
 商标分类
商标分类  商标转让
商标转让 
一种基于神经网络的语音指令及身份识别方法与流程
 2021-01-28 12:01:52|
2021-01-28 12:01:52| 343|
343| 起点商标网
起点商标网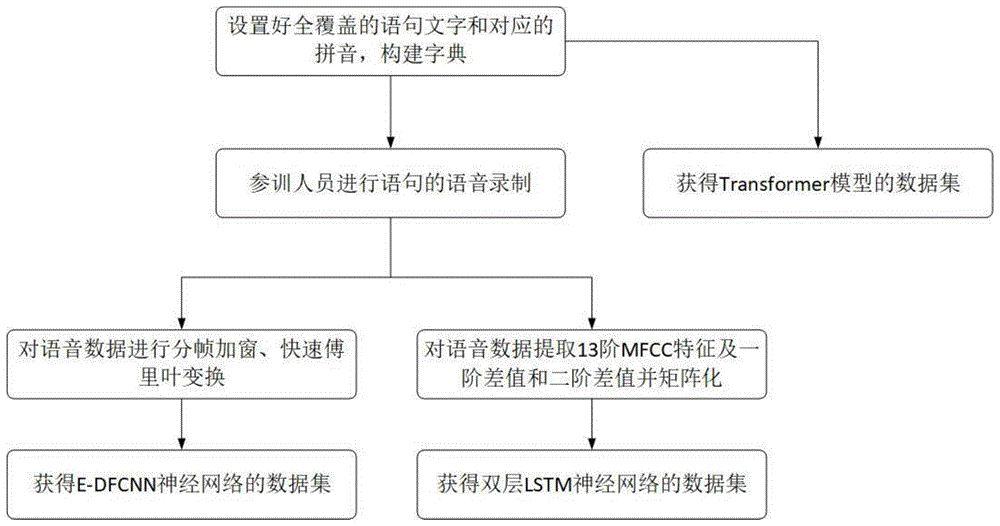
本发明属于语音及指令信息的处理
技术领域:
,尤其涉及一种基于神经网络的语音指令及身份识别方法。
背景技术:
:现在正处于一个人工智能飞速发展的时代,语音识别技术在各行各业中应用的越来越多,其中科大讯飞的语音识别技术尤为突出,在大部分场景下都有较好的表现。但是针对一些专用场景,要求不仅能够识别出人到底说出了什么话,还需要分辨出是哪个人说出的语音,此时科大讯飞的语音识别技术的表现就不够理想。为了适应这种专用场景的需求,需要一种新的特殊性的语音识别技术识别语音和说话者,本发明就是在这样的背景下产生的。技术实现要素:一种基于神经网络的语音指令及身份识别方法,通过神经网络将语音中的指令及人员身份识别出来,从而省去了对指令及人员身份的手工输入,使得如训练等场景的操作更加方便快捷,效率得到提升。为实现上述目的,本发明创造采用如下技术方案。一种基于神经网络的语音指令及身份识别方法,包括数据集的获取及神经网络的设计与构建;步骤1,用于构建语音识别拼音转文字数据集的步骤;包括,确定当前场景需要识别的所有语句,确定语句文字和对应拼音,所述语句文字应涵盖所有需要识别的语句中的文字;基于前述语句文字和对应拼音分别构建出文字列表和拼音列表,即可通过这两个表将每个文字和拼音转换为整数值;最后将所有的语句的拼音和文字转换为整数值,并以拼音的整数列表作为基础数据建立拼音转文字的数据集;步骤2,用于获取身份及语音识别基础数据的步骤;包括,确定当前场景需要识别的人员身份,以其名字或id作为识别标签,分别让所有人员录制前述步骤1中的所有语句;步骤3,用于构建身份及语音语句识别数据集的步骤;所述语音语句识别数据集采用如下方式建立:对前述步骤2中获取的语音数据进行分帧、加窗和快速傅里叶变换,得到相应的语音时频特征,并以该语音时频特征为基础数据建立语音语句识别的数据集;所述身份识别数据集采用如下方式建立:对前述步骤2中获取的语音数据进行mfcc特征提取,并以该mfcc特征为基础数据建立身份识别的数据集;步骤4,构建语音指令及身份识别数据集神经网络;所述语音指令及身份识别数据集神经网络的设计包含以下步骤:步骤4.1,确定网络层数,以及每层神经元数量;步骤4.2,确定神经网络的超参数,包括学习率和迭代次数;步骤4.3,确定神经网络的相关函数,包括代价函数和激活函数;步骤4.4,依序构建出语音指令识别数据集的e-dfcnn神经网络、transformer模型数据集神经网络和身份识别数据集的双层lstm神经网络。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述e-dfcnn神经网络采用四个卷积神经网络单元,所述四个卷积神经网络单元的卷积核大小为3*3,卷积核数量依次为32、64、128、128;共使用三个池化层,选择最大池化层,池化窗口大小为2*2;共使用三个全连接层,前两个全连接层神经元数量分别为512和256,最后一个全连接层的神经元数量为指令中包含的需要识别的汉语拼音的种类数;共使用了2个dropout层,丢弃率为0.2,防止过拟合。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述transformer模型以汉字拼音作为输入,输出汉字拼音对应的汉字,输入和输出长度相同,是一个序列标注任务,其中layernorm层用于做归一化处理,为防止分母为0报错,增加一个小浮点数epsilon,值为1e-8,即10的-8次方;embedding层对字词进行向量化操作,向量最大长度为100,其中隐藏神经元个数为512,丢弃率为0.2;multi-headattention层中,head的数量为8,隐藏神经元个数为512,丢弃率为0.2;前馈层采用1d卷积神经网络,神经元数量为2048。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述双层lstm神经网络,核心采用两个双向lstm构成,其中输出单样本的特征值的维度为128,丢弃率为0.2,循环层丢弃率为0.2,输入尺寸为300*39;使用两个全连接层,第一个全连接层的神经元数量为32,第二个全连接层的神经元数量为参与样本训练的人员的数量。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述步骤4中,还包括确定神经网络的超参数的步骤,所述超参数至少包括学习率、步长、训练迭代次数;具体而言:在e-dfcnn神经网络模型中,学习率为0.0008,迭代次数为50次,在每次迭代中,batch_size为4;在transformer模型中,学习率为0.0003,迭代次数为50次,在每次迭代中,batch_size为4;在双层lstm神经网络模型中,学习率为0.001,迭代次数为50次,在每次迭代中,batch_size为8。对前述基于神经网络的语音指令及身份识别方法的进一步改进,还包括确定神经网络的相关函数的步骤,所述相关函数至少包括代价函数和激活函数;具体而言:在e-dfcnn神经网络模型中,其中4个卷积神经网络单元,激活函数统一为relu函数;其中3个全连接层,前两个全连接层激活函数均选择relu函数,最后一个全连接层选择softmax函数作为激活函数以进行分类输出;采用ctc作为损失函数,其优化函数选择adam函数,学习率为0.0008;在transformer模型中,在multi-headattention层中,其激活函数统一为relu函数;在前馈层中,其激活函数统一为relu函数;最终的输出层激活函数使用softmax函数作为分类函数;损失函数选择交叉熵代价函数,其优化函数选择adam函数,学习率为0.0003;在双层lstm神经网络模型中,其中第一层全连接层选择relu函数作为激活函数,第二层全连接层选择softmax函数作为激活函数以进行分类输出;选择交叉熵代价函数作为损失函数,选择rmsprop函数作为其优化函数,学习率为0.0008。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述语音识别拼音字典包括多个语句文字和拼音字段表;所述语句文字和拼音字字段表中的拼音字段以“发声+声调”的形式保存,遍历这所有语句文字和拼音字段表,将拼音存入列表中构成字典,将文字转换为拼音所处列表位置的数字。对前述基于神经网络的语音指令及身份识别方法的进一步改进,所述步骤3中,对语音数据进行分帧加窗采用的函数为:在对语音数据进行分帧加窗以后,通过快速傅里叶变换,获得用于进行语音语句识别的输入数据。对前述基于神经网络的语音指令及身份识别方法的进一步改进,对于每个人录制的语音,将语音按照“名字+语音序号”的方式保存下来,后续通过文件名提取出人员的身份标签。对前述基于神经网络的语音指令及身份识别方法的进一步改进,对语音进行mfcc特征提取,提取出音频的13阶mfcc特征及这13阶特征的一阶差值和二阶差值,一共是39维特征,将其处理成矩阵形式后构成进行身份识别的数据集。其有益效果在于:1、解决了在专业领域,对语音数据和人员进行双重识别的需求;通过用于语音指令识别的e-dfcnn神经网络,将语音输入转换为拼音的输出;将拼音通过拼音字典将拼音列表转换为整数值列表,通过transformer模型将其转换为文字对应整数值的列表,后经文字字典转换为文字,得到了指令的识别结果;最后将语音输入通过双层lstm神经网络,将语音输入转换为人员的身份,基于本申请的基于神经网络的语音指令及身份识别方法能够用于各种有关于指令考核、中枢指挥机构的专业场景。2、区别于现有的科大讯飞等现有技术中的dfcnn模型,本发明的语音识别速度与dfcnn模型几乎相同,但准确率的提升率超过8%,更适应于指令化语言的快速识别和分析,能够有效提高指令考核、中枢指挥机构等专业场景的反应速度和准确度。附图说明图1是基于神经网络的语音指令及身份识别方法数据集的获取流程示意图;图2是音频处理后得到的语谱图;图3是神经网络设计及构建流程图;图4是e-dfcnn神经网络的结构图;图5是transformer模型的结构图;图6是双层lstm神经网络的结构图。具体实施方式以下结合具体实施例对本发明创造作详细说明。本申请的一种基于神经网络的语音指令及身份识别方法,包括数据集的获取及神经网络的设计与构建;对于数据集的获取流程参见图1,实例通过型号为某型的笔记本电脑的麦克风来录制语音获取的舰艇指令数据集为例对本发明的流程进行一个具体的阐述。步骤1,确定当前场景需要识别的所有语句,设定好语句的文字和对应的拼音,其中语句中的文字应该涵盖所有需要识别的语句中的文字。实施例具体的实施过程说明如下:如表1所示,设定好100条用于训练的语句文字和拼音。其中拼音以“发声+声调”的形式保存,每个拼音之间空一格。遍历这100条语句,将拼音存入列表中构成字典。如此一来即可将文字转换为拼音所处列表位置的数字。表1语句文字和拼音示例表(部分示意)步骤2,确定当前场景需要识别的人员身份,将其名字或id作为识别的标签,并让这些人员录制步骤1中提到的语句。实施例具体的实施过程说明如下:在本例中,选取十人,每个人录制表1中显示的100条语句的语音,并将语音按照“名字+语音序号”的方式保存下来,后续即可通过文件名提取出人员的身份标签,而语音则用以进行后续的语音处理。步骤3,对语音数据进行分帧加窗和快速傅里叶变换,得到语音的时频特征,即获得了语音语句识别的数据集;对语音数据进行mfcc特征提取,即获得了语音人声识别的数据集。实施例具体的实施过程说明如下,使用汉明窗对音频进行加窗操作,其函数为:在对音频进行分帧加窗以后,通过快速傅里叶变换,即可获得用于进行语音语句识别的输入数据,即用以分辨说的话是什么。再次对音频进行mfcc特征提取,提取出音频的13阶mfcc特征以及这13阶特征的一阶差值和二阶差值,一共是39维特征。将其处理成矩阵形式后,即可获得用于进行语音人声识别的数据集,即用以分辨是谁说的话,对音频处理后得到的语谱图如图2所示。对于神经网络的设计流程,参见图3,实施例以上述生成的数据集设计对应的神经网络。步骤1,确定网络层数,并设定每层神经元数量。实施例具体的实施过程说明如下:如图4所示,对于e-dfcnn神经网络,总共使用了四个卷积神经网络单元,其中四个卷积神经网络单元的卷积核大小均为3*3,卷积核数量依次为32、64、128、128;一共使用了三个池化层,使用的池化层规格参数都一样,池化方式选择最大池化层,池化窗口大小为2*2;一共使用了3个全连接层,前两个全连接层神经元数量分别为512和256,最后一个全连接层的神经元数量为指令中包含的需要识别的汉语拼音的种类数;一共使用了2个dropout层,丢弃率为0.2。e-dfcnn的神经网络模型层数表如表2所示:表2e-dfcnn的神经网络模型层数表类型卷积核/池化层尺寸个数神经元选中概率cov2d_1积层(3,3)32--cov2d_2卷积层(3,3)32--maxpool2d_1池化层(2,2)32--cov2d_3卷积层(3,3)64--cov2d_4卷积层(3,3)64--maxpool2d_2池化层(2,2)64--cov2d_5卷积层(3,3)128--cov2d_6卷积层(3,3)128--maxpool2d_3池化层(2,2)128--cov2d_7卷积层(3,3)128--cov2d_8卷积层(3,3)128--dropout_1------0.2dense_1全连接层--512dropout_2------0.2dense_2全连接层--256dropout_3------0.2对于transformer模型,该模型将汉字拼音作为输入,输出汉字拼音对应的汉字,由于输入和输出长度相同,只是一个序列标注任务,只需编码器encoder即可。其中layernorm层用于做归一化处理,为防止分母为0报错,增加一个小浮点数epsilon,值为1e-8,即10的-8次方;embedding层对字词进行向量化操作,向量最大长度设置为100,其中隐藏神经元个数为512,丢弃率为0.2;multi-headattention层中,head的数量为8,隐藏神经元个数为512,丢弃率为0.2;前馈层采用1d卷积神经网络,神经元数量为2048。对于双层lstm神经网络,核心采用两个双向lstm构成,其中输出单样本的特征值的维度设定为128,丢弃率为0.2,循环层丢弃率为0.2,输入尺寸为300*39;使用两个全连接层,第一个全连接层的神经元数量为32,第二个全连接层的神经元数量为参与样本训练的人员的数量。双层lstm神经网络的层数表如表3所示:表3双层lstm神经网络的层数表类型尺寸个数神经元选中概率bidirectional_1(lstm)双向lstm(300,39)--0.2,0.2bidirectional_2(lstm)双向lstm(300,39)--0.2,0.2flatten_1扁平层------dense_1全连接层--32--dense_2全连接层--人数--步骤2,确定神经网络的超参数,包括学习率和迭代次数等。实施例具体的实施过程说明如下:区别于通过训练得到的参数数据,超参数是在开始学习过程之前设置值的参数,在确定的神经网络的结构之后,训练网络之前需要确定超参数的值。这些超参数包括学习率、步长、训练迭代次数等。在e-dfcnn神经网络模型中,学习率设定为0.0008,迭代次数为50次,在每次迭代中,batch_size设定为4。在transformer模型中,学习率设定为0.0003,迭代次数为50次,在每次迭代中,batch_size设定为4。在双层lstm神经网络模型中,学习率设定为0.001,迭代次数为50次,在每次迭代中,batch_size设定为8。步骤3,确定神经网络的相关函数,包括代价函数和激活函数,实施例具体的实施过程说明如下:代价函数主要用来衡量期望的输出值与实际输出值的差异,是用来量化网络模型的误差的目标函数。激活函数是神经网络具有非线性拟合能力的核心,激活函数给神经网络提供了线性拟合的能力。在e-dfcnn神经网络模型中,其中4个卷积神经网络单元,激活函数统一设置为relu函数;其中3个全连接层,前两个全连接层激活函数均选择relu函数,最后一个全连接层选择softmax函数作为激活函数以进行分类输出。采用ctc作为损失函数,其优化函数选择adam函数,学习率设置为0.0008。在transformer模型中,在multi-headattention层中,其激活函数统一设置为relu函数;在前馈层中,其激活函数统一设置为relu函数;最终的输出层激活函数使用softmax函数作为分类函数;损失函数选择交叉熵代价函数,其优化函数选择adam函数,学习率设置为0.0003。在双层lstm神经网络模型中,其中第一层全连接层选择relu函数作为激活函数,第二层全连接层选择softmax函数作为激活函数以进行分类输出。选择交叉熵代价函数作为损失函数,选择rmsprop函数作为其优化函数,学习率设置为0.0008。步骤4,依序构建出改进的e-dfcnn神经网络、transformer模型和双层lstm神经网络。实施例具体的实施过程说明如下:参照图4中的模型所示,依序将各层连接,设定好参数,即可构建e-dfcnn神经网络。参照图5中的模型所示,依序将各层连接,设定好参数,即可构建transformer模型。参照图6中的模型所示,依序将各层连接,设定好参数,即可构建双层lstm神经网络。至此,神经网络设计完成,表4是dfcnn神经网络与本发明采用的e-dfcnn神经网络错误率对比,可以看出本发明的准确率明显更高。表4dfcnn神经网络与本发明采用的e-dfcnn神经网络错误率对比声学模型词错误率整句错误率dfcnn10.77%20%e-dfcnn6.15%12%表5是dfcnn神经网络与发明采用的e-dfcnn神经网络对指令音频处理时间对比,可以看出本发明在提高准确率的情况下,几乎没有花费更多的时间。表5dfcnn神经网络与发明中e-dfcnn神经网络对指令音频处理时间对比声学模型100句指令音频转换用时平均一句转换用时dfcnn28.5秒0.285秒e-dfcnn29.7秒0.297秒表6是将语音识别神经网络及拼音转文字神经网络结合起来的两个神经网络错误率对比,可以看出结合起来后仍然是本发明在正确率上有更好的表现。表6不同神经网络组合后错误率对比模型组合词错误率整句错误率dfcnn+transformer16.77%28%e-dfcnn+transformer9.15%16%本发明的双层lstm神经网络,在使用很少次数的迭代训练次数即可形成极高的准确率,能够更有效的应对现场变化的语音指令信息以及应对某些加密等特殊场合的语音处理,,应对临时数据处理的需求,数据表明,在经过50次迭代的训练后,对于人员身份的识别准确度可达到80%,且准确率将随着迭代次数的增加不断提高。最后应当说明的是,以上实施例仅用以说明本发明创造的技术方案,而非对本发明创造保护范围的限制,尽管参照较佳实施例对本发明创造作了详细地说明,本领域的普通技术人员应当理解,可以对本发明创造的技术方案进行修改或者等同替换,而不脱离本发明创造技术方案的实质和范围。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips