
 商标分类
商标分类  商标转让
商标转让 
一种患者语音愤怒情绪识别方法和系统与流程
 2021-01-28 14:01:42|
2021-01-28 14:01:42| 344|
344| 起点商标网
起点商标网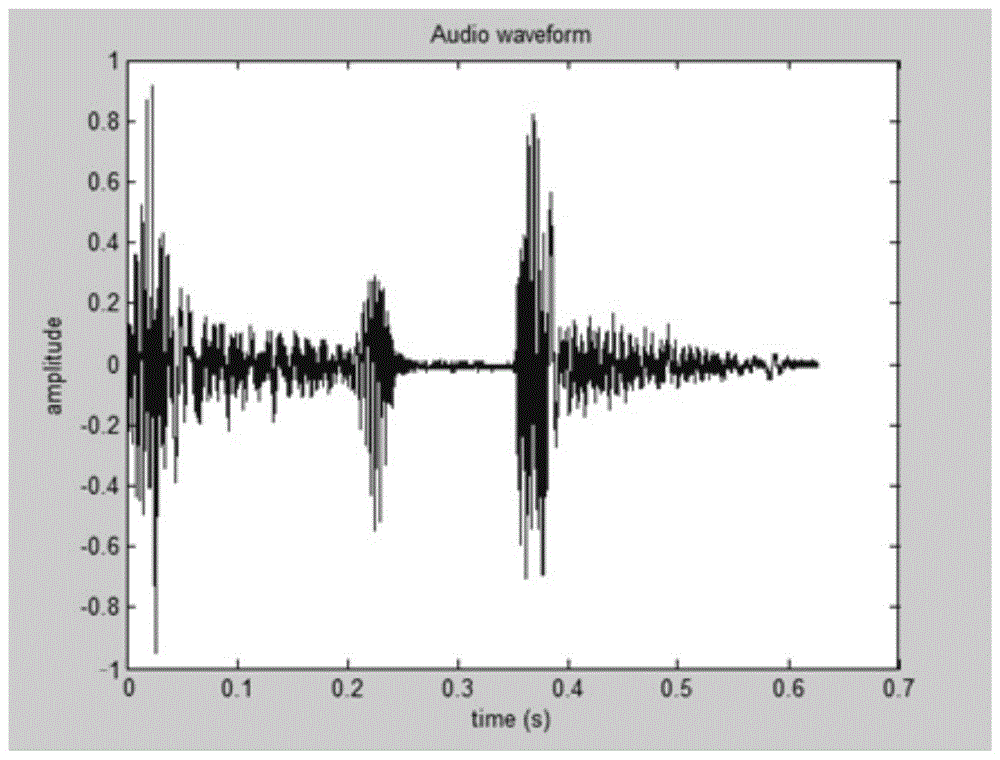
本发明涉及人工智能的技术领域,特别涉及一种患者语音愤怒情绪识别方法和系统。
背景技术:
在医院,由于患者身体不适,情绪易于激动,在与医生和护士的沟通中,患者易与医护人员发生语言或者肢体的冲突。如何预防医患冲突的发生一直是医疗系统的重要课题。
经过长期的经验积累和数据采集,科研人员发现,医患冲突产生前患者的语音中,语义信息中的词汇具有一定的情感倾向,例如“讨厌、无语、傻”,通过对语义的判断,可以识别患者的情绪,从而提前做出预警,及时避免冲突的发生。
然而,实际应用中发现,大多数情况下,患者说话都有口音或者方言,并不是标准的普通话,因此并不能通过语音准确识别语义,因此无法准确识别患者的情绪。另外,语音中的语气是表达情绪倾向的关键,在生气的状态下,有可能语音中的语义并没有情感倾向但是语气(音量和语调等)更直接表达情绪。如何充分利用语气来识别患者的情绪成为了研究的课题。
技术实现要素:
本发明的目的在于,克服语义识别患者情绪准确性不高的情况,加入了基于语气识别患者情绪的方法,将语义识别和语气识别相结合,提出了一种患者语音愤怒情绪识别方法和系统。
为了实现上述发明目的,本发明提供了以下技术方案:
一种患者语音愤怒情绪识别方法,包括以下步骤:
s1、采集患者语音录音样本;
s2、提取语音录音样本中的文本信息,并将文本信息输入预先建立的语义情绪愤怒度检测模型,输出语义愤怒概率评估参数;根据语音录音样本中的语音频谱信息,获取相应的语气愤怒概率评估参数;语气愤怒概率评估参数是根据梅尔频率倒谱系数获得;
s3、将语义愤怒概率评估参数和语气愤怒概率评估参数通过数学判别模型进行叠加,得出语音愤怒程度综合评分,数学判别模型包括高斯混合模型、贝叶斯网络或线性判别模型。
作为本发明的优选方案,步骤s2中,获取相应的语气愤怒概率评估参数包括以下步骤:
s21,提取语音录音样本的语音音量曲线的包络信号;
s22,基于过零率检测算法将包络信号分为多个音素,并消除音素中的静音,得到预处理音素;
s23,计算预处理音素的梅尔频率倒谱系数;并根据梅尔频率倒谱系数生成语气愤怒概率评估参数。
作为本发明的优选方案,步骤s23具体包括以下步骤:
s231,将预处理音素进行时频变换,得到预处理音素的fft频谱;
s232,对预处理音素的fft频谱进行加窗处理;
s233,将加窗后的fft频谱进行快速傅里叶变换后,按时间先后顺序排列,得到时间-频率-能量分布图;
s234,将时间-频率-能量分布图中的频谱转换为梅尔频谱,将梅尔频谱进行倒谱分析,获取梅尔频率倒谱系数;并根据梅尔频率倒谱系数提取特征值,组合为语气愤怒概率评估参数。
作为本发明的优选方案,步骤s234具体包括以下步骤:
a1,将时间-频率-能量分布图中的频谱转换为梅尔频谱;
a2,对梅尔频率进行取对数计算,得到梅尔频率的对数参数;
a3,将对数参数做逆变换,并取逆变换后的系数为梅尔频率倒谱系数;
a4,从梅尔频率倒谱系数中提取40个特征值;从色度矢量中提取128个特征值;从光谱对比特征值中提取19个特征值,从色调质心特征中提取了6个特征值;
a5、将步骤a4中提取的特征拼接为193维度的向量,作为语气愤怒概率评估参数。
作为本发明的优选方案,步骤s234中将时间-频率-能量分布图中的频谱转换为梅尔频谱的计算公式为:
其中,f是时间-频率-能量分布图中的频率,mel(f)是时间-频率-能量分布图中的频率相应的梅尔频率。
作为本发明的优选方案,步骤s2中获取语义愤怒概率评估参数具体包括以下步骤:
k21,提取语音录音样本中的文本信息;
k22,利用汉语分词工具将文本信息进行分词,得到文本信息的多个词组;
k23,将文本信息的多个词组输入bert模型或者ernie2模型,得到对话句子向量;
k24,对对话句子向量进行词嵌入向量化,得到单词向量;
k25,将单词向量输入到语义情绪愤怒度检测模型,输出语义愤怒概率评估参数,语义情绪愤怒度检测模型是利用深度神经网络对单词向量和预先设置的语气极性判别初始化值进行训练得到的。
作为本发明的优选方案,步骤k25中,语义情绪愤怒度检测模型的训练过程包括:
将单词向量输入深度神经网络,在深度神经网络最后一层神经元输出的参数中标记情绪标记,当情绪标记与预先设置的语气极性判别初始化值不一样时,利用反向传播算法对深度神经网络的权重矩阵进行修订,情绪标记包括极愤怒、愤怒、中性、高兴、很高兴。
作为本发明的优选方案,步骤s3中的数学判别模型采用高斯混合模型,步骤s3具体包括以下步骤:
s31,将语义愤怒概率评估参数代入高斯分布概率密度函数,得到语义评估参数的高斯分布;
s32,将语气愤怒概率评估参数代入高斯分布概率密度函数,得到语气评估参数的高斯分布;
s33,根据先验概率设置语义评估参数的高斯分布的权重值以及语气评估参数的高斯分布的权重值;
s34,根据语义评估参数的高斯分布、语义评估参数的高斯分布的权重值、语气评估参数的高斯分布和语气评估参数的高斯分布的权重值,计算语音的愤怒程度的综合评分。
作为本发明的优选方案,计算语音的愤怒程度的综合评分的计算公式为:
其中,k为高斯分布的个数,i为高斯分布的编号,μi是服从正态分布的随机变量的均值,
基于相同的构思,还提出了一种患者语音愤怒情绪识别系统,包括语音获取设备,处理器和显示设备,
语音获取设备用于采集医院患者语音录音样本,并将语音录音样本输出到处理器;
处理器接收语音录音样本,并且处理器中的执行指令可以执行权利要求1-9任一项的方法,输出语音愤怒程度综合评分;
显示设备接收并显示语音愤怒程度综合评分。
与现有技术相比,本发明的有益效果:
1、本发明的方法分别通过语音语义和语音语气识别患者的情绪,并且将识别结果通过高斯混合模型进行叠加,得出语音的愤怒程度的综合评分。通过该得分,可以及时准确的获取医院场景下患方的情绪,进行及时有效的处理,避免冲突的发生。
2、本发明方法中,采用语音语气识别患者的情绪时,对语音进行了梅尔频率转换,并对梅尔频率进行倒谱分析,该方法更有利于语音语气特征的提取,准确性较高。
3、本发明中,在语气愤怒概率评估参数的获取过程中,不仅提取了40个梅尔频率倒谱系数特征值,还从色度矢量中提取128个特征值;从光谱对比特征值中提取19个特征值,色调质心特征中提取了6个特征值,将上述多种类型的特征值进行了组合,得到了组合后的语气愤怒概率评估参数,使得在评价语气时综合考虑了语气、语调、停顿和连续变化,方案更加细化,评估结果更接近于真实情况。
附图说明
图1为本发明实施例1中的一种患者语音愤怒情绪识别方法的流程图;
图2为本发明实施例1中的词嵌入向量化实例数据;
图3为本发明实施例1中的多层深度神经网络dnn结构图;
图4为本发明实施例1中原始语音震荡信号;
图5为本发明实施例1中的原始语音震荡信号相应的包络信号;
图6为本发明实施例1中的计算mel频率倒谱系数的流程图;
图7为本发明实施例1中色度矢量计算步骤流程图;
图8为本发明实施例1中光谱对比特征值获取步骤流程图;
图9为本发明实施例1中色调质心特征的计算方法计算步骤流程图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
实施例1
一种患者语音愤怒情绪识别方法,流程图如图1所示,主要包括以下步骤:
s1、采集患者语音录音样本。
s2、提取语音录音样本中的文本信息,并将文本信息进行预处理后输入预先建立的语义情绪愤怒度检测模型,输出语义愤怒概率评估参数;根据语音录音样本中的语音频谱信息,获取相应的语气愤怒概率评估参数。
s3、将语义愤怒概率评估参数和语气愤怒概率评估参数通过高斯混合模型进行叠加,得出语音的愤怒程度综合评分。
步骤s1中,录音样本特征包括但不限于单人诉求,多人对话,以及包含的背景声音的门诊大厅,抢救室等封闭空间的整体音频。在医院语音录音的样本中截取500句冲突语音和500句中性语音(即采样语音),由人工和科大讯飞听见语音转化系统(https://www.iflyrec.com/)同时进行语音听写转换,如果出现转换结果不一致的情况,以人工转化的结果作为标准结果。并且对不一致的地方利用文本差异标记方法进行标记,作为中文计算机语音识别系统的弱项,留待进一步强化学习。转换一致的文本信息作为语义情绪愤怒度检测模型的训练样本或测试样本。
作为优选方案,s2中获取语义愤怒概率评估参数具体包括以下步骤:
①利用开源的jieba(结巴)或thunlp(清华自然语言处理系统)等汉语分词工具,对采集到的文本内容进行分词。
②将情感倾向分为正面,负面及中性三种类别,利用传统方法当中的基于通用性语气倾向词典对数据当中的语气极性判别进行初始化的编著。
③基于①的分词结果,利用最新的bert或者ernie2等模型(由google或者baidu提供)进行语句向量化。提取语义特征形成特定对话句子向量。
④利用bert模型当中的embedding功能,对整个句子进行词嵌入向量化。也就是说,将特定单词转化为一个由n个元素形成的向量。
词嵌入向量化的基本操作为:其具体方法为利用google的双向编码器模型获得12层或者更多层的转化器令牌,然后将最后3-4层获得的向量化的单词相加,最后获得该单词的向量化表示。
例如:“你们为什么让我等这么久?”这样的一个单词经过上述向量化的变化之后就可以变成一个矩阵,从而进入下一步的机器学习,转换后的数据如图2所示。
⑤利用深度神经网络dnn对④获得的矩阵和②获得的训练集进行训练。训练的具体步骤如下:
首先,通过步骤④获得输入矩阵x,记x的尺寸维度为m*n,其中,m可以表示为一段话的单词数,n表示每个单词向量化之后的长度。
其次,随机生成一个权重矩阵w和残差矩阵b,我们可以把这个权重和残差矩阵看成1层神经元,单层神经元z的计算可以由公式(1)表示,
z[l]=w[l]x[l]+b[l](1)
对于多层神经网络,神经元z可以用线性模型表示为公式(2):
z[l]=w[l]x[l-1]+b[l](2)
其中,w是权重矩阵,b是残差矩阵,x单词向量矩阵,式中的[l-1]表示第1层到第l层的层数。
加上一个激活函数,可得:
x[l]=g(z[l]x[l-1]+b[l])(3)
其中g()为激活函数,可以是sigmoid,tanh或relu等。公式中的[l-1]表示第1层到第l层。只要给出输入矩阵x,由公式(4)和(5)可以逐层计算出x的向量x[l],
x[l]=g(z[l])=g(w[l]x[l-1]+b[l])(4)
a[0]=x(5)
公式(5)中,将输入的单词向量矩阵x定义为初始层向量a[0]。最后,输出最后一层的x值,深度神经网络dnn结构图,如图3所示,输出最后一层的x值可以针对5个情绪标记,分别标记为极愤怒,愤怒,中性,高兴,很高兴5个等级。如果该等级与实际文本标记的情绪不一样,则利用反向传播算法对于权重矩阵w进行修订。
反向传播算法的基本原理是:
根据输入文本转化而成的单词向量矩阵x和权重矩阵w计算所得的预测值
对于m个样本集合,可以计算交叉信息熵,交叉信息熵j(x,y;w,b)计算公式为公式(7):
公式中,x表示样本,y表示预测值,w,b分别是向前传播算法输入的权重矩阵和残差矩阵,m表示第m个样本,l表示第l层的参数,a[l](m)是第m个样本,在第l层的向量。如果上述计算结果y和预测值y不一样,就可以按照某个误差权重α,对w和b进行修正,修正之后可以获得新的权重矩阵w和残差矩阵b:
其中,w,b分别是向前传播算法输入的权重矩阵和残差矩阵,
根据数学推导,w和b的变化率可以由以下公式计算:
其中,
⑥给出基于文本语言的愤怒概率评估。
作为优选方案,步骤s2中获取语气愤怒概率评估参数主要步骤如下:
①获取语音的包络信号。包络信号是指:将任一平稳窄带高斯随机过程x(t)表示为标准正态振荡的公式:
x(t)=a(t)cos(ωt+ph(t))(12)
其中ω是窄带随机过程的载波频率;a(t)和ph(t)是x(t)的包络和相位。包络即随机过程的振幅随着时间变化的曲线。对于音频信号来说,包络可以理解为语音音量变化的曲线。原始语音震荡信号如图4所示,相应的包络信号如图5所示。
包络信号的计算方法为:
假设有时域信号k(t),首先通过离散傅里叶变换dft将时域信号转化为频域信号k(n):
k(n)=dft(k(t))(13)
其中k(n)可以拆分为两部分频域的乘积,其中h(n)为低频部分,e(n)为高频部分:
k(n)=h(n)*e(n)(14)
相应的,将公式(14)的时域公式表示为:
k(t)=h(t)*e(t)(15)
对公式(14)两边取对数,然后进行反傅里叶变换,则有:
idft(log(x(n)))=idft(log(h(n)))+idft(log(e(n)))(16)
此时获得的时域信号如下:
x′(n)=h′(n)+e′(n)(17)
令e′(n)=0,就获得的h′(n),h′(n)就是包络部分对应的时域信号。
②获得语音包络信号后,找出语音包络信号的起始点和结束点。其基本工作原理是消除信号开始和结束时的静音。对于该方法使用过零率(zero-crossingrate,zcr)的检测算法程序,可以将语音分为独立的音素(phones)。zcr之间的部分认为是静音。对汉语来讲,可以认为是两个字符之间的间隔。
③计算计算梅尔频率倒谱系数(mel-frequencycepstralcoefficients,mfcc)
梅尔频率倒谱系数计算方法如下:
a:通过前述步骤②获得的音素起始点和结束点对语音进行分帧,对每一帧的信息进行时频变换,得到每一帧的fft频谱。
b:对fft频谱进行加窗处理。
窗函数本质上就是给定区间内为常数而在区间外为0的函数,特定帧的声波函数乘以窗函数可以过滤掉傅里叶变换主峰之外的部分。由于语音之外的振动可以认为是随机噪音,因此,我们在完成分帧之后可以采用窗函数来滤掉每一帧除开主峰之外的随机噪音,这个过程称为加窗。
研究发现,在加窗的时候采用高斯(gaussianwindows)窗和汉明窗(hammingwindow)的时候对于窗内噪音过滤效果较好。所以,将原fft频谱函数乘以高斯窗函数或汉明窗函数。
高斯窗函数为:
海明窗函数为:
上面公式(18)和(19)中,n表示窗的时间序数,n的取值范围0≤n≤n-1表示一个特定周期。
c:将加窗后的各帧频谱通过快速傅里叶变换,并按照时间先后顺序排列起来,得到时间-频率-能量分布图。很直观的表现出语音信号随时间的频率中心的变化。
d:mel频率分析(mel-frequencyanalysis)
mfcc考虑到了人类听觉特征,先将时间-频率-能量分布图中的线性自然频谱转换为体现人类听觉特性的mel频谱中。将普通频谱转化到mel频谱的公式为:
其中,f是所述时间-频率-能量分布图中的频率,mel(f)是所述时间-频率-能量分布图中的频率相应的梅尔频率。
e:获取mel频率倒谱系数(mel-frequencycepstralcoefficients)
在mel频谱上进行倒谱分析(取对数;做逆变换,逆变换通过dct离散余弦变换实现;取dct后的系数作为mfcc系数),采用mfcc提取40个特征值,利用类似原理,可以从chromavectors(色度矢量)提取128个特征值,spectralcontrastfeatures(光谱对比特征值)提取19个特征值、tonalcentroidfeatures(色调质心特征)提取6个特征值。将上述特征值拼接为193维度的向量,代表语音特征,将提取的语音特征作为语气愤怒概率评估参数。计算梅尔频率到谱系数的流程图如图6所示。
其中,色度矢量的获取方法的参考文献是:peeters,geoffroy."musicalkeyestimationofaudiosignalbasedonhiddenmarkovmodelingofchromavectors."proceedingsoftheinternationalconferenceondigitalaudioeffects(dafx).2006。如图7所示,音频信号首先进行预处理(预处理包括静音检测、正弦分析、重新合成、调谐),将预处理后的数据进行fft变换,得到频域音高类向量,将频域音高类向量映射到新高音符,再进行随着时间推移的平滑处理,最后映射到色度,得到色度矢量。
光谱对比特征值的计算方法参考文献:jiang,dan-ning,etal."musictypeclassificationbyspectralcontrastfeature."proceedings.ieeeinternationalconferenceonmultimediaandexpo.vol.1.ieee,2002。如图8所示,光谱对比特征值获取的步骤包括:对语音进行数字采样后,对获取的采样数据进行fft变换,采样数据从时域转换到频域,然后对频域采样数据进行八度音阶滤波,将滤波后的数据进行log函数计算,最后通过k-l变换(karhunen-loevetransform)得到光谱对比特征值。
色调质心特征的计算方法参考文献:harte,christopher,marksandler,andmartingasser."detectingharmonicchangeinmusicalaudio."proceedingsofthe1stacmworkshoponaudioandmusiccomputingmultimedia.2006。如图9所示,色调质心特征的获取步骤包括:对音频数据进行常数-q变换,得到log变换后的频谱向量,然后对log变换后的频谱向量基于12位调谐色度图进行变换,得到音高类向量,最后对音高类向量进行色调质心变换,得到6d质心向量。
步骤s3主要是将单独的文本和单独的语气判断出来的愤怒程度通过特定数学模型进行叠加得出发言人当时愤怒程度的综合评分。特定数学模型包含但不限于高斯混合模型,贝叶斯网络,各种线性判别模型等生成模型和判别模型。
作为优选方案,将单独的文本和单独的语气判断出来的愤怒程度通过高斯混合模型(gaussianmixturemodel,gmm)进行叠加得出发言人当时愤怒程度的综合评分。具体实现步骤如下:
①将语义愤怒概率评估参数代入高斯分布概率密度函数,得到语义评估参数的高斯分布;
②将语气愤怒概率评估参数代入所述高斯分布概率密度函数,得到语气评估参数的高斯分布;
③根据先验概率设置语义评估参数的高斯分布的权重值并设置语气评估参数的高斯分布的权重值;
④根据语义评估参数的高斯分布、语义评估参数的高斯分布的权重值、语气评估参数的高斯分布和语气评估参数的高斯分布的权重值,计算语音的愤怒程度的综合评分。
采用的高斯分布概率密度函数公式如下:
其中,参数μ为均值,σ表示标准差,e为自然对数,π为圆周率。
假设有k个高斯分布,那么特定情况p(x)出现的概率为:
其中,k为高斯分布的个数,i为高斯分布的编号,μi是服从正态分布的随机变量的均值,
例如通过文本发现愤怒概率为p(文本),通过语音发现愤怒概率为p(语音),根据医生经验或者统计特定时间范围内医院某个特定地点出现的愤怒情况统计获得此地发生愤怒现象的概率为p,那么我们可以根据贝叶斯算法获得:
p(愤怒|语音特征)=p(愤怒)*p(语音特征|愤怒)/[p(文本)*p(语音特征|文本)+p(愤怒)*p(语音特征|愤怒)]
也就是可以得到出现特定语音特征时的愤怒值。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



