
 商标分类
商标分类  商标转让
商标转让 
基于HMM和DNN的藏语语音识别方法与流程
 2021-01-28 17:01:10|
2021-01-28 17:01:10| 429|
429| 起点商标网
起点商标网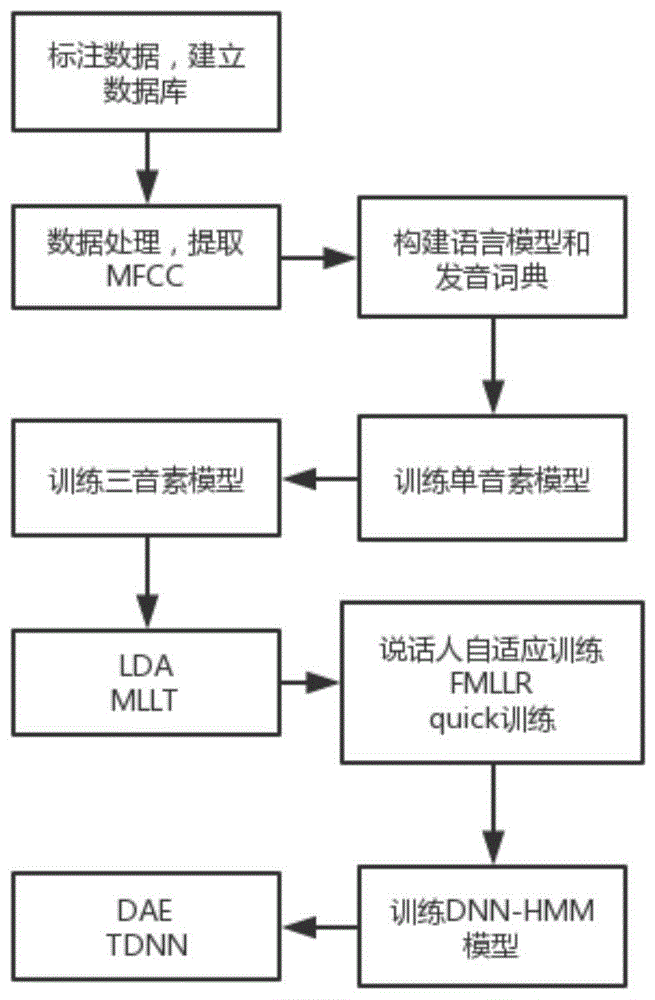
本发明涉及人工智能领域,尤其涉及一种用于低资源语料藏语的语音识别模型的训练方法及系统。
背景技术:
:在当今社会中,人工智能,虚拟现实,可穿戴设备等已经成为了科技行业研究的前沿和热点,而这些领域不可避免的需要人类与计算机进行交互,而语音识别技术无疑是人机交互中最便捷最直接的应用方式,语音识别技术就是让计算机理解人的语言并转化成等价的文字的过程。长期以来,语音识别领域声学模型的建模都是使用gmm-hmm模型(高斯-隐马尔科夫模型),该模型具有可靠的精度,并且有成熟的最大期望算法(em算法)来进行模型参数训练,因此gmm-hmm模型广泛应用在语音识别领域。但因为高斯混合模型(gmm模型)属于浅层模型,随着数据量的增加,建模能力明显不足。21世纪以来,语音识别领域最大的突破来自深度神经网络(dnn)概念的提出和应用,自2011年微软首次应用dnn在大规模语音识别任务中获得显著效果提升以来,dnn在语音识别领域受到越来越多的关注。在现在市面上常见的商用语音识别系统,dnn已经逐步取代了gmm进行声学模型建模,dnn因其更好的表征能力和学习能力克服了原有gmm模型的不足,现在已经成为各大互联网公司和科研机构研究的重点。基于目前的语音识别技术的研究,语音识别都是基于汉语,英语,法语等主流语言,而世界上有很多种小语种的语言,在现有的基础和低数据资源的情况下,如何实现小语种的语音识别是一件非常有意义的事。在我国有约700万藏族人民,主要分布在我国青海省、西藏自治区以及四川省西部,在当今时代,提高藏族人民人机交互的效率,让广大藏族人民享受到科技发展带来的便捷,成为一个重要的任务。然而当前市面上,并没有有效对藏语进行语音识别的系统。技术实现要素:为克服现有技术的不足,本发明旨在提出一种基于hmm-dnn(隐马尔科夫模型-深度神经网络)的藏语语音识别系统,将深度学习训练模型与藏语这种低资源语料结合,训练基于藏语的建立模型,对藏语语音进行识别,提高藏族人民人机交互的效率。为此,本发明采取的技术方案是,基于hmm和dnn的藏语语音识别方法,步骤如下:步骤1:录制藏语语音数据,并对录制的藏语语音数据进行标注,建立数据库;步骤2:进行数据准备,提取梅尔频率倒谱系数mfcc,以及进行倒谱均值方差归一化;步骤3:构建语言模型和发音字典步骤4:进行单音素模型的训练,并进行解码和对齐;为每一个音素建立模型,使用维特比训练对模型进行不断地更新,更新状态转移概率,用最大期望算法完成对高斯混合模型中参数的更新,完成单音素模型的训练;步骤5:训练三音子模型,并进行解码和对齐步骤6:进行线性判别分析和最大似然线性变换,并进行解码和对齐输入的数据集为:d=(x1,y1),(x2,y2),...,(xm,ym)其中x为n维向量,yi∈c1,c2,...,ck,希望降维到维数d,输出为样本为降维后的样本集;首先计算类内散度矩阵sw和类间散度矩阵sb,然后计算矩阵sw-1sb,再计算该矩阵的最大d个特征值和对应的d个特征向量(w1,w2,...,wd),得到投影矩阵,对样本集中的每一个样本特征xi转化为新的样本zi=wtxi,最后得到新的输出样本集d′=(z1,y1),(z2,y2),...,(zm,ym);然后对新的输出样本集d′进行最大似然线性变换,变换中每个高斯分量有两个方差矩阵:和hr,能够在多个高斯分量之间共享,最终的方差矩阵为:使用最大似然估计结合最大期望算法em求解对应的参数;用求解所得的新参数重新训练gmm,然后计算最大似然线性变换mllt的统计量,更新mllt矩阵t,更新模型的均值以及转换矩阵m←tm,m为lda变换矩阵,写入文件中;步骤7:进行说话人自适应训练、基于特征空间最大似然线性回归以及快速训练步骤8:训练隐马尔科夫模型-深度神经网络hmm-dnn模型,对语音数据添加噪声来得到有噪音的数据,并进行模型训练。