
 商标分类
商标分类  商标转让
商标转让 
图特征提取、脂水分配系数预测方法及图特征提取模型与流程
 2021-01-08 11:01:42|
2021-01-08 11:01:42| 354|
354| 起点商标网
起点商标网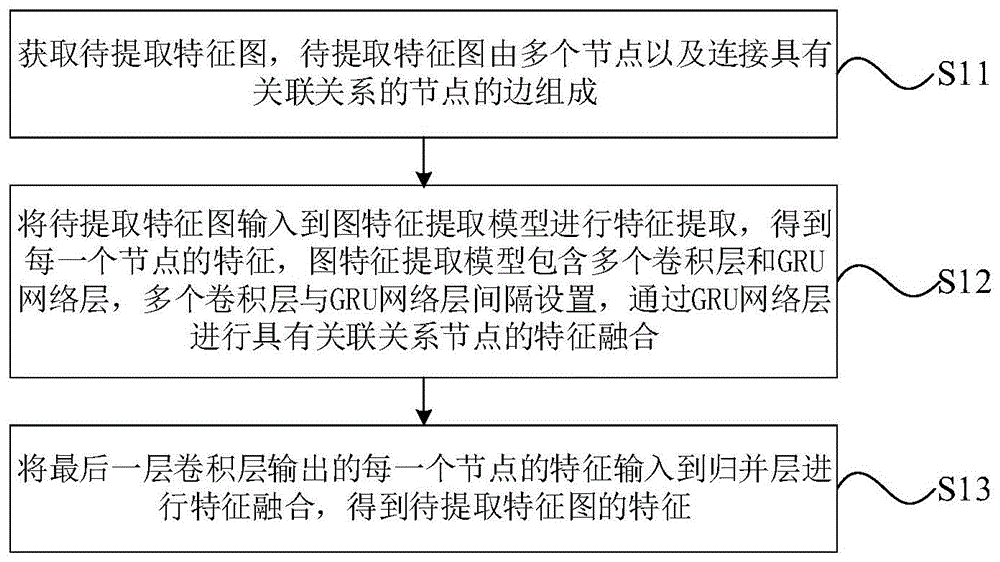
本发明涉及人工智能技术领域,具体涉及一种图特征提取、脂水分配系数预测方法及图特征提取模型。
背景技术:
脂水分配系数logp=物质在辛醇中的浓度/物质在水中的浓度,该指标是药物设计中的重要参考要素,它影响着药物在体内的吸收运转。该指标虽然可以由简单的实验测得,但是在药物设计早期虚拟筛选阶段,需要对大量候选小分子进行实验测定是不现实的,这时药化专家往往会借助软件计算的方法对logp进行粗筛。
相关技术中,通常采用机器学习模型对小分子的logp进行预测,但是特征的提取需要大量的前期工作,而且需要具有较深专业知识和经验,工作量大。故亟待提出一种图特征提取方法,以学到小分子的合理且充足的表征信息,更准确的表达分子的特征,减少工作量。
技术实现要素:
因此,本发明要解决的技术问题在于克服现有技术中特征提取需要大量前期工作,工作量大的缺陷,从而提供一种图特征提取、脂水分配系数预测方法及图特征提取模型。
根据第一方面,本发明实施例公开了一种图特征提取方法,包括:获取待提取特征图,所述待提取特征图由多个节点以及连接具有关联关系的节点的边组成;将所述待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,所述图特征提取模型包含多个卷积层和gru网络层,所述多个卷积层与所述gru网络层间隔设置,通过所述gru网络层进行具有关联关系节点的特征融合;将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到所述待提取特征图的特征。
可选地,所述通过所述gru网络层进行具有关联关系节点的特征融合,包括:
w′=gru(w,aroundw)
其中,aroundw表示图中与节点w连接的所有其他节点v对w节点的总影响;
可选地,所述将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,包括:将所述最后一层卷积层输出的每一个节点的特征输入到归并层,通过所述归并层将每一个节点的特征映射为模拟指纹后进行特征融合。
可选地,所述通过所述归并层将每一个节点的特征映射为模拟指纹后进行特征融合,包括:
其中,w(n)是第n层图卷积计算后节点w的输出特征向量;dim表示任一节点特征向量映射到dim维向量空间中;
根据第二方面,本发明实施例还公开了一种脂水分配系数预测方法,包括如下步骤:利用如第一方面或第一方面任一可选实施方式所述的图特征提取方法对生物小分子进行特征提取;利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。
可选地,所述脂水分配系数预测模型通过下述方式训练得到:获取第一脂水分配系数训练数据以及与所述第一脂水分配系数关联的训练数据,所述第一脂水分配系数相关的训练数据包括:溶解度、熔点、离解系数、在ph=7.4条件下测得的脂水分配系数中的至少一种;将所述第一脂水分配系数训练数据以及与所述第一脂水分配系数相关的训练数据输入到机器学习模型进行预训练,得到脂水分配系数预测模型。
可选地,所述方法还包括:获取第二脂水分配系数训练数据以及与所述第二脂水分配系数相关的训练数据,所述第二脂水分配系数相关的数据与所述第一脂水分配系数相关的训练数据相同,所述第二脂水分配系数训练数据以及与所述第二脂水分配系数相关的训练数据的准确性大于所述第一脂水分配系数训练数据以及与所述第一脂水分配系数关联的训练数据;将所述第二脂水分配系数训练数据以及与所述第二脂水分配系数相关的训练数据输入到所述脂水分配系数预测模型中进行训练,得到目标脂水分配系数预测模型。
根据第三方面,本发明实施例还公开了一种图特征提取模型,包括:输入层,用于获取待提取特征图,所述待提取特征图由多个节点以及连接具有关联关系的节点的边组成;多个卷积层和gru网络层,所述多个卷积层与所述gru网络层间隔设置,每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层,重复所述每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层的步骤,直至最后一个卷积层;归并层,用于将最后一层卷积层输出的每一个节点的特征进行特征融合,并将特征融合结果通过输出层输出。
根据第四方面,本发明实施例还公开了一种计算机设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器执行如第一方面或第一方面任一可选实施方式所述的图特征提取方法的步骤或如第二方面或第二方面任一可选实施方式所述的脂水分配系数预测方法的步骤。
根据第五方面,本发明实施例还公开了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面或第一方面任一可选实施方式所述的图特征提取方法的步骤或如第二方面或第二方面任一可选实施方式所述的脂水分配系数预测方法的步骤。本发明技术方案,具有如下优点:
1.本发明提供的图特征提取方法,通过获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;将待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,图特征提取模型包含多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,通过gru网络层进行具有关联关系节点的特征融合;将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征。本发明实施例在每次卷积操作时使用了gru网络层来把具有关联关系节点的特征信息融合起来,由于gru对输入的不同信息有不同程度的敏感度,gru网络层可通过内部的几个门控子网络保留一些有用信息,丢弃一些无用信息,使得网络的表达能力更好,更适合表达图内部节点之间的相互作用,减少前期的提取工作量,提高效率。
2.本发明提供的脂水分配系数预测方法,通过利用图特征提取方法对生物小分子进行特征提取,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。本发明实施例通过使用图特征提取方法对生物小分子进行特征提取,以学到小分子的合理且充足的表征信息,更准确的表达分子的特征,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测,使得对脂水分配系数预测更加准确,且减少工作量。
3.本发明提供的图特征提取模型,包括:输入层,用于获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层,重复每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层的步骤,直至最后一个卷积层;归并层,用于将最后一层卷积层输出的每一个节点的特征进行特征融合,并将特征融合结果通过输出层输出。本发明实施例通过增加gru网络层,在卷积操作时使用了gru网络层来把具有关联关系节点的特征信息融合起来,由于gru对输入的不同信息有不同程度的敏感度,gru网络层可通过内部的几个门控子网络保留一些信息,丢弃一些无用信息,使得网络的表达能力更好,更适合表达图内部节点之间的相互作用。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中图特征提取方法的一个具体示例的流程图;
图2为本发明实施例中脂水分配系数预测方法的一个具体示例的流程图;
图3为本发明实施例中脂水分配系数预测模型的一个训练方法的一个具体示例图;
图4为本发明实施例中脂水分配系数预测模型的另一个训练方法的一个具体示例图;
图5为xlogp3与本发明实施例中logp的预测散点图;
图6为本发明实施例中图特征提取模型的一个具体示例图;
图7为本发明实施例中图特征提取装置的一个具体示例的原理框图;
图8为本发明实施例中脂水分配系数预测装置的一个具体示例的原理框图;
图9为本发明实施例中计算机设备的一个具体示例图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,还可以是两个元件内部的连通,可以是无线连接,也可以是有线连接。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
本发明实施例公开了一种图特征提取方法,如图1所示,包括:
s11:获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成。
示例性地,该待提取特征图可以为分子图.本发明实施例对该待提取特征图不作具体限定,本领域技术人员可以根据实际情况设定。待提取特征图由多个节点以及连接具有关联关系的节点的边组成,例如,对于分子图,图中的节点为组成分子的各个原子,原子的属性信息包括:形式电荷(formalcharge)、部分电荷(partialcharge)杂化类型(例如,sp、sp2、sp3等)等;边为原子之间的共价键,包括:单键、双键、三键和pi键。
该待提取特征图的获取方法可以为人工上传到服务器,也可以为从数据库中调用,本发明实施例对该待提取特征图的获取方法不作具体限定,本领域技术人员可以根据实际情况设定。
s12:将待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,图特征提取模型包含多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,通过gru网络层进行具有关联关系节点的特征融合。
示例性地,gru网络层是一种特殊的神经网络,通过其内部的几个门控子网络,可以保留输入的待提取特征图中的重要的信息输出到输出特征向量中,同时忽略掉一些无用的信息,因此,gru网络层通过参考目标节点的信息将目标节点的邻居节点的信息累加后再与目标节点的特征信息进行特征融合。
具体的融合方法如下:对于任一节点w,用与它直接相连的其他节点v来进行信息更新,具体地,先利用公式(1)计算w所有邻居节点v的汇总值aroundw,该汇总值就是节点w的所有邻居节点v对w的总影响,再利用公式(2)更新w值本身,这里的更新操作使用了循环神经网络的基本单元gru,可以实现优选择地更新和遗忘。
w′=gru(w,aroundw)(2)
其中,aroundw表示图中与节点w连接的所有其他节点v对w节点的总影响;
2层卷积操作:
w″=gru(w′,aroundw′)(4)
其中,aroundw′表示图中与节点w连接的所有其他节点v对w节点的总影响;w″表示二次卷积操作更新后的节点w的特征向量。
3层卷积操作:
w″′=gru(w″,aroundw″)(6)
其中,aroundw″表示图中与节点w连接的所有其他节点v对w节点的总影响;w″′表示三次卷积操作更新后的节点w的特征向量。
以此类推得到4层卷积操作特征信息……第n层卷积操作特征信息。
s13:将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征。
示例性地,将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征可以为将图中所有节点的特征输入到归并层直接求和,也可以图中每一个节点的特征输入到归并层,通过归并层将每一个节点的特征映射为模拟指纹后进行特征融合,本发明实施例对该待提取特征图的特征的获得方法不作具体限定,本领域技术人员可以根据实际需求情况设定。
本发明提供的图特征提取方法,通过获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;将待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,图特征提取模型包含多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,通过gru网络层进行具有关联关系节点的特征融合;将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征。本发明实施例在每次卷积操作时使用了gru网络层来把具有关联关系节点的特征信息融合起来,由于gru对输入的不同信息有不同程度的敏感度,gru网络层可通过内部的几个门控子网络保留一些信息,丢弃一些无用信息,使得网络的表达能力更好,更适合表达图内部节点之间的相互作用,减少前期的提取工作量,提高效率。
作为本发明实施例一个可选实施方式,上述步骤s13包括:
将最后一层卷积层输出的每一个节点的特征输入到归并层,通过归并层将每一个节点的特征映射为模拟指纹后进行特征融合。
示例性地,将最后一层卷积层输出的每一个节点的特征输入到归并层,通过归并层将每一个节点的特征映射为模拟指纹后进行特征融合具体为:将最后一层卷积层输出的每一个节点的特征输入到归并层,通过归并层将所有节点信息映射到一个x维的位图文件(bitmap)中,构造一个x维的分子指纹,使得特征信息映射到位图文件的不同位置,然后将每一个节点的特征进行融合。在本发明实施例中,该位图文件可以为2048维的。相对于直接将所有的节点的特征信息进行求和得到待提取特征图的特征,特征表达能力更好,不会造成特征信息的混淆和互相遮盖,能够更好的表达待提取特征图的局部和全局特征。
具体地,可通过如下公式进行待提取特征图的特征提取:
其中,w(n)是第n层图卷积计算后节点w的输出特征向量;dim表示任一节点特征向量映射到dim维向量空间中;
本发明实施例还公开了一种脂水分配系数预测方法,如图2所示,包括如下步骤:
s21:利用如上述图特征提取方法实施例的图特征提取方法对生物小分子进行特征提取。
示例性地,利用如上述图特征提取方法实施例的图特征提取方法对生物小分子进行特征提取的方法具体为直接将生物小分子图输入到图特征提取模型中,利用上述图特征提取方法实施例的图特征提取方法对生物小分子图进行特征提取,得到生物小分子的特征。
s22:利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。
示例性地,直接将提取到的生物小分子特征输入到预先训练好的脂水分配系数预测模型得到脂水分配系数预测值。脂水分配系数预测模型可以使用现有的脂水分配系数预测模型,也可以根据需求提前训练好,本发明实施例对该脂水分配系数预测模型不作具体限定,本领域技术人员可以根据实际情况选择。
如图3所示,脂水分配系数预测模型的训练方法可以采用预训练+微调的方法训练得到,在初始化模型参数的情况下,先采用大量的软件计算数据进行预训练,再采用更加准确的实验和专利数据进行微调。
本发明提供的脂水分配系数预测方法,通过利用图特征提取方法对生物小分子进行特征提取,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。本发明实施例通过使用图特征提取方法对生物小分子进行特征提取,以学到小分子的合理且充足的表征信息,更准确的表达分子的特征,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测,使得对脂水分配系数预测更加准确,且减少工作量。
作为本发明实施例一个可选实施方式,脂水分配系数预测模型通过下述方式训练得到:
获取第一脂水分配系数训练数据以及与第一脂水分配系数关联的训练数据,第一脂水分配系数相关的训练数据包括:溶解度(logs)、熔点(mp)、离解系数(pka)、在ph=7.4条件下测得的脂水分配系数(logd)中的至少一种。
示例性地,该第一脂水分配系数训练数据以及与第一脂水分配系数关联的训练数据可以从化学数据库中获取,化学数据库中包括了180万小分子化合物,化学数据库中的脂水分配系数训练数据以及脂水分配系数关联的训练数据都是由软件计算得到的。第一脂水分配系数相关的训练数据包括:溶解度、熔点、离解系数、在ph=7.4条件下测得的脂水分配系数中的至少一种
将第一脂水分配系数训练数据以及与第一脂水分配系数相关的训练数据输入到机器学习模型进行预训练,得到脂水分配系数预测模型。
示例性地,如图4所示,将第一脂水分配系数训练数据以及与第一脂水分配系数相关的训练数据均输入到机器学习模型进行强监督或弱监督的多任务预训练,得到脂水分配系数预测模型,最后的损失是各项的损失加权和。具体地,可以根据与脂水分配系数的相关性给不同的参数设置不同的权重,例如,脂水分配系数:1、在ph=7.4条件下测得的脂水分配系数:1、离解系数:0.1、溶解度:1、熔点:0.1。本发明实施例对该权重的设置不作具体限定,本领域技术人员可以根据实际情况设定。
本发明实施例采用多任务学习,同时学习多个脂水分配系数的相关指标,通过数据之间的协同作用增强模型鲁棒性,克服了本领域数据稀疏的问题。
作为本发明实施例一个可选实施方式,该脂水分配系数预测方法还包括:
获取第二脂水分配系数训练数据以及与第二脂水分配系数相关的训练数据,第二脂水分配系数相关的数据与第一脂水分配系数相关的训练数据相同,第二脂水分配系数训练数据以及与第二脂水分配系数相关的训练数据的准确性大于第一脂水分配系数训练数据以及与第一脂水分配系数关联的训练数据。
示例性地,该第二脂水分配系数训练数据以及与第二脂水分配系数相关的训练数据可以从化学数据库以及专利文献中获取得到,其属于实验数据,相对于计算得到的第一脂水分配系数训练数据以及与第一脂水分配系数相关的训练数据准确性更高,利用准确性更好的数据对脂水分配模型进行微调,得到的模型鲁棒性更好。
将第二脂水分配系数训练数据以及与第二脂水分配系数相关的训练数据输入到脂水分配系数预测模型中进行训练,得到目标脂水分配系数预测模型。具体的训练方法参见脂水分配系数预测模型的描述,在此不再赘述。
为了检验本发明方法的效果,将其与目前广泛使用且效果较好的xlogp3进行对比分析,结果如图5所示,给两个模型输入同样的1800个类药小分子,本发明实施例的方案得到的pearson相关系数为0.83,而xlogp3的pearson相关系数为0.76,本发明的脂水分配系数的预测更加准确。
本发明实施例还公开了一种图特征提取模型,如图6所示,包括:
输入层31,用于获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;具体实现方式见实施例中步骤s11的相关描述,在此不再赘述。
多个卷积层32和gru网络层33,多个卷积层32与gru网络层33间隔设置,每一个卷积层32将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层33进行特征融合,并输入到下一个卷积层32,重复每一个卷积层32将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层33进行特征融合,并输入到下一个卷积层32的步骤,直至最后一个卷积层32;具体实现方式见实施例中步骤s12的相关描述,在此不再赘述。
归并层34,用于将最后一层卷积层32输出的每一个节点的特征进行特征融合,并将特征融合结果通过输出层35输出。具体实现方式见实施例中步骤s13的相关描述,在此不再赘述。
本发明提供的图特征提取模型,包括:输入层,用于获取待提取特征图;多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层,重复每一个卷积层将提取到的待提取特征图中具有关联关系的节点的特征输入到gru网络层进行特征融合,并输入到下一个卷积层的步骤,直至最后一个卷积层;归并层,用于将最后一层卷积层输出的每一个节点的特征进行特征融合,并将特征融合结果通过输出层输出。本发明实施例通过增加gru网络层,在卷积操作时使用了gru网络层来把具有关联关系节点的特征信息融合起来,由于gru对输入的不同信息有不同程度的敏感度,gru网络层可通过内部的几个门控子网络保留一些信息,丢弃一些无用信息,使得网络的表达能力更好,更适合表达图内部节点之间的相互作用。
本发明实施例公开了一种图特征提取装置,如图7所示,包括:
获取模块41,用于获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;具体实现方式见实施例中步骤s11的相关描述,在此不再赘述。
第一提取模块42,用于将待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,图特征提取模型包含多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,通过gru网络层进行具有关联关系节点的特征融合;具体实现方式见实施例中步骤s12的相关描述,在此不再赘述。
融合模块43,用于将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征。具体实现方式见实施例中步骤s13的相关描述,在此不再赘述。本发明提供的图特征提取装置,通过获取待提取特征图,待提取特征图由多个节点以及连接具有关联关系的节点的边组成;将待提取特征图输入到图特征提取模型进行特征提取,得到每一个节点的特征,图特征提取模型包含多个卷积层和gru网络层,多个卷积层与gru网络层间隔设置,通过gru网络层进行具有关联关系节点的特征融合;将最后一层卷积层输出的每一个节点的特征输入到归并层进行特征融合,得到待提取特征图的特征。本发明实施例在每次卷积操作时使用了gru网络层来把具有关联关系节点的特征信息融合起来,由于gru对输入的不同信息有不同程度的敏感度,gru网络层可通过内部的几个门控子网络保留一些信息,丢弃一些无用信息,使得网络的表达能力更好,更适合表达图内部节点之间的相互作用。
本发明实施例还公开了一种脂水分配系数预测装置,如图8所示,包括:
第二提取模块51,用于利用如上述图特征提取方法实施例的图特征提取方法对生物小分子进行特征提取;具体实现方式见实施例中步骤s21的相关描述,在此不再赘述。
预测模块52,用于利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。具体实现方式见实施例中步骤s21的相关描述,在此不再赘述。
本发明提供的脂水分配系数预测装置,通过利用图特征提取方法对生物小分子进行特征提取,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测。本发明实施例通过使用图特征提取方法对生物小分子进行特征提取,以学到小分子的合理且充足的表征信息,更准确的表达分子的特征,利用预先训练好的脂水分配系数预测模型对提取到的生物小分子特征进行脂水分配系数预测,使得对脂水分配系数预测更加准确,且减少工作量。
本发明实施例还提供了一种计算机设备,如图9所示,该计算机设备可以包括处理器61和存储器62,其中处理器61和存储器62可以通过总线或者其他方式连接,图7中以通过总线连接为例。
处理器61可以为中央处理器(centralprocessingunit,cpu)。处理器61还可以为其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等芯片,或者上述各类芯片的组合。
存储器62作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序、非暂态计算机可执行程序以及模块,如本发明实施例中的图特征提取方法或脂水分配系数预测方法对应的程序指令/模块(例如,图7所示的获取模块41、第一提取模块42和融合模块43或图8所示的第二提取模块51和预测模块52)。处理器61通过运行存储在存储器62中的非暂态软件程序、指令以及模块,从而执行处理器的各种功能应用以及数据处理,即实现上述方法实施例中的图特征提取方法或脂水分配系数预测方法。
存储器62可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储处理器61所创建的数据等。此外,存储器62可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施例中,存储器62可选包括相对于处理器61远程设置的存储器,这些远程存储器可以通过网络连接至处理器61。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
所述一个或者多个模块存储在所述存储器62中,当被所述处理器61执行时,执行如图1所示实施例中的图特征提取方法或如图2所示实施例中的脂水分配系数预测方法。
上述计算机设备具体细节可以对应参阅图1至图2所示的实施例中对应的相关描述和效果进行理解,此处不再赘述。
本领域技术人员可以理解,实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)、随机存储记忆体(randomaccessmemory,ram)、快闪存储器(flashmemory)、硬盘(harddiskdrive,缩写:hdd)或固态硬盘(solid-statedrive,ssd)等;所述存储介质还可以包括上述种类的存储器的组合。
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



