
 商标分类
商标分类  商标转让
商标转让 
一种呼吸系统疾病基因SNP位点分型优化的方法与流程
 2021-02-02 18:02:06|
2021-02-02 18:02:06| 415|
415| 起点商标网
起点商标网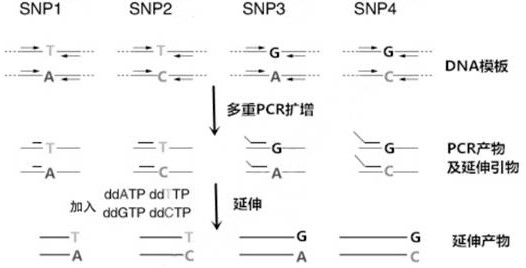
本发明涉及基因识别
技术领域:
,具体涉及一种呼吸系统疾病基因snp位点分型优化的方法。
背景技术:
:呼吸系统疾病是我国最常见疾病,城乡居民两周患病率、两周就诊率、住院人数构成长期居第1位,所致死亡居死因顺位第1~4位,疾病负担居第3位,已成为我国最为突出的公共卫生与医疗问题之一。慢性呼吸疾病是who定义的“四大慢病”之一,肺癌已成为我国排名第一位的肿瘤,肺结核将成为我国排名第一的传染病,尘肺占职业病的90%,此外,新发突发呼吸道传染病等公共卫生事件构成重大社会影响。呼吸系统疾病是我国第一大系统性疾病,其发病率、患病率、死亡率、病死率和疾病负担巨大,对我国人民健康构成严重威胁。随着大气污染、庞大的吸烟人群、人口老龄化、新发和耐药致病原等问题的日益凸显,呼吸系统疾病的防治形势越发严峻。呼吸系统疾病患者包含多种基因分型,不同基因分型对于相关药物的敏感性也不同。因此,在用药前需要了解患者的基因分型,才能利于医师对症下药。单核苷酸多态性(snp)标记分型的手段既有传统的手段如sscp(singlestrandconformationpolymorphism)和caps(cleavageamplificationpolymorphisms)等,也有现在较快速的手段如massarray质谱和taqman探针方法等,还有基于芯片的检测手段如dna芯片技术已经开发出来并迅速被应用和趋于成熟。使用高密度的dna芯片或微列阵可以同时对上万个snp的分型。目前snp已经广泛地应用于关联分析,基因精细定位和分子标记辅助育种过程中。但是上述方法都存在一定的缺点:sscp手段只能用非变性胶,实验条件苛刻,需要常温条件,一般实验室难以达到;caps手段实验过程繁琐,一个实验程序需要耗费很长的时间;massarray质谱和taqman探针方法及其他芯片方法费用相当高昂,一般实验室难以承担。snapshot技术,是在一个含有测序酶,四种荧光标记的ddntp,紧挨多态位点5'端的不同长度延伸引物和pcr产物模板的反应体系中,引物延伸一个碱基即终止,经测序仪跑胶后,根据峰的颜色可知掺入的碱基种类,从而确定该样本的基因型,现有技术中的采用snapshot(小测序)技术针对snp分型一般用于10~30个位点的分型,只有10个同时分型位点,且由于扩增片段长度和荧光染料种类的限制,在一个复合扩增体系中只可以同时扩增较少的snapshot基因座,一般为一种荧光物质标记一个基因座,一个扩增体系最多可同时复合4个snapshot基因座。技术实现要素:在为了克服现有技术的不足,本发明的目的在于提供一种呼吸系统疾病基因snp位点分型优化的方法,适用于与人体免疫功能紊乱/免疫功能失调相关的呼吸系统疾病,利用snapshotsnp分型技术对14个snp位点体系进行优化,针对中等通量(10~50位点)的snp分型项目进行技术上的改进,将同时分型位点从10个提高到14个,大大提高了分型的通量的准确性,准确性能达99.99%。本发明的目的之一采用如下技术方案实现:一种呼吸系统疾病基因snp位点分型优化的方法,包括以下步骤:1提取样品中的基因组dna,得到dna提取液;2)对步骤1)所得的dna提取液加入pcr缓冲溶液、mg2+溶液、dntp、dna聚合酶和pcr引物,进行多重pcr反应得到pcr扩增产物;pcr引物由14个snp基因位点组成,14个snp基因位点在ncbi中snp的数据库的rs号为:rs11650680、rs320995、rs545659、rs8193036、rs4647958、rs2353397、rs8111930、rs505010、rs3794262、rs6311、rs5417、rs13008848、rs1568351和rs2352262。14个snp基因位点引物的序列为:rs11650680f:tccctgctagtcccaccaattc,rs11650680r:aggggaccttccagatccatga;rs320995f:tggtttggactggaaatgggttta,rs320995r:cgtgaccgctgcctttttagtc;rs545659f:ccctcccccatcatctggtaaa,rs545659r:cccgggagactctgaatctttttc;rs8193036f:cccccatcatgtctcctctcct,rs8193036r:ccctgcatgctaccaagcaact;rs4647958f:tgccaatgctcatctgggactc,rs4647958r:tggagatccttggcctcagaga;rs2353397f:gctgtggtacagctgcaaatagctc,rs2353397r:cctgaaaacagagaaagaggggtgt;rs8111930f:ggcctttgtgtggaacctgaac,rs8111930r:gcccagaaccctgaaaggtgag;rs505010f:tctaacccaggccagattgctaca,rs505010r:ccatgcccagccagaattataca;rs3794262f:gcacagacaaaggacactgtgga,rs3794262r:ccactggtgtgaaaggcatcaa;rs6311f:tggtttccacgggaatggagta,rs6311r:cactgttggctttggatggaagt;rs5417f:ggccttttgttccagggactct,rs5417r:gatgggacccacagccacaag;rs13008848f:catcctctctggcggttgtgat,rs13008848r:ctttttgcccaaggctgttgtg;rs1568351f:gctccctcgattttccccactt,rs1568351r:ggaaggagctctaaagcctggttgt;rs2352262f:tctgacaacacaggacccacattc,rs2352262r:cacatggccttggcagtcctac;3)pcr产物经核酸外切酶ⅰ和虾碱性磷酸酶纯化,得到纯化后的pcr扩增产物;4)纯化后的pcr扩增产物与延伸引物混合物、snapshotmultiplexkit溶液和超纯水混合,进行延伸反应,得到延伸产物;其中,延伸引物混合物由14个snp基因位点的引物组成,14个snp基因位点在ncbi中snp的数据库的rs号为:rs11650680、rs320995、rs545659、rs8193036、rs4647958、rs2353397、rs8111930、rs505010、rs3794262、rs6311、rs5417、rs13008848、rs1568351和rs2352262;14个snp基因位点引物的序列为:rs11650680sr:ttttttttttttttttgtcagagaaggctccctgggta;rs320995sr:tttttttttttttttgggtaactttaggaaaaggctgtctacatt;rs545659sr:ttttttttttttttttggcctggagtaacacaaagtgaaactc;rs8193036sf:ttttttcctgccccccttttctccatct;rs4647958sr:tttgcctcggcctccaaggaagag;rs2353397sf:ttttttttttttgctgcaaatagctcatttccaccattatt;rs8111930sr:ttttttttttttgagctggccaggtaaacaggtga;rs505010sr:tttttttttttttttttacaattttacaagataagattcacaacgag;rs3794262sr:tttttttttttttttttttttttataattactttcttacagcctaagccaga;rs6311sr:tttttttttttttggctttggatggaagtgcc;rs5417sr:ttttttttttttttttttttttttttttttttttttttgtggggctcccgcggatct;rs13008848sr:tttttttttttttttttttttttttcccaaggctgttgtgtttttagaggt;rs1568351sr:tttttttttttttttttttttttttttccagaggaagaggagcagagaaaacag;rs2352262sf:cccacattccagcatggcaa;5)延伸产物经过虾碱性磷酸酶纯化,得到纯化后的延伸产物;6)得到纯化后的延伸产物后,加入hi-di甲酰胺和liz120sizestandard混匀,变性后上测序仪;7)通过测序仪分析步骤6)所得延伸产物的荧光标记和长度信息。进一步,步骤2)中,扩增条件为:95℃、5min预变性;然后依次在94℃、20s,65℃、40s,72℃、1.5min,进行11个循环;再依次在94℃、20s,59℃、30s,72℃、1.5min,进行20个循环;接着在72℃保持2min;最终在4℃保存。再进一步,步骤2)中,pcr引物中各引物的浓度为:rs11650680:1μm;rs320995:1μm;rs545659:1μm;rs8193036:1μm;rs4647958:1μm;rs2353397:1μm;rs8111930:1μm;rs505010:1μm;rs3794262:1μm;rs6311:1μm;rs5417:1μm;rs13008848:1μm;rs1568351:1μm;rs2352262:1μm。进一步,步骤2)中,对步骤1)所得的dna提取液进行pcr扩增,先进行10×条件:加入1μldna提取液与1μlpcr缓冲溶液、3.0mmolmg2+溶液、0.3mmoldntp、1udna聚合酶和1μlpcr引物混合反应,再进入gc条件:加入1μldna提取液与1μlpcr缓冲溶液、3.0mmolmg2+溶液、0.3mmoldntp、1μldna聚合酶和1μlpcr引物反应,得到pcr扩增产物。再进一步,步骤3)中,10μlpcr产物与5u虾碱性磷酸酶和2u核酸外切酶ⅰ混合,纯化条件为:在37ºc温浴30min,然后75ºc灭活15min。进一步,步骤4)中,延伸引物混合物中各延伸引物的浓度均为1μm。再进一步,步骤4)中,2μl纯化后的pcr扩增产物与1μl延伸引物混合物、5μlsnapshotmultiplexkit溶液和2μl超纯水混合,进行延伸反应,得到延伸产物。进一步,步骤4)中,延伸反应条件为:96℃、1min预变性;然后依次在96℃、10s,55℃、5s,60℃、30s,进行28个循环;最终在4℃保存。再进一步,步骤5)中,在10μl延伸产物加入1u虾碱性磷酸酶在37℃下温浴30min,然后在75℃灭活15min,得到纯化后的延伸产物。进一步,步骤6)中,取1μl纯化后的延伸产物与0.3μlliz120sizestandard和9μlhi-di混匀,在95ºc变性5min后,上abi3730xl测序仪。相比现有技术,本发明的有益效果在于:本发明基于美国lifetechnologies公司开发的snapshot技术,针对不同snp位点设计不同长度的和pcr扩增引物和延伸引物来做到多个snp在一个反应体系中进行分型,可在14个位点同时分型。由于此方法为四色荧光标记,所以可以针对各种snp类型进行分类,同时还可以对插入、缺失进行分析。分析得到呼吸系统疾病患者的基因分型后,有利于医生的对症下药。附图说明图1为实施例1的流程图;图2为实施例1的四色荧光标记图。具体实施方式下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。实施例1一种呼吸系统疾病基因snp位点分型优化的方法,如图1所示,包括以下步骤:1)提取样品中的基因组dna,得到dna提取液;2)取步骤1)所得的1μldna提取液进行pcr扩增,加入1μlpcr缓冲溶液、3.0mmolmg2+溶液、0.3mmoldntp、1udna聚合酶(来自qiageninc.)和1μlpcr引物混合,进行多重pcr反应,得到pcr扩增产物;扩增条件为:95℃、5min预变性;然后依次在94℃、20s,65℃、40s,72℃、1.5min,进行11个循环;再依次在94℃、20s,59℃、30s,72℃、1.5min,进行20个循环;接着在72℃保持2min;最终在4℃保存。pcr引物由14个snp基因位点组成,14个snp基因位点在ncbi中snp的数据库的rs号为:rs11650680、rs320995、rs545659、rs8193036、rs4647958、rs2353397、rs8111930、rs505010、rs3794262、rs6311、rs5417、rs13008848、rs1568351和rs2352262。14个snp基因位点引物的序列为:rs11650680f:tccctgctagtcccaccaattc,rs11650680r:aggggaccttccagatccatga;rs320995f:tggtttggactggaaatgggttta,rs320995r:cgtgaccgctgcctttttagtc;rs545659f:ccctcccccatcatctggtaaa,rs545659r:cccgggagactctgaatctttttc;rs8193036f:cccccatcatgtctcctctcct,rs8193036r:ccctgcatgctaccaagcaact;rs4647958f:tgccaatgctcatctgggactc,rs4647958r:tggagatccttggcctcagaga;rs2353397f:gctgtggtacagctgcaaatagctc,rs2353397r:cctgaaaacagagaaagaggggtgt;rs8111930f:ggcctttgtgtggaacctgaac,rs8111930r:gcccagaaccctgaaaggtgag;rs505010f:tctaacccaggccagattgctaca,rs505010r:ccatgcccagccagaattataca;rs3794262f:gcacagacaaaggacactgtgga,rs3794262r:ccactggtgtgaaaggcatcaa;rs6311f:tggtttccacgggaatggagta,rs6311r:cactgttggctttggatggaagt;rs5417f:ggccttttgttccagggactct,rs5417r:gatgggacccacagccacaag;rs13008848f:catcctctctggcggttgtgat,rs13008848r:ctttttgcccaaggctgttgtg;rs1568351f:gctccctcgattttccccactt,rs1568351r:ggaaggagctctaaagcctggttgt;rs2352262f:tctgacaacacaggacccacattc,rs2352262r:cacatggccttggcagtcctac;pcr引物中各引物的浓度为:(单位:μm)rs11650680rs320995rs545659rs8193036rs4647958rs2353397111111rs8111930rs505010rs3794262rs6311rs5417rs13008848111111rs1568351rs2352262113)10μlpcr产物与5u虾碱性磷酸酶(来自promega公司)和2u核酸外切酶ⅰ(来自epicentre公司)混合纯化,纯化条件为:在37ºc温浴30min,然后75ºc灭活15min,得到纯化后的pcr扩增产物。4)2μl纯化后的pcr扩增产物与1μl延伸引物混合物、5μlsnapshotmultiplexkit溶液(来自abi公司)和2μl超纯水混合,进行延伸反应,得到10μl延伸产物;其中,延伸反应条件为:96℃、1min预变性;然后依次在96℃、10s,55℃、5s,60℃、30s,进行28个循环;最终在4℃保存。其中,延伸引物混合物由14个snp基因位点的引物组成,14个snp基因位点在ncbi中snp的数据库的rs号为:rs11650680、rs320995、rs545659、rs8193036、rs4647958、rs2353397、rs8111930、rs505010、rs3794262、rs6311、rs5417、rs13008848、rs1568351和rs2352262;14个snp基因位点引物的序列为:snp位点序列(5'-3')seqidnors11650680ttttttttttttttttgtcagagaaggctccctgggta1rs320995tttttttttttttttgggtaactttaggaaaaggctgtctacatt2rs545659ttttttttttttttttggcctggagtaacacaaagtgaaactc3rs8193036ttttttcctgccccccttttctccatct4rs4647958tttgcctcggcctccaaggaagag5rs2353397ttttttttttttgctgcaaatagctcatttccaccattatt6rs8111930ttttttttttttgagctggccaggtaaacaggtga7rs505010tttttttttttttttttacaattttacaagataagattcacaacgag8rs3794262tttttttttttttttttttttttataattactttcttacagcctaagccaga9rs6311tttttttttttttggctttggatggaagtgcc10rs5417ttttttttttttttttttttttttttttttttttttttgtggggctcccgcggatct11rs13008848tttttttttttttttttttttttttcccaaggctgttgtgtttttagaggt12rs1568351tttttttttttttttttttttttttttccagaggaagaggagcagagaaaacag13rs2352262cccacattccagcatggcaa14延伸引物混合物中各延伸引物的浓度为:(单位:μm)rs11650680rs320995rs545659rs8193036rs4647958rs2353397111111rs8111930rs505010rs3794262rs6311rs5417rs13008848111111rs1568351rs2352262115)在10μl延伸产物加入1u虾碱性磷酸酶(来自promega公司)在37℃下温浴30min,然后在75℃灭活15min,得到纯化后的延伸产物;6)得到纯化后的延伸产物后,加入hi-di甲酰胺和liz120sizestandard混匀,变性后上abi3730xl测序仪;7)abi3730xl测序仪上收集的原始数据用genemapper4.1(appliedbiosystemsco.,ltd.,usa)来分析。其中,实施例1的结果图见图2。上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。序列表<110>广东瑞昊生物技术有限公司<120>一种呼吸系统疾病基因snp位点分型优化的方法<160>16<210>1<211>54<212>dna<213>人工序列<400>ttttttttttttttttgtcagagaaggctccctgggta<210>2<211>42<212>dna<213>人工序列<400>tttttttttttttttgggtaactttaggaaaaggctgtctacatt<210>3<211>27<212>dna<213>人工序列<400>ttttttttttttttttggcctggagtaacacaaagtgaaactc<210>4<211>46<212>dna<213>人工序列<400>ttttttcctgccccccttttctccatct<210>5<211>40<212>dna<213>人工序列<400>tttgcctcggcctccaaggaagag<210>6<211>34<212>dna<213>人工序列<400>ttttttttttttgctgcaaatagctcatttccaccattatt<210>7<211>23<212>dna<213>人工序列<400>ttttttttttttgagctggccaggtaaacaggtga<210>8<211>50<212>dna<213>人工序列<400>tttttttttttttttttacaattttacaagataagattcacaacgag<210>9<211>44<212>dna<213>人工序列<400>tttttttttttttttttttttttataattactttcttacagcctaagccaga<210>10<211>37<212>dna<213>人工序列<400>tttttttttttttggctttggatggaagtgcc<210>11<211>60<212>dna<213>人工序列<400>ttttttttttttttttttttttttttttttttttttttgtggggctcccgcggatct<210>12<211>24<212>dna<213>人工序列<400>tttttttttttttttttttttttttcccaaggctgttgtgtttttagaggt<210>13<211>51<212>dna<213>人工序列<400>tttttttttttttttttttttttttttccagaggaagaggagcagagaaaacag<210>14<211>55<212>dna<213>人工序列<400>cccacattccagcatggcaa。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips