
 商标分类
商标分类  商标转让
商标转让 
一种智能数字化教学模型的制作方法
 2021-01-25 15:01:53|
2021-01-25 15:01:53| 299|
299| 起点商标网
起点商标网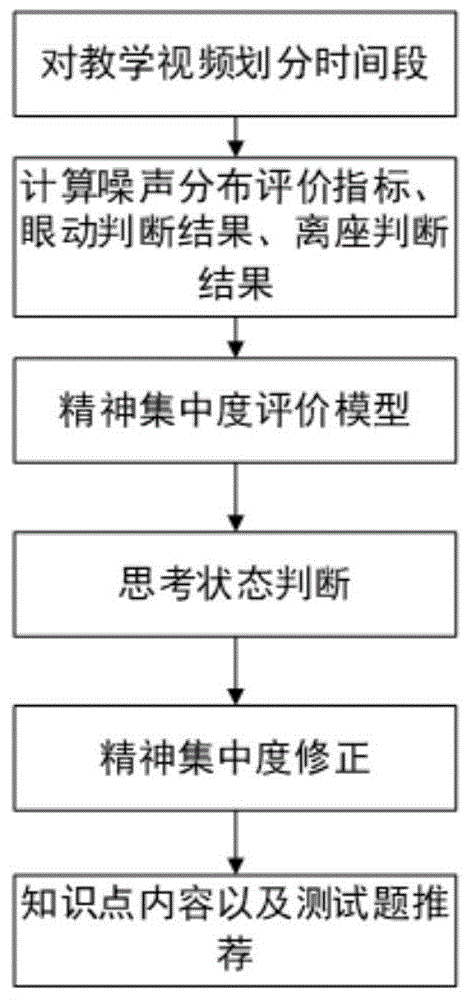
本发明涉及数字化教学、计算机视觉技术领域,具体涉及一种智能数字化教学模型。
背景技术:
随着数字化教育的推广,教育教学越来越趋于智能化。目前,教学系统通常通过分析一定时间段内数据修正教学策略,该方法存在的问题在于:第一,数据分析不具备实时性,策略调整后仍需要一定时间验证调整方向是否正确,会出现一定的滞后性;第二,通常根据眼动追踪进行内容推荐,不能适用于教育教学。
技术实现要素:
本发明的目的在于针对上述现有技术存在的缺陷,提出一种智能数字化教学模型。
一种智能数字化教学模型,该模型执行以下步骤:
步骤1,根据教学视频的知识点分布将视频划分为多个时间段,针对每个时间段执行步骤2-6;
步骤2,采集视频播放期间的声音信号,根据声音信号中包含用户产生噪声的时间长度得到噪声分布评价指标的计算结果;根据左右瞳孔中心坐标判断瞳孔中心是否识别正常,如果正常则根据瞳孔中心坐标是否处于预设区间判断眼动是否正常;判断用户是否离座;
步骤3,建立精神集中度评价模型为:
步骤4,将人脸三维关键点分为面部中心区域关键点集、面部两侧区域关键点集,综合两个关键点集与鼻尖关键点之间的距离,判断用户是否处于思考状态,若是则转至步骤5,否则转至步骤6;
步骤5,统计用户处于思考状态的时间;判断思考状态时间段内声音信号中是否存在周期高频信号,如果存在,则将周期高频信号的时长从tnoise中减去,得到修正的噪声分布评价指标的计算结果;将思考状态时间段内眼动判断结果为异常的修正为眼动正常;根据修正结果对精神集中度评价结果进行修正;
步骤6,根据时间段内教学视频的内容、精神集中度评价结果、思考状态时间,为用户推荐相应难度的知识点内容以及测试题。
进一步地,所述综合两个关键点集与鼻尖关键点之间的距离,判断用户是否处于思考状态包括:
计算
进一步地,所述综合两个关键点集与鼻尖关键点之间的距离,判断用户是否处于思考状态包括:
计算
进一步地,所述综合两个关键点集与鼻尖关键点之间的距离,判断用户是否处于思考状态包括:
计算
进一步地,所述瞳孔中心坐标通过如下方法获得:对采集的红外图像进行分析,定位瞳孔中心坐标。
进一步地,所述根据左右瞳孔中心坐标判断瞳孔中心是否识别正常,如果正常则根据瞳孔中心坐标是否处于预设区间判断眼动是否正常包括:
对采集的彩色图像进行人脸关键点检测,结合深度信息,得到人脸三维关键点坐标;
以左右眼角关键点所在直线为横轴,以左眼角关键点指向右眼角关键点的方向为x轴方向,从鼻尖关键点向横轴作垂线,鼻尖关键点指向垂点的方向为y轴方向;
根据左右瞳孔中心坐标判断瞳孔中心是否识别正常;
判断左瞳孔中心点坐标(xl,yl)是否满足xl∈[-xm,-xn],yl∈[-ym,yn],满足时判断眼动正常,否则判断为眼动异常,xm、xn、ym、yn、margin2为人为设置的经验阈值。
进一步地,所述根据左右瞳孔中心坐标判断瞳孔中心是否识别正常包括:
当左右瞳孔中心点坐标(xl,yl)、(xr,yr)满足(|xl|-|xr|)2+(|yl|-|yr|)2≤margin2时,判定识别正常,否则判定为识别异常,margin2为阈值。
进一步地,所述判断用户是否离座包括:
对采集的彩色图像进行人体关键点检测,将检测关键点坐标映射到深度图,得到检测关键点深度信息;
若检测关键点深度信息大于设定阈值,则判断为离座,否则判断为未离座。
进一步地,所述检测关键点为肩部关键点。
进一步地,所述根据时间段内教学视频的内容、精神集中度评价结果、思考状态时间,为用户推荐相应的知识点内容以及测试题包括:
若精神集中度评价结果不大于第一设定阈值,判断为用户该处知识点精神不集中,推送内容为该时间段知识点的基础内容以及相关基础难度测试题;
若精神集中度评价结果大于第一设定阈值,但不存在思考状态,判断用户在教学过程已掌握基础知识,推送内容为该时间段知识点的拓展内容以及相关基础难度测试题;
若精神集中度评价结果大于第一设定阈值,且存在一定时间的思考状态,判断用户在教学过程已掌握拓展内容,推送内容为该时间段知识点的考点内容以及相关拓展难度测试题;
若精神集中度评价结果大于第一设定阈值并大于预设等级,且存在较长时间的思考状态,判断用户在教学过程已经掌握所有知识点,推送内容为该时间段知识点的考点内容以及试题难度测试题。
本发明与现有技术相比,具有以下有益效果:
1.根据教学视频的知识点分布将视频划分为多个时间段,分别对每个时段的用户状态进行实时分析,结合用户状态进行实时内容推荐,不仅能够适用于教育教学,而且解决了现有教育教学中分析不具备实时性的问题,提高了分析和推荐的实时性、针对性。
2.本发明结合噪声分布评价指标、眼动分析结果、离座判断结果构造精神集中度模型,综合多种影响因素提高了精神集中度判断精度;对时间段内的精神集中度进行量化计算,相比于传统的二值判断,在内容推荐阶段,有利于提供更加细分的用户状态下的推荐结果。
3.本发明将面部关键点分为中心区域关键点、两侧区域关键点,为两种类型赋予不同的权重,提高了思考状态模型的判断精度;以内眼角关键点与鼻尖关键点之间的距离和/或上唇中心关键点与鼻尖关键点之间的距离为参考距离,一方面能够降低用户前后移动带来的影响,另一方面能够隔离工况,使模型适用于不同人,扩大模型的适用范围;利用满足一定条件的距离指数函数,扩大表情变化导致的微小距离变化,进一步提高思考状态的判断结果。
4.本发明利用思考状态判断结果对精神集中度分析指标进行修正,进一步提高了精神集中度的计算精度,有助于提高内容推荐的精度。
5.本发明根据眼角关键点以及鼻尖关键点构建坐标系,该坐标系具有相对性,有助于提高眼动判断效率,而且设计判断规则进行识别是否异常的判断,避免后续误判,提高了眼动判断精度。
附图说明
图1为本发明方法流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本发明提供一种智能数字化教学模型,可应用于网络课程在线学习过程中,自动分析教学质量,并推送相应的内容给用户。图1为本发明方法流程图。下面通过具体实施例来进行说明。
实施例一:
实施例场景限制为在线学习移动端,该移动端可为手机、平板电脑等具有声音采集模块、图像采集模块的设备,需要获取教学移动端的相机、麦克风等应用权限。
一种智能数字化教学模型,模型执行以下步骤:
步骤1,根据教学视频的知识点分布将视频划分为多个时间段,针对每个时间段执行步骤2-6。
基于教学视频课程长度以及内容,根据知识点分布以及经验划分出若干时间段。例如,课程长度为45分钟,因此按经验设置划分时间段长度为5分钟,根据课程内容的重点难点分布划分时间段,即所划分时间段的起始时间戳与重点难点讲解开始时刻对齐,若内容讲解时间不足5分钟,按5分钟划分,若超过5分钟,相应延长该时间段。
本方案根据精神集中度评价结果、思考状态结果以及知识点内容进行教学内容推荐。精神集中度评价模型基于三类评价指标,包括噪声分布评价指标、眼动分析评价指标以及离座分析评价指标。
步骤2,采集视频播放期间的声音信号,根据声音信号中包含用户产生噪声的时间长度得到噪声分布评价指标的计算结果;根据左右瞳孔中心坐标判断瞳孔中心是否识别正常,如果正常则根据瞳孔中心坐标是否处于预设区间判断眼动是否正常;判断用户是否离座。
信息感知方法为:噪声分布评价指标所需感知信息的感知方法为通过麦克风采集声音信号;眼动分析评价指标以及离座分析评价指标所需感知信息的方法为通过摄像头采集rgb-d图像和ir图像。
噪声分布评价指标获取方式为:首先通过麦克风采集声音信号,采集时间段为教学视频播放时间段;所采集声音信号通过离散傅里叶变换转换至频域。一种实施方式是基于先验信息得知用户产生的噪声的频率高于正常声音或低于正常声音(播放教学视频无用户产生噪声时的声音),因此在频域中设置经验阈值margin1,筛除掉低于或高于经验阈值的声音信号。另一种实施方式是基于先验信息得知播放教学视频无用户产生噪声时的声音频率范围(该声音频率范围可为多个频率区间,可以提高检测精度),将处于声音频率范围之内的声音信号筛除。经过筛除后所保留的声音信号通过逆傅里叶变换转换至时域;统计所保留声音信号所覆盖的时间长度tnoise,与教学视频播放的时间段长度t计算噪声分布评价指标
对采集的彩色图像进行人脸关键点检测,结合深度信息,得到人脸三维关键点坐标;以左右眼角关键点所在直线为横轴,以左眼角关键点指向右眼角关键点的方向为x轴方向,从鼻尖关键点向横轴作垂线,鼻尖关键点指向垂点的方向为y轴方向;根据左右瞳孔中心坐标判断瞳孔中心是否识别正常;判断左瞳孔中心点坐标(xl,yl)是否满足xl∈[-xm,-xn],yl∈[-ym,yn],满足时判断眼动正常,否则判断为眼动异常,xm、xn、ym、yn为人为设置的经验阈值。
具体地,首先通过摄像头采集rgb-d图像及ir图像;对rgb图像进行人脸关键点检测,并映射至深度图depth中,得到人脸3dlandmarks信息;通过ir图像得到瞳孔位置;通过人脸3dlandmarks信息,提取出眼角关键点坐标canl1,canl2,canr1,canr2,canl代表左眼眼角点,canr代表右眼眼角点,下标1代表内眼角点,下标2代表外眼角点,鼻尖关键点坐标nose,通过ir图像信息得到瞳孔中心点坐标pupill,pupilr,下标l、r分别代表左右,上述坐标均为图像坐标,且由于为手机相机拍摄,其图像对齐在手机内部已设置,因此三类坐标在同一图像坐标系中处理;基于先验信息,眼角及鼻尖关键点位置近似不变,两瞳孔中心点每次的偏移近似一致,因此建立坐标系,坐标系横轴为四个眼角关键点所在直线l1,以左眼角关键点指向右眼角关键点的方向为x轴方向,过鼻尖中心点作直线l1的垂线l2,鼻尖中心点指向垂点的方向为y轴方向;设置阈值,当瞳孔中心点在上述坐标系中坐标(xl,yl)、(xr,yr)满足(|xl|-|xr|)2+(|yl|-|yr|)2≤margin2时,该帧处理结果保留,否则判断为识别异常;当处理结果保留时,判断(xl,yl)是否满足xl∈[-xm,-xn],yl∈[-ym,yn],满足时判断该帧处理结果为眼动正常;否则,判断该帧处理结果为眼动异常。上述xm、xn、ym、yn、margin2为设置的经验阈值,可以根据实施场景调整。根据眼动情况对用户精神集中度进行分析较为直观。
离座分析评价指标获取方式为:首先通过rgb图像提取人体关键点,具体为肩部关键点,映射至深度图depth并设置阈值margin3;当肩部关键点所对应的深度均大于该阈值,判断为离座,否则,判断为正常。
步骤3,建立精神集中度评价模型。将步骤2的计算结果、判断结果输入精神集中度评价模型,计算用户的精神集中度,若精神集中度大于第一设定阈值,则转至步骤4,否则转至步骤6。
精神集中度评价模型,该模型基于先验信息,通过上述三类指标构建评价模型,其优点在于可以通过噪声、眼动、离座三个方面在一段时间内联合评价用户的精神集中度,并划分为对应级别,以量化精神集中度。具体模型aemodel(attentionevaluatemodel)为:
本实施例对精神集中度评价模型结果进行分级。一种实施方式是,当γ1、γ2、γ3相等时,若aemodel∈[0,0.2],则评级结果为一级,若aemodel∈(0.2,0.4],则评级结果为二级,若aemodel∈(0.4,0.6],则评级结果为三级,若aemodel∈(0.6,0.8],则评级结果为四级,若aemodel∈(0.8,1],则评级结果为五级。
当判断用户精神集中度评价较好时,本实施例中用户精神集中度评价等级为三级或以上,进一步判断是否用户为思考状态,以便于评价用户在学习时的状态。具体为,设置一个经验阈值margin3,本实施设定阈值为0.4,当精神集中度评价模型输出结果大于阈值margin3,调用思考状态判断模型;否则无需调用。
步骤4,将人脸三维关键点分为面部中心区域关键点集、面部两侧区域关键点集,综合两个关键点集与鼻尖关键点之间的距离,判断用户是否处于思考状态,若是则转至步骤5,否则转至步骤6。
思考状态判断模型,模型的输入为人脸的3dlandmarks数据。思考状态判断模型下,面部关键点应至少包括眉部关键点集合、鼻部关键点集合、唇部关键点集合。首先以鼻尖关键点作为中心点,基于其他各关键点到中心点的距离将3dlandmarks数据分为两个点集,此时需设置经验阈值margin4,该阈值应大于眉头关键点与中心点的距离。当某点到中心点距离小于等于阈值margin4时,将该点分配至点集一ps1为面部中心区域点集,当某点到中心点距离大于阈值margin4时,点集二ps2为面部两侧区域点集。实施者也可以直接进行关键点划分,划分为面部中心关键点集、面部两侧关键点集。优选地,点集一包括与中心点较近的眉部关键点集合、鼻部关键点集合、唇部关键点集合以及下巴关键点集合,点集二包括与中心关键点较远的眉部关键点(例如眉尾关键点)以及其他面部关键点。然后由于眼角内侧关键点到鼻尖关键点的距离d1近似不变,因此以距离d1作为基准值,且根据所分配点集分配不同的权重,面部中心区域点集权重为σ1,面部两侧区域点集权重为σ2,且应满足σ1>σ2,在本发明中取σ1=0.75,σ2=0.25。用于判断的统计值thinkstatemodel即
进一步地,思考状态判断模型还可以为:
进一步地,思考状态判断模型还可以为:
进一步地,思考状态判断模型还可以为:
步骤5,统计用户处于思考状态的时间;判断思考状态时间段内声音信号中是否存在周期高频信号,如果存在,则将周期高频信号的时长从tnoise中减去,得到修正的噪声分布评价指标的计算结果;将思考状态时间段内眼动判断结果为异常的修正为眼动正常;根据修正结果对精神集中度评价结果进行修正。
基于先验信息,考虑到部分用户处于思考状态时可能存在重复行为,例如重复敲击桌面等行为,此时,噪声响度评价指标应排除该类行为所产生的噪声信号的干扰,以提高评价结果的准确率。具体为:当模块二判断用户在某一时间段内属于思考状态时,相应时间段的音频信号通过周期估计的方法判断是否存在周期高频信号,若存在,该高频信号从频域筛除,以修正噪声响度评价指标。所述周期估计的方法为公知技术,实施者可采用基于波形的自相关法、平均幅度差法;基于变换法的倒谱法等。考虑到思考状态时,眼睛出现偏离,同样对模型进行修正。
步骤6,根据时间段内教学视频的内容、精神集中度评价结果、思考状态判断结果,为用户推荐相应难度的知识点内容以及测试题。
内容推送模型,具体为设置推送规则进行内容的推送,规则具体如下:
当精神集中度评价结果为一级或二级,此时判断为用户该处知识点精神不集中,推送内容为该处知识点基础内容以及相关基础难度测试题;
经精神集中度评价结果为三级、四级或五级,但不存在一定时间的思考状态,判断用户在教学过程已掌握基础知识,推送内容为该处知识点的拓展内容以及相关基础难度测试题;
经精神集中度评价结果为三级或四级,且存在一定时间的思考状态,判断用户在教学过程可能已掌握拓展内容,推送内容为该处知识点的考点内容以及相关拓展难度的测试题;
经精神集中度评价结果为五级,且存在较长时间的思考状态,判断用户在教学过程已经掌握整个知识点,推送内容为该处知识点的考点内容以及试题难度的测试题。
通过上述规则进行知识内容的推送,可针对用户在课程上的表现推送对应难度的知识内容以及测试题,便于巩固并提高用户的知识点掌握水平,而不会出现用户知识点掌握水平高于推送内容及测试题难度的情况。
以上实施例仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



