
 商标分类
商标分类  商标转让
商标转让 
叠音检测方法、装置和设备与流程
 2021-01-28 18:01:35|
2021-01-28 18:01:35| 386|
386| 起点商标网
起点商标网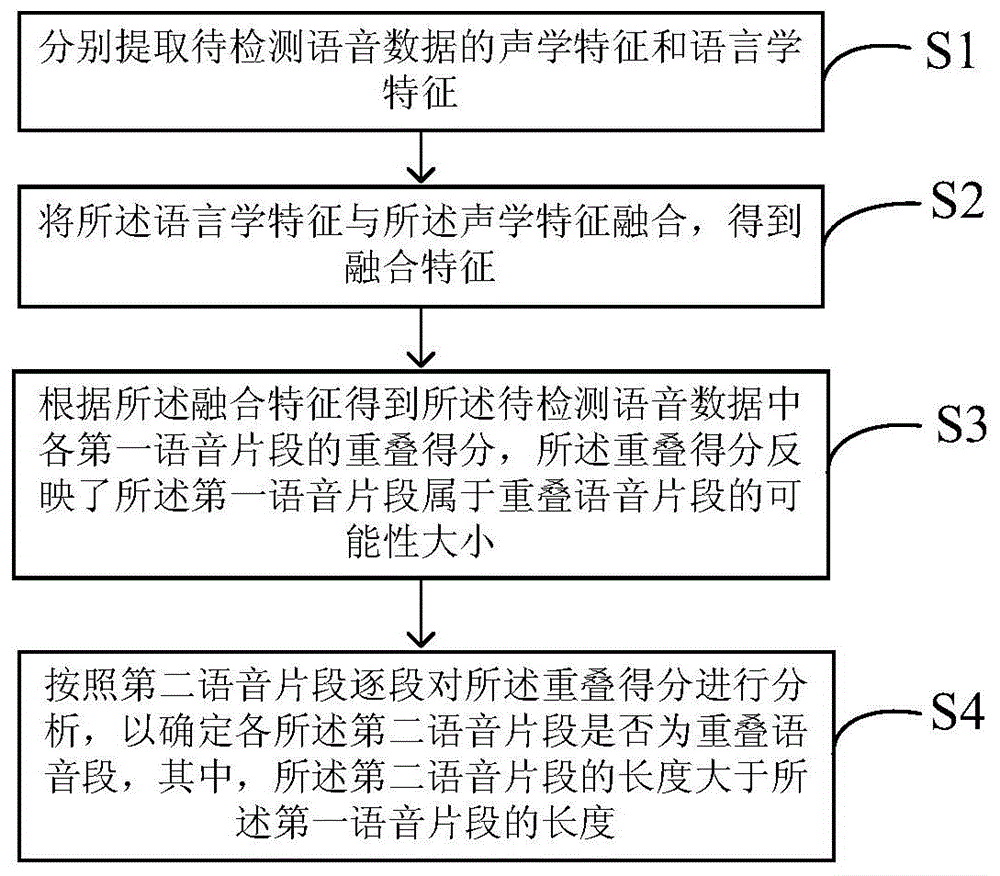
本发明涉及语音重叠检测技术领域,尤其涉及一种叠音检测方法、装置和设备。
背景技术:
叠音是指在同一时间段存在两个或两个以上说话人同时说话的情况。在很多真实的应用场景中,特别是会议、对话交流、讨论等,重叠语音段在说话人转折点、背景说话或插话中十分常见。重叠语音段的存在会影响相关语音识别系统的应用效果,例如在连续语音识别时会影响对主要说话人进行语音识别所得到的文字的准确性,在说话人识别中会影响说话人模型的建模纯度,而在多说话人分割任务中会影响说话人变换点的检测,降低对说话人的聚类效果。由此可见,如何来检测和分离这些重叠语音段是语音识别应用在这些场景中的一个挑战,而准确的重叠语音段检测是对重叠语音段进行后续处理的基础,后续对重叠语音段的相应处理将会有效提高相关语音识别在真实场景下应用的准确率和鲁棒性。
现有对重叠语音段的检测方法多是使用各种声学频谱特征,以高斯混合模型-隐马尔可夫(gmm-hmm)为框架对类别进行建模,再通过维特比解码得到重叠语音的时间信息。然而当重叠语音段很短时,仅仅依靠传统语音的声学特征很难去对这些很短的重叠语音段进行检测,这样会影响重叠语音段的检测效果和鲁棒性。而且gmm在计算每一时刻hmm观测概率时,仅关注当前时刻的信息,其所能包含的信息量是有限的,在重叠语音检测时逐帧进行检测,一般而言一帧的时长是0.01秒,出现这么短的重叠音或单人音的情况是不合理的,因此在实际应用中基于gmm-hmm的重叠语音检测效果也是较差的。
技术实现要素:
鉴于此,本发明提供了一种叠音检测方法、装置和设备,本发明还相应提供了一种计算机程序产品,通过以上形式,能够提高叠音检测的准确性和鲁棒性。
关于上述本发明采用的技术方案具体如下:
第一方面,本发明提供了一种叠音检测方法,包括:
分别提取待检测语音数据的声学特征和语言学特征;
将所述语言学特征与所述声学特征融合,得到融合特征;
根据所述融合特征得到所述待检测语音数据中各第一语音片段的重叠得分,所述重叠得分反映了所述第一语音片段属于重叠语音片段的可能性大小;
按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段,其中,所述第二语音片段的长度大于所述第一语音片段的长度。
在其中一种可能的实现方式中,所述分别提取待检测语音数据的声学特征和语言学特征包括:
提取所述待检测语音数据中各第一语音片段的声学特征;
利用预先训练的重叠语音声学模型和单人说话声学模型提取所述待检测语音数据中各第一语音片段的语言学特征。
在其中一种可能的实现方式中,所述利用预先训练的重叠语音声学模型和单人说话声学模型提取所述待检测语音数据中各第一语音片段的语言学特征包括:
针对每一第一语音片段,利用所述重叠语音声学模型对所述第一语音片段进行识别,得到第一最大后验概率,并利用所述单人说话声学模型对所述第一语音片段进行识别得到第二最大后验概率,其中所述第一最大后验概率为利用所述重叠语音声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率,所述第二最大后验概率为利用所述单人说话声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率;
根据所述第一最大后验概率和所述第二最大后验概率得到所述语言学特征。
在其中一种可能的实现方式中,所述按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段包括:
利用预设的滑窗及阈值检测策略按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段。
在其中一种可能的实现方式中,所述利用预设的滑窗及阈值检测策略包括:
利用滑窗统计落入所述滑窗内的各第一语音片段的重叠得分;
若所述滑窗内的第一语音片段的重叠得分大于预设第一阈值,则确定所述第一语音片段为重叠语音片段;
若所述滑窗内的所述重叠语音片段的占比大于预设第二阈值,则确定所述滑窗对应的所述第二语音片段为重叠语音段。
在其中一种可能的实现方式中,所述根据所述融合特征得到所述待检测语音数据中各第一语音片段的重叠得分包括:
将所述融合特征输入预先构建的重叠得分模型,得到各所述第一语音片段的重叠得分。
第二方面,本发明提供了一种叠音检测装置,包括:
特征提取模块,用于分别提取待检测语音数据的声学特征和语言学特征;
特征融合模块,用于将所述语言学特征与所述声学特征融合,得到融合特征;
重叠得分计算模块,用于根据所述融合特征得到所述待检测语音数据中各第一语音片段的重叠得分,所述重叠得分反映了所述第一语音片段属于重叠语音片段的可能性大小;
重叠得分分析模块,用于按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段,其中,所述第二语音片段的长度大于所述第一语音片段的长度。
在其中一种可能的实现方式中,所述特征提取模块包括:
声学特征提取单元,用于提取所述待检测语音数据中各第一语音片段的声学特征;
语言学特征提取单元,用于利用预先训练的重叠语音声学模型和单人说话声学模型提取所述待检测语音数据中各第一语音片段的语言学特征。
在其中一种可能的实现方式中,所述重叠得分分析模块利用预设的滑窗及阈值检测策略按照第二语音段逐段对所述重叠得分进行分析,以确定各所述第二语音段是否为重叠语音段。
第三方面,本发明提供了一种叠音检测设备,包括:
一个或多个处理器、存储器以及一个或多个计算机程序,所述存储器可以采用非易失性存储介质,其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述设备执行时,使得所述设备执行如第一方面或者第一方面的任一可能实现方式中的所述方法。
第四方面,本发明还提供了一种计算机程序产品,当所述计算机程序产品被计算机执行时,用于执行第一方面或者第一方面的任一可能实现方式中的所述方法。
在第四方面的一种可能的设计中,该产品涉及到的相关程序可以全部或者部分存储在与处理器封装在一起的存储器上,也可以部分或者全部存储在不与处理器封装在一起的存储介质上。
本发明的核心构思在于提出一种利用将声学特征和语言学特征融合所得到的融合特征作为重叠语音段的检测特征的叠音检测方案,具体是根据融合特征得到待检测语音数据中各第一语音片段的重叠得分,然后按照时长更长的第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段。由于融合了蕴含文本信息的语言学特征,同时考虑了待检测语音数据中的声音信息和文本信息,以此作为重叠语音段的检测特征,在计算重叠得分时,利用了同时蕴含了待检测语音数据中的声音信息和文本信息的融合特征,挖掘出待检测语音数据中所包含的丰富信息,可以提高叠音检测的准确性和鲁棒性;同时,按照第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段,可以对叠音检测结果进行顺滑,减少叠音检测结果中某些奇异点的问题,进一步提高叠音检测的准确性。
进一步地,本发明还利用预设的滑窗及阈值检测策略按照第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段,通过调节第一阈值及第二阈值,可以平衡在不同应用场景中对重叠语音检测的正确率和召回率;与单人语音段相比,滑窗经过重叠语音段时,每个语音片段被判断为重叠语音片段的可能性提高,进而在整个滑窗内,重叠语音片段的占比会提高,因此该滑窗对应的第二语音片段被判断为重叠语音段,从而实现对较短时长的重叠语音段也能很好的召回。
进一步地,本发明还利用预先训练的重叠语音声学模型和单人说话声学模型,根据体现了重叠语音声学模型对第一语音片段的识别结果的第一最大后验概率和体现了单人说话声学模型对第一语音片段的识别结果的第二最大后验概率得到语言学特征,便于准确地提取待检测语音数据中每一第一语音片段的语言学特征,进而提高叠音检测的准确性。
进一步地,本发明还使用bi-lstm的模型结构计算重叠得分,更好地处理序列的长距离依赖关系,可以利用第一语音片段的上下文信息,即利用当前时刻、上一时刻及下一时刻的信息得到重叠得分,从而更准确地得到第一语音片段属于重叠语音片段的概率,进而提高后续利用重叠得分得到叠音检测结果的准确性。
附图说明
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
图1为本发明提供的叠音检测方法的实施例的流程图;
图2为本发明提供的提取声学特征和语言学特征的实施例的流程图;
图3为本发明提供的提取语言学特征的实施例的流程图;
图4为本发明提供的滑窗及阈值检测策略的实施例的流程图;
图5为本发明提供的滑窗的窗长及窗移的示意图;
图6为本发明提供的叠音检测装置的实施例的结构示意图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
为了提高重叠语音检测效果,本案发明人进行了研究:
起初的思路是:重叠语音、单人语音、非语音分别使用三个状态的隐马尔可夫模型hmm模型来表示,发射概率由高斯混合模型gmm来建模。训练时,对训练数据语音进行分帧、预加重等预处理后,提取梅尔倒谱系数mfcc或者其他声学特征,之后使用声学特征用最大似然估计完成gmm-hmm模型参数计算。在重叠语音检测阶段,待检测语音经过相同的预处理和特征提取后,然后利用训练好的hmm模型进行维特比解码,判别重叠语音和非重叠语音。在解码过程中,可以设定一个重叠插入惩罚因子,当重叠语音的hmm模型由单一说话人状态向重叠语音状态转移时,增加该项作为惩罚,反之则不增加,通过调整惩罚因子可以平衡重叠语音检测的正确率和召回率的平衡。
在实际应用中,重叠语音段存在于环境噪声、混响、谈话内容、说话人声音大小、重叠语音段时长等区别很大的各种场景中。当重叠语音段很短时,背景说话人只是说了几句表示赞同、肯定的话,如“嗯嗯”、“是的”等,仅仅依靠传统语音的声学特征很难去对这些很短的重叠语音段进行检测,这样会影响重叠语音段的检测效果和鲁棒性。同时,对于基于gmm-hmm的重叠语音检测系统来说,gmm在计算每一时刻hmm观测概率时候gmm没有利用帧的上下文信息,且gmm模型也不能有效地对呈非线性或近似非线性的数据去学习深层非线性特征变换的能力,所以在重叠语音段检测时,gmm所能包含的信息量是有限的,在实际应用中基于gmm-hmm的重叠语音检测效果也是较差的。
正是基于对上述效果不佳方案的分析和探究,本发明才提出了一种利用将声学特征和语言学特征融合所得到的融合特征作为重叠语音段的检测特征的叠音检测构思。具体如下,本发明提供了所述叠音检测方法的至少一种实施例,如图1所示,可包括:
步骤s1、分别提取待检测语音数据的声学特征和语言学特征。
具体地,所述待检测语音数据主要是指用来检测叠音数据的语音数据,所针对的应用场景可以是诸如会议、对话交流、讨论、朗读、演讲、语言测试以及表演类型的口述等(语言类曲艺表演,脱口秀等),也可以对机器合成的语音进行叠音检测,并不特别针对音乐、自然界声音等非人类语音音频数据;所述待检测语音数据的接受方式可以通过各类型麦克风现场录音或后期采集,还可以通过网络远程传输等其他方式,本发明对此不作限定。本申请实施例中,声学特征和语言学特征用于后续的叠音检测,声学特征对应于人类说话的发音习惯,语言学特征对应于人类说话的文本信息习惯,其与具体的说话内容相关。
本发明在一些实施方式中,如图2所示,步骤s1可以包括如下步骤:
步骤s11、提取所述待检测语音数据中各第一语音片段的声学特征;
一般而言,声学特征为语音数据的频谱特征。比如,声学特征可以包括梅尔频率倒谱系数(melfrequencycepstrumcoefficient,mfcc)特征、滤波器组(filterbank,fb)特征或幅度谱特征等。第一语音片段可以是语音帧,也可以是由多个语音帧组成的音素对应的语音片段,还可以是其他的语音片段,本发明对第一语音片段的大小不作限定。
下面以第一语音片段为语音帧为例进行说明,本发明实施例中的声学特征采用连续语音识别中常用的mfcc特征。
可以通过如下方式提取待检测语音数据中各语音帧的声学特征:
将待检测语音数据经过分帧加窗、快速傅里叶变化、梅尔滤波等步骤后得到待检测语音数据的mfcc特征,x={xd1,xd2,...,xdt},其中x表示mfcc特征,t表示提取的待检测语音数据的语音帧数,d表示特征维度,即每一语音帧均由维度为d的向量表示,xd1表示第一语音帧的mfcc特征向量表示,xd2表示第二语音帧的mfcc特征向量表示,以此类推,x是一个t行d列的矩阵,例如,在待检测语音数据的语音帧数t为5,每一语音帧的声学特征均由维度为13的向量表示时,mfcc特征可以用一个5行13列的矩阵x表示。
步骤s12、利用预先训练的重叠语音声学模型和单人说话声学模型提取所述待检测语音数据中各第一语音片段的语言学特征。
考虑到在单个说话人的环境下,每帧语音对应了特定的音素状态,多个语音帧对应一个音素,相邻帧的语音在声学空间具有一定的连续性,对应音素状态的转换频率相对平缓,而当两个或以上人同时发音时,不同的人在说不同的语音内容,其对应音素状态的序列也会与一般正常单人说话场景中有很大的不同,因此可以利用各自对应的声学模型提取语言学特征。由于重叠语音声学模型和单人说话声学模型属于不同的声学模型,其模型参数不同,其对待检测语音数据进行识别时,所识别的声学建模单元(例如,音素状态、音素、三因素、音节等)也是不完全相同的,可以据此利用重叠语音声学模型和单人说话声学模型两者得到两个声学建模单元的序列,进而根据声学建模单元的序列得到语言学特征。其中,重叠语音声学模型和单人说话声学模型可为采用连续语音识别中的系统框架,例如深度神经网络(deepneuralnetwork,dnn)、长短期记忆网络(longshort-termmemory,lstm),卷积神经网络(convolutionalneuralnetwork,cnn等。本发明在一些实施方式中,如图3所示,步骤s12可以包括如下步骤:
步骤s121、针对每一第一语音片段,利用所述重叠语音声学模型对所述第一语音片段进行识别,得到第一最大后验概率,并利用所述单人说话声学模型对所述第一语音片段进行识别得到第二最大后验概率,其中所述第一最大后验概率为利用所述重叠语音声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率,所述第二最大后验概率为利用所述单人说话声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率;
仍以第一语音片段为语音帧为例进行说明,将待检测语音数据中的某个语音帧输入重叠语音声学模型时,会得到该语音帧的声学建模单元(例如,音素状态),即重叠语音声学模型预测某个声学建模单元的后验概率,以p(i|overlap)表示,其表示利用重叠语音声学模型预测该语音帧属于第i个声学建模单元的后验概率,例如,在声学建模单元(例如,音素状态)的数量为n时,会得到该语音帧对应的n个后验概率,选取其中最大的后验概率为第一最大后验概率,其对应的声学建模单元作为重叠语音声学模型对该语音帧的识别结果。例如,当将待检测语音数据中的第一语音帧输入重叠语音声学模型时,分别得到该语音帧属于n个音素状态的后验概率,其中,音素状态s1所对应的后验概率最大,则重叠语音声学模型对第一语音帧的识别结果为音素状态s1。
类似地,将待检测语音数据中的某个语音帧输入单人说话声学模型时,会得到该语音帧的声学建模单元(例如,音素状态),即单人说话声学模型预测某个声学建模单元的后验概率,以p(i|single)表示,其表示利用单人说话声学模型预测该语音帧属于第i个声学建模单元的后验概率,例如,在声学建模单元的数量为n时,会得到该语音帧对应的n个后验概率,选取其中最大的后验概率为第二最大后验概率,其对应的声学建模单元作为单人说话声学模型对该语音帧的识别结果。例如,当将待检测语音数据中的第一语音帧输入单人说话声学模型时,分别得到该语音帧属于n个音素状态的后验概率,其中,音素状态s2所对应的后验概率最大,则单人说话声学模型对第一语音帧的识别结果为音素状态s2。
逐个将待检测语音数据中的语音帧依次输入重叠语音声学模型时,得到对应的第一声学建模单元序列i(overlap),逐个将待检测语音数据中的语音帧依次输入单人说话声学模型时,得到对应的第二声学建模单元序列i(single)。
在本发明的一些实施方式中,所述重叠语音声学模型可以通过如下步骤训练得到:(1)获取训练样本,其中,训练样本只包括重叠语音的训练语音和对应的声学建模单元状态标注结果,不包括单人说话的训练语音和对应的声学建模单元状态标注结果;(2)生成训练语音的语音帧序列的各语音帧的特征向量;(3)将训练语音的语音帧序列的各语音帧的特征向量作为输入,将训练语音的语音帧序列的各语音帧的声学建模单元状态作为输出,训练得到所述重叠语音声学模型。
类似地,所述单人说话声学模型可以通过如下步骤训练得到:(1)获取训练样本,其中,训练样本只包括单人说话的训练语音和对应的声学建模单元状态标注结果,不包括重叠语音的训练语音和对应的声学建模单元状态标注结果;(2)生成训练语音的语音帧序列的各语音帧的特征向量;(3)将训练语音的语音帧序列的各语音帧的特征向量作为输入,将训练语音的语音帧序列的各语音帧对应的声学建模单元状态作为输出,训练得到所述单人说话声学模型。
并且还可以进一步说明的是,重叠语音声学模型及单人说话声学模型还可以根据重叠语音及单人说话相应的标注数据进行针对性的模型训练,以此提升声学模型的识别效果。首先对标注数据进行预处理,滤除静音、噪声等无效数据后得到干净的说话语音数据,然后按时间顺序标注单人说话的语音帧及重叠语音的语音帧,例如,可以将单人说话的语音帧标注为0,将重叠语音的语音帧标注为1,然后进行针对性的模型训练。
步骤s122、根据所述第一最大后验概率和所述第二最大后验概率得到所述语言学特征。
步骤s121中得到的第一最大后验概率反映了重叠语音声学模型对语音帧的识别结果,所述第二最大后验概率反映了单人说话声学模型对同一语音帧的识别结果,由于当两个或两个以上人同时发音时,不同的人在说不同的语音内容,其对应的声学建模单元序列(例如,音素状态序列)也会与一般正常单人说话场景中有很大的不同,因此可以根据采用重叠语音声学模型得到的第一声学建模单元序列及采用单人说话声学模型得到的第二声学建模单元序列两者的差异得到语言学特征。作为一个示例而非限制,可以将第一最大后验概率和第二最大后验概率的差值作为语言学特征。
若待检测语音数据是一段单人语音,则利用单人说话声学模型对该语音数据的识别效果较好,识别得分也较高,而由于重叠语音声学模型在训练时所使用的训练数据都是重叠语音,其在建模时均使用带有其他人干扰时的音素发音,因此其对正常单人语音的发音不能有很好的拟合,因此其对单人语音的识别结果状态也是模棱两可,得分较低。反之,若待检测语音数据是一段重叠语音,则利用重叠语音声学模型对该段语音的识别结果较好,得分较高,利用单人说话声学模型对该段语音的识别结果较差,得分较低。具体而言,可采用以下公式表示语言学特征:
其中t表示帧数,yi1overlap表示利用重叠语音声学模型对语音帧进行识别得到的第一最大后验概率得分,yi2single表示利用单人说话声学模型对同一语音帧进行识别得到的第二后验概率得分,(yi1overlap-yi2single)1表示第一语音帧的语言学特征向量表示,(yi1overlap-yi2single)2表示第二语音帧的语言学特征向量表示,以此类推。
可见,对于待检测语音数据中的每一语音帧而言,其对应的语言学特征向量可以由该语音帧对应的第一最大后验概率和第二最大后验概率两者的差值表示。在待检测语音数据的语音帧数t为5时,语言学特征可以用一个5行1列的矩阵y表示。
可见,语言学特征y反映了重叠语音声学模型和单人说话声学模型这两个声学模型对待检测语音数据进行识别的匹配程度的得分差,得分越高,则该段语音更有可能是重叠语音段,得分越低,则该段语音更有可能是单人语音段。
需要指出的是,本发明在一些实施方式中,可以将第二最大后验概率和第一最大后验概率的差值作为语言学特征,还可以采用其他方式表示利用重叠语音声学模型和单人说话声学模型这两个声学模型对待检测语音数据进行识别的匹配程度的差异,本发明对此不作限定。本发明在一些实施方式中,可以先得到音素状态序列,然后针对每个语音帧求第二最大后验概率和第一最大后验概率的差值;也可以先得到音素序列,然后针对每个音素求第二最大后验概率和第一最大后验概率的差值,此处的音素对应的不是语音帧而是由多个语音帧组成的小语音片段。还需指出的是,本发明对提取语言学特征及声学特征的顺序不做限制,本发明在一些实施方式中,可以先提取语言学特征再提取声学特征,也可以同时提取语言学特征及声学特征。
步骤s2、将所述语言学特征与所述声学特征融合,得到融合特征。
此步骤即是利用步骤s1得到的声学特征和语言学特征,得到二者的融合特征,然后在后续的步骤中,利用融合特征得到叠音检测结果。在多人说话场景中,背景说话人说话内容的干扰必然会改变对正常单人说话的音素状态的识别,这些实际场景中出现的情况可以表明使用语言学信息有助于在重叠语音段检测中准确检测重叠语音,因此可以将语言学特征与声学特征融合,进行叠音检测。
具体的融合方式可以采用拼接方法,其中,拼接方法可以采用多种常规的方式,例如直接拼接等,对此本发明不作限定。具体地,将语言学特征与声学特征在特征维度进行拼接,得到新的融合特征,接续前文,声学特征的维度为d,语言学特征的维度是1,因此融合特征的维度是d+1,新的融合特征可以表示为xnew={xd+11,xd+12,xd+1t}。仍以待检测语音数据的语音帧数t为5,每一语音帧均由维度为13的向量表示其声学特征为例,与语言学特征融合后得到的融合特征用一个5行14列的矩阵xnew表示。
步骤s3、根据所述融合特征得到所述待检测语音数据中各第一语音片段的重叠得分,所述重叠得分反映了所述第一语音片段属于重叠语音片段的可能性大小。
此步骤即是根据步骤s2得到的融合特征得到待检测语音数据中各语音帧的重叠得分,然后在后续的步骤中,对重叠得分进行分析,根据分析结果判断待检测语音数据是否为叠音数据,以实现叠音检测。
具体而言,可以将步骤s2得到的融合特征输入预先构建的重叠得分模型,得到各语音帧的重叠得分。关于重叠得分模型,在本发明的一些实施方式中,所述预先构建的重叠得分模型可以采用对时序建模能力更强、可以更好地处理序列的长距离依赖关系的双向长短期记忆网络(bidirectionallongshort-termmemory,bi-lstm)模型得到重叠得分,bi-lstm模型的输入是步骤s2得到的融合特征,输出是重叠得分。具体而言,bi-lstm模型由bi-lstm层、全连接层和softmax层,考虑到网络模型的应用效率和网络复杂度,bi-lstm模型可以使用3层512维度的bi-lstm层,利用bi-lstm层,可以提取更高级抽象特征,bilstm层的输入xinput是步骤s2得到的融合特征xnew,bi-lstm层包括前向bilstm层和后向bi-lstm层,其中,前向bi-lstm层可以捕获正向语音信息,得到正向隐藏层状态向量,后向bi-lstm层可以捕获反向语音信息,得到反向隐藏层状态向量,然后将正向隐藏层状态向量和反向隐藏层状态向量拼接,得到bi-lstm层的输出矩阵x1={x10241,x10242,...x1024t},与单向的lstm相比,双向lstm网络模型可以学习到更多的信息。在待检测语音数据的语音帧数t为5的情况下,bi-lstm层的输出是5行1024列的矩阵x1。
接着,将bi-lstm层的输出x1输入到全连接层对特征维度进行降维,将特征维度降为2,得到全连接层的输出矩阵xoutput={x21,x22,…,x2t},在待检测语音数据的语音帧数t为5的情况下,全连接层的输出是5行2列的矩阵x1,这两列数据分别对应于某一语音帧为重叠语音帧的第一预测得分和同一语音帧为单人语音帧的第二预测得分。
然后,将全连接层的输出输入到softmax层,对第一预测得分和第二预测得分进行规整,得到第一规整预测得分和第二规整预测得分,使得与同一语音帧对应的第一规整预测得分和第二规整预测得分均在0和1之间,并且两者相加之和为1,最终得到的第一规整预测得分代表某一语音帧为重叠语音帧的预测概率,第二规整预测得分代表某一语音帧为单人语音帧的预测概率。因此,softmax层的输出是2个类别(“重叠语音帧”和“单人语音帧)的概率,本发明在其他方式中,第一规整预测得分为某一语音帧为单人语音帧的预测概率,第二规整预测得分为某一语音帧为重叠语音帧的预测概率,本发明对此不作具体限定。
在模型训练阶段,可以利用交叉熵准则对网络进行迭代更新,完成网络的训练。bi-lstm模型的训练与现有常见神经网络训练过程基本相同,在此不再详细阐述。
综上所述,在计算重叠得分时,利用了同时蕴含了待检测语音数据中的声音信息和文本信息的融合特征,挖掘出待检测语音数据中所包含的丰富信息,可以提高叠音检测的准确性和鲁棒性;本发明可以使用诸如bi-lstm的模型结构计算重叠得分,更好地处理序列的长距离依赖关系,可以利用第一语音片段的上下文信息,即利用当前时刻、上一时刻及下一时刻的信息得到重叠得分,从而更准确地得到第一语音片段属于重叠语音片段的概率,进而提高后续利用重叠得分得到叠音检测结果的准确性。
以上过程仅是对重叠得分模型的一种示意性举例,本实施例并不限定具体的确定重叠得分的过程及手段,但仍需要强调的是:bi-lstm模型本身虽然是常规手段,但本实施例设计bi-lstm模型这个步骤的目的是借助于bi-lstm模型来得到重叠得分,并在此基础上,对重叠得分进行分析,以此提高叠音检测的准确性。需要说明的是,本发明在一些实施方式中,可以采用其他分类模型,例如,可以采用深度神经网络(deepneuralnetwork,dnn)、卷积神经网络(convolutionalneuralnetwork,cnn)、或两者的结合等神经网络得到重叠得分。
步骤s4、按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段,其中,所述第二语音片段的长度大于所述第一语音片段的长度。
本发明考虑到一个语音段是短时连续的,该语音段要么是重叠语音,要么是单人语音,因此可以按照语音段逐段进行叠音检测。此步骤即是以比第一语音片段的时长更长的第二语音片段为单位对步骤s3得到的第一语音片段的重叠得分进行分析,根据分析结果判断与各第二语音片段对应的待检测语音数据是否为叠音数据,以实现叠音的逐段检测,与第一语音片段相比,这里的第二语音片段是粒度更大的语音片段,示例性地,在第一语音片段是语音帧的情况下,第二语音片段可以是指由多个语音帧组成的语音片段,即根据语音帧对第二语音片段进行分析;在第一语音片段是由多个语音帧组成的音素对应的语音片段的情况下,第二语音片段可以是由多个音素对应的小语音片段组成的更大的语音片段,即根据音素对应的小语音片段对第二语音片段进行分析,可见步骤s4的设计思路是通过分析小的语音片段的重叠得分,实现对大的语音片段的叠音检测。并且还需说明的是,当前检测的第二语音片段和上一时刻检测的第二语音片段以及下一时刻检测的第二语音片段之间可以有部分重叠的第一语音片段(例如,语音帧),也可以没有重叠的第一语音片段,本发明对此不做限定。现有技术中按照语音帧进行叠音检测,一帧的时长是0.01秒,出现这么短的重叠音或单人音的情况是不合理的,在一个语音段中会出现很多帧是单人语音帧(标注为0),但中间少数几个帧是重叠音帧(标注为1),即在一个语音段中会出现几个奇点,影响对语音段整体的叠音判断结果。与现有技术中的逐帧检测相比,本发明按照语音段实现叠音检测,检测结果为整个语音段为重叠语音段(标注为1)还是单人语音段(标注为0),因此与现有技术相比,可以对叠音检测结果进行顺滑,减少检测结果中某些奇异点的问题,因而可以提高叠音检测的准确性。
具体而言,可以利用预设的滑窗及阈值检测策略按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段。具体地,本发明在一些实施方式中,预设的滑窗及阈值检测策略可以如图4所示,包括如下步骤:
步骤s41、利用滑窗统计落入所述滑窗内的各第一语音片段的重叠得分;
本发明以滑窗的形式完成对每个第二语音片段的叠音检测。仍以第一语音片段为语音帧为例进行说明,首先设定滑窗的窗长,比如可将窗长设定为300帧(即3秒的语音长度),其表示每次取300帧的重叠得分的结果作为基础进行进一步判断,然后设定在滑窗移动过程中的窗移,比如将窗移设定为100帧(即1秒的语音长度),其表示每次移动100帧。如图5示出的滑窗,窗长是6帧,窗移是1帧。窗长影响叠音检测的颗粒度,即以多少个语音帧进行叠音检测结果的判断,窗移影响叠音检测的速度。
步骤s42、若所述滑窗内的第一语音片段的重叠得分大于预设第一阈值,则确定所述第一语音片段为重叠语音片段;
将滑窗内的重叠得分大于第一阈值p1(例如为0.6)的语音帧作为重叠语音帧(标记为1),反之,将滑窗内的重叠得分小于等于预设第一阈值的语音帧作为单人语音帧(标记为0),即重叠得分超过第一阈值的语音帧就认为是重叠语音帧。这一步骤的目的是根据滑窗内各语音帧的重叠得分与预设第一阈值的比较结果,将滑窗内的各语音帧划分为重叠语音帧和单人语音帧。
步骤s43、若所述滑窗内的所述重叠语音片段的占比大于预设第二阈值,则确定所述滑窗对应的所述第二语音片段为重叠语音段。
将其中重叠语音帧的占比大于第二阈值p2(例如为0.5)的滑窗所对应的第二语音片段作为重叠语音段。在确定滑窗内的300个语音帧是否为重叠语音帧后,再以滑窗内300各语音帧中重叠语音帧在所有语音帧的占比,确定滑窗对应的第二语音片段是否为重叠语音段。
与单人语音段相比,滑窗经过重叠语音段时,每个语音片段被判断为重叠语音片段的可能性提高,进而在整个滑窗内,重叠语音片段的占比会提高,因此该滑窗对应的第二语音片段被判断为重叠语音段,从而实现对较短时长的重叠语音段也能很好的召回。
通过调节第一阈值及第二阈值,可以平衡在不同应用场景中对重叠语音检测的正确率和召回率。正确率是针对检测结果而言的,它表示的是检测结果为重叠语音段的语音段中有多少是真正的重叠语音段;而召回率是针对待检测语音数据而言的,它表示的是待检测语音数据中的重叠语音段有多少被判断正确了,两者的分母不同,正确率的分母是判断为重叠语音段的样本数,召回率的分母是原来样本中所有的重叠语音段。第一阈值p1越小,滑窗内的某个语音帧更倾向于被判断为重叠语音帧,滑窗所对应的第二语音片段则更倾向于被判断为重叠语音段,即提高了召回率,当然可以理解的是,降低第一阈值p1的同时会降低正确率。类似地,第二阈值p2越小,滑窗所对应的第二语音片段则更倾向于被判断为重叠语音段,即提高了召回率,当然可以理解的是降低第二阈值p2的同时会降低正确率。因此降低第一阈值及第二阈值,可以提高召回率降低正确率,增加第一阈值及第二阈值,可以提高正确率降低召回率,通过调节第一阈值及第二阈值,可以达到正确率和召回率的平衡。
综上所述,本发明的核心构思在于提出一种利用将声学特征和语言学特征融合所得到的融合特征作为重叠语音段的检测特征的叠音检测方案,具体是根据融合特征得到待检测语音数据中各第一语音片段的重叠得分,然后按照时长更长的第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段。由于融合了蕴含文本信息的语言学特征,同时考虑了待检测语音数据中的声音信息和文本信息,以此作为重叠语音段的检测特征,在计算重叠得分时,利用了同时蕴含了待检测语音数据中的声音信息和文本信息的融合特征,挖掘出待检测语音数据中所包含的丰富信息,可以提高叠音检测的准确性和鲁棒性;同时,按照第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段,可以对叠音检测结果进行顺滑,减少叠音检测结果中某些奇异点的问题,进一步提高叠音检测的准确性。
进一步地,本发明还利用预设的滑窗及阈值检测策略按照第二语音片段逐段对重叠得分进行分析,以确定各第二语音片段是否为重叠语音段,通过调节第一阈值及第二阈值,可以平衡在不同应用场景中对重叠语音检测的正确率和召回率;与单人语音段相比,滑窗经过重叠语音段时,每个语音片段被判断为重叠语音片段的可能性提高,进而在整个滑窗内,重叠语音片段的占比会提高,因此该滑窗对应的第二语音片段被判断为重叠语音段,从而实现对较短时长的重叠语音段也能很好的召回。
进一步地,本发明还利用预先训练的重叠语音声学模型和单人说话声学模型,根据体现了重叠语音声学模型对第一语音片段的识别结果的第一最大后验概率和体现了单人说话声学模型对第一语音片段的识别结果的第二最大后验概率得到语言学特征,便于准确地提取待检测语音数据中每一第一语音片段的语言学特征,进而提高叠音检测的准确性。
进一步地,本发明还使用bi-lstm的模型结构计算重叠得分,更好地处理序列的长距离依赖关系,可以利用第一语音片段的上下文信息,即利用当前时刻、上一时刻及下一时刻的信息得到重叠得分,从而更准确地得到第一语音片段属于重叠语音片段的概率,进而提高后续利用重叠得分得到叠音检测结果的准确性。
相应于上述各实施例及优选方案,本发明还提供了一种叠音检测装置的实施例,如图6所示,具体可以包括如下部件:
特征提取模块101,用于分别提取待检测语音数据的声学特征和语言学特征;
特征融合模块102,用于将所述语言学特征与所述声学特征融合,得到融合特征;
重叠得分计算模块103,用于根据所述融合特征得到所述待检测语音数据中各第一语音片段的重叠得分,所述重叠得分反映了所述第一语音片段属于重叠语音片段的可能性大小;
重叠得分分析模块104,用于按照第二语音片段逐段对所述重叠得分进行分析,以确定各所述第二语音片段是否为重叠语音段,其中,所述第二语音片段的长度大于所述第一语音片段的长度。
在其中一种可能的实现方式中,所述特征提取模块102包括:
声学特征提取单元,用于提取所述待检测语音数据中各第一语音片段的声学特征;
语言学特征提取单元,用于利用预先训练的重叠语音声学模型和单人说话声学模型提取所述待检测语音数据中各第一语音片段的语言学特征。
在其中一种可能的实现方式中,所述语言学特征提取单元包括:
第一最大后验概率及第二最大后验概率计算子单元,用于针对每一第一语音片段,利用所述重叠语音声学模型对所述第一语音片段进行识别,得到第一最大后验概率,并利用所述单人说话声学模型对所述第一语音片段进行识别得到第二最大后验概率,其中所述第一最大后验概率为利用所述重叠语音声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率,所述第二最大后验概率为利用所述单人说话声学模型识别所述第一语音片段属于各个声学建模单元时的各个后验概率中的最大概率;
语言学特征生成子单元,用于根据所述第一最大后验概率和所述第二最大后验概率得到所述语言学特征。
在其中一种可能的实现方式中,所述重叠得分分析模块104利用预设的滑窗及阈值检测策略按照第二语音段逐段对所述重叠得分进行分析,以确定各所述第二语音段是否为重叠语音段。
在其中一种可能的实现方式中,所述重叠得分分析模块104包括:
滑窗统计单元,用于利用滑窗统计落入所述滑窗内的各第一语音片段的重叠得分;
重叠语音帧确定单元,用于若所述滑窗内的第一语音片段的重叠得分大于预设第一阈值,则确定所述第一语音片段为重叠语音片段;
重叠语音段确定单元,用于若所述滑窗内的所述重叠语音片段的占比大于预设第二阈值,则确定所述滑窗对应的所述第二语音片段为重叠语音段。
在其中一种可能的实现方式中,所述重叠得分计算模块103具体用于,将所述融合特征输入预先构建的重叠得分模型,得到各所述第一语音片段的重叠得分。
应理解以上图6所示的叠音检测装置的各个部件的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些部件可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分部件以软件通过处理元件调用的形式实现,部分部件通过硬件的形式实现。例如,某个上述模块可以为单独设立的处理元件,也可以集成在电子设备的某一个芯片中实现。其它部件的实现与之类似。此外这些部件全部或部分可以集成在一起,也可以独立实现。在实现过程中,上述方法的各步骤或以上各个部件可以通过处理器元件中的硬件的集成逻辑电路或者软件形式的指令完成。
例如,以上这些部件可以是被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(applicationspecificintegratedcircuit;以下简称:asic),或,一个或多个微处理器(digitalsingnalprocessor;以下简称:dsp),或,一个或者多个现场可编程门阵列(fieldprogrammablegatearray;以下简称:fpga)等。再如,这些部件可以集成在一起,以片上系统(system-on-a-chip;以下简称:soc)的形式实现。
综合上述各实施例及其优选方案,本领域技术人员可以理解的是,在实际操作中,本发明适用于多种实施方式,本发明以下述载体作为示意性说明:
(1)一种叠音检测设备,其可以包括:
一个或多个处理器、存储器以及一个或多个计算机程序,其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述设备执行时,使得所述设备执行前述实施例或等效实施方式的步骤/功能。
应理解,叠音检测设备能够实现前述实施例提供的方法的各个过程。该设备中的各个部件的操作和/或功能,可分别为了实现上述方法实施例中的相应流程。具体可参见前文中关于方法、装置等实施例的描述,为避免重复,此处适当省略详细描述。
应理解,叠音检测设备中的处理器可以是片上系统soc,该处理器中可以包括中央处理器(centralprocessingunit;以下简称:cpu),还可以进一步包括其它类型的处理器,例如:图像处理器(graphicsprocessingunit;以下简称:gpu)等,具体在下文中再作介绍。
总之,处理器内部的各部分处理器或处理单元可以共同配合实现之前的方法流程,且各部分处理器或处理单元相应的软件程序可存储在存储器中。
(2)一种可读存储介质,在可读存储介质上存储有计算机程序或上述装置,当计算机程序或上述装置被执行时,使得计算机执行前述实施例或等效实施方式的步骤/功能。
在本发明所提供的几个实施例中,任一功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的某些技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以如下所述软件产品的形式体现出来。
(3)一种计算机程序产品(该产品可以包括上述装置并可以存储于某存储介质中),该计算机程序产品在终端设备上运行时,使终端设备执行前述实施例或等效实施方式的叠音检测方法。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到上述实施方法中的全部或部分步骤可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,上述计算机程序产品可以包括但不限于是指app;接续前文再做补充说明,上述设备/终端可以是一台计算机设备(例如手机、pc终端、云平台、服务器、服务器集群或者诸如媒体网关等网络通信设备等)。并且,该计算机设备的硬件结构还可以具体包括:至少一个处理器,至少一个通信接口,至少一个存储器和至少一个通信总线;处理器、通信接口、存储器均可以通过通信总线完成相互间的通信。其中,处理器可能是一个中央处理器cpu、dsp、微控制器或数字信号处理器,还可包括gpu、嵌入式神经网络处理器(neural-networkprocessunits;以下简称:npu)和图像信号处理器(imagesignalprocessing;以下简称:isp),该处理器还可包括特定集成电路asic,或者是被配置成实施本发明实施例的一个或多个集成电路等,此外,处理器可以具有操作一个或多个软件程序的功能,软件程序可以存储在存储器等存储介质中;而前述的存储器/存储介质可以包括:非易失性存储器(non-volatilememory),例如非可移动磁盘、u盘、移动硬盘、光盘等,以及只读存储器(read-onlymemory;以下简称:rom)、随机存取存储器(randomaccessmemory;以下简称:ram)等。
本发明实施例中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示单独存在a、同时存在a和b、单独存在b的情况。其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项”及其类似表达,是指的这些项中的任意组合,包括单项或复数项的任意组合。例如,a,b和c中的至少一项可以表示:a,b,c,a和b,a和c,b和c或a和b和c,其中a,b,c可以是单个,也可以是多个。
本领域技术人员可以意识到,本说明书中公开的实施例中描述的各模块、单元及方法步骤,能够以电子硬件、计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方式来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
以及,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可。尤其,对于装置、设备等实施例而言,由于其基本相似于方法实施例,所以相关之处可参见方法实施例的部分说明即可。以上所描述的装置、设备等实施例仅仅是示意性的,其中作为分离部件说明的模块、单元等可以是或者也可以不是物理上分开的,即可以位于一个地方,或者也可以分布到多个地方,例如系统网络的节点上。具体可根据实际的需要选择其中的部分或者全部模块、单元来实现上述实施例方案的目的。本领域技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上依据图式所示的实施例详细说明了本发明的构造、特征及作用效果,但以上仅为本发明的较佳实施例,需要言明的是,上述实施例及其优选方式所涉及的技术特征,本领域技术人员可以在不脱离、不改变本发明的设计思路以及技术效果的前提下,合理地组合搭配成多种等效方案;因此,本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



