
 商标分类
商标分类  商标转让
商标转让 
一种基于双层声学模型的快速语音识别方法与流程
 2021-01-28 12:01:03|
2021-01-28 12:01:03| 308|
308| 起点商标网
起点商标网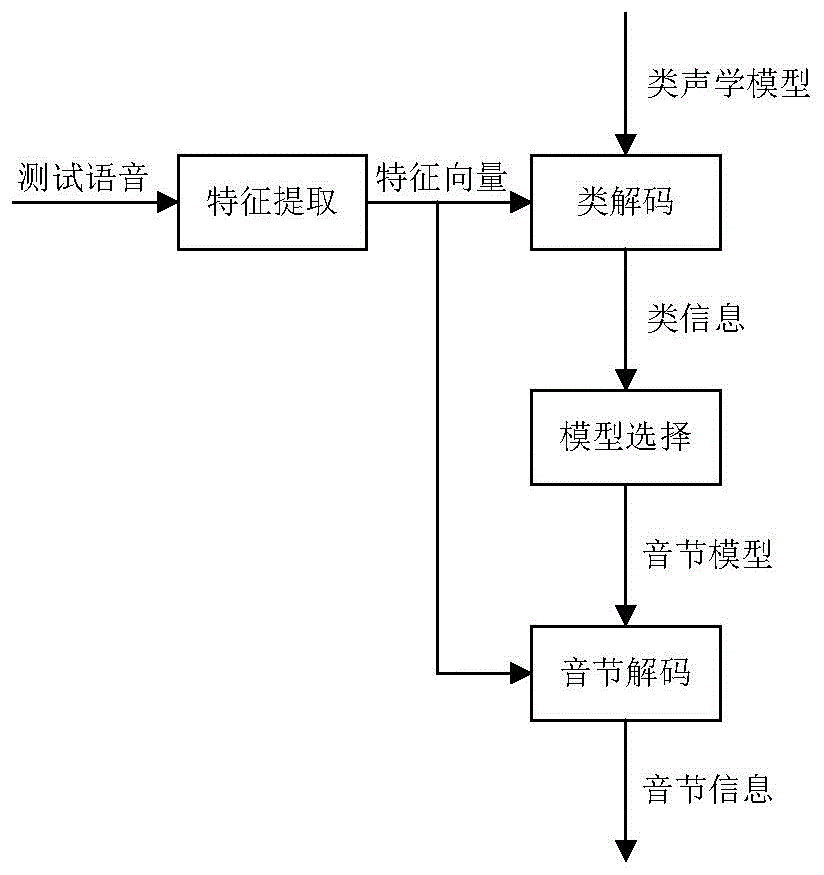
本发明属于语音识别技术领域,具体涉及到一种基于双层声学模型的快速语音识别方法。
背景技术:
在传统的语音识别系统中,需要在训练阶段为语音的每个音节建立声学模型;在识别阶段,用每个音节的声学模型计算当前语音特征参数的概率,并比较概率大小,以概率最大的声学模型对应的音节为识别结果。随着语音识别系统词汇量的增加,识别阶段的运算量也随之增加,这会影响语音识别在手持设备等运算性能较差的设备中的应用。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提供一种基于低频音节识别的语音增强方法,解决了语音增强后语音音质差的问题。
技术方案:本发明提供一种基于双层声学模型的快速语音识别方法,包括训练阶段和识别阶段,其中,训练阶段包括:
(1)对训练语音文本进行预处理;
(2)用共振峰聚类的方法将语音识别系统的全部音节划分为若干类;
(3)用每一类的所有音节的训练语音进行模型训练,生成类声学模型;
(4)用每个音节的训练语音进行模型训练,生成该音节的声学模型;
识别阶段包括:
(5)对测试语音文本进行预处理;
(6)用类声学模型对当前测试语音的特征向量进行类解码,将其归为某一类语音;
(7)根据类解码得到的类信息,调用该类所有音节的声学模型,对当前语音的特征向量进行音节解码,得到识别结果。
进一步的,包括:
所述步骤(1)中对训练语音文本进行预处理包括加窗,分帧和提取美尔频率倒谱系数,作为语音的特征向量。
设一帧语音信号的幅度谱为x(k),则美尔频率倒谱系数对应向量c的第l个元素可以表示为
其中,n0是帧长;m0是mel滤波器组中滤波器的个数;wm(k)是mel滤波器组中第m个滤波器在频率k处的加权因子;l是mfcc向量c的维数。
进一步的,包括:
所述步骤(2)包括:
首先对每个音节的训练语音提取共振峰,并取平均值,得到该音节的共振峰向量;然后,对全部音节的共振峰向量进行聚类,将n个音节划分为m类,每一类的音节个数分别为n1,n2,…,nm,它们满足:
进一步的,包括:
所述步骤(3)中,对每一类音节,用这些音节的全部训练语音训练生成该类的高斯混合模型,第m类的高斯混合模型的输出概率可以表示为
其中,xt表示第t帧语音的mfcc向量;cmk、μx,mk和σx,mk分别表示第m类的gmm中第k个高斯混合单元的混合系数、均值向量和协方差矩阵;d表示mfcc向量的维数;nm表示第m类的gmm的高斯混合数。
进一步的,包括:
所述步骤(4)中,设语音识别系统有n个音节,在训练阶段用每个音节的全部训练语音生成该音节的连续密度隐马尔可夫模型,得到n个连续密度隐马尔可夫模型,这n个连续密度隐马尔可夫模型组成音节模型,用于测试阶段的音节解码,每个连续密度隐马尔可夫模型由6个左右结构的状态组成,每个状态用一个高斯混合数为4的高斯混合模型表示。第n个音节的连续密度隐马尔可夫模型的第i个状态的概率密度函数可以表示为:
其中,xt表示第t帧语音的mfcc向量;cn,im、μn,im和σn,im分别表示第n个hmm的第i个状态中第m个高斯混合单元的混合系数、均值向量和协方差矩阵;d表示特征向量的维数。
有益效果:本发明与现有技术相比,其显著优点是:本发明用共振峰聚类的方法将语音识别系统的全部音节划分为若干类,用每一类所有音节的训练语音进行模型训练,生成该类的声学模型,在识别过程中,先用类声学模型对输入语音的特征向量进行类解码,得到类信息,再调用该类所有音节的声学模型进行音节解码,得到识别结果。设语音识别系统有n个音节,如果直接进行声学解码,那么就需要运算n次;如果将这n个音节划分为m类,每类有k个音节,那么总共只需要运算(m+k)次。本方法可以减少运算次数,节省系统的电能,延长电池的使用时间。
附图说明
图1为本发明所述的方法流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
本发明设计了一种基于双层声学模型的快速语音识别方法,其总体框架如图1所示。在该算法中,将语音识别系统的全部音节划分为若干类,为语音识别系统同时配置类声学模型和音节声学模型;在识别过程中,通过先进行类识别,确定类信息,再进行类内音节识别的方法,减小声学解码的计算量,以实现节省电能,延长电池使用时间的目的。
本发明的具体步骤如下:
(1)用共振峰聚类的方法将语音识别系统的全部音节划分为若干类;
(2)用每一类的所有音节的训练语音进行模型训练,生成该类的声学模型;
(3)用每个音节的训练语音进行模型训练,生成该音节的声学模型(音节模型);
(4)在识别阶段,先用类声学模型对当前语音的特征向量进行类解码,将其归为某一类语音;
(5)然后根据类解码得到的类信息,调用该类所有音节的声学模型,对当前语音的特征向量进行音节解码,得到识别结果。
主要包括特征提取、类解码、模型选择和音节解码模块。下面逐一详细说明附图中各主要模块的具体实施方案。
1、特征提取
对训练语音或测试语音加窗,分帧,提取美尔频率倒谱系数(mfcc:melfrequencycepstralcoefficient),作为语音的特征向量。
设一帧语音信号的幅度谱为x(k),则mfcc向量c的第l个元素可以表示为
其中,n0是帧长;m0是mel滤波器组中滤波器的个数;wm(k)是mel滤波器组中第m个滤波器在频率k处的加权因子;l是mfcc向量c的维数。
2、模型训练
在训练阶段,需要训练生成每个音节的声学模型,并且对系统的全部音节进行聚类,将其划分为若干类,生成每一类的声学模型。在本发明中,用连续密度隐马尔可夫模型(hmm:hiddenmarkovmodel)作为音节声学模型,即每个音节用一个hmm表示;用高斯混合模型(gmm:gaussianmixturemodel)作为类声学模型,即每一类音节用一个gmm表示。
设语音识别系统有n个音节,在训练阶段用每个音节的全部训练语音生成该音节的hmm,得到n个hmm,这n个hmm组成音节模型,用于测试阶段的音节解码。每个hmm由6个左右结构的状态组成,每个状态用一个高斯混合数为4的高斯混合模型表示。第n个音节的hmm的第i个状态的概率密度函数可以表示为
其中,xt表示第t帧语音的mfcc向量;cn,im、μn,im和σn,im分别表示第n个hmm的第i个状态中第m个高斯混合单元的混合系数、均值向量和协方差矩阵;d表示特征向量的维数。
在音节分类中,首先对每个音节的训练语音提取共振峰,并取平均值,得到该音节的共振峰向量;然后,对全部音节的共振峰向量进行聚类,将n个音节划分为m类,每一类的音节个数分别为n1,n2,…,nm,它们满足:
对每一类音节,用这些音节的全部训练语音训练生成该类的gmm。第m类的gmm的输出概率可以表示为
其中,xt表示第t帧语音的mfcc向量;cmk、μx,mk和σx,mk分别表示第m类的gmm中第k个高斯混合单元的混合系数、均值向量和协方差矩阵;d表示mfcc向量的维数;nm表示第m类的gmm的高斯混合数。
3、类解码
在识别阶段,用每一类的gmm对当前测试语音的特征向量进行类解码,并比较每一类gmm的输出概率,将当前测试语音归类为输出概率最大的gmm对应的类,得到类信息,即输出概率最大的gmm的类序号。
4、模型选择
根据类解码得到的类信息,类信息为类序号,选择该类所有音节的声学模型(hmm)作为后续音节解码的音节模型,其他类的音节声学模型(hmm)不参与音节解码。这样可以减小音节解码的计算量。
5、音节解码
用模型选择得到的音节模型中的每个音节的hmm对当前测试语音的特征向量计算概率,并以输出概率最大的hmm对应的音节为识别结果。具体的,将特征向量输入hmm,用前向-后向算法或viterbi算法计算输出概率。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



