
 商标分类
商标分类  商标转让
商标转让 
一种基于卷积神经网络的数字音频篡改被动检测方法与流程
 2021-01-28 13:01:46|
2021-01-28 13:01:46| 294|
294| 起点商标网
起点商标网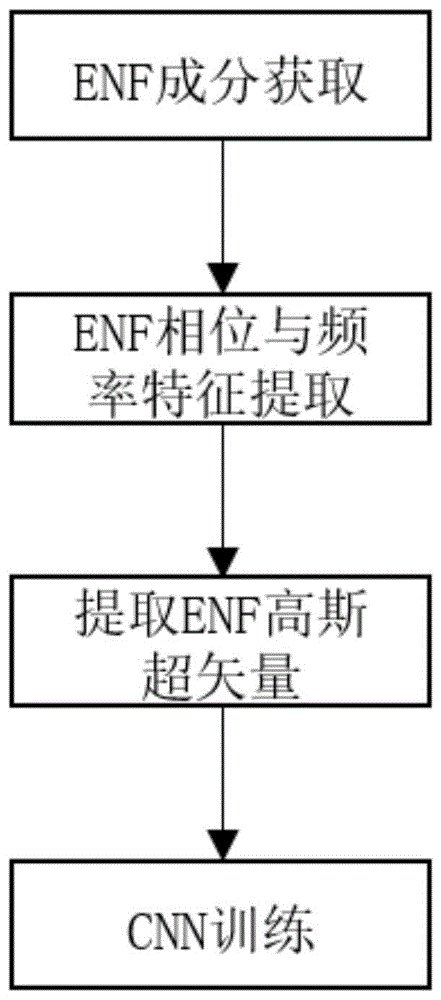
本发明属于数字音频篡改检测技术领域,特别指一种基于卷积神经网络的数字音频篡改被动检测方法。
背景技术:
随着数字音频技术的飞速进步,人们能够很方便地采集到数字音频信号,但同时也可利用许多音频处理软件轻易地对其进行后期编辑与修改。若将这种有意或无意篡改的数字音频应用到司法取证等重要场合,将很有可能引发一些不良的社会问题,因此,对数字音频篡改检测的研究有着非常重要的意义。
数字音频篡改被动检测是无需添加任何信息,仅靠音频自身特征来对数字音频的真实性和完整性进行分析判别的技术,对于复杂的取证环境具有现实意义。当录音设备采用电网供电时,录制的音频文件中残留有电网频率(electircnetworkfrequency,enf)信号。当数字音频被篡改时这种enf信号也会随着篡改操作发生变化,于是利用enf信号的唯一性与稳定性进行音频篡改被动检测有了两种研究思路,第一是将音频中提取出的enf信号与供电部门的enf数据库进行对比,这种方法实现难度高,代价大;第二是提取enf信号中的某些特征,进行一致性与规律性分析。目前利用enf信号进行音频篡改取证的研究方法主要是利用传统机器学习方法对enf信号的相位变化、相位的不连续性、瞬时频率突变等特征进行分类,从而达到篡改检测的目的,。
目前存在的数字音频检测方法中,大多是对相应特征设置阈值门限进行检测或采用机器学习方法进行分类。这些方法往往存在经验成分过多或是对于某一种篡改方法针对性太强和识别率不够的问题。
近年来,随着机器学习算法性能的提升和计算机存储、计算能力的提高,深度神经网络(deepneuralnetwork,dnn)被应用到音频篡改检测领域中。在深度神经网络中可以dnn深层次的非线性变换更好的拟合音频篡改的特征,实现自动学习与检测,具有识别率高的优点。因此,本发明采用卷积神经网络对enf高斯均值超矢量进行训练,利用较少的计算量充分学习其中的隐含信息,然后使用注意力机制attention的方法自动学习卷积神经网络中输出的信息的权重,确定其中对数字音频篡改检测有用的信息,减小冗杂信息,提升数字音频篡改检测系统的性能。
技术实现要素:
本发明的上述技术问题主要是通过下述技术方案得以解决的:
一种基于卷积神经网络的数字音频篡改被动检测方法,其特征在于,一种基于卷积神经网络的数字音频篡改被动检测方法,其特征在于,包括
步骤1、对原始语音信号进行处理得到电网频率(enf)成分;
步骤2、根据步骤1得到的enf成分,提取基于dft1的相位谱拟合特征参数pcoe与相位波动特征f1,基于hilbert变换的频率谱拟合特征参数fcoe,获得组合特征x=[fcoe,pcoe,f1];
步骤3、使用步骤2中的组合特征x训练通用背景模型(ubm),对包含篡改语音和未篡改语音的待训练语音信号按步骤2提取出组合特征x,对ubm模型参数通过自适应map来更新模型参数;得到待训练语音的均值矩阵作为enf高斯均值超矢量;
步骤4、采用卷积神经网络cnn对步骤3中得到的enf高斯均值超矢量进行训练,使用注意力机制attention对cnn卷积层的输出特征进行特征选择以去除对分类无效的特征,使用sofmax层进行篡改检测。
在上述的一种基于卷积神经网络的数字音频篡改被动检测方法,步骤1是对原始语音信号依次进行下采样、窄带滤波得到enf成分;具体包括:
步骤1.1、下采样:在保证提取enf精度的同时,有效减少计算量;将信号重采样频率定为1000hz或者1200hz;
步骤1.2、窄带滤波:为了防止相位延时得到理想的窄带信号,使用10000阶的线性零相位fir滤波器进行窄带滤波,中心频率在enf标准(50hz或60hz)处,带宽为0.6hz,通带波纹0.5db,阻带衰减为100db。
在上述的一种基于卷积神经网络的数字音频篡改被动检测方法,步骤2中,提取特征的具体方法包括:
步骤2.1、计算enf信号xenfc[n]在点n处的近似一阶导数
x′enfc[n]=fd(xenfc[n]-xenfc[n-1])(1)
其中fd(*)表示近似求导操作,xenfc[n]表示enf成分第n个点的值;
步骤2.2、对x′enfc[n]进行分帧加窗,帧长为10个标准enf频率周期
x′n[n]=x′enfc[n]w(n)(2)
其中汉宁窗
步骤2.3、每帧信号x′n[n]与xenfc[n]分别执行n点离散傅里叶变换(dft)得到x′(k)、x(k),根据|x′(k)|的峰值点的整数索引kpeak估计频率
其中dft0[kpeak]=x(kpeak),dft1[kpeak]=f(kpeak)|x′(kpeak)|,f(kpeak)是一个尺度系数;
其中ndft表示离散傅里叶变换点数,k为峰值点索引;
步骤2.4、计算xenfc的相位
步骤2.5、计算x′enfc的相位
其中
步骤2.6、步骤2.5中
步骤2.7、将步骤2.5中得到的x′enfc的相位
其中
步骤2.8、对信号xenfc[n]进行离散hilbert变换;首先得到xenfc[n]的解析函数
x(a)enfc[n]=xenfc[n]+i*h{xenfc[n]}(7)
其中
步骤2.9、对步骤2.8中的f[n]进行低通滤波,去除震荡;使用五阶椭圆滤波器iir滤波器;中心频率为enf标准频率,带宽为20hz,通带波纹为0.5hz,阻带衰减为64hz;由于频率估计的边界效应,去掉f[n]头尾各大约1s,最后得到enf成分的瞬时频率估计fhil;
步骤2.10、对步骤2.4中得到的相位特征
用sumofsines来拟合相位特征,其形式为:
其中a是振幅,b是频率,c是每个正弦波项的相位常量,n指这个序列的数量,1≤n≤9,x=[1,2,…,len(φ)],len(φ)为
用gaussian来拟合瞬时频率特征,其形式为:
其中a是峰值幅度,b是峰值所在位置,c与峰的旁瓣有关,n指拟合了多少个峰值,1≤n≤8,x=[1,2,…,len(f)],len(f)为fhil的长度,y为瞬时频率特征fhil;
步骤2.11、由步骤2.8中的频率谱拟合特征ff和相位谱拟合特征fp,步骤2.5中的相位波动特征f,获得组合特征x=[ff,fp,f]。
在上述的一种基于卷积神经网络的数字音频篡改被动检测方法,步骤3是获取enf高斯均值超矢量,具体包括:
步骤3.1、对于d维语音特征x={x1,x2,…,xt},用于计算其似然函数的公式为:
式中该密度函数由k个单高斯密度函数pk(xt)加权得到,wi式混合权重分量,其中每一个高斯分量的均值μk和协方差∑k的大小分别为:1×d和d×d;
其中pk(xt)为第k个d维高斯分量的概率密度函数,混合权重wk满足
步骤3.2、用em算法获取参数λ,先给予λ一个初始值,然后估计出新参数λ′,使得在λ′下的似然度更高,即p(x|λ′)≥p(x|λ),新参数再作为当前参数进行训练,不断迭代,各参数的重估计公式为:
其中wk代表混合权重,μk表均值和∑k为协方差矩阵;
步骤3.3、首先将原始语音与训练语音(包含未篡改语音与篡改语音)按步骤2提取处组合特征x,用原始语音的特征x按步骤3.2训练ubm模型,然后将训练语音的每个特征向量送入到ubm模型中,将经过map自适应得出的均值单独保留下来作为enf高斯均值超矢量。
在上述的一种基于卷积神经网络的数字音频篡改被动检测方法,步骤4是卷积神经网络模型训练,具体包括:
步骤4.1、构建卷积神经网络(cnn),cnn网络模型由三个卷积块组成(滤波器个数分别为64、128、256),每个块包含两层卷积层(激活函数为relu)、一层maxpool层(poolsize为2);
步骤4.2、最后一个卷积块的输出输入到attention机制中进行特征选择,具体是:
a、最后一个卷积块的输出进行flatten操作后输入进神经元个数为1024的全连接层(激活函数为relu);
b、步骤a中的全连接层的输出通过一层全连接层和sigmoid层;
c、步骤a中的全连接层的输出与步骤b中sigmoid的输出相乘;
步骤4.3、步骤4.2.c中的输入到神经元个数为128的全连接层(激活函数为relu),最后神经元个数为2的全连接层(激活函数为softmax)作为输出层进行分类,具体是:
a、4.2.c中的输入到神经元个数为128的全连接层;
b、步骤a中的输出输入到神经元个数为2的全连接层(激活函数为softmax)
其中fc表示第c个神经元的输入,c=2为本层神经元个数,pc表示待测语音是原始语音还是篡改语音的概率;
c、最后输出层得到的概率可得出待测语音是否被篡改,计算所有测试语音正确识别是否被篡改的概率,即系统的识别率。
因此,本发明具有如下优点:与传统数字音频篡改检测相比,本法发明提出对enf波动超矢量特征采用卷积神经网络cnn与注意力机制attention来进行分类。卷积神经网络可以更好的学习原始音频与篡改音频的差异性。注意力机制从cnn输出的大量特征中筛选出重要信息,减小输入数据的运算负担。本发明的数字音频篡改检测方法与传统数字音频篡改检测方法相比能够有效提升系统的识别性能,优化了系统结构,提高了相应设备源识别产品的竞争力。
附图说明
图1是本发明的方法流程示意图。
图2是卷积神经网络结构图。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
本发明种基于卷积神经网络的数字音频篡改被动检测方法,本发明的算法流程图如图1所示,可以分为四部分:1)enf成分获取;2)enf相位与频率特征提取;3)训练ubm提取enf高斯均值超矢量;4)卷积神经网络训练。
步骤一:enf成分获取,步骤如下:
a、将音频进行下采样,重采样频率定为1000hz或者1200hz;
b、使用10000阶的线性零相位fir滤波器进行窄带滤波,中心频率在enf标准(50hz或60hz)处,带宽为0.6hz,通带波纹0.5db,阻带衰减为100db;
步骤二:enf相位与频率特征提取,步骤如下:
a、求信号一阶导数、分帧加窗、离散傅里叶变换、线性插值估算相位、计算相位波动特征:
(a-1)计算enf信号xenfc[n]在点n处的近似一阶导数
x′enfc[n]=fd(xenfc[n]-xenfc[n-1])(1)
其中fd(*)表示近似求导操作,xenfc[n]表示enf成分第n个点的值。
(a-2)对x′enfc[n]进行分帧加窗,帧长为10个标准enf频率周期
x′n[n]=x′enfc[n]w(n)(2)
其中汉宁窗
(a-3)每帧信号x′n[n]与xenfc[n]分别执行n点离散傅里叶变换(dft)得到x′(k)、x(k),根据|x′(k)|的峰值点的整数索引kpeak估计频率
其中dft0[kpeak]=x(kpeak),dft1[kpeak]=f(kpeak)|x′(kpeak)|,f(kpeak)是一个尺度系数。
其中ndft表示离散傅里叶变换点数,k为峰值点索引。
(a-4)计算xenfc的相位
(a-5)计算x′enfc的相位
其中
(a-6)
(a-7)将的x′enfc的相位
其中
b、hilbert变换、低通滤波、提取enf成分的瞬时频率估计f[n]:
(b-1)对信号xenfc[n]进行离散hilbert变换。首先得到xenfc[n]的解析函数
x(a)enfc[n]=xenfc[n]+i*h{xenfc[n]}(7)
其中
(b-2)对f[n]进行低通滤波,去除震荡。使用五阶椭圆滤波器iir滤波器。中心频率为enf标准频率,带宽为20hz,通带波纹为0.5hz,阻带衰减为64hz。
由于频率估计的边界效应,去掉f[n]头尾各大约1s,最后得到enf成分的瞬时频率估计fhil。
c、曲线拟合、特征组合:
(c-1)对相位特征
用sumofsines来拟合相位特征,其形式为:
其中a是振幅,b是频率,c是每个正弦波项的相位常量,n指这个序列的数量,1≤n≤9,x=[1,2,…,len(φ)],len(φ)为
用gaussian来拟合瞬时频率特征,其形式为:
其中a是峰值幅度,b是峰值所在位置,c与峰的旁瓣有关,n指拟合了多少个峰值,1≤n≤8,x=[1,2,…,len(f)],len(f)为fhil的长度,y为瞬时频率特征fhil。
(c-2)由频率谱拟合特征ff和相位谱拟合特征fp,相位波动特征f,获得组合特征x=[ff,fp,f]。
步骤三:训练ubm模型,提取出enf高斯均值超矢量。
给出一组按步骤二中提取出的组合特征x,训练通用背景模型(ubm);
(a-1)对于d维语音特征x={x1,x2,…,xt},用于计算其似然函数的公式为:
式中该密度函数由k个单高斯密度函数pk(xt)加权得到,其中每一个高斯分量的均值μk和协方差∑k的大小分别为:1×d和d×d;
其中混合权重wk满足
(a-2)用em算法获取参数λ,先给予λ一个初始值,然后估计出新参数λ′,使得在λ′下的似然度更高,即p(x|λ′)≥p(x|λ),新参数再作为当前参数进行训练,不断迭代,各参数的重估计公式为:
其中wk代表混合权重,μk表均值和∑k为协方差矩阵。
b、利用ubm模型对训练数据进行最大后验概率(maximumaposteriori,map)操作,提取出enf高斯均值超矢量。
步骤四:利用卷积神经网络如图2对enf高斯均值超矢量进行训练。
a、构建卷积神经网络(cnn),cnn网络模型由三个卷积块组成(滤波器个数分别为64、128、256),每个块包含两层卷积层(激活函数为relu)、一层maxpool层(poolsize为2)。
b、最后一个卷积块的输出输入到attention机制中进行特征选择,具体是:
(b-1)、最后一个卷积块的输出进行flatten操作后输入进神经元个数为1024的全连接层(激活函数为relu)。
(b-2)、步骤(b-1)中的全连接层的输出通过一层全连接层和sigmoid层。
(b-3)、步骤(b-1)中的全连接层的输出与步骤b中sigmoid的输出相乘。
c、步骤b的输出输入到神经元个数为128的全连接层(激活函数为relu),最后神经元个数为2的全连接层(激活函数为softmax)作为输出层进行分类,具体是:
(c-1)、步骤b的输出输入到神经元个数为128的全连接层。
(c-2)、输入到神经元个数为2的全连接层(激活函数为softmax)
其中fc表示第c个神经元的输入,c=2为本层神经元个数,pc表示待测语音是原始语音还是篡改语音的概率。
(c-3)、最后输出层得到的概率可得出待测语音是否被篡改,计算所有测试语音正确识别是否被篡改的概率,即系统的识别率。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



