
 商标分类
商标分类  商标转让
商标转让 
一种语音识别引擎的准确度测试方法、装置、电子设备与流程
 2021-01-28 17:01:11|
2021-01-28 17:01:11| 417|
417| 起点商标网
起点商标网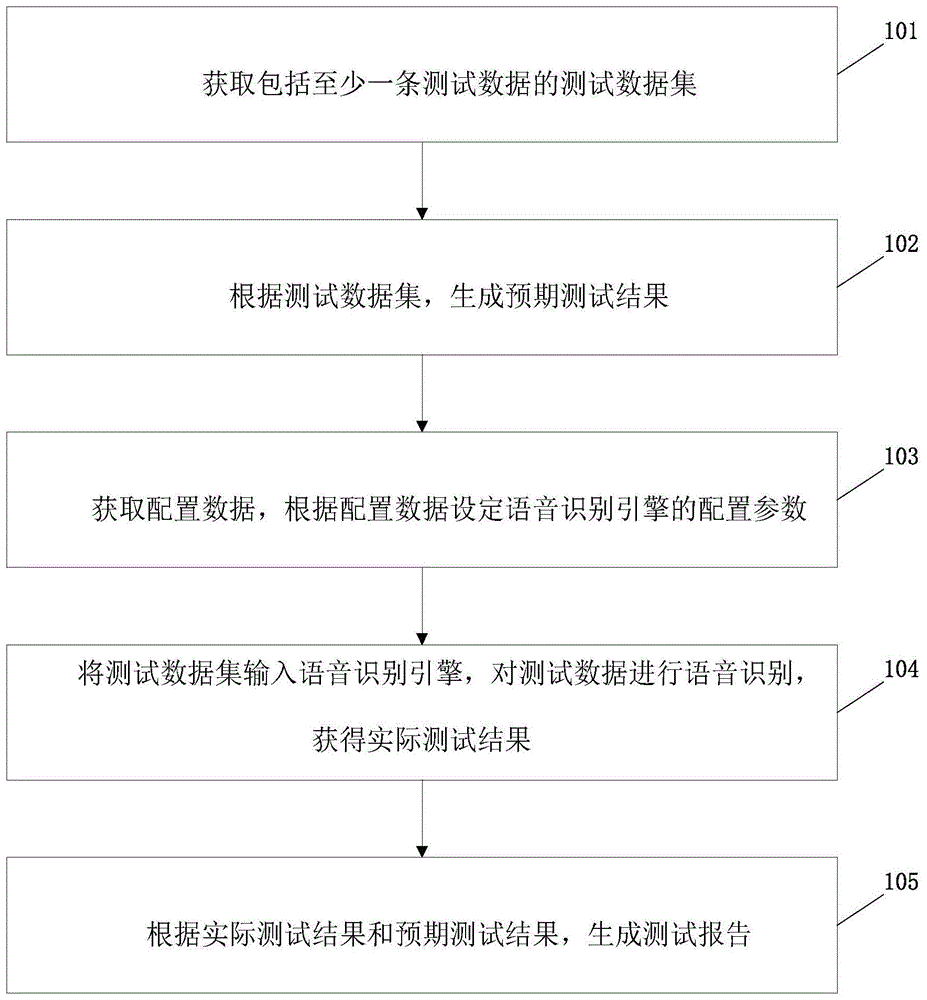
本发明涉及语音识别
技术领域:
,特别是指一种语音识别引擎的准确度测试方法、装置、电子设备。
背景技术:
:目前,随着语音识别技术的发展,越来越多的语音识别引擎被应用的到人们日常常用的电子设备中;现有的语音识别引擎能够对用户的语音进行语音识别和语义理解,并根据语音识别和语义理解结果控制电子设备相应执行预设的操作。但由于语音识别引擎的工作环境和涉及的软硬件结构均比较复杂,使用中会容易发生错误,影响准确度,故对于语音识别引擎需要进行定期的准确度测试。现有的对于语音识别引擎的准确度测试一般为人工检测,人工检测存在诸多的缺点,如测试过程不稳定、测试人员的发音不标准、测试人员的判断疏忽等,这些都会影响语音识别引擎的准确度测试结果的可靠性;另外,人工检测会耗费大量人力、效率低下、且成本较高。技术实现要素:有鉴于此,本发明的目的在于提出一种语音识别引擎的准确度测试方法、装置、电子设备,能够实现自动化的语音识别引擎的准确度测试,检测效率高、成本较低,且能够有效提高语音识别引擎的准确度测试结果可靠性。基于上述目的,本发明提供了一种语音识别引擎的准确度测试方法。一种语音识别引擎的准确度测试方法,包括:获取包括至少一条测试数据的测试数据集;根据所述测试数据集,生成预期测试结果;获取配置数据,根据所述配置数据设定语音识别引擎的配置参数;将所述测试数据集输入所述语音识别引擎,对所述测试数据进行语音识别,获得实际测试结果;根据所述实际测试结果和所述预期测试结果,生成测试报告。在本发明其他的一些实施方式中,所述测试数据为:在所述语音识别引擎的应用环境下采集的音频数据;当所述测试数据有至少两条时,至少两条所述测试数据均采集自同一声源。在本发明其他的一些实施方式中,所述获取包括至少一条测试数据的测试数据集,包括:调用预设的声纹模板,基于所述声纹模板,生成至少一条音频数据;获取所述至少一条音频数据作为所述至少一条测试数据。在本发明其他的一些实施方式中,所述根据所述配置数据设定语音识别引擎的配置参数,包括:解析所述配置数据,获得语种配置信息;根据所述语种配置信息,设定所述语音识别引擎所使用的语种;解析所述配置数据,获得工作模式配置信息;根据所述工作模式配置信息,设定所述语音识别引擎所在的工作模式,根据所述工作模式相应的调用预设的语音识别词库。在本发明其他的一些实施方式中,所述将所述测试数据集输入所述语音识别引擎,对所述测试数据进行语音识别,获得实际测试结果,包括:将所述测试数据集中的所述测试数据通过所述语音识别引擎的音频数据输入接口输入,并进行语音识别;记录所述测试数据的语音识别结果、语义识别结果、操作种类和操作参数;建立表格,将所述测试数据及其对应的所述语音识别结果、所述语义识别结果、所述操作种类和所述操作参数,分别以表格项的形式进行存储,以获得所述实际测试结果。在本发明其他的一些实施方式中,所述根据所述实际测试结果和所述预期测试结果,生成测试报告,包括:将所述实际测试结果和所述预期测试结果整合为一个表格;将所述实际测试结果和所述预期测试结果中相应的表格项进行比较,并生成比较结果;将比较结果为不相同的表格项进行突出标示。在本发明其他的一些实施方式中,所述的语音识别引擎的准确度测试方法还包括:将所述测试报告发送至预先关联的测试报告接收终端。在本发明其他的一些实施方式中,所述的语音识别引擎的准确度测试方法还包括:接收更新数据;根据所述更新数据,更新所述测试数据集和所述配置数据。基于同一发明构思,本发明还提供了一种语音识别引擎的准确测试装置。一种语音识别引擎的准确测试装置,包括:获取模块,用于获取包括至少一条测试数据的测试数据集;生成模块,用于根据所述测试数据集,生成预期测试结果;配置模块,用于获取配置数据,根据所述配置数据设定语音识别引擎的配置参数;测试模块,用于将所述测试数据集输入所述语音识别引擎,对所述测试数据进行语音识别,获得实际测试结果;结果处理模块,用于根据所述实际测试结果和所述预期测试结果,生成测试报告。基于同一发明构思,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任意一实施方式中所述的方法。从上面所述可以看出,本发明提供的语音识别引擎的准确度测试方法、装置、电子设备,通过生成的测试数据集来进行语音识别引擎的输入数据进行测试,避免了现有技术中人工测试带来的测试环境因素和人为主观因素的不良影响;同时,通过配置数据设定语音识别引擎的配置参数,以实现自动化的测试,最大程度的降低测试过程中的人为参与和干预,实现了自动化的语音识别引擎的准确度测试,检测效率高、成本较低,且能够有效提高语音识别引擎的准确度测试结果可靠性。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明一种语音识别引擎的准确度测试方法实施例的流程示意图;图2为本发明一种语音识别引擎的准确度测试方法另一实施例的流程示意图;图3为本发明一种语音识别引擎的准确度测试方法另一实施例的流程示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。传统的应用测试语音识别引擎的准确度的方法往往采用的是人工测试,此种测试方法虽说在一定程度上能够起到测试效果,但测试人员的主观因素在测试过程中会起到一定的干扰作用而使得测试结果不准。本发明所提供的方法、装置、电子设备,采用的是全自动化测试语音识别引擎的准确度,大大减小了因为测试人员的主观性而带来的测试误差,检测效率高、成本较低,且能够有效提高语音识别引擎的准确度测试结果可靠性。在本发明提供的一个实施例中,一种语音识别引擎的准确度测试方法,参考图1,包括:步骤101:获取包括至少一条测试数据的测试数据集;在本实施例中,根据测试需求,获取包括至少一条测试数据的测试数据集,其中,测试需求是指现有的需要语音识别引擎识别的某一规则或者用户需要语音识别引擎识别的某种需求,例如通过用户语音识别引擎识别:搜索某个地方,或者开启、关闭某一程序等需求。具体地,例如,测试需求为:搜索海淀区的海洋馆,与之相对应的生成包括至少一条测试数据的测试数据集可为:通过专业人员录制的音频文件“搜索海淀区的海洋馆”。在本实施例中,根据测试需求,通过直接采集已有的测试数据即可获取包括至少一条测试数据的测试数据集,此种获取测试数据集的方式较为方便、简洁,利用现有的测试数据即可完成测试数据集的获取。其中,测试数据为:在语音识别引擎的应用环境下采集的音频数据;当测试数据有至少两条时,至少两条测试数据均采集自同一声源。当然,在本发明其他的一些实施例中,至少两条测试数据也可采集来自于不同声源。在本实施例中,还可根据测试需求,先生成测试数据后获取包括至少一条测试数据的测试数据集,包括:调用预设的声纹模板,基于所述声纹模板,生成至少一条音频数据;获取所述至少一条音频数据作为所述至少一条测试数据。