
 商标分类
商标分类  商标转让
商标转让 
基于条件变分自编码器的目标人语音增强方法与流程
 2021-01-28 18:01:58|
2021-01-28 18:01:58| 401|
401| 起点商标网
起点商标网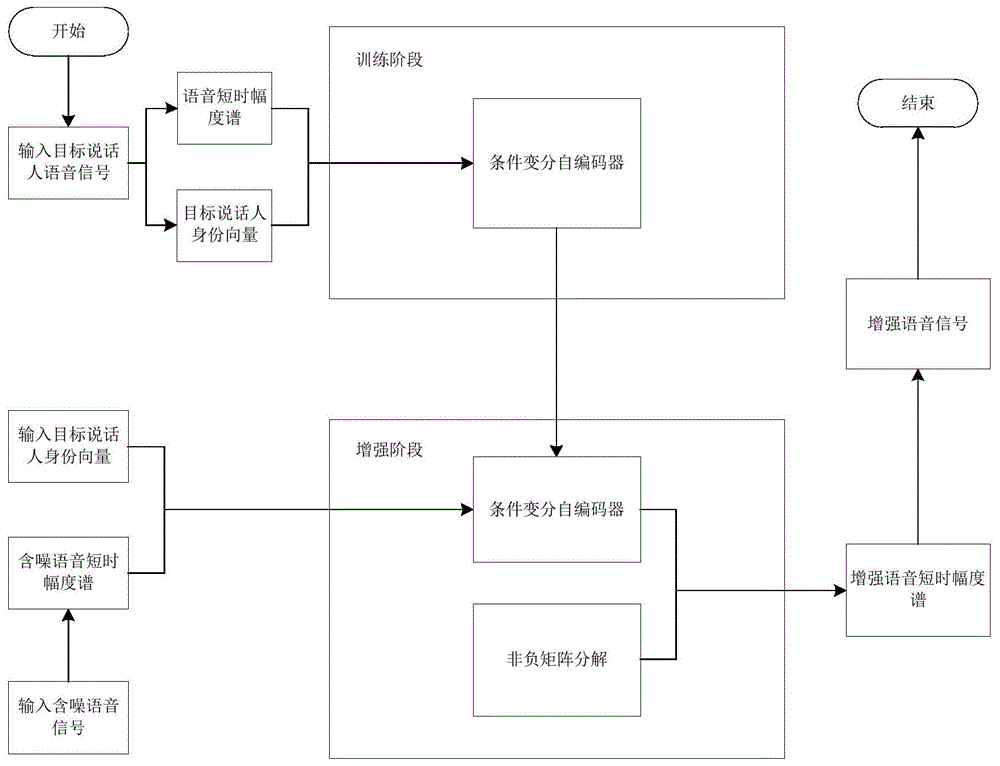
本发明属于语音增强的领域,具体涉及一种基于条件变分自编码器的目标人语音增强方法。
背景技术:
使用传声器在真实环境中采集到说话人的语音信号时,会同时采集到各种干扰信号,它们可能是背景噪声、房间混响等。这些噪声干扰在信噪比较低时会降低语音的质量,并且使语音识别准确率严重下降。从噪声干扰中提取目标语音的技术称为语音增强技术。
谱减法可以用来实现语音增强(boll,s.f.(1979)suppressionofacousticnoiseinspeechusingspectralsubtraction,ieeetransactionsonacoustics,speechandsignalprocessing,27,113–120.)。中国专利cn103594094a中,将语音通过短时傅里叶变换到时-频域,然后使用一种自适应的阈值的谱减法将当前帧的语音信号功率谱与估计的噪声功率谱相减,得到增强信号的功率谱,最后通过短时傅里叶逆变换得到时域的增强信号。然而,由于对语音和噪声做了不合理假设,这种增强方法对语音质量有较大损伤。
非负矩阵分解算法也被用于语音增强(wilsonkw,rajb,smaragdisp,etal.speechdenoisingusingnonnegativematrixfactorizationwithpriors[c].proceedingsoftheieeeinternationalconferenceonacoustics,speech,andsignalprocessing,2008.)。通过对语音和噪声的短时功率谱分别进行非负矩阵分解,可以得到语音和噪声的字典,在增强时通过该字典进行增强。中国专利cn104505100a就使用了一种结合谱减法和最小均方误差的非负矩阵分解算法进行语音增强。然而,非负矩阵分解仅仅对语音特征进行线性建模,对语音的非线性特性建模能力不佳,这限制了其性能。
最近,多种基于深度学习的生成模型被用于语音建模中,其中变分自编码器是一种显式地学习数据分布的方法,可以用于对语音进行非线性建模。文献(s.leglaive,l.girinandr.horaud,"avariancemodelingframeworkbasedonvariationalautoencodersforspeechenhancement,"2018ieee28thinternationalworkshoponmachinelearningforsignalprocessing(mlsp),aalborg,2018,pp.1-6,doi:10.1109/mlsp.2018.8516711.)就使用了一种联合变分自编码器和非负矩阵分解的语音增强算法,其中变分自编码器模型事先用清晰语音短时功率谱训练,非负矩阵模型在增强时学习,在不损伤语音质量的前提下,这种算法对非稳态的噪声有较好的增强效果。然而,由于变分自编码器模型使用了清晰语音训练,该增强模型对于人声干扰的增强能力不佳。
在实际应用中,噪声的种类千差万别,除了非人声噪声以外,从人声干扰下提取目标说话人的语音也是非常具有意义的。
技术实现要素:
现有技术在充满人声干扰的环境下使用变分自编码器-非负矩阵分解模型进行语音增强时,常常将干扰人声保留,影响了增强效果。本发明提出了一种基于条件变分自编码器的语音增强方法,该方法能有效应对人声干扰问题,提高语音增强性能。
