
 商标分类
商标分类  商标转让
商标转让 
语音交互的方法、装置、电子设备及存储介质与流程
 2021-01-28 12:01:32|
2021-01-28 12:01:32| 315|
315| 起点商标网
起点商标网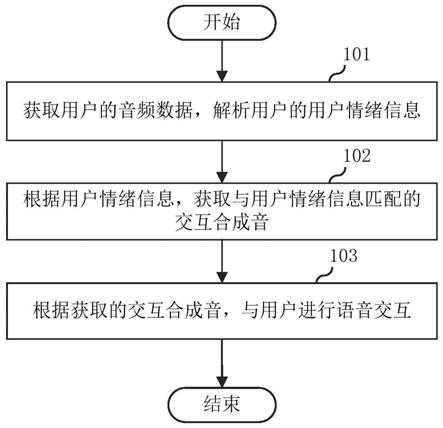
[0001]
本发明实施例涉计算机技术领域,特别涉及一种语音交互的方法、装置、电子设备及存储介质。
背景技术:
[0002]
语音识别技术应用于各种智能设备上,例如,智能音箱、智能空调等。智能设备通过语音识别技术,获取用户的意图,为用户提供与意图匹配的服务,例如,用户说播放歌曲,智能音箱为用户播放音乐。语音识别的过程如下,例如,智能设备采集用户的音频流信息,并发送至服务器,服务器接收该音频流信息,解析该音频流信息得到音频中的内容信息;服务器根据上下文信息和此时的内容信息,判定用户的意图,服务器将与该意图匹配的操作数据发送至智能设备,以便智能设备按照操作数据为用户提供服务。
[0003]
发明人发现相关技术中至少存在如下问题:目前用户与智能设备进行语音交互过程中,智能设备通常采用用户预先设定的声音进行回复,回复的声音一成不变,降低了用户与智能设备进行语音交互的需求,影响用户使用智能设备的体验。
技术实现要素:
[0004]
本发明实施方式的目的在于提供一种语音交互的方法、装置、电子设备及存储介质,使得可以采用与用户情绪信息匹配的合成音进行语音交互,提高电子设备的拟人化功能。
[0005]
为解决上述技术问题,本发明的实施方式提供了一种语音交互的方法,包括:获取用户的音频数据,解析用户的用户情绪信息;根据用户情绪信息,获取与用户情绪信息匹配的交互合成音;根据获取的交互合成音,与用户进行语音交互。
[0006]
本发明的实施方式还提供了一种语音交互的装置,包括:识别模块、获取模块和交互模块;识别模块用于获取用户的音频数据,解析用户的用户情绪信息;获取模块用于根据用户情绪信息,获取与用户情绪信息匹配的交互合成音;交互模块用于根据获取的交互合成音,与用户进行语音交互。
[0007]
本发明的实施方式还提供了一种电子设备,包括:至少一个处理器;以及,与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行上述的语音交互的方法。
[0008]
本发明的实施方式还提供了一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时实现上述的语音交互的方法。
[0009]
本发明实施方式相对于现有技术而言,获取用户的情绪信息,获取与用户情绪信息匹配的交互合成音,根据该交互合成音与用户进行语音交互,由于与用户进行交互的交互合成音不再是一成不变的声音,在用户不同的情绪下,与情绪匹配的交互合成音不同,使得用户会感受到是与具有感情的电子设备进行语音交互,提高了电子设备的拟人化程度,提高了用户使用电子设备进行语音交互的使用体验感。
[0010]
另外,从用户的音频数据中获取用户的意图信息;根据用户情绪信息和意图信息,从预先存储的人物角色中获取与用户情绪匹配的交互角色;根据交互角色对应的合成音,生成交互合成音。增加用户的意图信息,结合意图信息和用户情绪信息可以提高匹配交互角色的准确度,获取到使用户满意的交互合成音。
[0011]
另外,从用户的音频数据中获取用户的意图信息,包括:提取用户的音频数据中的第一意图信息;根据用户情绪信息,矫正第一意图信息,获取第二意图信息作为用户的意图信息。通过用户情绪信息,可以矫正第一意图信息,提高确定的用户的意图信息的准确度。
[0012]
另外,人物角色包括:关联角色和常规角色,关联角色为用户的社交关系网络中的角色,常规角色为用户的社交关系网络之外的角色;根据用户情绪信息和意图信息,从存储的角色中选取匹配的交互角色,包括:获取用户的社交关系网络;根据用户情绪信息、用户的社交关系网络以及意图信息,判断关联角色中是否存在匹配的交互角色,获得判断结果;若判断结果指示关联角色中不存在匹配的交互角色,则从常规角色中选取交互角色;若判断结果指示关联角色中存在匹配的交互角色,则从关联角色中选取匹配的交互角色。关联角色是用户的社交关系网络中的人物角色,获取用户熟悉角色的声音作为交互合成音,提高用户的满意度;另外优先在关联角色中匹配交互角色,可以提高匹配的速度。
