
 商标分类
商标分类  商标转让
商标转让 
终端设备的语音唤醒方法、系统、电子设备、存储介质与流程
 2021-01-28 17:01:09|
2021-01-28 17:01:09| 317|
317| 起点商标网
起点商标网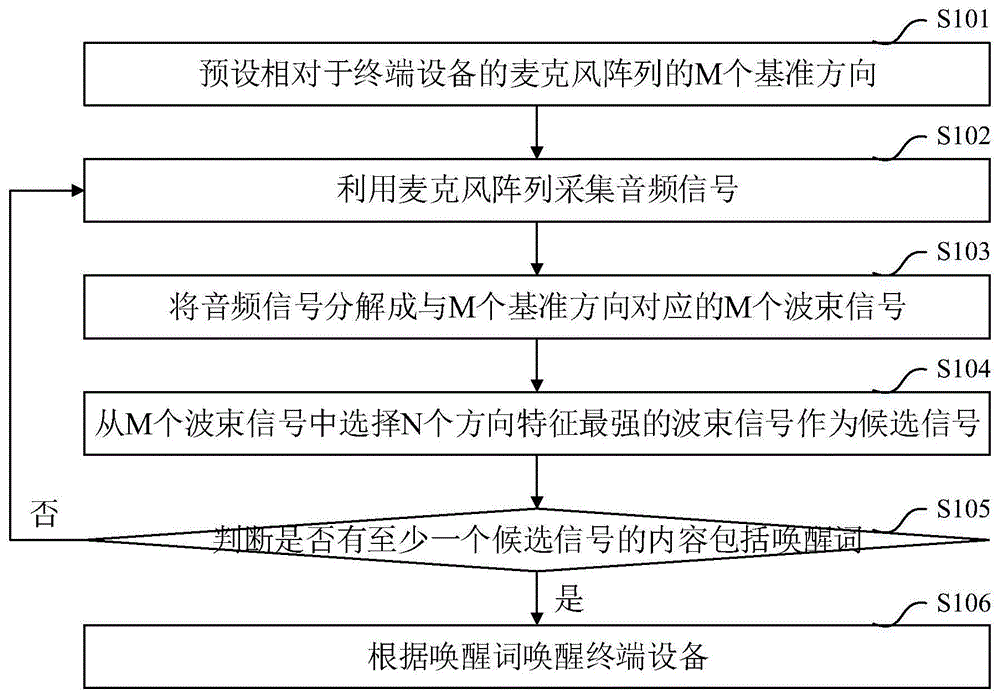
本发明涉及语音处理技术领域,尤其涉及一种终端设备的语音唤醒方法、系统、电子设备、存储介质。
背景技术:
随着硬件技术的飞速发展,尤其是高性能低功耗芯片技术的不断进步,使得智能耳机、智能音箱等语音终端成为了人机交互的主要方式,而手机、电脑等终端相应地退化成了资讯展示的界面。其中,基于语音终端的语音唤醒技术的好坏直接影响到用户的体验。
语音唤醒技术通常包括两方面内容,其一,声源辨别;其二,语音识别。关于声源辨别,由于回声、混响及多声源的叠加等会对声源音频产生巨大的干扰,从而语音终端难以从中辨别出真正的声源,进而,也就难以识别出声源音频的内容。
当前,通常基于以下原理来实现声源定位进而辨别出声源:基于最大输出功率的可控波束形成技术、基于到达时间差技术及基于高分辨率谱估计的定位,然而,上述声源定位实现方法仍然难以抵抗混响、噪声等的影响,换言之,上述声源定位实现方法的定位精度不高,容易受到干扰。
技术实现要素:
本发明实施例要解决的技术问题是为了克服现有技术中语音唤醒终端设备容易受到干扰的缺陷,提供一种终端设备的语音唤醒方法、系统、电子设备、存储介质。
本发明实施例是通过下述技术方案来解决上述技术问题:
一种终端设备的语音唤醒方法,其特点在于,所述语音唤醒方法包括:
预设相对于所述终端设备的麦克风阵列的m个基准方向;
利用所述麦克风阵列采集音频信号;
将所述音频信号分解成与m个基准方向对应的m个波束信号;
从m个波束信号中选择n个方向特征最强的波束信号作为候选信号;
判断是否有至少一个候选信号的内容包括唤醒词,若是,则根据所述唤醒词唤醒所述终端设备;
其中,m和n是正整数。
较佳地,所述判断是否有至少一个候选信号的内容包括唤醒词,若是,则根据所述唤醒词唤醒所述终端设备的步骤包括:
判断是否有至少一个候选信号的内容包括唤醒词,若是,则:
令初始值为0的计数值加1;
判断所述计数值是否达到计数阈值;
若达到所述计数阈值,则根据所述唤醒词唤醒所述终端设备;
若未达到所述计数阈值,则返回所述利用所述麦克风阵列采集音频信号的步骤;
若否,则将所述计数值清零,并返回所述利用所述麦克风阵列采集音频信号的步骤。
较佳地,在所述利用所述麦克风阵列采集音频信号的步骤之前,所述语音唤醒方法还包括:
利用所述麦克风阵列采集多个样本音频信号,其中,每一样本音频信号的声源方向已知且属于m个基准方向中的任意一个;
将所述样本音频信号分解成与m个基准方向对应的m个样本波束信号;
根据各样本音频信号分别构建第一训练数据集,所述第一训练数据集包括声源方向对应的样本波束信号以及表征所述声源方向的方向特征的样本方向数组,所述样本方向数组包括m个分别用于表征所述m个基准方向的元素;
根据所有第一训练数据集训练声源定位模型,所述声源定位模型用于根据输入的样本波束信号输出对应的样本方向数组;
所述从m个波束信号中选择n个方向特征最强的波束信号作为候选信号的步骤包括:
将m个波束信号依次输入所述声源定位模型,输出对应的方向数组,所述方向数组的m个元素分别用于表征所述m个波束信号的方向特征;
按照所述方向数组中元素的值从大到小的顺序选择n个波束信号作为候选信号。
较佳地,每一样本音频信号还标记有唤醒词,在所述利用所述麦克风阵列采集音频信号的步骤之前,所述语音唤醒方法还包括:
根据各样本音频信号分别构建第二训练数据集,所述第二训练数据集包括声源方向对应的样本波束信号以及样本识别数组,所述样本识别数组包括两个分别用于表征样本波束信号的内容包括所述唤醒词的概率以及不包括所述唤醒词的概率的元素;
根据所有第二训练数据集训练唤醒词识别模型,所述唤醒词识别模型用于根据输入的样本波束信号输出对应的样本识别数组;
所述判断是否有至少一个候选信号的内容包括唤醒词的步骤包括:
将n个候选信号依次输入所述唤醒词识别模型,分别输出对应的识别数组;
判断n个识别数组中表征包括所述唤醒词的概率的元素的最大值是否大于预设阈值;
若是,则确定有至少一个候选信号的内容包括唤醒词,并且最大值对应的候选信号所对应的基准方向是所述音频信号的声源方向;
若否,则确定候选信号的内容均不包括所述唤醒词。
较佳地,所述根据所有第一训练数据集训练声源定位模型的步骤包括:
利用卷积神经网络训练声源定位模型;
所述根据所有第二训练数据集训练唤醒词识别模型的步骤包括:
以样本波束信号在所述卷积神经网络中最后一个卷积层的数据为输入来训练唤醒词识别模型;
将n个候选信号依次输入所述唤醒词识别模型的步骤包括:
将n个候选信号在所述卷积神经网络中的最后一个卷积层的数据依次输入所述唤醒词识别模型。
较佳地,当判断所述计数值达到计数阈值时,所述根据所述唤醒词唤醒所述终端设备的步骤包括:
判断包括当前音频信号的连续计数阈值个音频信号的声源方向是否相同;
若是,则根据所述唤醒词唤醒所述终端设备。
较佳地,所述根据所有第二训练数据集训练唤醒词识别模型的步骤包括:
利用神经网络和连接时序分类训练唤醒词识别模型。
较佳地,所述利用所述麦克风阵列采集音频信号的步骤包括:
对所述音频信号进行回声消除处理。
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特点在于,所述处理器执行所述计算机程序时实现上述任一种终端设备的语音唤醒方法。
一种计算机可读存储介质,其上存储有计算机程序,其特点在于,所述计算机程序被处理器执行时实现上述任一种终端设备的语音唤醒方法的步骤。
一种终端设备的语音唤醒系统,其特点在于,所述语音唤醒系统包括:
基准方向预设模块,用于预设相对于所述终端设备的麦克风阵列的m个基准方向;
音频信号采集模块,用于利用所述麦克风阵列采集音频信号;
音频信号分解模块,用于将所述音频信号分解成与m个基准方向对应的m个波束信号;
候选信号选择模块,用于从m个波束信号中选择n个方向特征最强的波束信号作为候选信号;
判断模块,用于判断是否有至少一个候选信号的内容包括唤醒词,若是,则调用唤醒模块;
所述唤醒模块用于根据所述唤醒词唤醒所述终端设备;
其中,m和n是正整数。
较佳地,所述判断模块包括:
第一判断单元,用于判断是否有至少一个候选信号的内容包括唤醒词;
若所述第一单元判断为是,则调用:
计数单元,用于令初始值为0的计数值加1;
第二判断单元,用于判断所述计数值是否达到计数阈值;
若所述第二判断单元判断为是,则调用所述唤醒模块;
若所述第二判断单元判断为否,则调用所述音频信号采集模块;
若所述第一单元判断为否,则调用清零单元,并调用所述音频信号采集模块;
所述清零单元用于将所述计数值清零。
较佳地,所述音频信号采集模块还用于利用所述麦克风阵列采集多个样本音频信号,其中,每一样本音频信号的声源方向已知且属于m个基准方向中的任意一个;
所述音频信号分解模块还用于将所述样本音频信号分解成与m个基准方向对应的m个样本波束信号;
所述语音唤醒系统还包括:
第一构建模块,用于根据各样本音频信号分别构建第一训练数据集,所述第一训练数据集包括声源方向对应的样本波束信号以及表征所述声源方向的方向特征的样本方向数组,所述样本方向数组包括m个分别用于表征所述m个基准方向的元素;
第一训练模块,用于根据所有第一训练数据集训练声源定位模型,所述声源定位模型用于根据输入的样本波束信号输出对应的样本方向数组;
所述候选信号选择模块包括:
方向特征获取单元,用于将m个波束信号依次输入所述声源定位模型,输出对应的方向数组,所述方向数组的m个元素分别用于表征所述m个波束信号的方向特征;
候选信号选择单元,用于按照所述方向数组中元素的值从大到小的顺序选择n个波束信号作为候选信号。
较佳地,每一样本音频信号还标记有唤醒词,所述语音唤醒系统还包括:
第二构建模块,用于根据各样本音频信号分别构建第二训练数据集,所述第二训练数据集包括声源方向对应的样本波束信号以及样本识别数组,所述样本识别数组包括两个分别用于表征样本波束信号的内容包括所述唤醒词的概率以及不包括所述唤醒词的概率的元素;
第二训练模块,用于根据所有第二训练数据集训练唤醒词识别模型,所述唤醒词识别模型用于根据输入的样本波束信号输出对应的样本识别数组;
所述第一判断单元包括:
唤醒词识别子单元,用于将n个候选信号依次输入所述唤醒词识别模型,分别输出对应的识别数组;
判断子单元,用于判断n个识别数组中表征包括所述唤醒词的概率的元素的最大值是否大于预设阈值;
若是,则调用第一确定子单元;若否,则调用第二确定子单元;
所述第一确定子单元用于确定有至少一个候选信号的内容包括唤醒词,并且最大值对应的候选信号所对应的基准方向是所述音频信号的声源方向;
所述第二确定子单元用于确定候选信号的内容均不包括所述唤醒词。
较佳地,所述第一训练模块具体用于利用卷积神经网络训练声源定位模型;
所述第二训练模块具体用于以样本波束信号在所述卷积神经网络中最后一个卷积层的数据为输入来训练唤醒词识别模型;
所述唤醒词识别子单元具体用于将n个候选信号在所述卷积神经网络中的最后一个卷积层的数据依次输入所述唤醒词识别模型。
较佳地,所述判断模块包括:
第三判断单元,用于在所述第二判断单元判断为是时,判断包括当前音频信号的连续计数阈值个音频信号的声源方向是否相同;
若是,则调用所述唤醒模块。
较佳地,所述第二训练模块具体用于利用神经网络和连接时序分类训练唤醒词识别模型。
较佳地,所述音频信号采集模块包括:
回声消除单元,用于对所述音频信号进行回声消除处理。
本发明实施例的积极进步效果在于:本发明实施例并未采用声源定位算法,而是通过将采集到的音频信号分解为几个基准方向上的波束信号,进而根据各波束信号的方向特征来近似推断可能的声源方向,能够提高唤醒词的识别精度,极大限度地排除干扰信号对唤醒终端设备的影响。
附图说明
图1为根据本发明实施例1终端设备的语音唤醒方法的流程图。
图2为根据本发明实施例1终端设备的语音唤醒方法中基准方向的示意图。
图3为根据本发明实施例1终端设备的语音唤醒方法中训练声源定位模型的流程图。
图4为根据本发明实施例1终端设备的语音唤醒方法中训练唤醒词识别模型的流程图。
图5为根据本发明实施例1终端设备的语音唤醒方法中步骤s105的流程图。
图6为根据本发明实施例2的电子设备的硬件结构示意图。
图7为根据本发明实施例4终端设备的语音唤醒系统的模块示意图。
图8为根据本发明实施例4终端设备的语音唤醒系统中判断模块15的模块示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
本实施例提供一种终端设备的语音唤醒方法,图1示出了本实施例的流程图。参照图1,本实施例的语音唤醒方法包括:
s101、预设相对于终端设备的麦克风阵列的m个基准方向。
具体地,在本实施例中,正整数m可以取值为8,如图2所示,可以麦克风阵列所在位置为中心点o,设置相对于中心点o均匀分布的8个基准方向,分别记为:d1、d2、d3、d4、d5、d6、d7、d8。
s102、利用麦克风阵列采集音频信号。
在该步骤中,还可以采用例如语音自适应回声消除(aec)算法对采集到的音频信号进行回声消除处理,以提高后续对音频信号处理的准确度。
s103、将音频信号分解成与m个基准方向对应的m个波束信号。
在本实施例中,可以基于mvdr(minimumvariancedistortionlessresponse,最小方差无畸变失真响应)自适应波束形成算法,形成与8个基准方向对应的8个波束信号,分别记为:b1、b2、b3、b4、b5、b6、b7、b8,其中,波束信号bi对应于基准方向di(i是在1至8之间取值的正整数)。
s104、从m个波束信号中选择n个方向特征最强的波束信号作为候选信号。
在本实施例中,可以事先(步骤s101和步骤s102之间)训练声源定位模型来获知各波束信号方向特征的强弱。具体地,参照图3,训练声源定位模型的步骤可以包括:
s201、利用麦克风阵列采集多个样本音频信号。
在该步骤中,每一样本音频信号的声源方向已知,并且已知的声源方向属于8个基准方向中的任意一个。具体地,可以分别在基准方向d1、d2、d3、d4、d5、d6、d7、d8上发出样本声源信号,麦克风阵列即可采集到源自各个基准方向的样本音频信号。在该步骤中,也可以对样本音频信号进行回声消除处理,来提高训练数据的准确度。
s202、将样本音频信号分解成与m个基准方向对应的m个样本波束信号。
在该步骤中,以源自基准方向d1的样本音频信号为例,该样本音频信号可以经由例如mvdr自适应波束形成算法形成与8个基准方向对应的8个样本波束信号:b1(d1)、b2(d1)、b3(d1)、b4(d1)、b5(d1)、b6(d1)、b7(d1)、b8(d1),其中,样本波束信号bi(d1)是源自基准方向d1的样本音频信号经分解后在基准方向di上的样本波束信号。
s203、根据各样本音频信号分别构建第一训练数据集。
在该步骤中,第一训练数据集包括声源方向对应的样本波束信号以及表征声源方向的方向特征的样本方向数组。在本实施例中,样本方向数组可以包括8个分别用于表征8个基准方向的元素,记为:[p1、p2、p3、p4、p5、p6、p7、p8],其中,元素pi用于表征声源方向在基准方向di的上的概率,元素pi的值越大表示声源方向在该基准方向上的方向特征越强,并且
以源自基准方向d1的样本音频信号为例,基准方向d1是声源方向,样本波束信号b1(d1)与基准方向d1对应,由于仅以样本波束信号b1(d1)而非整个样本音频信号作为输入,有样本方向数组[1、0、0、0、0、0、0、0],是以,该组第一训练数据集可以包括{b1(d1),[1、0、0、0、0、0、0、0]}。如此,构建多组第一训练数据集。
s204、根据所有第一训练数据集训练声源定位模型。
在本实施例中,声源定位模型用于根据输入的样本波束信号输出对应的样本方向数组。具体地,在本实施例中,可以利用卷积神经网络训练声源定位模型,例如,可以将样本波束信号依次输入第一卷积层、第二卷积层、全连接层之后,输出样本方向数组。
在训练出声源定位模型之后,步骤s104可以具体包括:
将m个波束信号依次输入声源定位模型,输出对应的方向数组;
按照方向数组中元素的值从大到小的顺序选择n个波束信号作为候选信号。
具体地,在本实施例中,将波束信号b1、b2、b3、b4、b5、b6、b7、b8分别输入上述声源定位模型,输出的表征8个波束信号方向特征的方向数组例如是[0.4、0.25、0.05、0.03、0、0.01、0.06、0.2],则音频信号的声源方向是基准方向d1的概率为0.4,是基准方向d2的概率为0.25,……。在本实施例中,正整数n可以取值为3,则根据上述方向数组可以选择波束信号b1、b2、b8为候选信号。如此,滤除了声源方向的方向特征不明显的若干波束信号,保留了声源方向的方向特征比较明显的波束信号作为候选信号。
s105、判断是否有至少一个候选信号的内容包括唤醒词;
若是,则转至步骤s106;若否,则返回步骤s102;
s106、根据唤醒词唤醒终端设备。
在本实施例中,每一样本音频信号还标记有唤醒词,在训练声源定位模型的基础上,还可以训练唤醒词识别模型来获知各波束信号的内容包括唤醒词的概率。具体地,参照图4,训练唤醒词识别模型的步骤可以包括:
s301、根据各样本音频信号分别构建第二训练数据集。
在该步骤中,第二训练数据集包括声源方向对应的样本波束信号以及样本识别数组。在本实施例中,样本识别数组可以包括2个元素,记为:[q1、q2],其中,元素q1用于表征样本波束信号的内容包括唤醒词的概率,元素q2用于表征样本波束信号的内容包括唤醒词的概率,并且q1+q2=1。
在本实施例中,例如唤醒词是“哈喽”,样本音频信号源自基准方向d1并且包括唤醒词“哈喽”,则第二训练数据集可以包括{b1(d1),[1、0]}。如此,构建多组第二训练数据集。
s302、根据所有第二训练数据集训练唤醒词识别模型。
在本实施例中,唤醒词识别模型用于根据输入的样本波束信号输出对应的样本识别数组。具体地,在本实施例中,可以利用神经网络(例如循环神经网络(rnn)、深度神经网络(dnn)、卷积循环神经网络(crnn))和连接时序分类(ctc)训练唤醒词识别模型。
其中,为了降低数据维度,减小神经网络的计算量,可以不直接将样本波束信号输入神经网络,而是以样本波束信号在卷积神经网络中最后一个卷积层的数据作为神经网络的输入,例如,不直接以样本波束信号b1(d1)作为唤醒词识别模型的输入,而是以样本波束信号b1(d1)在上述第二卷积层的数据作为唤醒词识别模型的输入。
在本实施例中,参照图5,步骤s105可以具体包括:
s1051、判断是否有至少一个候选信号的内容包括唤醒词;
若是,则转至步骤s1052;若否,则转至步骤s1054;
s1052、令初始值为0的计数值加1;
s1053、判断计数值是否达到计数阈值;
若是,则执行步骤s106;若否,则返回步骤s102;
s1054、将计数值清零,并返回步骤s102。
在训练出唤醒词识别模型之后,步骤s1051可以具体包括:
将n个候选信号依次输入唤醒词识别模型,分别输出对应的识别数组;
判断n个识别数组中表征包括唤醒词的概率的元素的最大值是否大于预设阈值;
若是,则确定有至少一个候选信号的内容包括唤醒词,并且最大值对应的候选信号所对应的基准方向是音频信号的声源方向;
若否,则确定候选信号的内容均不包括唤醒词。
具体地,在本实施例中,例如,将候选信号b1输入上述唤醒词识别模型后,输出的识别数组是[0.8,0.2],则候选信号b1包括唤醒词“哈喽”的概率为0.8;将候选信号b2输入上述唤醒词识别模型后,输出的识别数组是[0.7,0.3],则候选信号b2包括唤醒词“哈喽”的概率为0.7;将候选信号b8输入上述唤醒词识别模型后,输出的识别数组是[0.6,0.4],则候选信号b8包括唤醒词“哈喽”的概率为0.6。其中,包括唤醒词“哈喽”的概率的最大值为0.8。相应地,可以上述候选信号在卷积神经网络中第二卷积层的数据作为上述唤醒词识别模型的输入。
在本实施例中,预设阈值可以在0和1之间取值。假设,在本实施例中,预设阈值取值为0.75,有包括唤醒词“哈喽”的最大概率0.8大于0.75,则可以确定有至少一个候选信号的内容包括唤醒词“哈喽”,并且最大概率0.8对应的候选信号b1所对应的基准方向d1是发出唤醒词“哈喽”的音频信号的声源方向。若在本实施例中预设阈值取值为0.85,有包括唤醒词“哈喽”的最大概率0.8小于0.85,则可以确定候选信号的内容均不包括唤醒词“哈喽”。
上述步骤s1051-s1054的设置,旨在对候选波束包括唤醒词的结果进行多次校验,以减少误唤醒,其中,计数阈值可以根据实际应用进行自定义设置,例如,在本实施例中,计数阈值可以取值为3。计数值达到计数阈值3,表示连续3次采集的音频信号均包括唤醒词。
在本实施例中,在计数值达到计数阈值的基础上,还可以做出进一步地校验,判断包括当前音频信号的连续计数阈值个音频信号的声源方向是否相同,若相同,则校验成功,否则,校验不成功。
具体地,在计数值累加的过程中,每次确定候选信号的内容包括唤醒词的同时,还确定一声源方向,也即,当计数值达到3时,对应有3个声源方向,当确定的3个声源方向为同一方向时,则校验成功,可以确定存在唤醒终端设备的音频信号,可以根据唤醒词唤醒终端设备。
在实施例中,并未采用声源定位算法,而是通过将采集到的音频信号分解为几个基准方向上的波束信号,进而根据各波束信号的方向特征来近似推断可能的声源方向,以提高唤醒词的识别精度,极大限度地排除干扰信号对唤醒终端设备的影响。
实施例2
本实施例提供一种电子设备,电子设备可以通过计算设备的形式表现(例如可以为服务器设备),包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其中处理器执行计算机程序时可以实现实施例1提供的终端设备的语音唤醒方法。
图6示出了本实施例的硬件结构示意图,如图6所示,电子设备9具体包括:
至少一个处理器91、至少一个存储器92以及用于连接不同系统组件(包括处理器91和存储器92)的总线93,其中:
总线93包括数据总线、地址总线和控制总线。
存储器92包括易失性存储器,例如随机存取存储器(ram)921和/或高速缓存存储器922,还可以进一步包括只读存储器(rom)923。
存储器92还包括具有一组(至少一个)程序模块924的程序/实用工具925,这样的程序模块924包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
处理器91通过运行存储在存储器92中的计算机程序,从而执行各种功能应用以及数据处理,例如本发明实施例1所提供的终端设备的语音唤醒方法。
电子设备9进一步可以与一个或多个外部设备94(例如键盘、指向设备等)通信。这种通信可以通过输入/输出(i/o)接口95进行。并且,电子设备9还可以通过网络适配器96与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。网络适配器96通过总线93与电子设备9的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备9使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理器、外部磁盘驱动阵列、raid(磁盘阵列)系统、磁带驱动器以及数据备份存储系统等。
应当注意,尽管在上文详细描述中提及了电子设备的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本申请的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
实施例3
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现实施例1提供的终端设备的语音唤醒方法的步骤。
其中,可读存储介质可以采用的更具体可以包括但不限于:便携式盘、硬盘、随机存取存储器、只读存储器、可擦拭可编程只读存储器、光存储器件、磁存储器件或上述的任意合适的组合。
在可能的实施方式中,本发明还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在终端设备上运行时,所述程序代码用于使所述终端设备执行实现实施例1中的终端设备的语音唤醒方法的步骤。
其中,可以以一种或多种程序设计语言的任意组合来编写用于执行本发明的程序代码,所述程序代码可以完全地在用户设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户设备上部分在远程设备上执行或完全在远程设备上执行。
实施例4
本实施例提供一种终端设备的语音唤醒系统,图7示出了本实施例的模块示意图。参照图7,本实施例的语音唤醒系统包括:
基准方向预设模块11,用于预设相对于终端设备的麦克风阵列的m个基准方向。
具体地,在本实施例中,正整数m可以取值为8,亦如图2所示,可以麦克风阵列所在位置为中心点o,设置相对于中心点o均匀分布的8个基准方向,分别记为:d1、d2、d3、d4、d5、d6、d7、d8。
音频信号采集模块12,用于利用麦克风阵列采集音频信号。
在本实施例中,音频信号采集模块12还可以包括回声消除单元,该回声消除单元可以采用例如语音自适应回声消除(aec)算法对采集到的音频信号进行回声消除处理,以提高后续对音频信号处理的准确度。
在本实施例中,音频信号采集模块12还用于利用麦克风阵列采集多个样本音频信号。其中,每一样本音频信号的声源方向已知,并且已知的声源方向属于8个基准方向中的任意一个。具体地,可以分别在基准方向d1、d2、d3、d4、d5、d6、d7、d8上发出样本声源信号,麦克风阵列即可采集到源自各个基准方向的样本音频信号。回声消除单元也可以对样本音频信号进行回声消除处理,来提高训练数据的准确度。
音频信号分解模块13,用于将音频信号分解成与m个基准方向对应的m个波束信号。
在本实施例中,可以基于mvdr(minimumvariancedistortionlessresponse,最小方差无畸变失真响应)自适应波束形成算法,形成与8个基准方向对应的8个波束信号,分别记为:b1、b2、b3、b4、b5、b6、b7、b8,其中,波束信号bi对应于基准方向di(i是在1至8之间取值的正整数)。
在本实施例中,音频信号分解模块13还用于将样本音频信号分解成与m个基准方向对应的m个样本波束信号。其中,以源自基准方向d1的样本音频信号为例,该样本音频信号可以经由例如mvdr自适应波束形成算法形成与8个基准方向对应的8个样本波束信号:b1(d1)、b2(d1)、b3(d1)、b4(d1)、b5(d1)、b6(d1)、b7(d1)、b8(d1),其中,样本波束信号bi(d1)是源自基准方向d1的样本音频信号经分解后在基准方向di上的样本波束信号。
第一构建模块21,用于根据各样本音频信号分别构建第一训练数据集。
在本实施例中,第一训练数据集包括声源方向对应的样本波束信号以及表征声源方向的方向特征的样本方向数组。在本实施例中,样本方向数组可以包括8个分别用于表征8个基准方向的元素,记为:[p1、p2、p3、p4、p5、p6、p7、p8],其中,元素pi用于表征声源方向在基准方向di的上的概率,元素pi的值越大表示声源方向在该基准方向上的方向特征越强,并且
以源自基准方向d1的样本音频信号为例,基准方向d1是声源方向,样本波束信号b1(d1)与基准方向d1对应,由于仅以样本波束信号b1(d1)而非整个样本音频信号作为输入,有样本方向数组[1、0、0、0、0、0、0、0],是以,该组第一训练数据集可以包括{b1(d1),[1、0、0、0、0、0、0、0]}。如此,构建多组第一训练数据集。
第一训练模块22,用于根据所有第一训练数据集训练声源定位模型。
在本实施例中,声源定位模型用于根据输入的样本波束信号输出对应的样本方向数组,来获知各波束信号方向特征的强弱。具体地,在本实施例中,可以利用卷积神经网络训练声源定位模型,例如,可以将样本波束信号依次输入第一卷积层、第二卷积层、全连接层之后,输出样本方向数组。
候选信号选择模块14,用于从m个波束信号中选择n个方向特征最强的波束信号作为候选信号。参见图7,候选信号选择模块14可以具体包括:
方向特征获取单元141,用于将m个波束信号依次输入声源定位模型,输出对应的方向数组;
候选信号选择单元142,用于按照方向数组中元素的值从大到小的顺序选择n个波束信号作为候选信号。
具体地,在本实施例中,方向特征获取单元141将波束信号b1、b2、b3、b4、b5、b6、b7、b8分别输入上述声源定位模型,输出的表征8个波束信号方向特征的方向数组例如是[0.4、0.25、0.05、0.03、0、0.01、0.06、0.2],则音频信号的声源方向是基准方向d1的概率为0.4,是基准方向d2的概率为0.25,……。在本实施例中,正整数n可以取值为3,则候选信号选择单元142根据上述方向数组可以选择波束信号b1、b2、b8为候选信号。如此,滤除了声源方向的方向特征不明显的若干波束信号,保留了声源方向的方向特征比较明显的波束信号作为候选信号。
第二构建模块31,用于根据各样本音频信号分别构建第二训练数据集。
在本实施例中,每一样本音频信号还标记有唤醒词,第二训练数据集包括声源方向对应的样本波束信号以及样本识别数组。在本实施例中,样本识别数组可以包括2个元素,记为:[q1、q2],其中,元素q1用于表征样本波束信号的内容包括唤醒词的概率,元素q2用于表征样本波束信号的内容包括唤醒词的概率,并且q1+q2=1。
在本实施例中,例如唤醒词是“哈喽”,样本音频信号源自基准方向d1并且包括唤醒词“哈喽”,则第二训练数据集可以包括{b1(d1),[1、0]}。如此,构建多组第二训练数据集。
第二训练模块32,用于根据所有第二训练数据集训练唤醒词识别模型。
在训练声源定位模型的基础上,本实施例还可以训练唤醒词识别模型来获知各波束信号的内容包括唤醒词的概率,其中,唤醒词识别模型用于根据输入的样本波束信号输出对应的样本识别数组。具体地,在本实施例中,可以利用神经网络(例如循环神经网络(rnn)、深度神经网络(dnn)、卷积循环神经网络(crnn))和连接时序分类(ctc)训练唤醒词识别模型。
为了降低数据维度,减小神经网络的计算量,可以不直接将样本波束信号输入神经网络,而是以样本波束信号在卷积神经网络中最后一个卷积层的数据作为神经网络的输入,例如,不直接以样本波束信号b1(d1)作为唤醒词识别模型的输入,而是以样本波束信号b1(d1)在上述第二卷积层的数据作为唤醒词识别模型的输入。
判断模块15,用于判断是否有至少一个候选信号的内容包括唤醒词;
若是,则调用唤醒模块16;若否,则调用音频信号采集模块12;
唤醒模块16用于根据唤醒词唤醒终端设备。
参见图8,判断模块15可以具体包括:
第一判断单元151,用于判断是否有至少一个候选信号的内容包括唤醒词;
若是,则调用计数单元152;若否,则调用清零单元154,并调用音频信号采集模块12;
计数单元152,用于令初始值为0的计数值加1;
第二判断单元153,用于判断计数值是否达到计数阈值;
若是,则调用唤醒模块16;若否,则调用音频信号采集模块12;
清零单元154,用于将计数值清零。
参见图8,第一判断单元151可以具体包括:
唤醒词识别子单元1511,用于将n个候选信号依次输入唤醒词识别模型,分别输出对应的识别数组;
判断子单元1512,用于判断n个识别数组中表征包括唤醒词的概率的元素的最大值是否大于预设阈值;
若是,则调用第一确定子单元1513;若否,则调用第二确定子单元1514;
第一确定子单元1513,用于确定有至少一个候选信号的内容包括唤醒词,并且最大值对应的候选信号所对应的基准方向是音频信号的声源方向;
第二确定子单元1514,用于确定候选信号的内容均不包括唤醒词。
具体地,在本实施例中,例如,唤醒词识别子单元1511将候选信号b1输入上述唤醒词识别模型后,输出的识别数组是[0.8,0.2],则候选信号b1包括唤醒词“哈喽”的概率为0.8;将候选信号b2输入上述唤醒词识别模型后,输出的识别数组是[0.7,0.3],则候选信号b2包括唤醒词“哈喽”的概率为0.7;将候选信号b8输入上述唤醒词识别模型后,输出的识别数组是[0.6,0.4],则候选信号b8包括唤醒词“哈喽”的概率为0.6。其中,包括唤醒词“哈喽”的概率的最大值为0.8。相应地,可以上述候选信号在卷积神经网络中第二卷积层的数据作为上述唤醒词识别模型的输入。
在本实施例中,预设阈值可以在0和1之间取值。假设,在本实施例中,预设阈值取值为0.75,判断子单元1512判断包括唤醒词“哈喽”的最大概率0.8大于0.75,则可以调用第一确定子单元1513确定有至少一个候选信号的内容包括唤醒词“哈喽”,并且最大概率0.8对应的候选信号b1所对应的基准方向d1是发出唤醒词“哈喽”的音频信号的声源方向。若在本实施例中预设阈值取值为0.85,判断子单元1512判断包括唤醒词“哈喽”的最大概率0.8小于0.85,则可以调用第二确定子单元1514确定候选信号的内容均不包括唤醒词“哈喽”。
本实施例中,判断模块15各组成单元的设置,旨在对候选波束包括唤醒词的结果进行多次校验,以减少误唤醒,其中,计数阈值可以根据实际应用进行自定义设置,例如,在本实施例中,计数阈值可以取值为3。计数值达到计数阈值3,表示连续3次采集的音频信号均包括唤醒词。
在本实施例中,判断模块15还可以包括第三判断单元,用于在第二判断单元判断为是时,判断包括当前音频信号的连续计数阈值个音频信号的声源方向是否相同,以做出进一步地校验。其中,若第三判断单元判断为是,则校验成功,否则,校验不成功。
具体地,在计数值累加的过程中,第一确定子单元1513每次确定候选信号的内容包括唤醒词的同时,还确定一声源方向,也即,当计数值达到3时,对应有3个声源方向,当确定的3个声源方向为同一方向时,则校验成功,可以确定存在唤醒终端设备的音频信号,可以调用模型模块6根据唤醒词唤醒终端设备。
在本实施例中,并未采用声源定位算法,而是通过将采集到的音频信号分解为几个基准方向上的波束信号,进而根据各波束信号的方向特征来近似推断可能的声源方向,以提高唤醒词的识别精度,极大限度地排除干扰信号对唤醒终端设备的影响。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