具体地,此种通过声纹模板生成至少一条音频数据是属于通过将测试需求输入至计算机等设备,计算机等设备控制带有声纹模板的装置以自动生成至少一条音频数据作为测试数据,上述生成测试数据方式属于全程包括测试数据集的生成均不需要人的参与、全自动化的过程。通过声纹模板自动生成测试数据的方式更进一步地实现了整个测试过程的自动化,且根据同一声纹模板生成的音频数据不会因为人的一些不稳定因素而受到一些不必要的干扰,检测效率高、成本较低。其中,声纹模板是通过提取特定用户的声纹特征,并能够基于该提取的声纹特征生成具有该声纹特征的音频数据的预设程序。声纹特征可通过本
技术领域:
内的常规算法对特定用户的声音进行分析而形成,本申请对此不予限定。此外,对于特定用户的选择,则是取决于本发明的测试方法所需语音的语种、音色等语音参数,本领域技术人员可以根据实施需要进行合理的设置和选择,本申请对此也同样不予限定。需要注意地是,在本发明其他的一些实施例中,测试数据集也可为满足测试需求而采用的专业人员录制的音频文件。具体的,专业人员录制的音频文件既可作为已有的测试数据也可作为当场生成的测试数据,其取决于具体地适用场景和人员配置等。其中,采用专业人员录制的音频文件,其不仅包括专业人员录制的含有测试需求的声音,还包括有属于周围环境所发出的背景音,能够更加真实的还原用户在具体使用环境下的声音,使得在实际环境中通过语音识别引擎的准确度更高。例如,专业人员会在车内录制需要导航去某个地方的音频文件,那么,音频文件中不仅会包括“导航去某某地方”的声音,还包括有车的引擎声等专属于环境的背景音。当然,通过声纹模板生成的音频数据或者通过专业人员录制的音频文件可保存至电脑等具有储存功能的器件中以供后面步骤使用。步骤102:根据测试数据集,生成预期测试结果;具体地,根据测试数据集,生成预期测试结果,其中,在本实施例中,根据测试数据集,得出的预期结果如表1所示:表1预期测试结果由表1可知,测试数据集音频文件1中,语音识别结果query为“把空调关闭”,其中,所对应的域domain为空调cns.air-control,语义识别结果为关闭close;测试数据集音频文件2中,语音识别结果query为“把播放器调节为摇滚模式”,其中,所对应的域domain为播放器cns.equalizer,语义识别结果为调节switch,参数为摇滚模式{'mode':['摇滚']};音频文件3等其他音频文件中的分析过程也是采用如上述所述的方法进行分析,在此不再赘述。步骤103:获取配置数据,根据配置数据设定语音识别引擎的配置参数;具体地,根据测试需求,确定配置数据,获取配置数据。其中,根据不同的测试需求,所确定、进而获取的配置数据也相应不同。配置数据可为包含语种、工作模式、音频种类等配置信息,获得相应的配置信息之后,即可设定语音识别引擎的相应的配置参数。配置参数即根据具体测试需求,语音识别引擎所对应使用的参数。在本实施例中,根据配置数据设定语音识别引擎的配置参数,包括:解析配置数据,获得语种配置信息;根据语种配置信息,设定语音识别引擎所使用的语种;其中,语种可为汉语、英语、德语等。例如,测试需求为上述的“把空调关闭”,则通过一系列识别之后,设定语音识别引擎所使用的语种即为汉语;测试需求为“turnofftheairconditioner”,通过一系列识别之后,设定语音引擎所使用的语种即为英语,其他语种的识别方式同于上述,在此不一一赘述。上述所述的设置方式能够根据识别不同的语种而使得语音识别引擎能够及时的反应更换为对应的语种,以使得语音识别引擎实现自动化测试。解析配置数据,获得工作模式配置信息;根据工作模式配置信息,设定语音识别引擎所在的工作模式,根据工作模式相应的调用预设的语音识别词库。其中,工作模式包括:离线(本地)模式和在线(服务器)模式。具体地,离线模式相应的调用预设的语音识别词库为本地词库,是指在测试语音识别引擎的设备中预先就有的词库,无需联网,依照该词库即可完成语音引擎的准确度测试,离线模式所提供的本地词库不会因其他原因而丢失词库信息,因而能够较为广泛地使用;在线模式相应的调用预设的语音是被词库为服务器词库,即在测试的过程中,能够通过联网而实时的获得互联网上所提供的一系列词库,所采用的语音识别词库较大且可以及时更新,当然,在在线模式中,也可同时采用本地词库以备不时之需。步骤104:将测试数据集输入语音识别引擎,对测试数据进行语音识别,获得实际测试结果;在本实施例中,将测试数据集输入语音识别引擎,对测试数据进行语音识别,获得实际测试结果,包括:将测试数据集中的测试数据通过语音识别引擎的音频数据输入接口输入,并进行语音识别;记录测试数据的语音识别结果、语义识别结果、操作种类和操作参数;建立表格,将测试数据及其对应的语音识别结果、语义识别结果、操作种类和操作参数,分别以表格项的形式进行存储,以获得实际测试结果。其中,所述建立的表格可以选用任何可视化表格生成软件完成,其目的是将实际测试结果(也同样适用于后述的预期测试结果、测试报告)以简单、直观的方式向用户展示,并实现方便的数据存储。本实施例中,以excel表格为例进行实施例的解释说明,显然,excel表格仅仅为一种可选的实施方式,其并不构成对建立的表格所选用的具体手段的限制。具体地,如下表2所示:表2实际测试结果与预期结果对比表其中,在本实施例中,如上表所示,实际测试结果录入文件即测试数据集为“关闭空调.wav”,语音识别结果为“打开风扇”,所在域为“cns.air-control”,语义识别结果为“open”,操作参数slot为{};预期结果录入文件即测试数据集为“关闭空调.wav”,语音识别结果为“关闭空调”,所在域为“cns.air-control”,语义识别结果为“close”,操作参数slot为{}。在本发明其他的一些实施例中,也是如上述所述建立excel表格,以excel表格项的形式进行存储,以获得实际测试结果。步骤105:根据实际测试结果和预期测试结果,生成测试报告。具体地,在本实施例中,根据实际测试结果和预期测试结果,生成测试报告,包括:将实际测试结果和预期测试结果整合为一个excel表格;将实际测试结果和预期测试结果中相应的excel表格项进行比较,并生成比较结果;将比较结果为不相同的excel表格项进行突出标示。具体地,如下表3所示:表3生成比较结果表由表3可知,在本实施例中,通过比较实际测试结果中相应的excel表格项与预期测试结果是否相同以判断语音识别、语义识别等是否错误,若实际测试结果中相应的excel表格项与预期测试结果均相同,则语音识别、语义识别均正确,语音识别引擎识别正确,否则,则语音识别引擎识别错误。具体地,在本实施例中,主要存在以下几种情形造成语音识别引擎错误:一是语音识别错误,语义识别正确,操作参数等正确;二是语音识别正确,语义识别错误,操作参数等正确;三是语音识别正确,语义识别正确,操作参数等错误。当然,也存在语音识别、语义识别、操作参数等中的两项及以上均识别错误而导致语音识别引擎识别错误。此外,在本发明又一实施例中,与本实施例相比,也可只生成比较结果表以供用户知晓,即在一些可选的实施方式中,实际测试结果和预期结果并不会以生成excel表格呈现,而是通过后台的电子设备等内部识别处理后进行结果比较以生成比较结果表即可,此种设置方式较为简单直观,有利于用户直接获取比较结果信息。当然,本实施例中的先生成实际测试结果和预期结果表格的对比表,后生成比较结构表的方式能够较为完整地向用户呈现了整个语音识别引擎的识别过程,能够让用户实时掌握语音识别引擎识别进程。上述两个实施例所提供的结果呈现方式不同,各自有着各自的优点,可根据具体适用场景、用户需求等情况而定。具体地,在得到上述测试报告后,将测试报告发送至预先关联的测试报告终端,并统计本次测试的准确率,如表4所示:表4测试准确率统计表totalpassfailerror526446800100%84.79%15.21%0.00%然后,将上述表4的统计结果汇总通过邮件等文件的形式发送给相关工程师,既保证了测试结果的可靠性,也实现了自动化测试语音引擎识别的准确率。在本发明一些较佳地实施例中,参考图2,还包括以下步骤:步骤106:将测试报告发送至预先关联的测试报告接收终端。具体地,在得到上述测试报告后,将测试报告发送至预先关联的测试报告终端,并存入相应的储存设备中,可供备份以及后期进行数据分析时使用。在本发明的一些较佳地实施例中,参考图3,还包括以下步骤:步骤107:接收更新数据;根据更新数据,更新测试数据集和配置数据。其中,本发明所提供的方法能够不止一次地进行测试,只要通过根据不同的测试需求、更新数据,获取对应的不同的测试数据集和配置参数,即可进行再次测试。值得注意地是,步骤106、步骤107均为本发明实施例中较佳地实施方式,对于本发明其他的实施例而言,也可不采用上述顺序或者必须步骤106、步骤107均有的实施方式,根据具体的应用场景以及工作人员配置而决定。基于同一发明构思,本发明还提供了一种语音识别引擎的准确度测试装置,包括:获取模块,用于获取包括至少一条测试数据的测试数据集;生成模块,用于根据测试数据集,生成预期测试结果;配置模块,用于获取配置数据,根据配置数据设定语音识别引擎的配置参数;测试模块,用于将测试数据集输入语音识别引擎,对测试数据进行语音识别,获得实际测试结果;结果处理模块,用于根据实际测试结果和预期测试结果,生成测试报告。基于同一发明构思,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行所述程序时实现如上述任意一实施方式中所述的方法。上述实施例的装置用于实现前述实施例中相应的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明的不同方面的许多其它变化,为了简明它们没有在细节中提供。另外,为简化说明和讨论,并且为了不会使本发明难以理解,在所提供的附图中可以示出或可以不示出与集成电路(ic)芯片和其它部件的公知的电源/接地连接。此外,可以以框图的形式示出装置,以便避免使本发明难以理解,并且这也考虑了以下事实,即关于这些框图装置的实施方式的细节是高度取决于将要实施本发明的平台的(即,这些细节应当完全处于本领域技术人员的理解范围内)。在阐述了具体细节(例如,电路)以描述本发明的示例性实施例的情况下,对本领域技术人员来说显而易见的是,可以在没有这些具体细节的情况下或者这些具体细节有变化的情况下实施本发明。因此,这些描述应被认为是说明性的而不是限制性的。尽管已经结合了本发明的具体实施例对本发明进行了描述,但是根据前面的描述,这些实施例的很多替换、修改和变型对本领域普通技术人员来说将是显而易见的。例如,其它存储器架构(例如,动态ram(dram))可以使用所讨论的实施例。本发明的实施例旨在涵盖落入所附权利要求的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips