
 商标分类
商标分类  商标转让
商标转让 
一种基于声音判别抑郁症的检测方法与流程
 2021-01-28 14:01:28|
2021-01-28 14:01:28| 366|
366| 起点商标网
起点商标网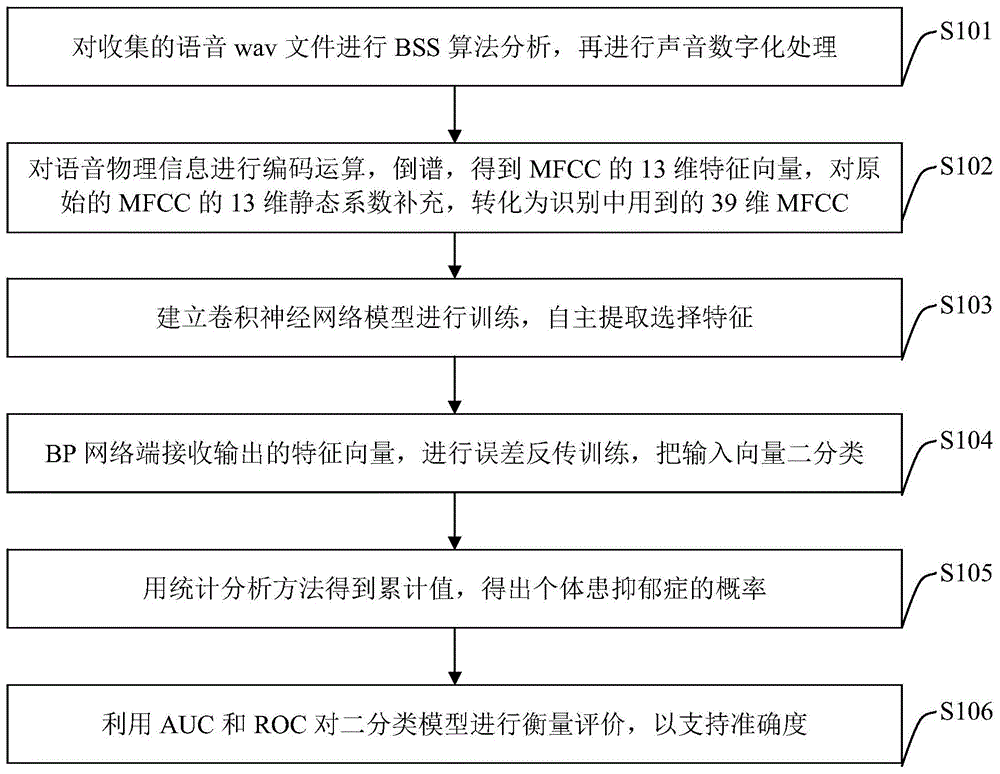
本发明属于语音处理技术领域,更具体地说,涉及一种基于声音判别抑郁症的检测方法。
背景技术:
抑郁症是一种伴随有思想和行为异常的精神障碍,已经成为全球范围内严重的公共卫生和社会问题。2017年世界卫生组织发表的报告显示,全球有超过3亿人正在被抑郁症折磨,在中国,抑郁症患者人数已达5400万人(占人口的4.2%),此发病率与全球水平相近(4.4%);在中国15-24岁的年轻人中,约有120万人患有抑郁症;中国大学生抑郁症发病率高达23.8%(与英国大学数据相近);联合国儿童基金会2015年的报告显示,农村地区青少年抑郁症发病率高于城市同龄人;以中国为例,由抑郁症引起的缺勤、医药费和丧葬费每年造成78亿美元的损失。抑郁症表现为,患有本病的人外表看上去和正常人无异,实则内心痛苦不堪,经常会心情低落、意志消沉,从开始表现的闷闷不乐到自卑、社交困难,到后期甚至有自杀的想法或行为。为此,降低自杀率的有效办法之一就是提前做好检测,及时治疗,即基于有效的抑郁症检测方法。近年来,抑郁症诊断还是依赖于传统抑郁症检测方法例如sds抑郁症自评量表,sds主要适用于具有抑郁症状的成年人,它对心理咨询门诊及精神科门诊或住院精神病人均可使用。对严重阻滞症状的抑郁病人,评定有困难。国内外学者也做了大量研究,ozdas等人基于声带抖动和声门波频谱范围探究造成抑郁症和自杀的风险因素。但是其实验样本数较少,缺少在大样本情况下的验证,且其实验样本的建立环境来自不同的通讯设备和环境。因此,对实验结果的准确性造成了一定的影响。
此外,国内外也有一些期刊文献公开了基于声音来检测抑郁症的方法,例如杨楚珺等人研究了《基于语音和面部特征的抑郁症识别技术研究》,基于语音特征部分,对访谈中记录的音频数据进行分析。数据集提供的音频特征由covarep算法从音频记录文件中提取。每0.3334s为一一个时间戳,提取的音频特征记录在每个时间戳下。根据音频特征的时序特性,建立长短期记忆网络(lstm),同时对数据集按照性别进行分类,将这些特征按照时间戳的顺序,作为长短期记忆网络(lstm)的输入,得到一个基于音频特征的预测结果。王田阳等人研究了《基于语音数据的有效特征分析及其在抑郁水平评估中的应用》,本文使用gmm建立多特征集决策系统,在多个特征集上分别训练模型,然后对预测结果进行决策融合,在男、女数据上分别得到了70%、75%的分类准确率。
此外,国内也有一些专利文献公开了基于声音来检测抑郁症的方法,例如中国专利cn106725532a公开了一种基于语音特征与机器学习的抑郁症自动评估系统和方法,基于语音处理、特征提取、机器学习技术,寻找语音特征与抑郁症之间的联系,为抑郁症的临床诊断提供客观参考依据。中国专利cn107657964a公开了一种基于声学特征和稀疏数学的抑郁症辅助检测方法及分类器,,基于语音和面部情绪共同识别的抑郁症判别;通过逆滤波器实现声门信号的估计,对语音信号采用全局分析,提取特征参数,分析特征参数的时序和分布特点,找到不同情感语音的韵律规律作为情感识别的依据;使用mfcc作为特征参数分析所要处理的语音信号,并用多组训练数据分别采集录音中的数据,建立神经网络模型进行判别。中国专利cn109171769a公开了一种应用于抑郁症检测的语音、面部特征提取方法及系统,根据能量信息法将音频数据进行特征提取,得到频谱参数和声学参数;将上述参数输入第一深度神经网络模型,得到语音深度特征数据;将视频图像进行静态特征提取,得到帧图像;将帧图像输入第二深度神经网络模型,得到面部特征数据;将视频图像进行动态特征提取,得到光流图像;将光流图像输入第三深度神经网络模型,得到面部运动特征数据;将面部特征数据和运动特征数据输入第三深度神经网络模型,得到面部深度特征数据;将语音深度特征数据和面部深度特征数据输入第四神经网络模型,得到融合数据。中国专利cn111329494a公开了一种基于语音关键词检索和语音情绪识别的抑郁症检测方法,通过采集待测人员的语音信息,可以利用从语音信息中提取到的语音特征和语音文本,对待测人员的抑郁情况进行自动识别。
虽然已经有很多尝试用神经网络来检测基于音频的depression,但现有的方法在训练时用单个音频62文件标记一个样本,最终输出总预测准确率,且单个文件没有63个预测正确的概率。本发明就是通过从单个文件进行处理,针对单个个体的独特性进行预估判断,更具有代表性。
综上所述,现有的技术存在的问题是:传统抑郁症检测方法是基于sds抑郁症自评量表和临床医生的主观判断,存在较大的误差,基于mfcc语音特征提取后没有采用bp神经网络算法二分类以及auc精确度验证,检测方法缺乏科学性,缺乏有效的客观评价指标。
技术实现要素:
1.要解决的问题
针对现有技术中的不足,本发明提供一种基于声音判别抑郁症的检测方法,在抑郁症识别率方面有很大的提升,并且方法系统可以在医院检测仪或电脑上轻松搭建,软硬件成本低廉。
2.技术方案
为了解决上述问题,本发明所采用的技术方案如下:
本发明的一种基于声音判别抑郁症的检测方法,所述基于声音判别抑郁症的检测方法基于语音特征提取并深度学习处理的抑郁症判别;通过声音要素数据化的采集及存储,对声音文件数据进行bss算法分析,对语音进行识别;使用mfcc作为特征参数分析所要处理的语音信号,转化到梅尔频率,进行倒谱分析;采用多组训练数据分别采集录音中的数据,建立卷积神经网络模型进行判别;使用bp神经网络方法对得到的测试样本数据进行分类分析;采用基于混淆矩阵的roc,auc模型评价方法,来判断基于声音判别个体患抑郁症的概率的准确性。
本发明的一种基于声音判别抑郁症的检测方法,包括以下步骤:
步骤s101、对收集的语音wav文件进行bss算法分析,再进行声音数字化处理;
步骤s102、对语音物理信息进行编码运算,倒谱(频谱包络和细节),得到mfcc的13维特征向量,供机器识别,对原始的mfcc的13维静态系数补充,转化为识别中用到的39维mfcc,分为:13静态系数+13一阶差分系数+13二阶差分系数,输入卷积神经网络模型;
步骤s103、建立卷积神经网络模型进行训练,自主提取选择特征;
步骤s104、bp网络端接收输出的特征向量,进行误差反传训练,把输入向量二分类;
步骤s105、用统计分析方法得到累计值,得出个体患抑郁症的概率;
步骤s106、利用auc和roc对二分类模型进行衡量评价,以支持准确度。
进一步,所述步骤s101具体包括:
(1)对录音进行采样,量化,编码以保证精度;
(2)明确并主要提取声音信号数字化中的3个主要指标:采样频率、量化位数、声道数声。
进一步,所述步骤s102具体包括:
(1)mfcc特征提取,包含两个关键步骤:转化到梅尔频率,然后进行倒谱分析;
(2)梅尔刻度的滤波器组在低频部分的分辨率高,跟人耳的听觉特性是相符的,这也是梅尔刻度的物理意义所在,转化到梅尔频率这一步的含义是首先对时域信号进行傅里叶变换转换到频域,然后再利用梅尔频率刻度的滤波器组对应频域信号进行切分,最后每个频率段对应一个数值;
(3)倒谱分析是对时域信号做傅里叶变换,然后取log,再进行反傅里叶变换,可以分为复倒谱、实倒谱和功率倒谱,有限选择功率倒谱。
进一步,所述步骤s102的mfcc提取特征的具体过程:
(1)预加重,频域乘以一个系数,这个系数跟频率成正相关,所以高频的幅值会有所提升;实际上就是通过了一个h(z)=1-kz-1高通滤波器,实现s′n=sn-k*sn-1;
(2)加窗,使用汉明窗对信号进行加窗处理s′n={0.54-0.46cos(2π(n-1)n-1)}*sn,相比于矩形窗函数,会减弱fft以后旁瓣大小以及频谱泄露;
(3)频域转换,将时域信号转化到频域进行后续的频率分析;
(4)使用梅尔刻度滤波器组过滤,对于fft得到的幅度谱,分别跟每一个滤波器进行频率相乘累加,得到的值即为该帧数据在在该滤波器对应频段的能量值,如果滤波器的个数为22,那么此时应该得到22个能量值;
(5)能量值取log,由于人耳对声音的感知并不是线性的,用log这种非线性关系更好描述,取完log以后才可以进行倒谱分析;
(6)离散余弦变换,进行反傅里叶变换然后通过低通滤波器获得最后的低频信号,获得最后的特征参数;(7)差分,由于语音信号是时域连续的,分帧提取的特征信息只反应了本帧语音的特性,为了使特征更能体现时域连续性,可以在特征维度增加前后帧信息的维度,常用的是一阶差分和二阶差分,将13维的mfcc转化成39维mfcc输入卷积神经网络模型。
进一步,所述步骤s103具体包括:
(1)第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段;
(2)另外一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段;
具体如下:
a.网络进行权值的初始化;
b.输入数据经过卷积层、下采样层、全连接层的向前传播得到输出值;
c.求出网络的输出值与目标值之间的误差;
d.当误差大于我们的期望值时,将误差传回网络中,依次求得全连接层,下采样层,卷积层的误差;
e.当误差等于或小于我们的期望值时,结束训练;
f.根据求得误差进行权值更新,然后在进入到b步。
进一步,所述步骤s104具体包括:
(1)网络初始化,根据系统输入输出序列(x,y)确定网络输入层节点数n、隐含层节点数l,输出层节点数m,初始化输入层、隐含层和输出层神经元之间的链接权值ωij,ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数;
(2)隐含层输出计算,根据输入变量x,输入层和隐含层间连接权值ωij以及隐含层阈值a,计算隐含层输出h,hj=f(∑ωijxi-aj)j=1,2,…,l,式中,l为隐含层节点数;f为隐含层激励函数;
(3)输出层输出计算,根据隐含层输出h,连接权值ωjk和阈值b,计算bp神经网络输出o,ok=∑hjωjk-bkk=1,2,…,m;
(4)误差计算,根据网络预测输出o和期望输出y,计算网络预测误差e,ek=yk-okk=1,2,…,m;
(5)权值更新,根据网络预测误差e更新网络连接权值ωij,ωjk,ωij=ωij+ηhi(1-hj)x(i)∑ωijekj=1,2,…,n;j=1,2,…,l;ωjk=ωjk+ηhjekj=1,2,…,l;k=1,2,…,m式中,η为学习速率;
(6)阈值更新,根据网络预测误差e更新网络节点阈值a,b,aj=aj+ηhj(1-hj)∑ωjkekj=1,2,…,l;bk=bk+ekk=1,2,…,m;
(7)判断算法迭代是否结束,若没有结束,返回(2);
(8)监督型学习分类算法定性输出分类,每帧指向是抑郁症和不是抑郁症。
进一步,所述步骤s105具体包括:
(1)测试数据提取了1000万帧进行训练,统计指向累计值;
(2)设置阈值,假设有800万帧分类指向有抑郁症的话,则可以说此人80%的概率患有抑郁症;1帧20ms,10分钟的录音,若有8分钟长度声音指向此人有抑郁症,则就说此人患有抑郁症。
进一步,所述步骤s106具体包括:
(1)基于混淆矩阵中的positive、negative、true、false的概念,称预测类别为1的为positive(阳性),预测类别为0的为negative(阴性),预测正确的为true(真),预测错误的为false(伪),对此四个概念进行组合,就产生了特有的混淆矩阵;
(2)计算truepositiverate(真阳率)、falsepositive(伪阳率),tprate=tp/(tp+fn),fprate=fp/(fp+tn),tprate的意义是所有真实类别为1的样本中,预测类别为1的比例,fprate的意义是所有真实类别为0的样本中,预测类别为1的比例;
(3)分类器起有效作用时,对于真实类别为1的样本,分类器预测为1的概率(即tprate),要大于真实类别为0而预测类别为1的概率(即fprate),即y>x;
(4)经实验设0.8作为阈值,得到一系列tprate,fprate,描点,求面积,即可得到auc值且较高,此时可说明评价基于声音判断抑郁症方法准确度较为可信。
相对比,中国专利cn109599129a公开了一种基于注意力机制和卷积神经网络的语音抑郁症识别方法,首先对语音数据进行预处理,对较长的语音数据进行分割,依据的是分割后的片段能够充分包含抑郁症相关的特征;然后对分割后每个片段提取梅尔频谱图,调整其输入到神经网络模型的频谱图尺寸大小,以便模型的训练;之后用预训练好的alexnet深度卷积神经网络进行权值的微调,提取梅尔频谱图中更高级的语音特征;然后用注意力机制算法,对片段级语音特征进行权重调整,得到句级的语音特征;最后对句级语音特征用svm分类模型进行抑郁症的分类。该专利同样通过卷积神经网络对语音数据进行特征提取,提取梅尔频谱图的进行优化调整,将语音信号的特征mel频率倒谱系数(mfccs)提取为矩阵向量特征以表征参与者自身声音的特征,后面不断更新权重以此得到最好的预测效果。但是,同时也存在很多不同之处,首先,在语音数据的预处理上,首先,我们删除每个音频文件的长无声部分,并将其余部分拼接成一个全新的。在此之后,向每个文件添加表示参与者是否健康的标签,带有0标签的是属于健康人员,带有1标签的是属于抑郁症人员,通过进行有监督的学习,最后通过softmax层将单个文件预测的概率输出,从而判断测试人员有多大可能性患有抑郁症。
3.有益效果
相比于现有技术,本发明的有益效果为:
(1)本发明与单纯临床检测或者使用sds抑郁症量表自测相比,本发明可以规避光照、行为、年龄等问题对检测带来的困扰,基于mfcc对语音特征的提取并深度学习处理,对大量的录音数据切帧分析,bp神经网络输出分类加以统计分析得到累计值,得出个体患抑郁症的概率,并利用auc和roc对二分类模型进行衡量评价,实验结果支持了准确度,证明本发明所提出的方法可以作为检测抑郁症是否存在的低成本且高效的方法;
(2)本发明基于声音判别抑郁症的检测方法在抑郁症识别率方面有很大的提升,并且方法系统可以在医院检测仪或电脑上轻松搭建,软硬件成本低廉;是一种精确、有效的抑郁症检测方法。
附图说明
以下将结合附图和实施例来对本发明的技术方案作进一步的详细描述,但是应当知道,这些附图仅是为解释目的而设计的,因此不作为本发明范围的限定。此外,除非特别指出,这些附图仅意在概念性地说明此处描述的结构构造,而不必要依比例进行绘制。
图1为本发明基于声音判别抑郁症的检测方法流程示意图;
图2为本发明基于声音判别抑郁症的检测方法的一种处理过程;
图3为本发明基于声音判别抑郁症的检测方法的另一种处理过程。
具体实施方式
下文对本发明的示例性实施例进行了详细描述。尽管这些示例性实施例被充分详细地描述以使得本领域技术人员能够实施本发明,但应当理解可实现其他实施例且可在不脱离本发明的精神和范围的情况下对本发明作各种改变。下文对本发明的实施例的更详细的描述并不用于限制所要求的本发明的范围,而仅仅为了进行举例说明且不限制对本发明的特点和特征的描述,以提出执行本发明的最佳方式,并足以使得本领域技术人员能够实施本发明。因此,本发明的范围仅由所附权利要求来限定。
如图1所示,基于声音判别抑郁症的检测方法包括以下步骤:
步骤s101、对收集的语音wav文件进行bss算法分析,再进行声音数字化处理;
所述步骤s101具体包括:
(1)对录音进行采样,量化,编码以保证精度;
(2)明确并主要提取声音信号数字化中的3个主要指标:采样频率、量化位数、声道数声。
步骤s102、对语音物理信息进行编码运算,倒谱(频谱包络和细节),得到mfcc的13维特征向量,供机器识别,对原始的mfcc的13维静态系数补充,转化为识别中用到的39维mfcc,分为:13静态系数+13一阶差分系数+13二阶差分系数,输入卷积神经网络模型;
所述步骤s012具体包括:
(1)mfcc特征提取,包含两个关键步骤:转化到梅尔频率,然后进行倒谱分析;
所述mfcc提取特征的具体过程:
(1)预加重,频域乘以一个系数,这个系数跟频率成正相关,所以高频的幅值会有所提升;实际上就是通过了一个h(z)=1-kz-1高通滤波器,实现s′n=sn-k*sn-1;
(2)加窗,使用汉明窗对信号进行加窗处理s′n={0.54-0.46cos(2π(n-1)n-1)}*sn,相比于矩形窗函数,会减弱fft以后旁瓣大小以及频谱泄露;
(3)频域转换,将时域信号转化到频域进行后续的频率分析;