[0013]
另外,获取用户的音频数据,解析用户的用户情绪信息,包括:对用户的音频数据进行预处理,预处理包括:预加重和/或语音端点检测;提取处理后的用户的音频数据的情绪特征信息;根据提取的情绪特征信息以及预设的情绪识别模型,获取用户的情绪信息。对用户的音频数据进行预处理,提高提取情绪特征信息的准确度,采用预设的情绪识别模型进行情绪识别,识别速度快且准确。
[0014]
另外,根据获取的交互合成音,与用户进行语音交互,包括:根据用户情绪信息,获取选取的交互合成音的交互情绪信息;按照选取的交互合成音以及交互情绪信息,生成与用户语音交互的交互语音。进一步提高了电子设备的拟人化程度。
[0015]
另外,根据获取的交互合成音,与用户进行语音交互,包括:根据意图信息,获取与用户交互的交互文本信息;根据获取的交互合成音以及交互文本信息,生成与用户语音交互的交互语音。利用交互合音和交互文本信息生成交互语音,可以根据不同的情绪发出交互文本信息的内容,提高电子设备交互的质量。
附图说明
[0016]
一个或多个实施例通过与之对应的附图中的图片进行示例性说明,这些示例性说明并不构成对实施例的限定,附图中具有相同参考数字标号的元件表示为类似的元件,除非有特别申明,附图中的图不构成比例限制。
[0017]
图1是根据本发明提供的第一实施例中的一种语音交互的方法的流程图;
[0018]
图2是根据本发明提供的第二实施例中的一种语音交互的方法的流程图;
[0019]
图3是根据本发明提供的第二实施例中的解析用户的用户情绪信息的一种具体实现示意图;
[0020]
图4是根据本发明提供的第二实施例中一种滤波器的示意图;
[0021]
图5是根据本发明提供的第二实施例中一种相邻两帧音频数据的示意图;
[0022]
图6是根据本发明提供的第二实施例中音素和状态之间关系的示意图;
[0023]
图7是根据本发明提供的第二实施例中用户的社交关系网络的示意图;
[0024]
图8是根据本发明提供的第三实施例中的一种语音交互的方法的流程图;
[0025]
图9是根据本发明提供的第四实施例中的一种语音交互的装置的结构框图;
[0026]
图10是根据本发明提供的第五实施例中的一种电子设备的结构框图。
具体实施方式
[0027]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本申请而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本申请所要求保护的技术方案。
[0028]
以下各个实施例的划分是为了描述方便,不应对本发明的具体实现方式构成任何限定,各个实施例在不矛盾的前提下可以相互结合相互引用。
[0029]
本发明的第一实施方式涉及一种语音交互的方法。其流程如图1所示,包括:
[0030]
步骤101:获取用户的音频数据,解析用户的用户情绪信息。
[0031]
步骤102:根据用户情绪信息,获取与用户情绪信息匹配的交互合成音。
[0032]
步骤103:根据获取的交互合成音,与用户进行语音交互。
[0033]
本发明实施方式相对于现有技术而言,获取用户的情绪信息,获取与用户情绪信息匹配的交互合成音,根据该交互合成音与用户进行语音交互,由于与用户进行交互的交互合成音不再是一成不变的声音,在用户不同的情绪下,与情绪匹配的交互合成音不同,使得用户会感受到是与具有感情的电子设备进行语音交互,提高了电子设备的拟人化程度,提高了用户使用电子设备进行语音交互的使用体验感。
[0034]
本发明的第二实施方式涉及一种语音交互的方法。第二实施方式是对第一实施方式的详细介绍。
[0035]
该语音交互的方法,可以应用于电子设备,例如,音箱、家庭助手装置、空调、电视机、车载装置等。也可以应用于与智能设备连接的服务器。在本示例中,应用该语音交互的方法的场景有多种,例如,以下三种场景:
[0036]
场景一:用户为老人,当音箱和该用户进行语音交互时,可以根据用户情绪信息,判断该用户此时的真正意图是与家人进行语音交互,则音箱使用该用户的外孙的声音和老人聊天,可以让用户感受到和家人聊天的愉快体验,使老人走出孤寂的情绪。
[0037]
场景二:用户可以与音箱闲聊倾诉心中的故事,在音箱感知到用户情绪信息为悲伤时,可以采用一种平稳温和的语气与用户进行对话,从而可以更好的充当好一个情感倾诉的角色,抚慰用户悲伤的情绪。
[0038]
场景三:用户为儿童时,音箱可以使用小孩的声音回复,从而可以和小孩分享快乐;当小孩伤心的时候,音箱可以使用母亲富有磁性的合成音进行回复,这样可以更好的安慰小孩,使小孩走出伤心的情绪。
[0039]
下面结合图2对该语音交互的方法进行详细的介绍,流程如图2所示。
[0040]
步骤201:获取用户的音频数据,解析用户的用户情绪信息。
[0041]
具体地,为了提高智能设备处理用户的音频数据的速度,本实施方式中该语音交互的方法应用于服务器,该服务器与智能设备通信连接,智能设备将采集到的用户的音频
数据发送至服务器。
[0042]
在一个例子中,解析用户的用户情绪信息可以采用如图3所示的子步骤。
[0043]
子步骤s11:对用户的音频数据进行预处理,获取处理后的音频数据,其中,预处理包括:预加重和/或语音端点检测。
[0044]
具体地,对用户的音频数据进行预处理,预处理包括预加重,或者语音端点检测;或者预处理既包括预加重也包括语音端点检测。
[0045]
预加重是一种对语音信号的高频分量进行补偿的方法。这种方法是增大信号跳变边沿后第一个跳变比特(binary digit,“bit”)的幅度。由于跳变bit代表了信号里的高频分量,对音频数据进行预加重处理,可以提高音频数据中高频分量,使音频数据的频谱变得平坦,便于频谱分析或者声道参数分析。
[0046]
此外,该预加重处理后,将预加重处理后的信号输入反混叠滤波器,通过该反混叠滤波器可以减少混叠频率分量,提高音频数据的质量。
[0047]
值得一提的是,音频数据从整体来看是随时间变化的,是一个非平稳过程,不能使用处理平稳信号的数字信号处理技术对其进行分析处理。但是,不同的声音是由人的口腔肌肉运动构成声道形状变化而产生的响应,这种肌肉运动对于音频数据的频率来说是非常缓慢的,因此音频数据具有时变特性,在一个短时间范围内如10-30ms,音频数据的特性基本保持相对稳定,具有短时平稳性。因此,可以在经过反混叠滤波器之后,对音频数据进行短时分析处理。
[0048]
可以理解的是,音频数据通常需要进行分帧和加窗操作,以便后续提取语音信号的特征。
[0049]
分帧操作是指将音频数据分为一段一段,每一段称为一帧,一帧的时间一般为10-30ms,为了使帧与帧之间平滑过渡,保持连续性,使用交叠分段的方法进行分帧。加窗操作是指预设的的窗函数ω(n)乘以采样函数s(n),从而形成加窗语音信号,窗函数可以是矩形窗和汉明窗,n指的是窗口长度,即样本点个数。采样频率可以为8khz。
[0050]
在音频数据进行了分帧加窗的处理后,可以进行端点检测,以准确地找出音频信号的起始点和结束点,从而有效分离有效信号和无效的噪声信号。
[0051]
获取经过端点检测处理后的音频数据。
[0052]
子步骤s12:提取处理后的音频数据的情绪特征信息。
[0053]
经过语音预处理之后,获得了多帧的音频数据。每一帧数据进行快速傅里叶变换(fast fourier transform,简称“fft”),从而将时域数据转为频域数据,将fft变换后的频域数据在时间上堆叠,形成声谱图。
[0054]
fft中含有参数n,n表示进行fft处理的点数,若一帧中点的个数小于n,则将该帧中的点数零填充至n的长度。对一帧数据做fft后会得到n点的复数,该点的模值就是该频率值下的幅度特性。每个点对应一个频率点,某一点n(n从1开始)表示的频率为f
n
=(n-1)*f
s
/n,第一个点(n=1,fn等于0)表示直流信号,最后一个点n的下一个点表示采样频率fs(n=n+1,fn=fs时,实际上这个点是不存在的)。对音频数据进行fft处理后可以得到n个频点,频率间隔(或者频率分辨率)为fs/n,比如,采样频率为16000,n为1600,那么对音频数据进行fft处理后得到1600个点,频率间隔为10hz,fft得到的1600个值的模可以表示1600个频点对应的振幅。因为fft具有对称性,当n为偶数时取n/2+1个点,当n为奇数时,取(n+1)/2个
点,比如n为512时最后会得到257个值。
[0055]
人耳听到的声音高低和实际频率不呈线性关系,用mel频率更符合人耳的听觉特性,即在1000hz以下呈线性分布,1000hz以上呈对数增长,mel频率与实际频率的转换公式可以表示为:
[0056][0057]
其中,f
mel
表示mel频率,f表示实际频率。
[0058]
假设使用10个梅尔滤波器组,为了获得滤波器组需要选择一个高频率和低频率,例如,可以将300hz作为低频率,8000hz作为高频率。若采样率是8000hz,那么低频率应该限制为4000hz。将低频率和高频率转为mel频率,可以得到401.25mel和2834.99mel。因为用10个滤波器,需要12个点来划分出10个区间,在401.25mel和2834.99mel之间划分出12个点:m(i)=(401.25,622.50,843.75,1065.00,1286.25,1507.50,1728.74,1949.99,2171.24,2392.49,2613.74,2834.99)。将以上12个点转回实际频率:h(i)=(300,517.33,781.90,1103.97,1496.04,1973.32,2554.33,3261.62,4122.63,5170.76,6446.70,8000);将上述12个点转回实际频率,即可得到频率间隔,可以表示为:
[0059]
f(i)=floor((n+1)*h(i)/fs)公式(2);
[0060]
其中,floor表示转回实际频率的函数;n为fft长度,默认为512,fs为采样频率,默认为16000hz,h(i)表示实际频率;则f(i)=(9,16,25,35,47,63,81,104,132,165,206,256)。这里256刚好对应512点fft的8000hz。再创建滤波器,第一个滤波器从第一个点开始,在第二个点到达最高峰,第三个点跌回零。第二个滤波器从第二个点开始,在第三个点到达最大值,在第四个点跌回零。以此类推,十组滤波器的示意图如4图所示。可以看到随着频率的增加,滤波器的宽度也增加。
[0061]
滤波器输出的计算公式如公式(3)所示:
[0062][0063]
其中,m表示滤波器数量,m的取值范围为1~m,本示例中m=10。k表示fft中的256个频点的编号,一个fft内有256个频点,k的取值范围为1~256。
[0064]
将滤波器的输出应用到能量谱后得到梅尔谱,具体的可以采用公式(4):
[0065][0066]
其中,|x(k)|
2
表示能量谱中第k个点的能量。以每个滤波器的频率范围内的输出作为权重,乘以能量谱中对应频率的对应能量,将滤波器范围内的能量加起来。例如,第一个滤波器负责的是9和16之间的点,那么只对9和16之间的点对应的频率的能量做加权和。
[0067]
每帧音频数据可以获得m个输出数据,对每个输出的数据进行对数对数计算,即可得到梅尔谱,记为log-mels。进行离散余弦变换,即可得到该用户的情绪参数。将情绪参数作为提取到的情绪特征信息。
[0068]
子步骤s13:根据提取的情绪特征信息以及预设的情绪识别模型,获取用户的情绪信息。
[0069]
根据提取到的情绪特征信息以及预设的情绪识别模型,即可得到用户的情绪信息。情绪识别模型可以预先训练,模型的结构可以采用深度学习的结构,如神经网络;也可以使用机器学习的结构,可以采集大量的标注有情绪标签的音频数据进行训练,音频数据的处理方式与步骤s11、步骤s12大致相同,得到情绪特征信息。
[0070]
需要说明的是,若采集的音频数据为网络中已经处理后的音频数据,则可以无需进行端点检测的处理。
[0071]
步骤202:从用户的音频数据中获取用户的意图信息。
[0072]
具体地,存储有预先训练得到的声学模型和语言模型,对用户的音频数据进行语音特征提取,将音频数据依次输入声学模型以及语音模型中,从而得到用户的意图信息。下面介绍声学模型和语言模型的训练过程。
[0073]
不同人的发音、语调、语速等各不相同,比如男人和女人、大人和小孩,即使是同一个字,不同的人发出的声音不同,为了让声学模型可以准备解析出声音中包含的文字信息,需要采集大量的用户的声音,从声音中提取语音特征数据,将提取的语音特征数据组成声学模型数据库。
[0074]
同理语言模型需要采集大量的文本信息;从而使得语言模型可以调整声学模型所得到的不合逻辑的字词,使得解析的用户的意图信息准确。
[0075]
将音频数据输入声学模型之前,可以切除首尾端的静音数据,避免对后续步骤造成干扰。静音切除操作之后,可以对采集的音频数据进行分帧、加窗处理。帧与帧之间一般是有交叠的,如图5所示。图5中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠,即为以帧长25ms、帧移10ms分帧。分帧后,音频数据被划分n小段。对分帧加窗处理后的音频数据进行梅尔频率倒谱系数(mel frequency cepstrum coefficient,简称“mfcc”)特征提取,本示例中假设声学特征是12维,那么将形成一个12行、n列的一个矩阵,称之为观察序列,这里n为总帧数,n为大于1的整数。之后通过声学模型和语言模型将该矩阵转换为文本信息。为了便于理解,本示例中将先介绍声音中的音素和状态。
[0076]
单词或单个字的发音均是由音素构成。例如,英语中的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见the cmu pronouncing dictionary。汉语一般用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。状态是比音素更小的语音单位。通常把一个音素划分成3个状态。
[0077]
通常语音识别有三步:第一步,把帧识别成状态;第二步,把状态组合成音素;第三步,把音素组合成单词。如图6所示,图6展示了音素和状态之间的关系;图6中每个小竖条代表一帧,多帧语音对应一个状态,每三个状态组合成一个音素,多个音素组合成一个单词。因此,若获取了每帧语音对应的状态了,即可获知对应的文字信息。本示例中,基于此原理,通过声学模型和语言模型获取每帧语音的观察概率、转移概率和语言概率。观察概率为每帧对应每个状态的概率;转移概率为每个状态转移到自身或转移到下个状态的概率;语言概率为根据语言统计规律得到的概率。
[0078]
其中,观察概率和转移概率由声学模型确定,语言概率由语言模型确定。语言模型通过大量的文本数据训练获得,可以利用语言本身的统计规律来帮助提升识别正确率。
[0079]
为了避免出现相邻两帧间的状态号都不相同的情况,例如,语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么会组合成300个音素,而实际该语音中的音素少于300。由于每帧很短,相邻帧的状态号应当相同。本示例中提出使用隐马尔可夫模型(hidden markov model,简称“hmm”)。
[0080]
首先构建一个状态网络。其次,从状态网络中寻找与声音最匹配的路径。
[0081]
输出的文本信息为预先的网络中的信息,避免了得到不相干的文本信息。
[0082]
状态网络越大,解析的文本信息就越准确率。在实际应用中,可以构建合理大小的状态网络。
[0083]
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为viterbi(维特比)算法,公式可以如公式(5)所示;
[0084][0085]
s(v=j,n)=max{s(v=i,n-l)*t(i,j,n)|i=1,...,v}
ꢀꢀꢀ
公式(5);
[0086]
其中s(v,n)表示的是以v结尾的最大概率的序列的概率,t(i,j,n)为第n-1步从i跳到第n步的j的概率,用于寻找全局最优路径。搜索出来最优路径,即解析出了文本信息。
[0087]
步骤203:根据用户情绪信息和意图信息,从预先存储的人物角色中获取与用户情绪匹配的交互角色。
[0088]
具体地,预先存储人物角色以及各人物角色各自对应的合成音。人物角色包括:关联角色和常规角色,关联角色为用户的社交关系网络中的角色,常规角色为用户的社交关系网络之外的角色。用户的社交关系网络可以预先存储,可以由用户输入。社交关系网络还可以根据用户输入的人物角色与用户自身的关系确定,例如,用户输入人物a,对应与自身的关系为女儿;人物b对应儿子;人物c对应同性友人,人物d为外孙,人物e为路人;如图7所示,根据用户输入的各人物与自身的关系,可以获得该用户的社交关系网络,即图7中虚线框中所表示网络;且获知人物角色a、b、c、d均为关联角色,而人物角色e与用户没有关系,处于虚线框外,为常规角色。
[0089]
常规角色可以在网络中采集不同年龄、性别的人物,以及各常规角色对应的声音样例。关联角色的声音样例可以由用户输入,或者由电子设备采集获得,例如,可以由该用户的各家庭成员依次录入各自的声音。可以根据获取的各人物角色的声音样例,构建情感数据库,构建的情感数据库中可以根据实际的需要进行设置,例如,针对汉语的声音;该情感数据库可以包括多模态、多通道的情感数据库accorpus_mm;情感语音识别数据库accorpus_sr;汉语普通话情感分析数据库accorpus_sa。例如,accorpus_sr子库共由25男25女的5类情感得到,5类情感分别为中性、高兴、生气、恐惧和悲伤,以16khz采样,16bit量化;每个发音者的数据均包含语音情感段落和语音情感命令两种类型。
[0090]
需要说明的是,为了准确地匹配交互角色,可以采集关联角色的基于5种基本情绪的声音,例如,中性、高兴、生气、恐惧和悲伤。
[0091]
在一个例子中,根据用户情绪信息和意图信息,判断关联角色中是否存在匹配的交互角色,获得判断结果;若述判断结果指示关联角色中不存在匹配的交互角色,则从常规角色中选取交互角色;若判断结果指示关联角色中存在匹配的交互角色,则从关联角色中
选取匹配的交互角色。
[0092]
具体地,可以预先设置匹配策略,例如,当用户处于悲伤,且意图信息包括:聊天、放音乐等内容时,选取该用户的亲人;当用户处于高兴时,且意图信息包括:分享、聊天等内容时;可以选择与用户通话次数多的关联角色,或者选取用户设置有高优先级别的关联角色等。根据用户的情绪信息同时结合该用户的意图信息,在关联角色中匹配交互角色;例如;用户当前的意图信息为“讲故事”;同时该用户的情绪处于恐惧的情绪中;此时,在用户的关联角色中查找可以保护用户的人物角色,如用户在社交关系网络中父亲、兄弟等关联人物。若在存储的关联人物中没有查找父亲、兄弟等人物角色,则可以从常规角色中查找声音浑厚、厚重的人物角色作为交互角色。
[0093]
再例如,用户的角色为儿子,用户的意图为“聊天”;用户的情绪信息为悲伤,结合该情绪信息,根据预先设置的对应关系,可以选取与该用户关系密切的关联角色作为交互角色,待播放的内容则可以根据用户的意图信息确定。
[0094]
值得一提的是,优先在关联角色中匹配交互角色,可以提高匹配的速度。
[0095]
步骤204:根据交互角色对应的合成音,生成交互合成音。
[0096]
值得一提的是,由于选取的交互角色与该用户的情绪信息匹配,使得用户可以缓解当前的情绪。辅助用户缓解悲伤、愤怒等负面情绪。
[0097]
需要说明的是,步骤202至步骤204是对第一实施方式中步骤102的具体介绍。
[0098]
步骤205:根据意图信息,获取与用户交互的交互文本信息。
[0099]
具体地,可以根据用户的意图信息获取待播放的内容信息;按照该交互角色对应的合成音播放该待播放的内容信息。
[0100]
步骤206:根据获取的交互合成音以及交互文本信息,生成与用户语音交互的交互语音。
[0101]
具体地,播放该交互语音,若该语音交互的方法应用于服务器,则生成的交互语音可以发送至电子设备,由电子设备播放该交互语音,例如,服务器将生成的交互语音发送至音响,由音响播放该交互语音。
[0102]
需要说明的是,步骤205至步骤206是对第一实施例中步骤103的详细介绍。
[0103]
上面各种方法的步骤划分,只是为了描述清楚,实现时可以合并为一个步骤或者对某些步骤进行拆分,分解为多个步骤,只要包括相同的逻辑关系,都在本专利的保护范围内;对算法中或者流程中添加无关紧要的修改或者引入无关紧要的设计,但不改变其算法和流程的核心设计都在该专利的保护范围内。
[0104]
本发明第三实施方式涉及一种语音交互的方法,本实施方式是对第二实施方式的进一步改进,主要改进之处在于,第三实施方式中根据用户情绪信息和第一意图信息,获取用户的意图信息。其流程如图8所示:
[0105]
步骤301:获取用户的音频数据,解析用户的用户情绪信息。
[0106]
步骤302:从用户的音频数据中获取用户的意图信息。
[0107]
在一个例子中,提取用户的音频数据中的第一意图信息;根据用户情绪信息,矫正第一意图信息,获取第二意图信息作为用户的意图信息。
[0108]
具体地,利用声学模型和语言模型提取音频数据中的第一意图信息,声学模型和语言模型的训练过程与第二实施方式中的大致相同,此处不再进行赘述。判断该第一意图
信息指示的应用场景,以及该应用场景下的情绪信息;将该应用场景下的情绪信息以及第一意图信息进行比对,若两者不同,调整该第一意图信息,得到第二意图信息。例如,提取到的第一意图信息为“播放听生日快乐歌”,生日快乐歌的播放场景通常携带高兴的情绪;而此时用户情绪信息为悲伤;该播放生日快乐歌曲的场景匹配的情绪为高兴,将该高兴的情绪与用户情绪信息进行比对,两者不同;则对“播放听生日快乐歌”的意图进行矫正,预设的矫正策略为:意图信息对应的情绪为高兴,用户情绪信息为悲伤,则更改该用户的意图为聊天。
[0109]
需要说明的是,矫正策略可以包括至少两种,以便可以准确矫正第一意图信息。
[0110]
将第二意图信息作为用户的意图信息。
[0111]
步骤303:根据用户情绪信息和意图信息,从预先存储的人物角色中获取与用户情绪匹配的交互角色。
[0112]
步骤304:根据交互角色对应的合成音,生成交互合成音。
[0113]
步骤301、步骤303及304与第二实施方式中的步骤201、步骤203及步骤204大致相同,此处将不再进行赘述。
[0114]
步骤305:根据用户情绪信息,获取交互合成音的交互情绪信息。
[0115]
具体地,由于存储了交互角色在各情绪下的声音,可以获取与用户情绪信息匹配的交互情绪信息,从而选取具有该交互情绪信息的交互合成音。例如,用户情绪信息为高兴,获取的交互合成音的交互情绪信息也为高兴。
[0116]
步骤306:按照交互合成音以及交互情绪信息,生成与用户语音交互的交互语音。
[0117]
具体地,按照该交互情绪信息、交互合成音以及意图信息,生成与用户语音交互的交互语音,使得交互语音也具有交互情绪。
[0118]
通过交互情绪信息,交互语音也具有情绪,使得与用户进行交互更加拟人化,提高用户的体验。
[0119]
本发明第四实施方式涉及一种语音交互的装置,语音交互的装置40的结构框图如图9所示,包括:识别模块401、获取模块402和交互模块403。识别模块401用于获取用户的音频数据,解析用户的用户情绪信息;获取模块402用于根据用户情绪信息,获取与用户情绪信息匹配的交互合成音;交互模块403用于根据获取的交互合成音,与用户进行语音交互。
[0120]
值得一提的是,本实施方式中所涉及到的各模块均为逻辑模块,在实际应用中,一个逻辑单元可以是一个物理单元,也可以是一个物理单元的一部分,还可以以多个物理单元的组合实现。此外,为了突出本发明的创新部分,本实施方式中并没有将与解决本发明所提出的技术问题关系不太密切的单元引入,但这并不表明本实施方式中不存在其它的单元。
[0121]
本发明第五实施方式涉及一种电子设备,该电子设备的结构框图如图10所示,包括至少一个处理器501;以及,与至少一个处理器501通信连接的存储器502;其中,存储器502存储有可被至少一个处理器501执行的指令,指令被至少一个处理器501执行,以使至少一个处理器501能够执行上述的语音交互的方法。
[0122]
其中,存储器502和处理器501采用总线方式连接,总线可以包括任意数量的互联的总线和桥,总线将一个或多个处理器501和存储器502的各种电路链接在一起。总线还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是
本领域所公知的,因此,本文不再对其进行进一步描述。总线接口在总线和收发机之间提供接口。收发机可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。经处理器处理的数据通过天线在无线介质上进行传输,进一步,天线还接收数据并将数据传送给处理器。
[0123]
处理器负责管理总线和通常的处理,还可以提供各种功能,包括定时,外围接口,电压调节、电源管理以及其他控制功能。而存储器可以被用于存储处理器在执行操作时所使用的数据。
[0124]
本发明第六实施方式涉及一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时实现上述的语音交互的方法。
[0125]
本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0126]
本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips