成语音信息标定向量,从而形成语音信息标定向量集;然后对语音信息标定向量集采用密度聚类方法,计算出聚类质心向量,即该类别语音信息典型特征分布向量;最后利用统计分析方法,计算语音信息典型特征分布向量中相邻峰值跃迁幅度,找出峰值跃迁幅度最大的两个峰值,计算语音信息分离阈值。
s4、语音信息分离:将目标语音信号序列与语音信息标定序列对齐,基于深度学习进行语音信号标定的过程中,生成语音信息标定序列时,采用插值填充的方法将语音信息标定序列拉伸至与原目标语音信号的相同长度,并将二者对齐;然后根据语音信息典型特征聚类计算得到的分离阈值,结合语音信息标定序列,设计滤波器,对目标语音信号逐点进行分离,将语音信号分离为包含所检索关键信息的关键语音信号和背景信号。
在步骤s1中,所述cnn卷积神经网络包括多个卷积层、多个池化层及全连接层,每个卷积层对应一个池化层,每个卷积层包括依次信号连接的一维卷积核conv1d、批标准化层bn及relu激活层,所述relu激活层与对应的池化层信号连接,所述多个卷积层和多个池化层按照卷积层→池化层的重复顺序排布,所述全连接层与最后一个池化层连接。
所述cnn卷积神经网络的卷积层使用专门设计的一维卷积核conv1d,并加入了批标准化(batchnormalization,bn),改善relu激活的性能,进一步防止梯度消失,从而提升语音信息分类模型的训练效果。所述池化层使用最大池化(maxpooling)。
在步骤s2中,所述反向梯度激活平均算法用于计算待测信号中语音信息特征分布,其计算公式为
(1)k—语音信息特征向量个数(通道数);本方法用到的语音信息特征向量,来自于待测语音信号。待测语音信号通过语音信息分类模型的逐层特征提取之后,由最后一个池化层输出。选取最后一个池化层的原因是,该层最接近全连接层,经过之前的cnn卷积神经网络逐层运算之后,该层输出的特征向量具有最好的语音信息特征。之后的全连接层(fc)不再继续提取特征,仅是加权计算语音信息的分类得分而已。在本实例中,k=256。
(2)z—语音信息特征向量的长度;在本实例中,z=4096。
(3)c—语音信息的类别个数;为训练好的语音信息分类模型可以分类的个数,c的数值根据实际情况设置,可以支持多分类。
(4)ak—第k个语音信息特征向量;由待测语音信号输入语音信息分类模型逐层计算至最后一个池化层输出而得,k=1,2,…k。
(5)
(6)yc—语音信息类别c的分类得分;由待测语音信号输入语音信息分类模型逐层计算得到,c=1,2,…c。
(7)
上述反向梯度激活平均运算的意义在于,通过对全连接层反向求导,获取第k个特性向量ak中的每个特征值
在语音信息检测的实践中,不同程度地出现语音信息特征消失的情况。经过分析发现,其原因在于反向梯度计算
因此,本发明对反向梯度激活平均运算结果进行了relu激活操作,只保留正梯度,过滤带来不利影响的负梯度。
所述特征加权激活映射算法用于计算语音信息特征标定向量,其计算公式为:
至此,得到的语音信息初始标定向量的长度为z,即特征向量ak的长度,由于经过cnn卷积神经网络的逐层抽取,初始分布向量的长度小于被测语音信号长度,为了能从被测语音信号中准确标定出信息所在区域,还需要将初始分布向量等比例拉伸至被测语音信号的尺寸,如下式:
在步骤s3中,语音信息分离阈值的计算方法如下:
v—红黑分离阈值;
f—语音信息典型特征分布向量;
f[i],f[i+1]—语音信息典型特征分布向量中相邻峰值;
伪代码:
在步骤s4中,语音信息分离的输入、输出及伪代码描述如下:
·输入
s—语音信号
ls—s的语音信息标定序列向量
v—语音信息分离阈值
·输出
sr—关键语音信号
sb—背景信号
·伪代码
分离的效果示例如图2所示,图中右上角的关键语音信号就是从待测信号中分离出来的,包含有“身份证”关键信息的信号分量,该信号分量可以作为后续语义分析,智能语音应答的数据支持。
本方法脱离语义分析的传统框架,直接针对语音信号开展信息检索并分离其中关键信息。通过深度学习,自动标定语音信号中的信息,实现关键信息的智能检索,方法简洁有效,可以提升检索效率。
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



