
 商标分类
商标分类  商标转让
商标转让 
车内交互音频加密方法、装置及设备与流程
 2021-01-28 17:01:39|
2021-01-28 17:01:39| 379|
379| 起点商标网
起点商标网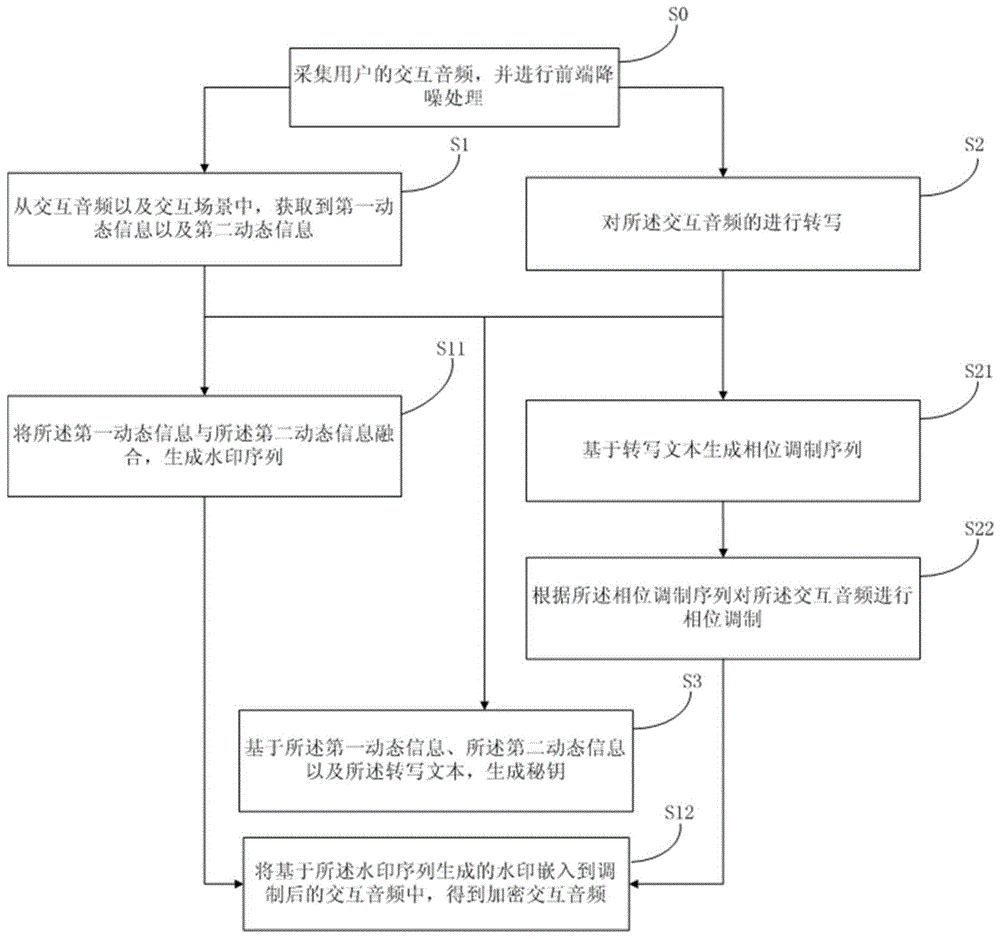
本发明涉及车联网领域,尤其涉及一种车内交互音频加密方法、装置及设备。
背景技术:
现有成熟的音频处理技术,例如但不限于回声消除、单麦克风降噪、麦克风阵列降噪等前端语音增强技术的效果在很大程度上得到了提升。与此同时,随着车联网的发展和普及,车内用户的交互音频可以通过多种途径被外部设备获取到并进行相应的应用处理,例如语义理解、业务查询、数据备份、匹配检索、远程服务请求等,在进行这些操作的过程中,通常车机会将人机交互信息经本地前端处理后传输至云端后台。但是由于相关法律法规和行业规范尚未完善,并且人机交互信息的传输动作一般不需要用户授权,这样非常容易发生车内用户信息甚至隐私被窃取的事件,因此,从信息安全角度,有必要在前端对车内用户的信息及隐私加强保护。
现有的加密保护方法是交互音频在经过前端降噪处理后,在音频的高频段添加一段固定码字序列编码的单频信号,此方式的设计核心是基于固定信息,因此加密内容较容易被破解。
技术实现要素:
鉴于上述,本发明旨在提供一种车内交互音频加密方法、装置以及设备,并相应地提出一种计算机可读存储介质以及计算机程序产品,通过多种动态信息联合加密的方式,能够有效解决现有对车内交互语音依靠固定信息进行加密的弊端。
本发明采用的技术方案如下:
第一方面,本发明提供了一种车内交互音频加密方法,包括:
从用户的交互音频以及交互场景中,获取到第一动态信息以及第二动态信息;
将所述第一动态信息与所述第二动态信息融合,生成水印序列;
基于所述交互音频的转写文本,生成相位调制序列;
基于所述第一动态信息、所述第二动态信息以及所述转写文本,生成秘钥;
根据所述相位调制序列对所述交互音频进行相位调制;
将基于所述水印序列生成的水印嵌入到调制后的交互音频中,得到加密交互音频。
在其中至少一种可能的实现方式中,所述第一动态信息为用户个人信息;所述第二动态信息为车辆信息。
在其中至少一种可能的实现方式中,所述用户个人信息包括如下一种或多种:声纹信息、年龄以及性别;所述车辆信息包括:所在位置、车速、胎压、油温、电池电量、用户对车内设备的设置参数、开窗状态、胎压以及乘员数量。
在其中至少一种可能的实现方式中,所述将所述第一动态信息与所述第二动态信息融合,生成水印序列包括:
将所述用户个人信息的特征向量与所述车辆信息的特征向量进行拼接,得到特征融合序列;
分别以所述特征融合序列的每一维特征作为初始条件,生成近似服从高斯分布的第一随机矩阵;
根据预设策略从所述第一随机矩阵中获取到所述水印序列。
在其中至少一种可能的实现方式中,所述基于所述交互音频的转写文本,生成相位调制序列包括:
将所述转写文本编码表示为数字序列;
分别以所述数字序列中每个数字作为初始条件,生成近似服从高斯分布的第二随机矩阵;
根据预设策略从所述第二随机矩阵中获取到所述相位调制序列。
在其中至少一种可能的实现方式中,所述基于所述第一动态信息、所述第二动态信息以及所述转写文本,生成秘钥包括:
将所述第一动态信息与所述第二动态信息融合,并根据预设策略生成第一单频信号;
根据预设策略以及所述转写文本生成第二单频信号;
将所述第一单频信号与所述第二单频信号融合,得到所述秘钥。
在其中至少一种可能的实现方式中,所述方法还包括:将所述秘钥以及所述加密交互音频分别配置在不同的传输通道。
第二方面,本发明提供了一种车内交互音频加密装置,包括:
动态信息获取模块,用于从用户的交互音频以及交互场景中,获取到第一动态信息以及第二动态信息;
水印生成模块,用于将所述第一动态信息与所述第二动态信息融合,生成水印序列;
相位调制序列生成模块,用于基于所述交互音频的转写文本,生成相位调制序列;
秘钥生成模块,用于基于所述第一动态信息、所述第二动态信息以及所述转写文本,生成秘钥;
相位调制模块,用于根据所述相位调制序列对所述交互音频进行相位调制;
水印添加模块,用于将基于所述水印序列生成的水印嵌入到调制后的交互音频中,得到加密交互音频。
在其中至少一种可能的实现方式中,所述第一动态信息包括用户的声纹信息;所述第二动态信息包括如下一种或多种车辆信息:位置、车速、开窗状态、胎压以及乘员数量。
在其中至少一种可能的实现方式中,所述水印生成模块包括:
特征拼接单元,用于将用户的声纹信息的特征向量与车辆信息的特征向量进行拼接,得到特征融合序列;
第一矩阵表示单元,用于分别以所述特征融合序列的每一维特征作为初始条件,生成近似服从高斯分布的第一随机矩阵;
水印获取单元,用于根据预设策略从所述第一随机矩阵中获取到所述水印序列。
在其中至少一种可能的实现方式中,所述相位调制序列生成模块包括:
编码单元,用于将所述转写文本编码表示为数字序列;
第二矩阵表示单元,用于分别以所述数字序列中每个数字作为初始条件,生成近似服从高斯分布的第二随机矩阵;
相位调制序列获取单元,用于根据预设策略从所述第二随机矩阵中获取到所述相位调制序列。
在其中至少一种可能的实现方式中,所述秘钥生成模块包括:
第一单频信号生成单元,用于将所述第一动态信息与所述第二动态信息融合,并根据预设策略生成第一单频信号;
第二单频信号生成单元,用于根据预设策略以及所述转写文本生成第二单频信号;
秘钥生成单元,用于将所述第一单频信号与所述第二单频信号再融合,得到所述秘钥。
在其中至少一种可能的实现方式中,所述装置还包括:加密信息传输配置模块,用于将所述秘钥以及所述加密交互音频分别配置在不同的传输通道。
第三方面,本发明提供了一种车内交互音频加密设备,包括:
一个或多个处理器、存储器以及一个或多个计算机程序,所述存储器可以采用非易失性存储介质,其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述设备执行时,使得所述设备执行如第一方面或者第一方面的任一可能实现方式中的所述方法。
第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行如第一方面或者第一方面的任一可能实现方式中的所述方法。
第五方面,本发明还提供了一种计算机程序产品,当所述计算机程序产品被计算机执行时,用于执行第一方面或者第一方面的任一可能实现方式中的所述方法。
在第五方面的一种可能的设计中,该产品涉及到的相关程序可以全部或者部分存储在与处理器封装在一起的存储器上,也可以部分或者全部存储在不与处理器封装在一起的存储介质上。
本发明摒弃固定信息加密思路,基于车内音频交互所涉及的多种动态信息并采取多环节联合应用的思路,提出了一种具有很高安全性、可靠性的交互音频加密方案。具体是从用户的交互音频以及交互场景中至少提取到两种不同维度的动态信息,并将多种动态信息相互融合用于生成水印,而又以与交互音频内容相关的转写文本作为另一种动态信息,用于对音频进行相位调制,除此之外,进一步地还考虑综合上述各种动态信息生成相应秘钥,并以独立的传输通道分别向外发送秘钥和加密音频,这样,基于上述种种安全措施的联合应用,可以有效保护车内用户的个人信息乃至隐私,与现有方式相比,大大增加了非授权破解的难度。
附图说明
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步描述,其中:
图1为本发明提供的车内交互音频加密方法的实施例的流程图;
图2为本发明提供的生成水印过程的实施例的示意图;
图3为本发明提供的车内交互音频加密装置的实施例的方框图。
具体实施方式
下面详细描述本发明的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
在对本发明技术方案进行说明之前,首先对现有的车内交互音频加密方案再做说明,从本领域技术发展来看,车内交互语音的防攻击技术还不太成熟,在语音交互过程中,基本是对音频压缩编码后直接明文传输,在服务端进行相应处理等。这样一旦黑客截取到车内用户音频,利用音频的声纹特征模拟车内用户的语音请求,无疑使得驾驶安全无法得到保障。
又如前文所述,现有的对车内交互音频的加密方式是在音频高频段添加固定码字序列编码的单频信号,远程的接收端在解码时,通过检测高频段是否含有特定码字序列编码的单频信号来判断输入音频是否为受保护的前端降噪引擎处理的车内交互音频,从而在一定程度上可以起到保护车内用户信息安全的目的。但是该方案在高频添加的水印信息是固定的,很容易被破解,冒认者只需要截取一定数量的经过降噪前端添加水印之后的音频,通过分析频谱信息,很容易发现较为固定的编码规律,从而破解水印的编码,导致完全丧失了保护的意义。而且,在高频段添加单频信号,从某种角度而言,也影响音频的听感质量。
有鉴于此,本发明摒弃基于固定信息加密的思路,考虑采用多种动态信息进行联合加密,加密信息灵活多变,与现有方式相比明显具有更高的安全性。
结合具体实施例而言,本发明提供了一种车内交互音频加密方法的实施例,如图1所示,其可以包括如下步骤:
步骤s0、采集用户的交互音频,并进行前端降噪处理。
该过程属于常规的前端技术,是后续实现加密操作的基础,此处交互音频通常可以是指用户与车内主机等设备的人机交互语音,而具体如何采集以及如何降噪则不属于本发明的侧重点,实施本发明时可借鉴大量成熟的相关技术。
步骤s1、从交互音频以及交互场景中,获取到第一动态信息以及第二动态信息。
本发明为了提升加密安全性,考虑利用到至少两个维度的动态信息作为加密基础,一个是来自用户的交互音频,另一个则与交互场景——也即是车辆自身信息相关。因为此二者皆会在不同的应用环境中发生动态变化,不是一成不变的固定属性,例如不同用户的发音声学特征是有差异的,例如表征各自用户发音特点的声纹信息,当然还可以是利用交互音频并结合现有语音处理技术获得的用户年龄、性别等个性化信息;而且,车辆在运行状态下,其自身信息也会实时发生变化,例如所在位置、实时车速、胎压、油温、电池电量、用户对车内设备的设置参数等等,因而以上这些相对灵活的动态信息则是本发明所利用的对象,在实际操作中,可以根据特定需求,从用户和车辆两个维度选择不同的动态信息组合方案,例如但不限于在本发明的一些可能的实现方式中,所述第一动态信息可以是指用户个人信息,后文将以用户的声纹信息作为示意性介绍;所述第二动态信息可以是指车辆信息,优选包括如下一种或多种车辆信息:位置、车速、开窗状态、胎压以及乘员数量。
此外,对于上述动态信息的获取方式本身,本领域技术人员能够理解已有大量成熟技术可供选择,此非本发明重点,此处不做赘述。
步骤s11、将所述第一动态信息与所述第二动态信息融合,生成水印序列。
本发明提出,水印的生成需要结合上述两种动态信息,而非单单采用其中一种,这同样是为了提升加密可靠性。具体的水印生成方式,可以是将上述动态信息编码为特征序列,并将两种动态信息的特征进行融合,再映射成随机序列。后文将对具体的水印生成方式进行示例,此处暂不赘述。
步骤s2、对所述交互音频的进行转写。
此过程也可视为音频的前端处理,即在本地将交互音频识别为文本,目的是获得交互信息所含的具体内容。当然,语音识别方式本身也有大量成熟技术可供选用,此处不做赘述,但需强调的是,因为本发明的初衷是对无线传输前的交互音频进行在先加密,因此可以理解为,转写过程一般发生在本地,而非传到远端后再进行识别返回。
步骤s21、基于转写文本生成相位调制序列。
音频传输需要进行相位调制是常规的处理方式,但本发明这里需要强调的是,为了体现多动态信息的联合作用,在进行相位调整的阶段,本发明也提出利用动态信息的思路,也即是将用户的交互音频的具体内容视作一种动态信息,并将其融入到相位调制环节,后文将对此过程进行具体示意说明。
步骤s3、基于所述第一动态信息、所述第二动态信息以及所述转写文本,生成秘钥。
信息加密技术中运用秘钥也属于常规的处理方式,但本发明这里还需要强调的是,为了再次体现多动态信息的联合作用,在秘钥制作过程,本发明也考虑到再一次将多种动态信息进行结合,这里是将前述第一动态信息、第二动态信息以及转写文本一并考虑,后文将对此过程进行具体示意说明。
步骤s22、根据所述相位调制序列对所述交互音频进行相位调制。
后文将对相位调制过程进行具体说明。
步骤s12、将基于所述水印序列生成的水印嵌入到调制后的交互音频中,得到加密交互音频。
后文将对添加水印的环节进行具体说明。
由此,便得到具有高安全性的加密交互音频以及相应的秘钥,此处还需指出的是:其一、上述步骤次序不以序号限定,例如水印、秘钥等生成环节皆可以是同一阶段,当然秘钥生成也可以置于添加水印之后,并且水印生成与相位调制序列生成二者也可不分先后,对此本发明不做限定(除此之外,本发明所用“第一”“第二”等表述也不具有次序和等级意义,仅作表述区分之用)。其二、在得到加密音频以及秘钥后,还可以考虑将二者分配到不同的传输通道,也即是通过不同的通道向外部设备传输所述加密交互音频以及所述秘钥,这样的设计的目的同样是为了巩固安全性和可靠性,分开传输能够降低风险发生概率,使得未经授权的破解操作更难以实现。
关于生成相位调制序列的具体实施方式,可以参考如下:
交互音频信号经过前端降噪系统的处理后,送入本地的语音识别系统,语音识别的结果为音频的文本内容。为了表示和后续处理的方便,在实际操作中可以将其统一通过ucs-2编码成unicode码来表示。ucs-2编码是一种国际通用的unicode编码标准,包括了世界上绝大多数的文字和符号,包括中英文和数字。unicode码用两个字节表示一个字符,如汉字“经”的编码为0x7ecf,字母“a”的编码为0x0061。接续前文,将交互音频的具体内容编码为unicode编码之后,就可以将其表示成一串数字序列,记为:b={bi|0≤i<m}。其中,m表示交互音频的总字符数、0<bi<65536。当然,此处对文本编码以及具体编码为数字形式,属于可选可变的操作,在其他实施例中不做此限定。
而生成相位调制序列的过程,则可以基于此:首先将音频内容序列归一化,使其取值在(0,1),如公式(0.1)所示。然后分别以每个数字
其中,bi和
接着,可以依据既定策略将矩阵p所有列拼接成列向量
关于生成水印序列及生成水印的具体实施方式,可以参考如下:
基于前文,第一动态信息可以是指车内用户的声音特征i-vector,具体可以表示为车内特定用户的声纹特征,不同说话人的i-vector特征差异较大。因此,将交互音频的i-vector特征作为加密水印元素之一,具有很高的安全性。举例来说,假设i-vector特征维数为r×1,可记为:v={vi|0≤i<r}。提取i-vector特征的步骤属于现有技术,例如先提取plp特征,再结合预先训练的gmm模型计算0阶和1阶的统计量,从而求取出i-vector因子,对此本发明不做限定和赘述;而对于第二动态信息,同样也可以将采集到的诸如车辆位置信息、车速信息、是否开窗、车内人数等信息组合编码为car-vector特征,对此本发明不做限定和赘述。
而生成水印序列的过程,则可以基于此:首先将i-vector和car-vector特征序列拼接后进行归一化,使其取值在(0,1),如公式(0.3)所示。然后分别以每一维特征
s=[s1,s2,…,sr](0.4)
si=[si,0,si,1,si,2,…]t(0.5)
其中,
而水印生成过程可参考图2所示。其中,
关于相位调制过程的具体实施方式,可以参考如下:
利用前述生成的与音频内容相关的相位调制序列对交互音频的相位进行调制,因为不同音频频谱调制前后差异较大,所以具有更佳的加密性能。同时,在实际调制过程可以保证每帧音频之间的相对相位不变,不会影响听感质量。
而相位调制的过程,则可以参考:首先对输入的交互音频信号x(n)分帧,每帧信号做k点fft,得到频域信号
此过程并非重点,此处不再过多赘述。
关于添加水印的过程的具体实施方式,可以参考如下:
前述生成的水印序列,近似于白噪声,其不是单频信号,在各个频段上的功率是一样的,因此不影响听感。并且水印序列与交互音频相关,而且近似服从高斯分布,很难被破解,具有很高的加密安全性。此外,加密水印通过白噪声的形式嵌入到目标音频中,不易被发觉。将生成的类似白噪声的水印嵌入相位调制后的音频,得到输出信号y(n),如公式(0.8)所示:
最后,关于秘钥生成过程的具体实施方式,可以参考如下:
前述过程通过相位调制和添加水印,将交互音频以及场景信息融入到了交互音频之中。虽然此加密水印的嵌入方式已具由较高隐蔽性,但为了在接收后端能正确去除嵌入水印和解密,本发明还将交互音频的文本内容、前述i-vector特征和car-vector特征信息结合起来,生成单频秘钥。
而生成秘钥的过程,则可以基于此:首先将步骤1的前述音频文本unicode序列b={bi|0≤i<m}表示成四进制编码序列b={b′i|0≤i<m*8}。然后对第i,0≤i<m*8个四进制码元,按公式(0.9)生成单频信号ebi(n),其中,a为幅值,可取固定值;fb’i与b’i呈线性关系,即fb’i=kb’i。然后将i-vector和car-vector的拼接序列v={vi|0≤i<r}按相同步骤,得到单频信号evi(n)。最后,输出秘钥e(n)如公式(0.10)所示。
e(n)=ebi(k)+evi(k),n=i*w+k(0.10)
由此,便得到了采用独立通道向接收端传输的加密音频以及秘钥,基于前文各实施例及优选方案,此处对于接收端的处理再做介绍性说明:在接收端,可以先通过解析秘钥获得第一动态信息、第二动态信息以及交互内容,再反向去除交互音频中的水印并解调,最终得到干净的语音信号。
具体来说,在接收端,首先解析前述秘钥,得到交互音频文本序列和i-vector和car-vector拼接特征序列;然后基于前述生成相位调制序列以及生成水印序列的方式,从接收到的交互音频中去除水印并进行相位解调;最后将去除水印的音频信号按前述步骤,反向得到交互音频的转写文本和i-vector和car-vector拼接特征,并与解析秘钥后所得到的信息进行合法性判决。本领域技术人员可以理解的是,解密过程源于前述加密操作,而解密本身所涉及的处理环节便可相应逆向实施,此不属于本发明的侧重点。
综上所述,本发明摒弃固定信息加密思路,基于车内音频交互所涉及的多种动态信息并采取多环节联合应用的思路,提出了一种具有很高安全性、可靠性的交互音频加密方案。具体是从用户的交互音频以及交互场景中至少提取到两种不同维度的动态信息,并将多种动态信息相互融合用于生成水印,而又以与交互音频内容相关的转写文本作为另一种动态信息,用于对音频进行相位调制,除此之外,还考虑综合上述各种动态信息生成相应秘钥,并以独立的传输通道分别向外发送秘钥和加密音频,这样,基于上述种种安全措施的联合应用,可以有效保护车内用户的个人信息乃至隐私,与现有方式相比,大大增加了非授权破解的难度。
相应于上述各实施例及优选方案,本发明还提供了一种车内交互音频加密装置的实施例,如图3所示,具体可以包括如下部件:
交互音频前端处理模块0,用于采集用户的交互音频,并进行前端降噪处理;
动态信息获取模块1,用于从用户的交互音频以及交互场景中,获取到第一动态信息以及第二动态信息;
水印生成模块2,用于将所述第一动态信息与所述第二动态信息融合,生成水印序列;
相位调制序列生成模块3,用于基于所述交互音频的转写文本,生成相位调制序列;
秘钥生成模块4,用于基于所述第一动态信息、所述第二动态信息以及所述转写文本,生成秘钥;
相位调制模块5,用于根据所述相位调制序列对所述交互音频进行相位调制;
水印添加模块6,用于将基于所述水印序列生成的水印嵌入到调制后的交互音频中,得到加密交互音频;
在其他实施方式中,还可以进一步包括加密信息传输配置模块,用于将所述秘钥以及所述加密交互音频分别配置在不同的传输通道。
在其中至少一种可能的实现方式中,所述第一动态信息包括用户的声纹信息、年龄以及性别;所述第二动态信息包括如下一种或多种车辆信息:所在位置、车速、胎压、油温、电池电量、用户对车内设备的设置参数、开窗状态、胎压以及乘员数量。
在其中至少一种可能的实现方式中,所述水印生成模块包括:
特征拼接单元,用于将用户个人信息的特征向量与车辆信息的特征向量进行拼接,得到特征融合序列;
第一矩阵表示单元,用于分别以所述特征融合序列的每一维特征作为初始条件,生成近似服从高斯分布的第一随机矩阵;
水印获取单元,用于根据预设策略从所述第一随机矩阵中获取到所述水印序列。
在其中至少一种可能的实现方式中,所述相位调制序列生成模块包括:
编码单元,用于将所述转写文本编码表示为数字序列;
第二矩阵表示单元,用于分别以所述数字序列中每个数字作为初始条件,生成近似服从高斯分布的第二随机矩阵;
相位调制序列获取单元,用于根据预设策略从所述第二随机矩阵中获取到所述相位调制序列。
在其中至少一种可能的实现方式中,所述秘钥生成模块包括:
第一单频信号生成单元,用于将所述第一动态信息与所述第二动态信息融合,并根据预设策略生成第一单频信号;
第二单频信号生成单元,用于根据预设策略以及所述转写文本生成第二单频信号;
秘钥生成单元,用于将所述第一单频信号与所述第二单频信号再融合,得到所述秘钥。
应理解以上图3所示的车内交互音频加密装置中各个部件的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些部件可以全部以软件通过处理元件调用的形式实现;也可以全部以硬件的形式实现;还可以部分部件以软件通过处理元件调用的形式实现,部分部件通过硬件的形式实现。例如,某个上述模块可以为单独设立的处理元件,也可以集成在电子设备的某一个芯片中实现。其它部件的实现与之类似。此外这些部件全部或部分可以集成在一起,也可以独立实现。在实现过程中,上述方法的各步骤或以上各个部件可以通过处理器元件中的硬件的集成逻辑电路或者软件形式的指令完成。
例如,以上这些部件可以是被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(applicationspecificintegratedcircuit;以下简称:asic),或,一个或多个微处理器(digitalsingnalprocessor;以下简称:dsp),或,一个或者多个现场可编程门阵列(fieldprogrammablegatearray;以下简称:fpga)等。再如,这些部件可以集成在一起,以片上系统(system-on-a-chip;以下简称:soc)的形式实现。
综合上述各实施例及其优选方案,本领域技术人员可以理解的是,在实际操作中,本发明适用于多种实施方式,本发明以下述载体作为示意性说明:
(1)一种车内交互音频加密设备,其可以包括:
一个或多个处理器、存储器以及一个或多个计算机程序,其中所述一个或多个计算机程序被存储在所述存储器中,所述一个或多个计算机程序包括指令,当所述指令被所述设备执行时,使得所述设备执行前述实施例或等效实施方式的步骤/功能。
(2)一种可读存储介质,在可读存储介质上存储有计算机程序或上述装置,当计算机程序或上述装置被执行时,使得计算机执行前述实施例或等效实施方式的步骤/功能。
在本发明所提供的几个实施例中,任一功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的某些技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以如下所述软件产品的形式体现出来。
(3)一种计算机程序产品(该产品可以包括上述装置),该计算机程序产品在计算机设备上运行时,使设备执行前述实施例或等效实施方式的车内交互音频加密方法。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到上述实施方法中的全部或部分步骤可借助软件加必需的通用硬件平台的方式来实现。
再者,本发明实施例中,“至少一个”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示单独存在a、同时存在a和b、单独存在b的情况。其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项”及其类似表达,是指的这些项中的任意组合,包括单项或复数项的任意组合。例如,a,b和c中的至少一项可以表示:a,b,c,a和b,a和c,b和c或a和b和c,其中a,b,c可以是单个,也可以是多个。
本领域技术人员可以意识到,本说明书中公开的实施例中描述的各模块、单元及方法步骤,能够以电子硬件、计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方式来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
以及,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可。尤其,对于装置、设备等实施例而言,由于其基本相似于方法实施例,所以相关之处可参见方法实施例的部分说明即可。以上所描述的装置、设备等实施例仅仅是示意性的,其中作为分离部件说明的模块、单元等可以是或者也可以不是物理上分开的,即可以位于一个地方,或者也可以分布到多个地方,例如系统网络的节点上。具体可根据实际的需要选择其中的部分或者全部模块、单元来实现上述实施例方案的目的。本领域技术人员在不付出创造性劳动的情况下,即可以理解并实施。
以上依据图式所示的实施例详细说明了本发明的构造、特征及作用效果,但以上仅为本发明的较佳实施例,需要言明的是,上述实施例及其优选方式所涉及的技术特征,本领域技术人员可以在不脱离、不改变本发明的设计思路以及技术效果的前提下,合理地组合搭配成多种等效方案;因此,本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



