
 商标分类
商标分类  商标转让
商标转让 
一种基于大数据机器学习的情感语音识别方法与流程
 2021-01-28 15:01:52|
2021-01-28 15:01:52| 345|
345| 起点商标网
起点商标网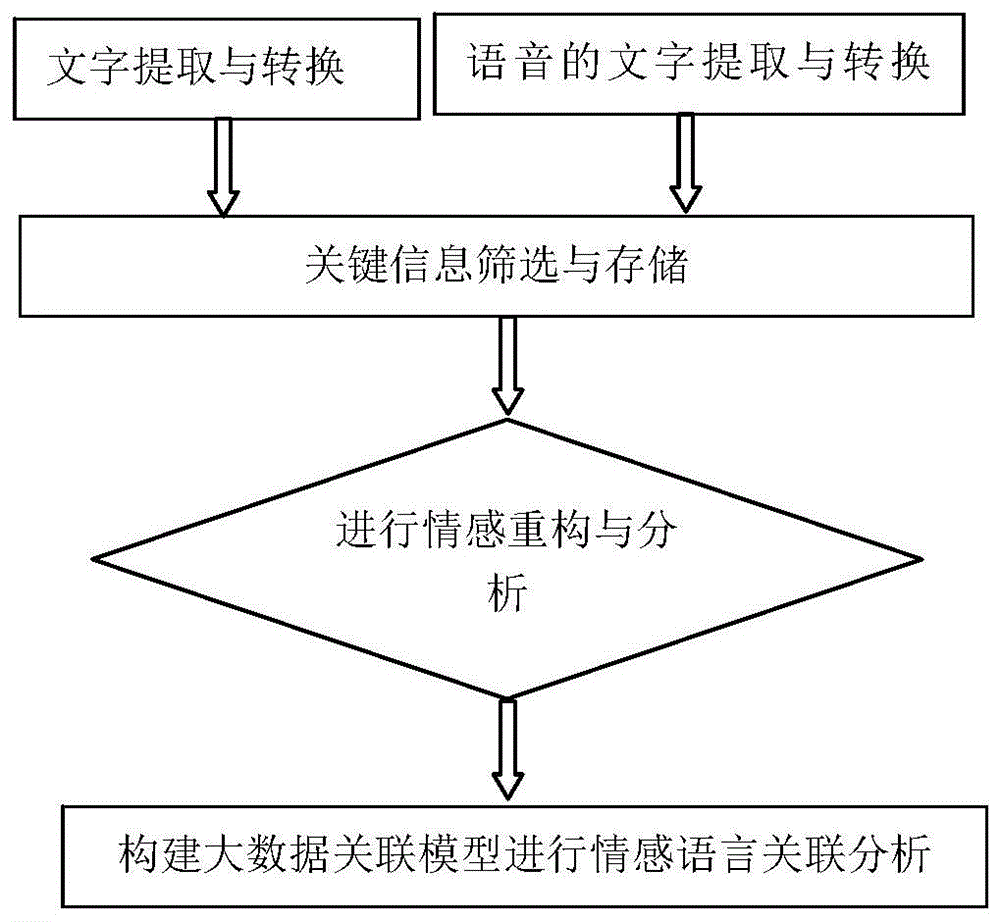
本发明属于大数据的
技术领域:
,具体涉及一种基于大数据机器学习的情感语音识别方法。
背景技术:
:伴随着互联网的迅猛发展,传统的情感研究路线显然满足不了当前纷繁复杂的发展形势,因此迫切需要一种高效、可靠并且具有一定语言识别和逻辑分析能力的研究方法来面对全球格局的复杂命题和传播模式、形态的多样化,以更高的品味和势能回应新局势下人事管理工作的使命和担当,深度拓展媒介融合场景中的算法应用。情感分析是文本的语义挖掘,可识别和提取原始文本材料中的主观信息,可帮助企业在监控在线对话的同时了解其品牌,产品或服务的社会情绪。但是,对社交媒体流的分析通常仅限于基本的情绪分析和基于计数的指标。这就好比仅仅是在表面划过,而错过了那些等待被发现的高价值见解。除此,现有的情感分析还广泛应用于心理学,比如罪犯的审讯、患者的心理评估、个人的情感分析等等。目前对情感分析还存在以下不足之处:1.“情感”的不稳定性和流动性较大,目前并没有一种可以遵循的、系统的研究,特别是在人文社会学科的研究范畴中,对于“情感”的探讨和测量多为泛化的、背景的描述性研究,缺乏学术严谨性和说服力;2.在检验情感与个人情感体验的关系时,缺乏对影响因素的精确量化,没有将受众的多样性、体验的差异性、社会文化情境等要素都纳入到研究中;3.目前量化只有通过人工进行,效率低出错率较高,没有办法就提取出来的情感关键字进行重构分析。技术实现要素:本发明的目的在于针对现有技术中的上述不足,提供一种基于大数据机器学习的情感语音识别方法,以解决现有人工量化分析效率低出错率较高的问题。为达到上述目的,本发明采取的技术方案是:一种基于大数据机器学习的情感语音识别方法,其包括:s1、获取若干文字和音频,并将文字和音频转换成可编辑提取的文字或二进制码;s2、根据转换的二进制编码进行遍寻式关键信息的筛选与存储;s3、读取遍寻式筛选得到的关键信息,并根据上下文限制进行语言重构和输出;s4、基于大数据关联模型,计算得到关键信息之间的相关度系数。优选地,s1获取若干文字和音频,并将文字和音频转换成可编辑提取的文字或二进制码,包括文字识别提取:其中,为文字wi在矩阵m′中的取值,i为文字长度;l为文字范围即字典;k,l为遍寻系数;b为分割点;s为所提取到的文字;语音识别提取:其中,p(s)为句子s出现的概率,w1为单词序列,i为单词序列编号,n为单词序列长度,t为时间遍寻系数,tt为语音长度总时间;优选地,s2中根据转换的二进制编码进行遍寻式关键信息的筛选与存储,包括:根据转换的二进制编码遍寻式筛选:其中,x为关键信息,y为所遍寻的临时信息,lmax和lmin分别为信息最大和最小长度;将筛选到的关键信息根据二进制格式进行存储。优选地,s3中读取遍寻式筛选得到的关键信息,并根据上下文限制进行语言重构和输出,包括:s3.1、输入关键字;s3.2、根据上下文限制进行语言重构,重构矩阵为:其中,w1为单词序列,p(w1)为单词w1出现的概率,i为单词序列编号,n为单词序列长度,ω为重构输出语句;s3.3、输出并保存输出语句。优选地s4中基于大数据关联模型,计算得到关键信息之间的相关度系数:其中,f(w1)11为单词w1在a和b场景中同时出现的次数;f(w1)00为单词w1在a和b场景中同时未出现的次数;f(w1)01为单词w1在a中未出现,b场景中出现的次数;f(w1)10为单词w1在a中出现,b场景中未出现的次数,t为时间遍寻系数,tt为语音长度总时间;f(w1)1+为单词w1在a中出现的次数;f(w1)+1为单词w1在b中出现的次数;f(w1)0+为单词w1在a中未出现的次数;f(w1)+0为单词w1在b中未出现的次数;φ为相关度系数,取值范围为-1到+1,若变量相互独立,则取值为零;若正相关则大于零;若不相关则小于零。本发明提供的基于大数据机器学习的情感语音识别方法,具有以下有益效果:本发明基于大数据的机器学习方法,根据海量样本材料进行文字提取和语言转换,筛选、提取关键信息,并进行分类存放,并进一步根据上下文实现相关情感的重组和再分析,最后基于大数据关联模型可以获得情感关键字或句子的相关性,实现情感分析研究;相比于传统人工对情感的分析提取,本发明可有效地解决现有人工量化分析效率低出错率较高的问题。附图说明图1为本发明流程图。图2为本发明语言重构流程图。具体实施方式下面对本发明的具体实施方式进行描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。根据本申请的一个实施例,参考图1,本方案的基于大数据机器学习的情感语音识别方法,包括:s1、获取若干文字和音频,并将文字和音频转换成可编辑提取的文字或二进制码;s2、根据转换的二进制编码进行遍寻式关键信息的筛选与存储;s3、读取遍寻式筛选得到的关键信息,并根据上下文限制进行语言重构和输出;s4、基于大数据关联模型,计算得到关键信息之间的相关度系数。根据本申请的一个实施例,以下将对上述步骤进行详细描述;步骤s1、获取若干文字和音频,并将文字和音频转换成可编辑提取的文字或二进制码,其具体包括文字识别提取和语音转换识别;其中,文字识别提取方法为:其中,为文字ωi在矩阵m′中的取值,i为文字长度;l为文字范围即字典;k,l为遍寻系数;b为分割点;s为所提取到的文字。语音识别提取方法为:其中,p(s)为句子s出现的概率,w1为单词序列,i为单词序列编号,n为单词序列长度,t为时间遍寻系数,tt为语音长度总时间。步骤s2、根据转换的二进制编码进行遍寻式关键信息的筛选与存储,其具体包括:关键信息的提取和转换情感本身不仅是自我情绪表达的呈现结果,也是一种文化的、社会的情感标准的呈现方式。根据情感研究目标和需求,将有关情感的特征符码加以配置,提取关键字信息,比如平静、兴奋、激动、失落、低沉、思虑、温和、感官愉悦、自我效能等,并将其转为为二进制格式。遍寻式关键信息筛选及存储根据转换的二进制编码遍寻式筛选,其筛选公式为:其中,x为关键信息,y为所遍寻的临时信息,lmax和lmin分别为信息最大和最小长度;将筛选到的关键信息根据二进制格式进行存储。步骤s3、读取遍寻式筛选得到的关键信息,并根据上下文限制进行语言重构和输出,其具体包括:参考图2,步骤s3.1、读取关键字,并输入关键字;步骤s3.2、根据上下文限制进行语言重构,其重构矩阵为:其中,w1为单词序列,p(w1)为单词w1出现的概率,i为单词序列编号,n为单词序列长度,ω为重构输出语句。步骤s3.3、输出重构语句。步骤s4、基于大数据关联模型,计算得到关键信息之间的相关度系数,其具体包括:利用大数据关联模型进一步分析情感关键字的内在关联性,构建关联模型为:其中,f(w1)11表示单词w1在a和b场景中同时出现的次数;f(w1)00表示单词w1在a和b场景中同时未出现的次数;f(w1)01表示单词w1在a中未出现,b场景中出现的次数;f(w1)10表示单词w1在a中出现,b场景中未出现的次数;f(w1)1+表示单词w1在a中出现的次数;f(w1)+1表示单词w1在b中出现的次数;f(w1)0+表示单词w1在a中未出现的次数;f(w1)+0表示单词w1在b中未出现的次数,t为时间遍寻系数,tt为语音长度总时间。φ为相关度系统,取值范围为-1到+1,若变量相互独立,则取值为零,若正相关则大于零,若不相关则小于零。根据本申请的一个实施例,以下传统方法对情感的分析是基于人工进行关键字或句子提取,比较费时并且有可能会存在提取漏洞并丢失局部关键字。根据实验可得,传统方法对大批量的文字的提取往往需要至少1周或更多的时间,而应用本发明算法则可以完美地解决这些问题,不存在关键字或句子丢失现象并且提取时间较短,具体如下表所示。表1文字提取识别传统方法与本发明方法对比方法时间是否可以自动重构传统提取方法至少5天不行本发明提取方法1h-3h可以由表可知,采用本发明算法极大的缩短了工作所需时间,解放了人工,并增大了工作效率,且可根据所提取的关键信息进行重构。本发明基于大数据的机器学习方法,根据海量样本材料进行文字提取和语言转换,筛选、提取关键信息,并进行分类存放,并进一步根据上下文实现相关情感的重组和再分析,最后基于大数据关联模型可以获得情感关键字或句子的相关性,实现情感分析研究;相比于传统人工对情感的分析提取,本发明可有效地解决现有人工量化分析效率低出错率较高的问题。本发明方法可识别和提取原始文本材料中的主观信息,可帮助企业在监控在线对话的同时了解其品牌,产品或服务的社会情绪。并基于本方法识别算法,发现企业在线对话高价值见解。除此,本发明还可应用于心理学,比如罪犯的审讯、患者的心理评估、个人的情感分析等等。虽然结合附图对发明的具体实施方式进行了详细地描述,但不应理解为对本专利的保护范围的限定。在权利要求书所描述的范围内,本领域技术人员不经创造性劳动即可做出的各种修改和变形仍属本专利的保护范围。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips