
 商标分类
商标分类  商标转让
商标转让 
一种基于模型融合框架的两阶段语音唤醒算法的制作方法
 2021-01-28 12:01:56|
2021-01-28 12:01:56| 314|
314| 起点商标网
起点商标网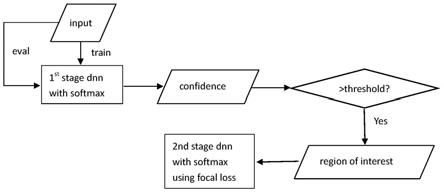
[0001]
本发明涉及语音识别技术领域,进一步说,尤其涉及一种基于模型融合框架的两阶段语音唤醒算法。
背景技术:
[0002]
语音唤醒现在逐渐开始应用在各种生活场景中,而误唤醒是多数唤醒系统的一个主要问题,尤其在例如智能家居这样的应用中,一般对误唤醒容忍度很低,且家庭语音环境复杂更容易误唤醒,本申请方案通过多个模型融合,从训练到解码两方面进行分阶段唤醒,以到达一个非常低的误唤醒水平。
[0003]
经检索,申请号为201210455175.2、名称为一种语音唤醒模块的实现方法及应用的技术方案,解决技术问题是即使在嘈杂环境下不论是否有播放音乐,都可以通过语音唤醒词开启语音唤醒功能,同时语音唤醒效果好;采用的技术方案是:语音输入(1)、语音唤醒算法(2)和唤醒执行(3)步骤,语音唤醒算法(2)获取语音输入(1)的语音信号,进行语音唤醒处理后,将结果输出给唤醒执行(3),从而完成唤醒操作;所述语音唤醒算法(2)通过声学特征提取(4)、唤醒词检测(5)、唤醒词确认(6)、构建唤醒词检测网络(7)、训练声学模型(8)和构建唤醒词确认网络(9)来实现,具体实现过程如下:第一步,声学特征提取(4):通过语音输入(1)获取语音信号输入,提取具有区分性的、并且是基于人耳听觉特性提取的特征,选取语音识别中用到的美尔频率倒谱系数特征作为声学特征;第二步,唤醒词检测(5):将提取得到的声学特征,采用训练的声学模型(8)在唤醒词检测网络(7)上计算声学得分,如果声学得分最优的路径中包含要检测的唤醒词,则确定已检出唤醒词,进入第三步操作,否则回到第一步重新进行提取声学特征(4)步骤;第三步,唤醒词确认(6):将提取得到的声学特征,采用训练的声学模型(8)在唤醒词确认网络(9)上进行唤醒词确认,得到最终确认得分;判断该检出的唤醒词是否为真实的唤醒词,即将该唤醒词的最终确认得分和预先设定的门限,如果最终确认得分大于等于门限,则认为该唤醒词是真实的唤醒词,语音唤醒成功,将结果输出给唤醒执行(3),从而完成语音唤醒操作;如果最终确认得分小于门限,则认为该唤醒词为虚假的唤醒词,重新回到第一步重新进行声学特征提取(4)步骤。综上,可以看出,本申请方案不论其技术方案还是所解决的技术问题均不同于上述申请方案。
技术实现要素:
[0004]
本发明为解决上述技术问题而采用的技术方案是提供一种基于模型融合框架的两阶段语音唤醒算法,通过结果层面模型融合的方式从工程上构建两个阶段的唤醒判别,使得网络层面实现简单其中,具体技术方案为:
[0005]
1)准备两个不同结构的神经网络,第一阶段训练一个小模型,应用全部训练数据;
[0006]
2)训练结束后,所有负样本训练数据过模型得到不同的分数,将一定得分以上的音频段选出来,作为region of interest,加上原本的正样本,作为第二阶段训练的数据;
[0007]
3)解码时,需要输入音频通过两个模型结果都大于阈值才可以唤醒。
[0008]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:3)步骤,利用模型融合,分阶段判别唤醒。
[0009]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:1)步骤,训练阶段:
[0010]
a.所有正样本数据清洗之后与所有负样本数据一起送到第一个比较小的网络训练;
[0011]
b.负样本通过第一个训练好的网络,得到一批confidence,其中得分比较高的表示更接近正样本,作为第一个网络难以分别的样本,把这些部分选出来称作region of interest;
[0012]
c.将region of interest以及所有正样本一起送入第二个较大的网络,通过focal loss中的gamma调整难样本的权重,同时网络中使用多层的splice拼接帧。
[0013]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:1)步骤,训练阶段:
[0014]
训练中使用focal loss更大程度区分难样本:
[0015]
fl(p
t
)=-(1-p
t
)γlog(p
t
).
[0016]
其中,fl表示loss,pt表示logits经过softmax结果。
[0017]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:1)步骤,训练阶段:
[0018]
网络层头部用rank-constrained topology,使得网络变小但保留有效信息,把splice后接的变换矩阵分解成2个小矩阵;
[0019][0020][0021]
其中,f表示激活函数,w(m)=[w
i,j(m)
]表示连接输入层的网络权重,x为输入。
[0022]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:3)步骤,解码流程:
[0023]
将输入音频分别通过两个训练好的模型,各得到一个confidence,设定2个阈值,当得到的两个confidence大于阈值的点时间差不超过一定范围时,认为是真的唤醒词,可以唤醒。
[0024]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:1)两个不同结构的神经网络,不同结构为大小和训练颗粒度的区别,第一阶段训练为裸的全连接神经网络。
[0025]
上述的一种基于模型融合框架的两阶段语音唤醒算法,其中:2)步骤,第二个模型多为大的多层splice,相邻或间隔的多帧拼接的神经网络。
[0026]
本发明相对于现有技术具有如下有益效果:通过结果层面模型融合的方式从工程上构建两个阶段的唤醒判别,使得网络层面实现简单,且有效利用了多模型融合时模型结构不同训练数据不同所带来的结果差异优势。最终在不降低唤醒率的情况下获得很好的防止误唤醒的效果。
附图说明
[0027]
图1为训练阶段流程图。
[0028]
图2为解码阶段流程图。
具体实施方式
[0029]
下面结合附图和实施例对本发明作进一步的描述。
[0030]
本申请方案创新点:
[0031]
1、利用模型融合,分阶段判别唤醒;
[0032]
2、训练中使用focal loss更大程度区分难样本;
[0033]
fl(p
t
)=-(1-p
t
)γlog(p
t
).
[0034]
其中,fl表示loss,pt表示logits经过softmax结果。
[0035]
3、网络层头部用rank-constrained topology,使得网络变小但保留有效信息,把splice后接的变换矩阵分解成2个小矩阵。
[0036][0037][0038]
其中,f表示激活函数,w(m)=[w
i,j(m)
]表示连接输入层的网络权重,x为输入。
[0039]
不同模型结构不同,第二阶段大模型使用多层splice。
[0040]
具体实施例为:
[0041]
准备两个不同结构的神经网络,通常为大小和训练颗粒度的区别。第一阶段训练一个小模型,多为裸的全连接神经网络,应用全部训练数据。
[0042]
训练结束后,所有负样本训练数据过模型得到不同的分数,将一定得分以上的音频段选出来,作为region of interest,加上原本的正样本,作为第二阶段训练的数据。第二个模型多为大的多层splice(相邻或间隔的多帧拼接)的神经网络。
[0043]
解码时,需要输入音频通过两个模型结果都大于阈值才可以唤醒。
[0044]
具体实施流程:
[0045]
训练阶段:
[0046]
所有正样本数据清洗之后与所有负样本数据一起送到第一个比较小的网络训练。
[0047]
负样本通过第一个训练好的网络,得到一批confidence,其中得分比较高的表示更接近正样本,作为第一个网络难以分别的样本,把这些部分选出来称作region of interest。
[0048]
将region of interest以及所有正样本一起送入第二个较大的网络,此网络使用focal loss更有助于区别难样本,可通过gamma调整难样本(分类错误)的权重,同时网络中使用多层的splice拼接帧,实验表明可提升模型效果。
[0049]
解码流程:
[0050]
将输入音频分别通过两个训练好的模型,各得到一个confidence,设定2个阈值,当得到的两个confidence大于阈值的点时间差不超过一定范围时,认为是真的唤醒词,可以唤醒。
[0051]
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips