
 商标分类
商标分类  商标转让
商标转让 
端到端的智能语音朗读评测方法与流程
 2021-01-28 15:01:58|
2021-01-28 15:01:58| 299|
299| 起点商标网
起点商标网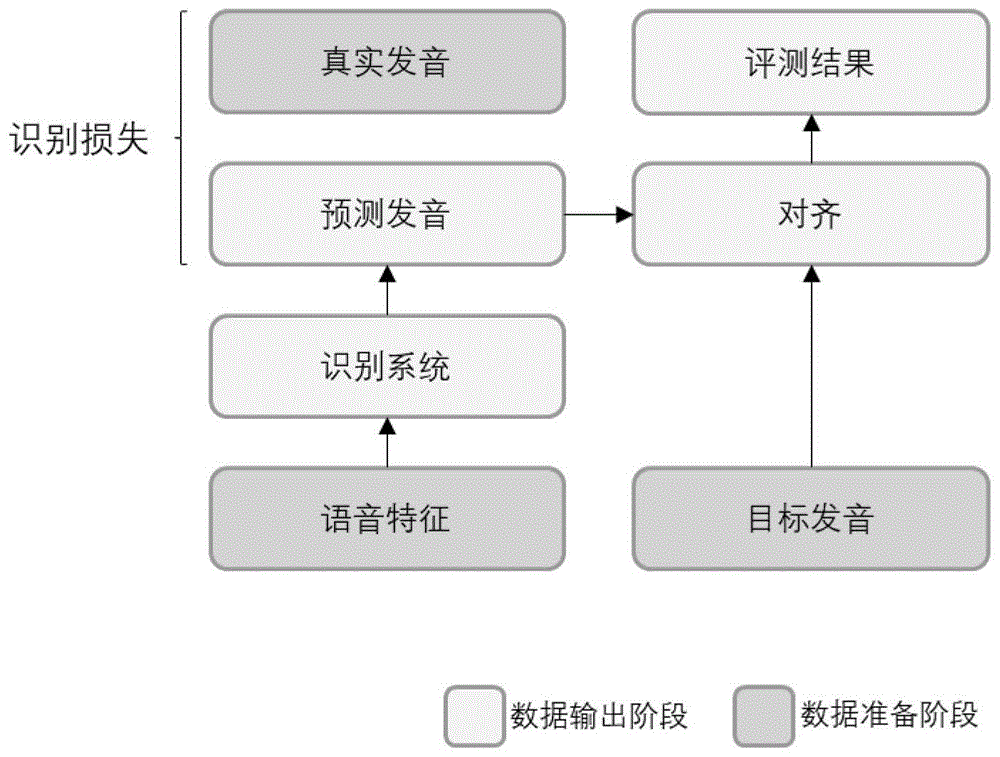
本发明涉及语音评测技术领域,具体涉及一种语音评测方法及系统。
背景技术:
随着人工智能中语音识别技术的发展,人们开始将目光聚焦于如何使用语音识别技术应用到教育相关的场景中。然而,传统基于隐马尔可夫链模型的识别评测方法需要对待识别的语言包含许多工程化处理的阶段,需要进行较为复杂的建模。传统识别方法需要将单词拆分成音素并考虑音素的前后文,组成三音素模型,再构建这些三音素模型对应的马尔科夫链,并从样本中估计该隐马尔可夫链模型对应的路径概率,最后得到识别结果。为了改进这些流程,领域专家需要花费很多精力来调整各个阶段模型的参数。而目前语音评测相关的技术由于需要将待识别的语音和所关注的文本进行对齐,往往需要基于隐马尔可夫链的模型提取特征,这无疑使得该语音评测技术的部署较为复杂,使得该技术的应用受到限制。而目前基于深度学习的语音识别(asr)评测方式需要先对评测的语音做识别,再将识别结果与待评测文本进行对齐以获得评测结果,导致评测质量和识别结果有关系。在这样的情况下,用户的口音对评测结果影响较大;另一方面,识别结果需要和评测文本进行对齐,无法做到完全端到端的输出错误位置,只能间接优化识别结果,无法直接优化评测结果。因此,某些并非由识别导致的(例如音调、节奏等等)评测错误难以被基于识别的此种方式正确判定。直接端到端输出评测情况的方法,不仅能极大的减轻部署的困难,还能够直接优化评测效果,给出更为精确的反馈,使得用户得到更好的学习反馈体验。
技术实现要素:
本发明提出了一个易于部署、可直接优化反馈指标的完全端到端输出语音评测方法,该评测方法可应用于口语朗读训练课程中。
用户通过跟读的方式朗读给出的文本,由智能设备采集该用户朗读的预设参考文本的待评测语音,由语音编码模块输出音频特征作为参考。另外一方面,根据用户的需要将参考文本转换为需要评测的语言单位(例如音素、音标或字母)串,将参考的语音特征和转换后的参考文本串输入文本、语音联合编码模块,由错误输出模块评价各类语言单位的朗读情况,获得更高级的语言相关特征,即每个目标语言单位的评测特征,并判断这些高级特征是否能匹配目标读音,最终直接解码输出朗读情况反馈给用户,使用户更加了解口语中需要改进的地方,从而激励用户继续学习和进步。
该评测方法采用基于深度学习的编码-解码模块直接输出语音与待评测文本之间的朗读情况,
构建了三个相关模块,包括语音编码模块、文本语音联合编码模块及错误输出模块。
语音编码模块作为该方法的声学模型,用于从音频中提取更高级的语言相关特征,输出编码后的语音特征至文本语音联合编码模块进行后续的处理。对于语音编码模块,额外增加针对说话人的辅助任务,使得该编码模块能够从音频特征中提取更多有助于评测的相关信息。在文本语音联合编码模块中,文本特征即可利用到这些评测信息融合更丰富的语音特征,用于输出更准确的评测结果。
文本语音联合编码模块首先将离散的文本输入映射至连续的特征空间,然后根据映射后的文本特征,与语音编码模块输出的语音特征进行融合,融合后的特征将被送入错误输出模块进行判定。
错误输出模块对融合后的语音、文本特征进行判定,判定该特征中的语音部分是否能够与文本部分相匹配,并将每个文本单位的匹配程度被映射为错误代码,输出给用户。该预测的错误情况与真实的错误情况之间的差异将作为整个方法的损失函数用于反向传播并优化整个方法。
该方法具有以下创新点:
该方法不再借助隐马尔可夫链(hmm)建模语音和音素状态之间的关系,而是直接构建输入为语音和待评测文本、输出为反馈结果的端到端评测模式。由于整个方法均基于深度学习构建,可与方法中的各个模块联合训练使得整体效果更好;训练流程上,同样比基于隐马尔科夫链的方法更易于构建。另外一方面,由于没有使用音素状态进行建模,朗读情况的反馈单位可以根据实际需要进行设定。
该方法构建的辅助任务能够更准确的提取评测相关特征,使得反馈的评测结果更为准确。
该方法直接输入语音和标准文本,输出反馈给用户的评测结果,不再需要输入语音识别之后与标准文本进行对齐。因此,该方法可以直接通过反向传播优化反馈结果。由于该方法完全端到端,该方法中的文本编码模块能够根据评测文本进行调整,除开反馈音素之外,还可反馈嘴型、舌位等其他单位,可直接构建音频-反馈单位的映射关系,训练流程得到极大的简化,能够更为容易地构建一个可直接反馈给用户所需要的信息的系统。
附图说明
图1是基于语音识别的评测方式图。
图2是本发明的评测方法示意图。
图3是本发明的评测模块示意图。
具体实施方式
为了更好地说明该方法的创新点,下面首先对现有语音评测方法做简单说明。现有语音评测方法包括基于隐马尔可夫链(hmm)的方法和基于深度学习语音识别的方法。
基于隐马尔可夫链的识别模型进行对齐,再对朗读情况结合模型中的状态进行判定,训练、推理过程通常包含以下步骤:
-从(语音,文本)的训练样本中提取语音信号特征,包括降噪预处理、归一化等过程,通常提取多维梅尔频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)或梅尔标度滤波器组(melscalefilterbank,fbank)等特征。
-根据语言相关的词典将文本中的每个单词转换为音素并构建隐马尔可夫链(hiddenmarkovmodel,hmm)模型。这些音素将由隐马尔可夫链中的状态构成。
-将语音特征与由文本拆分成音素状态的序列进行对齐,采用混合高斯模型(gaussianmixturemodel)估计每个状态对应的声学特征,构建声学模型。该过程将会迭代很多次,以获得更好的对齐结果及声学模型。上述构建的模型也被称为gmm-hmm。目前的评测模型为了获得更好的声学模型,还会基于上述构建的gmm-hmm获得对齐结果,基于每个状态所对齐到的声学特征,训练深度神经网络(deepneuralnetwork,dnn)来获得更好的声学模型。该模型被称为dnn-hmm。
在进行评测推理时,由上述训练好的模型获得待评测文本的后验概率,基于goodnessofpronunciation(gop)算法进行评测。假设待评测的音素为p,音素集合为q,输入的语音特征为o,则该音素的评测分数为
实际应用中,经过先验概率假设p(p)=p(q),q∈q及最大化近似∑q∈qp(o|q)p(q)≈maxq∈qp(o|q)之后,该公式变形为
该公式中的分子即为待评测文本相关的音素概率,分母为输入的语音特征所观测到的音素中最大的概率,均可通过上述训练好的gmm-hmm或dnn-hmm获得。
上述方法流程较为繁琐,应用门槛较高。为了改进这些流程,领域专家需要花费很多精力来调整各个阶段模型的参数,这无疑使得该语音评测技术的部署较为复杂,使得该技术的应用受到限制。因此,除开基于hmm进行文本对齐的评测方式,目前还存在基于语音识别(asr)的评测方式。其整体流程如图1所示。
在此流程的数据准备阶段,首先设定目标发音,要求被测试者朗读此目标发音并收集对应的语音数据,然后由专业的评测老师标注被试者的真实发音,记录进数据库。之后,该类评测方式基于标准读音提取的语音特征,输出预测发音,并与真实发音计算识别损失并反向传播,由此训练得到对应的声学模型。在推理时,使用该声学模型对输入语音进行识别,将识别结果与标准文本对齐,用于找出标准文本中哪些为错误读音并输出给用户。
然而,在该流程中,存在以下可以改进的地方:
-该评测系统主要依赖于标准读音训练得到的声学模型进行识别,因此包含口音的朗读将会对识别结果产生很大影响,进而影响评测结果。
-由于对齐操作不可微分,无法进行反向传播,该评测系统需要通过改进识别结果再进行对齐进而间接改进评测结果。因此,调整评测的难易度、或是优化评测系统的误检率指标较为困难。
基于以上可改进之处,该方法提出如图2所示的流程。
改进后的流程如下:
第一步,进行数据收集与准备。除开要求被测试者朗读目标发音、收集对应的语音数据并由专业的评测老师标注被试者的真实发音之外,还会记录被试者的语言背景(如性别、母语、口语分数)。数据收集完成后,对齐真实发音和目标发音,得到实际错误反馈。目标发音xtext由各个文本单位(例如第一个文本单位为
根据对齐后真实发音正确程度,其错误代码
第二步,训练该评测系统。该评测系统由三个模块构成,包括语音编码模块、文本语音联合编码模块和错误输出模块,如图3所示,下面进行详细描述。
1、语音编码模块
语音编码模块作为该方法的声学模型,用于从音频中提取更高级的语言相关特征。该模块首先将音频特征通过音频映射层映射为特定维度,然后堆叠多层非线性变换层,输出编码后的语音特征至文本语音联合编码模块进行后续的处理。若将语音编码模块前部的音频映射层和第一部分的多层非线性变化层组合表示为eaudio,输入的语音特征为xaudio,则编码后的语音特征yaudio为:
yaudio=eaudio(xaudio)
由于带有详细评测标注的数据较少,为了训练该语音编码模块来提取语音特征,将使用较大规模的语音识别数据集进行预训练,并在后续使用评测数据进行参数微调。
此外,该方法针对于此模块额外增加了于说话人相关的辅助任务,如口音、性别等等特征分类任务。这些特征是全局特征,因此需要在前述特征的基础上进行时间维度归一。归一化之后的特征经过多层非线性变换映射为预测的说话人相关的特征,并与真实说话人特征求损失函数并反向传播。在此基础上,输出的语音特征能够提取更多有助于评测的信息,使得最终输出的评测结果更为准确。
若将预测的说话人特征表示为
将真实说话人特征标记为
其中loss表示所使用的损失函数,根据预测的特征所不同,可以为均方误差或交叉熵损失等等函数。
2、文本语音联合编码模块
该模块的文本输入为目标发音xtext。文本语音联合编码模块首先将离散的文本输入通过文本映射层映射至连续的特征空间,然后根据映射后的文本特征,与语音编码模块输出的语音特征送入多层非线性融合层进行融合,得到了表征能力较强的联合特征。若将文本语音联合编码模块表示为ejoint,融合后的联合特征yjoint为
yjoint=ejoint(xtext,yaudio)
该联合特征长度同样为s(例如第一个联合特征为
该特征将被送入错误输出模块进行判定。
3、错误输出模块
错误输出模块对融合后的语音、文本特征进行多次非线性变换加强表征能力,并判定该特征中的语音部分是否能够与文本部分相匹配。每个文本单位的匹配程度通过sigmoid激活函数被映射为0到1(0表示读音完全不匹配文本单位,1表示读音完全匹配文本单位),并输出给用户。
若将错误输出模块表示为derr,则输出的预测评测情况序列
该预测评测情况长度为s(例如第一个评测为
该预测的错误情况
训练过程中总的损失函数ltotal为上述辅助损失函数ls、评测损失函数lerr的加权,即
ltotal=lerr+λls
其中λ为辅助任务的权重,用于反向传播并优化整个模型。
第三步,使用该评测系统。输入待评测的语音特征xaudio与目标读音xtext,输出该读音的评测情况
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