本发明采用的技术方案为:
基于条件变分自编码器的目标人语音增强方法,包括以下步骤:
步骤1,对目标说话人的清晰语音数据做短时傅里叶变换,得到短时幅度谱;
步骤2,构建目标说话人的身份编码向量,使用该身份编码向量与步骤1得到的短时幅度谱来训练条件变分自编码器作为语音模型;所述条件变分自编码器的输入是目标说话人的语音幅度谱和其身份编码向量,输出的是目标说话人的语音幅度谱的对数;
步骤3,对含噪语音信号做短时傅里叶变换,得到短时幅度谱,并保留含噪语音信号的相位谱;
步骤4,将步骤3得到的含噪语音信号的短时幅度谱输入所述语音模型,将目标说话人身份编码向量作为语音模型条件项,固定语音模型的解码器的权重;将语音模型和非负矩阵分解模型联合迭代优化得到语音和噪声的幅度谱估计;
步骤5,使用步骤4得到的幅度谱估计和步骤3中保留的含噪语音信号的相位谱组合成复数谱,再通过逆短时傅里叶变换得到增强语音时域信号。
进一步地,所述步骤2中,条件变分自编码器使用深度神经网络作为编码器和解码器,编码器将语音幅度谱映射到随机变量z,解码器从随机变量z映射到清晰语音。
进一步地,所述步骤4中,将语音模型和非负矩阵分解模型联合迭代优化的具体步骤如下:
1)所述条件变分自编码器的编码器和解码器可以表示为如下形式:
zt~qφ(zt|xt,c)
xt~pθ(xt|zt,c)
其中xt为输入语音的第t帧幅度谱,zt为编码器输出的第t帧的隐变量,c表示说话人身份向量,φ和θ分别表示编码器和解码器的权重,qφ和pθ分别表示编码器生成隐变量的分布和解码器生成语音幅度谱估计的分布;
在训练好上述编码器和解码器后,固定解码器pθ(xt|zt,c)的权重,在语音增强时仅对编码器权重进行反向传播训练,语音模型输出的语音幅度谱估计为σ(zt,c),功率谱估计为σ2(zt,c);
2)非负矩阵分解可以表示为如下形式:
v=wh
其中
3)在优化时,输入含噪语音的幅度谱xt和目标说话人身份向量c,初始化非负矩阵分解的参数w、h和1维t帧的增益向量
其中
之后使用如下迭代公式迭代非负矩阵分解的参数w、h和at:
其中,
经过多次数迭代后,得到的清晰语音估计表示为:
其中,xft和
进一步地,步骤3)中,使用以下式子来优化目标函数:
其中,
与现有技术相比,本发明的有益效果为:本发明的方法能够在多种复杂噪声场景下进行语音增强,由于将目标说话人信息引入了训练过程,本发明的方法对非目标人声的干扰消除能力强。
附图说明
图1是本发明基于条件变分自编码器的目标人语音增强方法处理流程图。
图2是本发明实施例中采用的变分自编码器模型示意图;其中使用的深度神经网络是帧独立的全连接网络,|st|代表输入的清晰语音幅度谱,c代表该语音对应说话人的身份独热向量,embedding代表网络将说话人身份向量降维至10维,σ(|zt|,c)代表输出语音的幅度谱。
图3是现有的变分自编码器-非负矩阵分解算法与本发明方法在不同噪声类型条件下的增强语音sdr值对比图。
图4是本发明方法和现有的基于变分自编码器-非负矩阵分解模型的算法在多人声混合条件下对目标语音的增强效果对比图。(a)是混合语音短时幅度谱,(b)是现有算法增强语音短时幅度谱,(c)是本发明方法增强语音短时幅度谱。
具体实施方式
本发明基于条件变分自编码器的目标人语音增强方法主要包括以下几个部分:
1、目标人语音模型训练
1)对目标人清晰语音信号做短时傅里叶变换
若目标人清晰语音信号为x(t),做n点fft的短时傅里叶变换,得到t帧f维(f=n/2+1)复数频谱为x={x1,...,xt},其中
2)构建目标人身份向量
若有m个说话人的清晰语音数据,将每一个说话人的身份标注为一个m维的独热向量(one-hotvector),假设某个目标说话人是数据集中的第i位,则其身份向量的第i维为1,其余维度都为0。
3)条件变分自编码器的训练
条件变分自编码器模型由一个编码器(encoder)和一个解码器(decoder)组成。编码器的目标是将语音幅度谱|xt|映射到一个随机变量zt,而解码器的目标是将从这个随机变量映射回语音幅度谱,一般假设这个随机变量满足高斯分布。
因此编码器和解码器的模型可表示为:
zt~qφ(zt|xt,c)(2)
xt~pθ(xt|zt,c)(3)
其中c为条件项,即为步骤2)中的目标说话人身份向量,其与编码器和解码器的耦合可以参考附图2。本实施例中首先使用一个神经网络将m维的身份向量降维至10维,并将降维后的输出和编、解码器的每一个隐层输出拼接。
条件变分自编码器的训练目标是最大化解码器输出的似然,即要使解码器输出的语谱越靠近真实语谱越好。因此其目标函数可以写为对数似然:
采取变分推断方法可以将上述目标函数分解为更容易计算的下式:
其中的
因此目标函数可以改写为:
其中
2、使用迭代算法进行语音增强
1)对含噪语音信号做短时傅里叶变换
若含噪语音信号为x(t),做n点fft的短时傅里叶变换同样能得到复数频谱为x={x1,...,xt}。
2)使用非负矩阵分解模型建模噪声
与语音模型(8)类似,噪声模型也可以描述为以下分布形式:
其中矩阵
v=wh(10)
假设噪声是加性噪声,则含噪语音信号xft可表示为:
其中xft、sft和nft分别表示含噪语音谱、清晰语音谱和噪声谱,at代表增益向量的第t个元素。
3)迭代优化
本实施例优化的参数是噪声模型的参数{w,h,a}和语音模型,优化目标是使式(11)的含噪语音似然最大,这一般可以通过期望最大化算法进行(e-m)。对于语音模型,只要使得含噪语音的似然最大,该目标函数如下:
该式类似训练的目标函数(7),只不过要计算的是含噪语音功率谱|xft|2和估计的含噪语音功率谱atσ2(zt,c)+vft)的i-s散度,优化过程将固定解码器权重θ,只优化φ。
由于解码器是一个合适的语音生成模型,优化上述目标函数时,本实施例将固定解码器权重,只优化编码器权重。噪声模型的优化可以使用majorization-minimization(mm)算法,具体而言其通过以下迭代式子完成:
其中,
通过上述迭代,最后将得到收敛的语音和噪声参数,本实施例最终目标是计算清晰语音估计,其可以表示成如下期望:
实施例
下面结合附图,对本发明实施例中的技术方案进行清楚、完整地描述。
1、训练及测试样本和客观评价标准
本实施例的训练数据和测试样本均来源于timit语音库,该语音库包涵629个说话人的语音数据。对每个说话人取其中7/8数据作为训练数据,对每一个说话人构造一个629维的身份向量。本实施例的测试样本由timit语音库剩余的1/8数据和demand噪声库的17种不同场景的噪声按照信噪比-5db到5db随机混合而成,共850条。
本实施例采用的条件变分自编码器如附图2所示,编码器和解码器均由帧独立的全连接深度神经网络组成,其隐层维度为512,采用的激活函数是tanh。编码器的输入是清晰语音的短时幅度谱,输出是zt的均值和方差的对数,将它们通过重采样方法组合成zt后输入解码器,解码器的输出是清晰语音的短时幅度谱的对数。说话人身份向量将先通过一个降维层(embedding)降维至10维,并和编解码器的隐层输出拼接。训练时,我们将用于训练的清晰语音短时幅度谱在时间帧方向打乱输入网络进行计算。
本实施例采用sdr(signal-to-distortionratio)作为增强性能的客观评价指标。其描述了增强语音中目标语音相对残留噪声的信噪比,计算式如下:
其中
2、参数设置
1)信号的短时傅里叶变换
本实施例中所有的信号采样率均为16khz,进行短时傅里叶变换使用汉宁窗,窗长为1024(64ms),帧移为256(16ms)。
2)条件变分自编码器
本实施例中所采用的条件变分自编码器,输入及输出维度为513,隐层维度为512,隐变量zt的维度为64,说话人身份向量压缩后的维度为10。编码器和解码器均是仅有一层隐层的全连接网络。训练使用adam优化器以0.001的学习率进行优化。
3)非负矩阵分解
本实施例中所采用的非负矩阵分解秩为10。
4)迭代参数
本实施例在迭代过程中,条件变分自编码器的编码器仍然采用adam优化器以0.001的学习率进行优化。迭代次数为200次,每一次迭代完成一次条件变分自编码器的反向传播训练,并且使用公式(13)(14)(15)对噪声模型参数进行迭代,其中采样数r=1,即直接选择条件变分自编码器的一次输出代入迭代。最后得到语音估计时也仅通过一次采样计算期望,即把公式(16)改写为:
3、方法的具体实现流程
参考附图1,方法的实现主要分为训练阶段和增强阶段。
训练阶段使用清晰说话人语音做短时傅里叶变换的幅度谱以及说话人的身份向量输入网络进行训练。增强阶段输入某说话人的含噪语音,将其做短时傅里叶变换得到幅度谱,使用0~1均匀分布的随机数初始化w和h,并将a初始化为全1。将含噪语音幅度谱以及该说话人的身份向量输入条件变分自编码器,固定解码器权重开始迭代。使用公式(12)(13)(14)(15)完成200次迭代。迭代收敛之后使用最后得到的条件变分自编码器、w、h以及a,代入式(18)得到清晰语音时频谱估计,最后将清晰语音时频谱做短时傅里叶逆变换即可得到增强后的语音。
为了体现本发明相对于现有方法的性能提升,本实施例将和文献(s.leglaive,x.alameda-pineda,l.girinandr.horaud,“arecurrentvariationalautoencoderforspeechenhancement,”icassp2020-2020ieeeinternationalconferenceonacoustics,speechandsignalprocessing(icassp),barcelona,spain,2020,pp.371-375,doi:10.1109/icassp40776.2020.9053164.)中的基于变分自编码器-非负矩阵分解算法进行对比,该算法舍去了本发明中的目标人条件项。图3给出了两种方法在第1点所述的测试样本中的增强性能对比折线图。其中横轴是17种不同的噪声类型,纵轴是两种方法在某种噪声条件下,增强语音的平均sdr值。图中的五角星点曲线cvae表示本发明条件变分自编码器-非负矩阵分解算法的增强性能,圆点曲线vae(amp)表示现有变分自编码器-非负矩阵分解算法的增强性能。可以发现,本发明的方法在多种噪声场景下相对于现有的相关算法的增强性能都有一定提升。在现有算法增强性能较弱的几种充满人声干扰的噪声环境下(例如图3中增强效果不佳的meeting、cafeter等噪声,即在会议、咖啡店等充满其他说话人干扰的场景),本发明的性能提升更为明显。图4是在双说话人混合条件下语音增强实例,其中目标语音是女声,干扰语音是男声,(a)图是混合语音短时幅度谱,(b)图是现有算法增强语音短时幅度谱,(c)图是本发明方法增强语音短时幅度谱,可以发现现有算法将干扰男声几乎保留,而本发明的方法可以较好地消除干扰男声。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



