
 商标分类
商标分类  商标转让
商标转让 
一种基于多任务学习的在轨自主加注控制方法及系统与流程
 2021-02-15 22:02:37|
2021-02-15 22:02:37| 411|
411| 起点商标网
起点商标网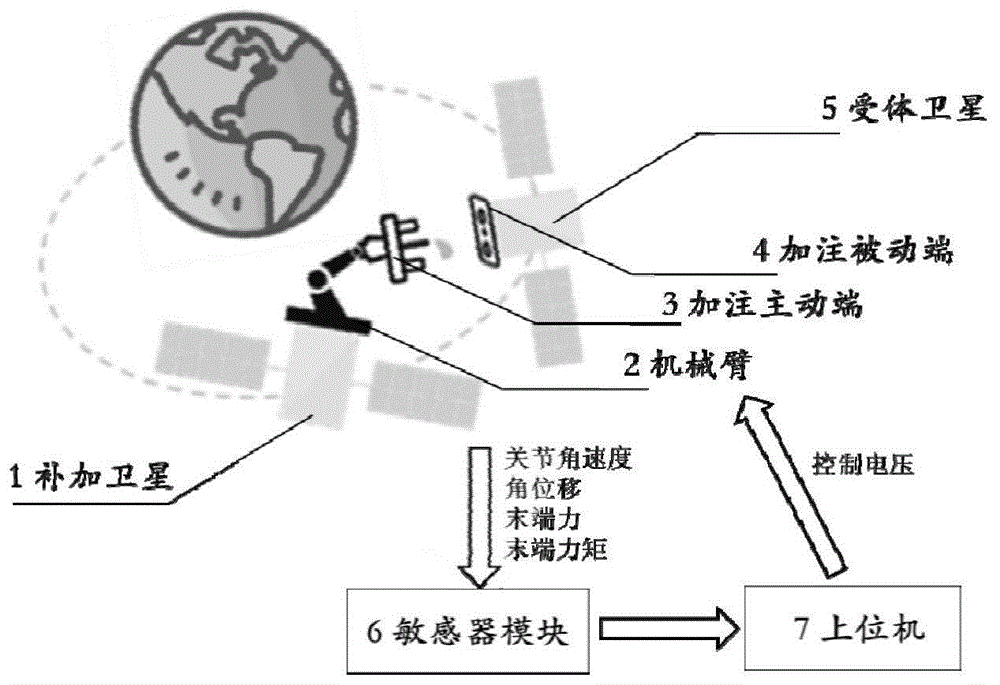
本发明涉及一种基于多任务学习的在轨自主加注控制方法及系统,属于空间技术领域。
背景技术:
在轨燃料加注技术能够有效延长航天器运行寿命,是带动其他在轨服务技术的先导和基础。对于遥操作的在轨加注,通讯时延会造成系统可控性、可靠性降低,发展自主化的在轨加注技术具有重要价值。面对干扰源多、不确定性大的空间环境,利用机械臂进行在轨加注具有更强的灵活性和鲁棒性。学习能力决定了这种系统的操作自主化水平,根据学习原理的不同,表1归纳了几种基于学习的机械臂操作控制方法。可以看出,深度强化学习方法兼具良好的环境感知能力与自主决策能力。在此框架下,用深度神经网络整体地表示控制策略(策略网络),策略网络以图像、机械臂关节测量、力测量等为输入,以电机指令为输出,控制机械臂完成加注操作。通过虚拟/实际环境的交互采样、奖励评价、优化对策略网络参数进行学习。学习完成后,策略网络能够根据环境反馈进行实时规划与控制,符合航天器智能自主化的发展趋势。
表1.基于学习的机械臂操作控制方法
技术实现要素:
本发明解决的技术问题是:克服现有技术的不足,提供了一种基于多任务学习的在轨自主加注控制方法及系统,将深度强化学习和多任务学习方法相结合,实现了多种操作任务策略网络的统一表达和学习,相比于人工设计任务状态判断与切换,提升了自主性与鲁棒性。
本发明的技术解决方案是:一种基于多任务学习的在轨自主加注控制方法,包括如下步骤:
步骤1,构建与真实环境相同的在轨加注虚拟环境和虚拟机械臂,采集虚拟机械臂与虚拟环境的交互行为数据,以在轨加注虚拟环境采样代替在轨加注真实环境采样;
步骤2,构建任务表达网络g和任务执行网络h,在在轨加注虚拟环境中使用强化学习方法训练与微调任务表达网络g和任务执行网络h,直到两个网络的参数收敛,形成多任务策略网络f;
步骤3,在一种基于多任务学习的在轨自主加注控制系统中,将真实机械臂运动状态复位,使用多任务策略网络f对真实机械臂进行控制,使真实机械臂执行相应动作,完成在轨加注操作任务。
进一步地,所述任务表达网络g包括任务分类器网络d和特征提取网络e;所述任务分类器网络d用于判断当前需要被执行的任务,输出独热型任务编码向量;所述特征提取网络e用于对rgb图像进行特征提取,输出高维的特征嵌入向量。
进一步地,所述任务分类器网络d和特征提取网络e均采用卷积神经网络结构,均以机械臂末端手眼相机的rgb图像为输入。
进一步地,所述任务执行网络h包括任务共享层s和任务预测层ti,i=1,2..n,n为任务总数,均采用多层感知机网络结构;所述任务共享层s用于处理多任务的共性嵌入,对在轨加注抓取、对接和插入操作场景下的测量信号进行共性特征提取,输出特征编码向量;所述任务预测层ti用于处理跨任务的特殊嵌入,以任务共享层s输出的特征编码向量为输入,对在轨加注抓取、对接和插入任务分别训练,输出连续的控制信号,驱动机械臂的关节电机完成在轨加注抓取、对接和插入任务。
进一步地,步骤2中训练与微调任务表达网络g和任务执行网络h的具体步骤为:
步骤2.1,训练任务表达网络g和任务共享层s:随机初始化任务表达网络g和任务执行网络hi=(ti,s)的参数,随机选取一种任务p=rand{1,2,...,n},在在轨加注虚拟环境中执行多任务策略网络f=(g,hp),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新f=(g,hp)的参数,直至算法收敛,实现任务p的奖励函数最大化,存储任务表达网络g和任务执行网络hp=(tp,s)的参数;
步骤2.2,微调任务预测层ti,i={1,2,...,n}\p:随机选取一种任务q={1,2..n}\p,在在轨加注虚拟环境中执行多任务策略网络f=(g,hq),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新tq的参数,直至算法收敛,实现全部任务的平均奖励函数最大化;
步骤2.3,存储多任务策略网络f=(g,ti,s),i=1,2..n的参数,完成任务执行网络h的训练与调整。
进一步地,所述基于值函数、利用策略梯度算法更新f=(g,hp)的参数,优化目标为机械臂末端位置姿态和目标位置姿态之差的2-范数最小。
进一步地,所述在轨加注操作任务包括抓取、对接和插入。
进一步地,步骤1中构建在轨加注虚拟环境的具体步骤为:
步骤1.1,根据真实机械臂的形状、尺寸、质量、惯量和关节阻尼,构建真实机械臂的多刚体动力学模型;
步骤1.2,根据加注主动端、加注被动端、受体卫星端面、受体卫星端面上的喷管和天线的真实形状和尺寸,构建在轨加注真实环境的多刚体动力学模型;
步骤1.3,根据在轨加注真实环境中加注主动端、加注被动端、受体卫星端面和受体卫星端面上的喷管和天线的真实光照和纹理,设置在轨加注真实环境的多刚体动力学模型的表面视觉特性。
一种基于多任务学习的在轨自主加注控制系统,包括补加卫星、机械臂、加注主动端、加注被动端、受体卫星、敏感器模块和上位机;
所述加注主动端位于补加卫星上,所述加注被动端位于受体卫星上,所述机械臂用于夹持加注主动端,并使加注主动端跟随其移动至加注被动端;所述机械臂的末端装有rgb相机;所述敏感器模块用于采集机械臂的环境交互数据,对采集信号进行滤波处理后发送至上位机;所述上位机根据输入的环境感知信息,读取存储的多任务策略网络f=(g,h)参数,运行多任务策略网络f=(g,h),输出控制电压到机械臂,使真实机械臂执行相应动作,完成在轨加注操作任务。
进一步地,所述敏感器模块包括单目视觉相机和六自由度力与力矩传感器;所述单目视觉相机安装在机械臂的末端;所述六自由度力与力矩传感器安装在机械臂手爪和末端关节之间。
本发明与现有技术相比的优点在于:
(1)本发明以深度强化学习为基本框架,将在轨加注所需的多任务操作进行结构整合,既实现了策略网络的统一表达,又节省了网络参数的存储空间,在星载计算资源有限的条件下具有优势;
(2)本发明利用多任务学习方法替代人控任务切换,减弱了人工因素的介入,有助于实现空间在轨全自主操作;
(3)本发明将多任务策略网络划分成表达、执行两模块,对前者进行预训练可以降低后者的优化负担,有利于提高收敛性。
附图说明
图1为本发明中一种基于多任务学习的在轨自主加注控制系统示意图;
图2为本发明的方法原理图;
图3为本发明的方法流程图;
图4为本发明中训练多任务策略网络f=(g,h)算法流程图。
具体实施方式
下面结合说明书附图和具体实施方式对本发明进行进一步解释和说明。
一种基于多任务学习的在轨自主加注控制方法及系统,被控对象是安装于补加卫星1上的机械臂2,机械臂2在多任务策略网络f的控制下,围绕加注主动端3依顺序进行抓取、对接、插入操作任务,使得加注主动端3与受体卫星5上的加注被动端4有效结合,最终完成在轨加注任务。本发明的核心是多任务策略网络f=(g,h)的架构设计与训练方法。多任务策略网络f以机械臂2的末端rgb图像、机械臂2的关节角速度、角位移、末端力、末端力矩等信号为输入,一方面负责任务判断、任务规划,另一方面输出控制电压到机械臂2的关节电机,使电机执行相应动作,完成与特定任务相匹配的操作。多任务策略网络f由两部分组成,分别是任务表达网络g和任务执行网络h,总体使用强化学习的方式训练。具体地,主要包含以下步骤:
步骤1,构建与真实环境相同的在轨加注虚拟环境和虚拟机械臂,采集虚拟机械臂与虚拟环境的交互行为数据,以在轨加注虚拟环境采样代替在轨加注真实环境采样;
步骤2,构建任务表达网络g和任务执行网络h,在在轨加注虚拟环境中使用强化学习方法训练与微调任务表达网络g和任务执行网络h,直到两个网络的参数收敛,形成多任务策略网络f;
步骤3,在一种基于多任务学习的在轨自主加注控制系统中,将真实机械臂运动状态复位,使用多任务策略网络f对真实机械臂进行控制,使真实机械臂执行相应动作,完成在轨加注操作任务。
作为本发明的进一步限定方案,步骤2中训练与微调任务表达网络g和任务执行网络h的具体步骤为:
步骤2.1,训练任务表达网络g和任务共享层s:随机初始化任务表达网络g和任务执行网络hi=(ti,s)的参数,i=1,2..n,n为任务总数,随机选取一种任务p=rand{1,2,...,n},在在轨加注虚拟环境中执行多任务策略网络f=(g,hp),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新f=(g,hp)的参数,直至算法收敛,实现任务p的奖励函数最大化,存储任务表达网络g和任务执行网络hp=(tp,s)的参数;
步骤2.2,微调任务预测层ti,i={1,2,...,n}\p:随机选取一种任务q={1,2..n}\p,在在轨加注虚拟环境中执行多任务策略网络f=(g,hq),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新tq的参数,直至算法收敛,实现全部任务的平均奖励函数最大化;
步骤2.3,存储多任务策略网络f=(g,ti,s),i=1,2..n的参数,完成任务执行网络h的训练与微调。
实施例一
如图1所示,本发明提供一种基于多任务学习的在轨自主加注控制方法,具体实施的控制系统主要包括:补加卫星1、机械臂2、加注主动端3、加注被动端4、受体卫星5、敏感器模块6、上位机7;所述加注主动端3位于补加卫星1上,所述加注被动端4位于受体卫星5上,所述机械臂3用于夹持加注主动端3,并使加注主动端3跟随其移动至加注被动端4;所述机械臂2的末端装有rgb相机;所述敏感器模块6用于采集机械臂2的环境交互数据,对采集信号进行滤波处理后发送至上位机7;所述上位机7根据输入的环境感知信息,读取存储的多任务策略网络f=(g,h)参数,运行多任务策略网络f=(g,h),输出控制电压到机械臂,使真实机械臂执行相应动作,完成在轨加注操作任务。
为了完成在轨加注操作,需要依次完成的任务包括抓取、对接、插入。具体地,抓取指机械臂2从补加卫星1的工具舱中成功抓住加注主动端3;对接指机械臂2携带加注主动端3定点到达加注被动端4附近;插入指机械臂2携带加注主动端3将加注枪插入加注被动端4上的加注孔。为了保证上述几种任务之间的连续性,我们考虑合作目标情况,即补加卫星1和受体卫星5之间没有大范围相对位移,二者接近刚性连接状态。
如图2所示,本发明提供一种基于多任务学习的在轨自主加注控制方法,核心是多任务策略网络f=(g,h)的架构设计与训练方法。多任务策略网络f以机械臂的末端rgb图像、机械臂3关节角速度、角位移、末端力、末端力矩等信号为输入,输出控制电压到机械臂关节电机。多任务策略网络f由任务表达网络g和任务执行网络h构成,任务表达网络g提取图像的任务特征和物体特征;任务执行网络h采用前端共享后端特殊的结构,控制机械臂完成与特定任务相匹配的操作,用强化学习的方式学习。
所述任务表达网络g包括任务分类器网络d和特征提取网络e,任务分类器网络d和特征提取网络e均采用卷积神经网络结构,均以机械臂末端手眼相机的rgb图像为输入;所述任务分类器网络d判断当前需要被执行的任务,输出独热(one-hot)型任务编码向量;所述特征提取网络e对rgb图像进行特征提取,输出高维的特征嵌入向量;所述任务执行网络h包括任务共享层s和任务预测层ti,i=1,2..n,n为任务总数,均采用多层感知机网络结构
系统的上位机7需要配置gpu,用以存储、优化多任务策略网络f=(g,h)参数。系统的反馈信号按照如下方式获取:机械臂关节角速度和关节角位移可以从机械臂的驱动器模拟量输出接口读取至上位机7,也可以通过以太网协议发送到上位机7;在末端工具和机械臂之间安装6自由度力传感器,末端力和力矩信号可以通过tcp或udp通讯方式发送到上位机7;rgb图像可以直接由相机通过高速usb串口发送至上位机7。
如图3所示,多任务策略网络f的训练与执行可分3个步骤进行实施。
步骤1,构建与真实环境相同的在轨加注虚拟环境和虚拟机械臂,采集虚拟机械臂与虚拟环境的交互行为数据,以在轨加注虚拟环境采样代替在轨加注真实环境采样;
步骤2,构建任务表达网络g和任务执行网络h,在在轨加注虚拟环境中使用强化学习方法训练与微调任务表达网络g和任务执行网络h,直到两个网络的参数收敛,形成多任务策略网络f;
步骤3,在一种基于多任务学习的在轨自主加注控制系统中,将真实机械臂运动状态复位,使用多任务策略网络f对真实机械臂进行控制,使真实机械臂执行相应动作,完成在轨加注操作任务。
步骤1中构建在轨加注虚拟环境的具体步骤为:
步骤1.1,根据真实机械臂的形状、尺寸、质量、惯量和关节阻尼,构建真实机械臂的多刚体动力学模型,建模可以通过mujoco等动力学仿真平台实施;
步骤1.2,根据加注主动端3、加注被动端4、受体卫星5端面、受体卫星5端面上的喷管和天线的真实形状和尺寸,构建在轨加注真实环境的多刚体动力学模型;
步骤1.3,根据在轨加注真实环境中加注主动端3、加注被动端4、受体卫星5端面、受体卫星5端面上的喷管和天线的真实光照和纹理,设置在轨加注真实环境的多刚体动力学模型的表面视觉特性。
如图4所示,步骤2中网络训练的具体步骤为:
步骤2.1,训练任务表达网络g和任务共享层s:随机初始化任务表达网络g和任务执行网络hi=(ti,s)的参数,i=1,2..n,n为任务总数,随机选取一种任务p=rand{1,2,...,n},在在轨加注虚拟环境中执行多任务策略网络f=(g,hp),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新f=(g,hp)的参数,直至算法收敛,实现任务p的奖励函数最大化,存储任务表达网络g和任务执行网络hp=(tp,s)的参数。优化目标为机械臂末端位置姿态和目标位置姿态之差的2-范数最小。优化采用演员-评论家框架,梯度方差小,优化算法可以使用trpo、ppo等在线策略的策略梯度优化算法,采用共轭梯度优化;
步骤2.2,微调任务预测层ti,i={1,2,...,n}\p:随机选取一种任务q={1,2..n}\p,在在轨加注虚拟环境中执行多任务策略网络f=(g,hq),获取策略运行下的采样轨迹,并计算采样轨迹产生的值函数,基于值函数、利用策略梯度算法更新tq的参数,直至算法收敛,实现全部任务的平均奖励函数最大化。任务预测层ti由多层全连接层组成,与步骤3.1类似地,优化目标为机械臂末端位置姿态和目标位置姿态之差的2-范数最小。优化采用演员-评论家框架,优化算法可以使用trpo、ppo等在线策略的策略梯度优化算法;
步骤2.3,存储多任务策略网络f=(g,ti,s),i=1,2..n的参数,完成任务执行网络h的训练与微调。
本发明说明书中未作详细描述的内容属本领域技术人员的公知技术。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



