
 商标分类
商标分类  商标转让
商标转让 
一种针对大功率目标信号的语音提取方法与流程
 2021-01-28 14:01:57|
2021-01-28 14:01:57| 278|
278| 起点商标网
起点商标网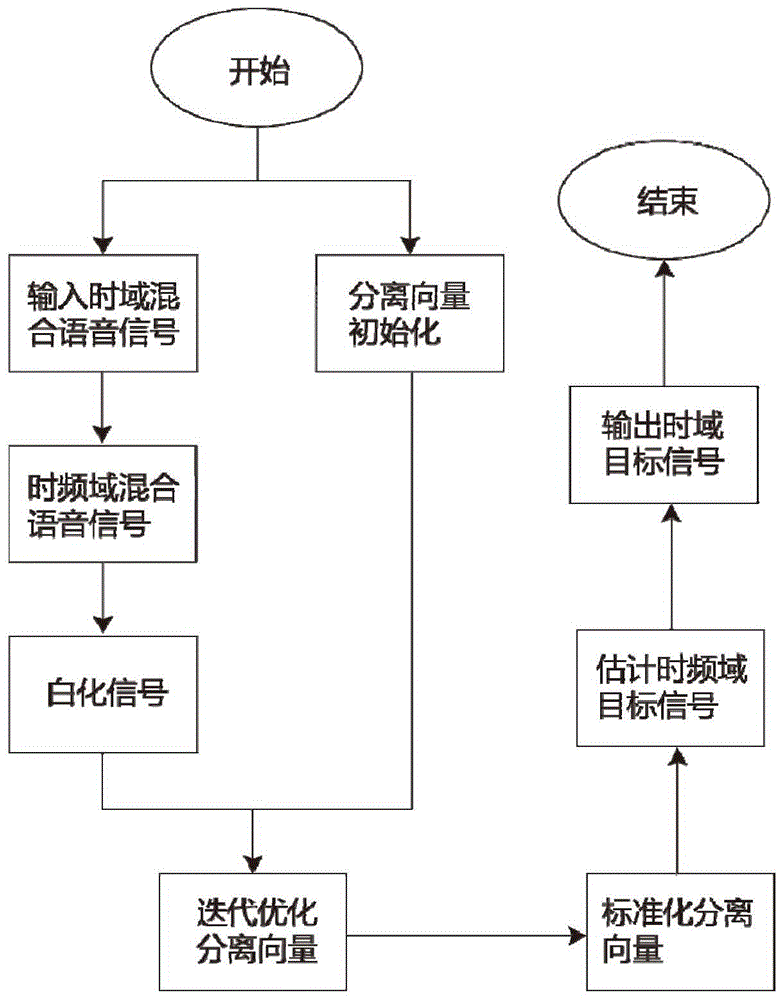
本发明涉及语音处理的技术领域,尤其是涉及一种针对大功率目标语音的提取方法。
背景技术:
语音分离技术可以从多个声源的混合信号中分离出原始的声源信号,是语音信号处理领域的一项重要任务,在智能家居系统、视频会议系统以及语音识别系统等多种应用场景下都发挥了重要作用。
在多通道的语音信号处理方案中,独立矢量分析(iva)以及它的变体被认为是最先进的分离方法,它对所有的声源信号都进行了完全的分离。然而,在很多的应用场景中,只需要估计出某一个特定话者的语音信号。通常的语音分离方法对那些不需要的声源信号也进行了估计,并且还要采取额外的步骤从所有分离出的信号当中挑选出目标的源信号,这样的做法浪费计算量且增加了系统的复杂程度。所以这种情况下,采用语音提取方法比起语音分离更加的高效。
已有的语音提取方法都需要对目标信号以及干扰信号作严格的假定,或是对源信号混合方式有先验的知识,这在很大程度上限制了此类方法在实际中的应用。如何高效、准确地针对目标信号进行提取,即使在很少的限制条件下也能保证算法的性能,是一个值得关注的技术问题。
技术实现要素:
为了解决上述技术问题,本发明提出了一种针对大功率目标信号的语音提取方法,该方法能准确、高效地对目标信号进行提取,并且估计出的目标信号有良好的效果。
本发明采用的技术方案为:
一种针对大功率目标信号的语音提取方法,包括如下步骤:
步骤1,获取待处理混合语音的时频域信号;
步骤2,初始化各频带的分离向量;将步骤1得到的混合语音时频域信号进行白化预处理,然后对所有频带的分离向量进行联合优化,收敛后对分离向量进行标准化,得到最终的目标语音分离向量并由此估计出目标语音的时频域信号;
步骤3,将步骤2估计出的目标语音时频域信号通过短时傅里叶逆变换,得到时域的目标语音信号。
进一步地,所述步骤1的具体步骤为:利用信号采集系统获取待处理混合语音的时域信号,对时域信号做短时傅里叶变换,得到待处理混合语音的时频域信号。
进一步地,所述步骤2中,初始化各频带的分离向量采用的是独热向量,向量的第一个元素是1,其余元素是0。
进一步地,所述步骤2中,进行白化预处理的具体步骤为:(1)根据各个频带的混合语音时频域信号计算对应频带的协方差矩阵;(2)将各频带的所述协方差矩阵进行特征值分解,获取按降序排列的由特征向量构成的特征向量矩阵,以及按降序排列的特征值作为对角元素构成的特征值对角矩阵;(3)根据所述特征向量矩阵以及特征值对角矩阵得到各频带白化的混合语音信号。
进一步地,所述步骤2中,对所有频带的分离向量进行联合优化的具体步骤为:(1)根据源信号模型选取得分函数,从而获得代价函数;(2)根据所述代价函数,利用快速不动点迭代方法得到分离向量的迭代更新规则;(3)使用所述迭代更新规则进行迭代直到收敛,得到各频带优化后的分离向量。
进一步地,所述步骤2中,对分离向量进行标准化的具体步骤为:(1)根据各个频带的协方差矩阵以及各频带优化后的分离向量,得到各频带混合向量;(2)根据各频带混合向量,对各频带优化后的分离向量进行标准化,得到各个频带最终的目标语音分离向量。
本发明针对大功率的目标语音信号,实现了一种高效的语音提取方法。该方法能够有针对性地对多个传声器实现多通道环境下的目标信号进行提取,有利于节省计算量,提取准确率高,同时保证了恢复出来的源信号的效果。
附图说明
图1为本发明的语音提取方法的流程示意图;
图2为本发明所适用的一个场景示意图;
图3是现有的ilrma方法、five方法、ogive-w方法与本发明方法在不同声源个数情况下的sir提升值对比图。
图4是现有的five方法、ogive-w方法与本发明方法在不同声源个数情况下对目标信号正确提取率的对比图。
具体实施方式
本发明针对大功率的目标语音提取方法主要包括以下几个部分:
1、信号获取
1)将两个以上的传声器以线阵列的形式布放来采集声源的信号,然后通过ad转换将模拟信号转换为数字信号。
2)对信号做短时傅里叶变换
若第m个传声器采集到的混合信号为xm(t),对其进行短时傅里叶变换,变换到时-频域,忽略时间帧数指标n,第k个频带的信号表示为
3)对信号进行白化预处理
对全部k个频带,计算xk的协方差矩阵
其中,
2、对目标信号的分离向量进行优化
1)基于负熵的代价函数
若第n个源信号矢量表示为sn,相应的估计信号表示为yn,为了使各估计信号之间尽可能地独立,采用负熵来作为独立性的度量,所以代价函数可以写为如下形式:
其中n{yn}代表变量yn的负熵,h{yn}代表变量yn的熵,
其中
上式是对n个源信号非高斯性的求和,所以可以通过寻找单个变量的非高斯性极大值来对某一个源信号进行提取。在很多实际的运用场景,通常目标源信号比起其他干扰信号有更高的功率(例如在所有说话人中目标说话人距离麦克风阵列最近,或者是在嘈杂的环境中目标说话人有意地提高音量),所以在本实施例中将大功率源信号最为目标信号进行提取。经过了白化之后,针对大功率源信号进行提取的代价函数为:
2)对各频带分离向量进行初始化
对所有的k=1,2,…,k,将分离向量
下标o表示初始值,其中e1是独热向量(one-hotvector),向量的第一个元素为1,其余元素为0.由于经过了白化,白化后的第一个主成分
3)快速不动点迭代
最小化代价函数的解需要满足使代价函数的一阶导数为零的条件,将代价函数对分离向量进行求导,并利用泰勒展式做近似得到:
下标o表示当前次迭代的参数。分别用g′(·)和g″(·)表示g(·)的一阶和二阶导数,可以进一步计算出(8)式右边的项,
上式最后的等号是由于常用的圆周对称假设
在每一步迭代之后,都需要对分离向量进行归一化:
4)源信号分布模型
根据不同的源信号先验分布模型,g有不同的形式。本发明实施例中采用了三种不同的分布:一种是常用的圆周对称拉普拉斯分布(ssl),相应地
3、对分离向量进行标准化
通过多次的迭代,最后将得到各频带收敛后的分离向量的解。为了解决恢复出的信号幅度不确定性,需要对收敛后得到的分离向量再进行标准化。根据源信号之间正交的假设,混合向量
然后取
4、重建目标信号
1)估计时-频域目标信号
本实施例的目标是估计出干净的目标语音信号,各个频带的目标信号可以通过如下的式子来计算:
2)重建时域目标信号
最终,将时频域的目标信号通过短时逆傅里叶变换变换到时域,恢复出时域的目标源信号。
实施例
下面结合附图,对本发明实施例中的技术方案进行清楚、完整地描述。
1、测试样本及客观评价标准
本实施例用imagemodel(j.b.allenandd.a.berkley,“imagemethodforefficientlysimulatingsmall-roomacoustics,”j.acoust.soc.am.,vol.65,pp.943–950,1979.)来生成混合信号,仿真房间的尺寸为7m×5m×2.75m,混响时间为200ms。参见图2,本实施例中有6个可供使用的扬声器作为声源,6个传声器以间隔为1.25cm排列成线阵列,距地面1.5m,阵列中心的位置在[4,1,1.5](m)处。扬声器与阵列处于同一水平面,干扰声源分布在距离阵列中心为1m的圆周上,目标声源(声源1)距离阵列中心0.3m,目标源比干扰源的功率高大约10db。干净语音信号选取自timit语音库,约10s长,信号采样率为16khz。本实施例中声源数目n从2变化到6,对每个n的取值,相应地选取附图2中的声源1到声源n发出信号,以及传声器1到传声器n接收信号,生成30段不同的混合语音样本。
本实施例采用sir(signal-to-interferenceratio)作为客观评价标准,其描述了估计信号中目标语音相对其他干扰信号的信干比。
2、参数设置
1)信号的短时傅里叶变换
短时傅里叶变换使用汉宁窗,窗长为2048,帧移为512。
2)源信号先验分布模型
在本发明的提取方法中,源信号分别选取了圆周对称拉普拉斯分布、多维广义高斯分布和多维t分布这三种模型,其中多维t分布模型的自由度参数v取值为4.
3)成功提取的判定
本实施例中将提取算法处理后的输出sir值(sir_out)与输入的混合信号的sir值(sir_in)相减,得到经过算法处理后的sir提升值(sir_imp),即sir_imp=sir_out-sir_in。若sir_imp>0,则认为提取成功。
3、方法的具体实现流程
参见附图1,输入时域混合语音做短时傅里叶变换得到时频谱并对其进行白化预处理,再按照(7)式对各频带的分离向量进行初始化。使用公式(12)(13)进行迭代优化。迭代收敛之后采用式(15)进行标准化得到最终的目标语音分离向量
为了体现本发明方法的性能,本实施例对当下最先进的ilrma方法(d.kitamuraetal.,“determinedblindsourceseparationunifyingindependentvectoranalysisandnonnegativematrixfactorization,”ieee/acmtrans.,audio,speech,lang.process.,vol.24,no.9,pp.1622-1637,2016.)和现有的其他两种提取方法five(r.scheiblerandn.ono,“fastindependentvectorextractionbyiterativesinrmaximization,”icassp.pp.601-605,ieee,2020.)、ogive-w(z.koldovskyandp.tichavsky,“gradientalgorithmsforcomplexnon-gaussianindependentcomponent/vectorextraction,questionofconvergence,”ieeetrans.signalprocess.,vol.67,no.4,pp.1050-1064,2018.)与本发明的方法进行对比,图3给出了只考虑正确提取的情况下,本发明中采用不同源信号模型的提取方法与ilrma方法、five方法、ogive-w方法处理后的平均sir_imp的对比图,图4给出了各提取方法的成功率,图中“fastive-ssl”表示采用圆周对称超高斯分布模型的本发明提取方法,“fastive-gg”表示采用多维广义高斯分布模型的本发明提取方法,“fastive-t”表示采用多维t分布模型的本发明提取方法。从图3的sir提升值可以看出,本发明的提取方法相比于其他两种提取方法(five和ogive-w)有更好的提取效果。从图4的正确提取率可以看出,本发明的提取方法能够保证对目标信号提取的准确率。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