(4)使用梅尔刻度滤波器组过滤,对于fft得到的幅度谱,分别跟每一个滤波器进行频率相乘累加,得到的值即为该帧数据在在该滤波器对应频段的能量值,如果滤波器的个数为22,那么此时应该得到22个能量值;
(5)能量值取log,由于人耳对声音的感知并不是线性的,用log这种非线性关系更好描述,取完log以后才可以进行倒谱分析;
(6)离散余弦变换,进行反傅里叶变换然后通过低通滤波器获得最后的低频信号,获得最后的特征参数;(7)差分,由于语音信号是时域连续的,分帧提取的特征信息只反应了本帧语音的特性,为了使特征更能体现时域连续性,可以在特征维度增加前后帧信息的维度,常用的是一阶差分和二阶差分,将13维的mfcc转化成39维mfcc输入卷积神经网络模型。
(2)梅尔刻度的滤波器组在低频部分的分辨率高,跟人耳的听觉特性是相符的,这也是梅尔刻度的物理意义所在,转化到梅尔频率这一步的含义是首先对时域信号进行傅里叶变换转换到频域,然后再利用梅尔频率刻度的滤波器组对应频域信号进行切分,最后每个频率段对应一个数值;
(3)倒谱分析是对时域信号做傅里叶变换,然后取log,再进行反傅里叶变换,可以分为复倒谱、实倒谱和功率倒谱,有限选择功率倒谱。
步骤s103、建立卷积神经网络模型进行训练,自主提取选择特征;
具体包括:
(1)第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段;
(2)另外一个阶段是,当前向传播得出的结果与预期不相符时,将误差从高层次向底层次进行传播训练的阶段,即反向传播阶段;
具体如下:
a.网络进行权值的初始化;
b.输入数据经过卷积层、下采样层、全连接层的向前传播得到输出值;
c.求出网络的输出值与目标值之间的误差;
d.当误差大于我们的期望值时,将误差传回网络中,依次求得全连接层,下采样层,卷积层的误差;
e.当误差等于或小于我们的期望值时,结束训练;
f.根据求得误差进行权值更新,然后在进入到b步。
步骤s104、bp网络端接收输出的特征向量,进行误差反传训练,把输入向量二分类;
具体包括:
(1)网络初始化,根据系统输入输出序列(x,y)确定网络输入层节点数n、隐含层节点数l,输出层节点数m,初始化输入层、隐含层和输出层神经元之间的链接权值ωij,ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数;
(2)隐含层输出计算,根据输入变量x,输入层和隐含层间连接权值ωij以及隐含层阈值a,计算隐含层输出h,hj=f(∑ωijxi-aj)j=1,2,…,l,式中,l为隐含层节点数;f为隐含层激励函数;
(3)输出层输出计算,根据隐含层输出h,连接权值ωjk和阈值b,计算bp神经网络输出o,ok=∑hjωjk-bkk=1,2,…,m;
(4)误差计算,根据网络预测输出o和期望输出y,计算网络预测误差e,ek=yk-okk=1,2,…,m;
(5)权值更新,根据网络预测误差e更新网络连接权值ωij,ωjk,ωij=ωij+ηhi(1-hj)x(i)∑ωijekj=1,2,…,n;j=1,2,…,l;ωjk=ωjk+ηhjekj=1,2,…,l;k=1,2,…,m式中,η为学习速率;
(6)阈值更新,根据网络预测误差e更新网络节点阈值a,b,aj=aj+ηhj(1-hj)∑ωjkekj=1,2,…,l;bk=bk+ekk=1,2,…,m;
(7)判断算法迭代是否结束,若没有结束,返回(2);
(8)监督型学习分类算法定性输出分类,每帧指向是抑郁症和不是抑郁症。
步骤s105、用统计分析方法得到累计值,得出个体患抑郁症的概率;
具体包括:
(1)测试数据提取了1000万帧进行训练,统计指向累计值;
(2)设置阈值,假设有800万帧分类指向有抑郁症的话,则可以说此人80%的概率患有抑郁症;1帧20ms,10分钟的录音,若有8分钟长度声音指向此人有抑郁症,则就说此人患有抑郁症。
步骤s106、利用auc和roc对二分类模型进行衡量评价,以支持准确度。
具体包括:
(1)基于混淆矩阵中的positive、negative、true、false的概念,称预测类别为1的为positive(阳性),预测类别为0的为negative(阴性),预测正确的为true(真),预测错误的为false(伪),对此四个概念进行组合,就产生了特有的混淆矩阵;
(2)计算truepositiverate(真阳率)、falsepositive(伪阳率),tprate=tp/(tp+fn),fprate=fp/(fp+tn),tprate的意义是所有真实类别为1的样本中,预测类别为1的比例,fprate的意义是所有真实类别为0的样本中,预测类别为1的比例;
(3)分类器起有效作用时,对于真实类别为1的样本,分类器预测为1的概率(即tprate),要大于真实类别为0而预测类别为1的概率(即fprate),即y>x;
(4)经实验设0.8作为阈值,得到一系列tprate,fprate,描点,求面积,即可得到auc值且较高,此时可说明评价基于声音判断抑郁症方法准确度较为可信。
实施例1
如图2和图3所示,采用oz(daic-woz)数据集中的distressanalysisinterviewcorpus-wizard作为实验数据,并采用上述的方法。
首先对daic-woz样本进行预处理,减少对后续特征提取的噪声干扰。由于原始的语音数据,在不经过预处理的情况下,可能会出现空白的间歇阶段。本发明通过灵活设置阈值,确定当前状态是否处于静音状态,如果超过阈值则选择删除,并在音频左右两端加上0.03的空白,以保证声音的稳定性,同时将每个文件标记为“抑郁”或“健康”,方便后续数据的处理;
其次,提取语音信号的mel频率倒谱系数,通过对声音文件的预加重、分帧加窗、fft变换转化、计算mel滤波等步骤,最终提取mfccs用于获取参与者独特语音属性的特征数据,这是网络模型完成正常训练至关重要的数据资料;
最后,将提取的mfccs特征输入到卷积神经网络模型中,在经过不同卷积层、全连接层以及softmax函数的分类预测,得到实际结果与目标值的误差,再使用bp算法反向传播误差值,更新网络权重和优化网络的结构,最终得到单个文件被预测为健康或者抑郁的概率值。将训练过后的模型评估测试集,得到预测的正确帧数在单个文件中的比例,得到单个文件的最终预测精度。
总的来说,总体预测精度为0.86,单个文件的平均预测精度为0.84。利用auc和roc的衡量模型预测的准确性,包括健康人被预测为健康的概率(tpr)和抑郁者被预测为抑郁的概率(fpr)。在调整相关训练参数时,模型仍具有较高的稳定性和预测精度,证明了方法的有效性。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