步骤3:构建语言模型和发音字典具体步骤如下:语言模型表示某一字序列发生的概率,采用链式法则,把一个句子的概率拆解成器中的每个词的概率之积,句子w是由其分词w1,w2...wn组成的,则p(w)拆成:p(w)=p(w1)p(w2/w1)p(w3/w1,w2)...p(wn/w1,w2,..wn-1),每一项都是在之前所有词的概率条件下,当前词的概率。步骤(6)详述如下:首先引入瑞利商的概念:其中x为非零向量,而a为n*n的hermitan矩阵,而后推广到广义瑞利商:其中x为非零向量,而a,b为n*n的hermitan矩阵,b是正定的,将上式转化为其最大值就是矩阵的最大特征值,其最小值也对应该矩阵的最小特征值;对于数据集d=(x1,y1),(x2,y2),...,(xm,ym),其中任意样本xi为n维向量,yi∈c1,c2,...,ck,nj为第j类样本的个数,j=1,2,...,k,xj为第j类样本的结合,而uj为第j类样本的均值向量,是第j类样本的协方差矩阵;假设要投影到的低维空间维度为d,对应的基向量为(w1,w2,...,wd),基向量组成的矩阵为w,它是一个n*d的矩阵,那么优化目标为:lda多类优化目标函数为:这样j(w)的优化就变成:这样右侧就直接用广义瑞利商的性质求出最大的d个值,此时对应的矩阵w为这最大的d个特征值对应的特征向量张成的矩阵;假设输入的数据集为:d=(x1,y1),(x2,y2),...,(xm,ym)其中x为n维向量。yi∈c1,c2,...,ck,希望降维到维数d,输出为样本为降维后的样本集;首先计算类内散度矩阵sw和类间散度矩阵sb,然后计算矩阵sw-1sb,再计算该矩阵的最大d个特征值和对应的d个特征向量(w1,w2,...,wd),得到投影矩阵;对样本集中的每一个样本特征xi转化为新的样本zi=wtxi,最后得到新的输出样本集d′=(z1,y1),(z2,y2),...,(zm,ym);然后对新的输出样本集d′进行最大似然线性变换,每个高斯分量有两个方差矩阵:和hr,可以在多个高斯分量之间共享,最终的方差矩阵:使用最大似然估计结合em算法求解对应的参数。本发明的特点及有益效果是:本发明使用hmm-dnn实现了一种藏语言的语音识别系统,该系统经过数据测试,康巴藏族的藏语言语音识别的错误率低于19%,可以基本应用于康巴藏族的人机交互中,在安静状态下,能有效将康巴藏语语音转换为藏语文字,有效的提高了藏族人民人机交互的效率,是一套颇具实际应用价值的系统。附图说明:图1为系统构建流程图。图2为hmm-dnn模型图。具体实施方式基于hmm-dnn的藏语语音识别系统,他的构建包括如下几个步骤:步骤1:录制藏语语音数据,并对录制的藏语语音数据进行标注,建立数据库。步骤2:进行数据准备,整理训练模型需要的几个文件,提取mfcc,以及进行倒谱均值方差归一化。在一个语音识别系统中,第一步要做的就是特征提取.声音的音高等信息能体现一个人的语音特性.一个人的语音特性可以体现在声道的形状上,如果可以准确知道这个形状,那么我们就可以对产生的音素进行准确的描述.声道的形状在语音短时功率谱的包络中显示出来.而mfcc就是一种准确描述这个包络的一种特征.先对语音进行预加重、分帧和加窗处理;然后对每个短时窗进行分析,通过快速傅里叶变换得到相应的频谱;将该频谱通过mel(梅尔)滤波器组得到mel频谱;最后对mel频谱进行倒谱分析,这样就获得了梅尔mel频率倒谱系数mfcc,这个mfcc就是这帧语音的特征。步骤3:构建语言模型和发音字典。发音字典包含系统所能处理的单词的集合,并标明了其发音。通过发音字典得到声学模型的建模单元和语言模型建模单元间的映射关系,从而把声学模型和语言模型连接起来,组成一个搜索的状态空间用于解码器进行解码工作。语言模型表示某一字序列发生的概率,一般采用链式法则,把一个句子的概率拆解成器中的每个词的概率之积。设句子w是由其分词w1,w2...wn组成的,则p(w)可以拆成(由条件概率公式和乘法公式):p(w)=p(w1)p(w2/w1)p(w3/w1,w2)...p(wn/w1,w2,..wn-1),每一项都是在之前所有词的概率条件下,当前词的概率。由马尔卡夫模型的思想,最常见的做法就是用n-元文法,即假定某一个字的输出只与前面n-1个字出现的概率有关系,这种语言模型叫做n-gram模型。步骤4:进行单音素模型的训练,并进行解码和对齐。为每一个音素建立模型,使用viterbitraining(维特比训练)对模型进行不断地更新,更新状态转移概率,用em算法完成对gmm中参数的更新,完成单音素模型的训练。步骤5:训练三音子模型,并进行解码和对齐。单因素建模没有考虑协同发音效应,也就是上下文音素对当前中心音素发音有影响,会产生协同变化,这与该音素的单独发音会有所不同,为了考虑这个影响,需要使用三音素建模,使得模型描述更加精准。单音素复制为三音素后,状态的个数成指数增加,但复制后的状态。为了解决数据稀疏,而需要训练的数量庞大,因此需要降低参数的数量。聚类是为了降低所有三音素参数的数量,即降低三音素的状态的个数。决策树的作用就是给三音素的状态做聚类。聚类后,所有的三音素的状态被聚类为多个簇,为每个簇内的所有三音素状态进行绑定(即多个状态共享一个状态的参数)。步骤6:进行线性判别分析和最大似然线性变换,并进行解码和对齐。线性判别分析是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。线性判别分析的核心思想为投影后类内方差最小,类间的方差最大。简单来说就是同类的数据集聚集的紧一点,不同类的离得远一点。假设输入的数据集为:d=(x1,y1),(x2,y2),...,(xm,ym)其中x为n维向量。yi∈c1,c2,...,ck,希望降维到维数d,输出为样本为降维后的样本集。首先计算类内散度矩阵sw和类间散度矩阵sb,然后计算矩阵sw-1sb,再计算该矩阵的最大d个特征值和对应的d个特征向量(w1,w2,...,wd),得到投影矩阵。对样本集中的每一个样本特征xi转化为新的样本zi=wtxi,最后得到新的输出样本集d′=(z1,y1),(z2,y2),...,(zm,ym)。然后对新的输出样本集进行最大似然线性变换,它是一个平方特征变换矩阵,用于建模方差,解决完全协方差的参数量大的问题。相比于完全协方差,该方法的每个高斯分量有两个方差矩阵:和hr,可以在多个高斯分量之间共享,最终的方差矩阵为:使用最大似然估计结合em算法求解对应的参数。用所得的新参数重新训练gmm,然后计算mllt(最大似然线性变换)的统计量,更新mllt矩阵t,更新模型的均值以及转换矩阵m←tm,写入文件中。步骤7:进行说话人自适应训练、基于特征空间最大似然线性回归以及快速训练。说话人自适应技术是利用特定说话人数据对说话人无关(si)的码本进行改造,其目的是得到说话人自适应(sa)的码本来提升识别性能。快速训练用来在现有特征上训练模型,对于当前模型中在树构建之后的每个状态,它基于树统计中的计数的重叠判断的相似性来选择旧模型中最接近的状态。步骤8:训练hmm-dnn模型,对语音数据添加噪声来得到有噪音的数据,并进行模型训练。之前的语音识别框架都是基于gmm-hmm的,然而浅层的模型结构的建模能力有限,不能捕捉获取数据特征之间的高阶相关性。而hmm-dnn系统利用dnn很强的表现学习能力,再配合hmm的系列化建模能力,在很多大规模语音识别任务中都超过了gmm模型。通过对语音数据添加噪声来得到有噪音的数据,而后对其进行训练,训练细节和dnn部分一样。然后对数据通过延时神经网络进行训练。下面结合附图来描述本发明实施的基于hmm和dnn的藏语语音识别系统。该方法包含以下步骤:步骤1:录制藏语语音数据,并对录制的藏语语音数据进行标注,建立数据库。我们采用的数据库是在青海西宁录制了40个小时,共15000句的藏语语音数据,该数据库包含40名(男性22名,女性18名)康巴藏族志愿者的藏语语音数据,数据库各项信息如表1所示。数据库分为train、test、dev三部分。说话人数量男性女性句子数量共计时长train261412975026test64222506dev84430008共计4022181500040表1:数据库中各个部分数据情况步骤2:进行数据准备,整理训练模型需要的几个文件,提取mfcc,以及进行倒谱均值方差归一化。首先进行发数据处理,第一步对数据库进行处理,对于数据库的三个部分train、test、dev分别整理出模型训练需要的几个文件text、wav.scp、utt2spk、spk2utt。其中text保存语音数据对应的文本,wav.scp存放语音数据的绝对路径,utt2spk存放语音id到说话人编号的映射,spk2utt存放说话人编号到语音id的映射。接下来是提取mfcc特征,先对语音进行预加重、分帧和加窗处理;然后对每个短时窗进行分析,通过快速傅里叶变换得到相应的频谱;将该频谱通过mel滤波器组得到mel频谱;最后对mel频谱进行倒谱分析,这样就获得了mel频率倒谱系数mfcc,这个mfcc就是这帧语音的特征。提取得具体步骤为:(1)计算出一个文件中帧的数目(通常帧长25ms,帧移10ms)。(2)对每一帧提取数据,可选做抖动,预加重和去除直流偏移,还可以和加窗函数相乘。(3)计算该点能量(假如用对数能量则没有c0)。(4)做快速傅里叶变换(fft)并计算功率谱。(5)计算每个梅尔滤波器的能量,如23个部分重叠的三角滤波器,其中心在梅尔频域等间距。(6)计算对数能量作宇轩变换,根据要求保留系数。然后进行倒谱均值方差归一化(cmvn)处理,受不同麦克风及音频通道的影响,会导致相同音素的特征差别比较大,通过cmvn可以得到均值为0,方差为1的标准特征。均值方差可以以一段语音为单位计算,但更好的是在一个较大的数据及上进行计算,这样识别效果会更具有鲁棒性。步骤3:构建语言模型和发音字典。首先进入主目录并建立dict,lang,graph三个文件夹,然后将语音数据库中dict下的文件考到data/dict目录下,查找字典中不包含<s>和</s>字符的行并输入到lexicon.txt文件中。构建字典l.fst文件并解压语言模型,生成g.fst文件和并检查它是否包含空环。在构建过程中有以下几种输入文件:(1)lexicon.txt文件是字典文件,格式为wordphonephone2phonen$(2)lexiconp.txt是带概率的字典文件,概率值为每个词出现的概率,格式为:wordpron-probphone1,phone2phonen。(3)silence_phones.txt/nonsilence_phones.txt为静音/非静音音素,每一行代表一组相同的basephone,但可能有不同的声调的音素,如:aa1a2a3。(4)optional_silence.txt:包含一个单独的音素用来作为词典中默认的静音音素。(5)extra_questions.txt:用来构建决策树的问题集,可以是空的,包含多组相同的音素,每一组音素包含相同的重音或者声调;也有可能是一致表示非语音的静音/噪音音素。这可以用于增加自动生成问题的数量。首先将源文件夹下的音素映射到phones/下的对应文件,然后根据音素的位置来添加extraquestions,字典中的词可能会出现同个发音的情况,这里在同音词的发音标注后面加入消岐符来进行区分,字典中有多少同音词就会有多少个消岐符。然后为每个音素创建描述词边界信息的文件,创建词汇-符号表。这个表中的内容就是所有词汇和符号与数字的对应,创建align_lexicon.{txt,int}文件,大体操作为从lexiconp.txt中移除概率部分。创建不包含消岐符的的l.fst文件用于训练使用。将词典中的单词和音素转换成fst输入格式的文件。将各个文本转换成前面映射得到的数字表示,创建完整的l.fst文件。然后根据语言模型生成g.fst文件。方便与之前的l.fst结合,发挥fst的优势。语言模型表示某一字序列发生的概率,一般采用链式法则,把一个句子的概率拆解成器中的每个词的概率之积。设句子w是由其分词w1,w2...wn组成的,则p(w)可以拆成(由条件概率公式和乘法公式):p(w)=p(w1)p(w2/w1)p(w3/w1,w2)...p(wn/w1,w2,..wn-1),每一项都是在之前所有词的概率条件下,当前词的概率。由马尔卡夫模型的思想,最常见的做法就是用n-元文法,即假定某一个字的输出只与前面n-1个字出现的概率有关系,这种语言模型叫做n-gram模型。步骤4:进行单音素模型的训练,并进行解码和对齐。首先通过少量的数据快速得到一个初始化的hmm-gmm模型和决策树,结合每个音素所对应的hmm模型状态数以及初始时的转移概率,采用少量数据,计算这批数据的均值(means)和变化幅度(variance),作为初始高斯模型。用这个计算出来的means和variance进行初始化。获取当前高斯数,而后在incgauss计算:(目标高斯数-当前高斯数)/增加高斯迭代次数,得到每次迭代需要增加的高斯数目。构造训练的网络,每个句子构造一个音素级别的fst网络。对每个句子的单词级别进行标注,l.fst是字典对于的fst表示,作用是将一串的音素转换成单词。构造monophone(单一音素)解码图就是先将text中的每个句子,生成一个fst,然后和l.fst进行composition形成训练用的音素级别fst网络。使用key-value(键值对)的方式保存每个句子和其对应的fst网络,通过key就能找到这个句子的fst网络,value中保存的是句子中每两个音素之间互联的边,例如句子转换成音素后,标注为:”abcdef”,那么value中保存的其实是a->bb->cc->dd->ee->f这些连接,后面进行hmm训练的时候是根据这些连接的id进行计数,就可以得到转移概率。而后对训练数据进行初始对齐,对齐即将每一帧观察量与标注对齐。初始时采用均匀对齐,即根据标注量和观察量来进行均匀对齐,比如有100帧序列,5个标注,那么就是每个标注20帧,虽然这种初始化的对齐方式误差会很大,但在接下来的训练步骤中会不断的重新对齐的。对对齐后的数据进行训练,获得中间统计量,每个任务输出到一个.acc的文件中。acc文件中记录了与hmm和gmm相关的统计量。然后是解码过程:创建一个完全扩展的解码图(hclg.fst),该解码图表示语言模型、发音字典、上下文相关性和hmm结构。其程序流程为:(1)由l_disambig.fst文件和g.fst文件生成最新的lg.fst文件。(2)根据(1)中生成的lg.fst文件,以及disambig.int文件,生成最新的clg_1_0.fst文件和labels_1_0文件和disambig_ilabels_1_0.int文件。(3)根据文件tree和tree和model,生成最新的ha.fst文件。(4)生成最新的hclga.fst文件。(5)生成最新的hclg.fst文件。(6)检查hclg.fst文件是否为空。(7)通过调用gmm-latgen-faster过程或gmm-latgen-faster-parallel过程进行解码,生成lat.job.gz文件。(8)最后是对齐过程,这里使用的是强制对齐,用训练好的模型将数据进行强制对齐方便以后使用。步骤5:训练三音子模型,并进行解码和对齐。单因素建模没有考虑协同发音效应,也就是上下文音素对当前中心音素发音有影响,会产生协同变化,这与该音素的单独发音会有所不同,为了考虑这个影响,需要使用三音素建模,使得模型描述更加精准。首先为决策树的构建累积相关的统计量。打开声学模型,并从中读取transitionmodel模型,打开特征文件和对其文件,对每一句话的特征和对应的对齐状态,累积统计量tree_stats,将累积统计量转移到buildtreestatstype类型的变量stats中,将stats写到文件job.treeacc中。然后对多个音素或多个因素集进行聚类,从treeacc文件中读取统计量到buildtreestatstypestats;读取vectorpdf_class_list,该变量指定所考虑的hmm状态,默认为1,也就是只考虑三状态hmm的中间状态;从sets.int读取矢量到phone_sets文件;默认的三音素参数n=3,p=1,生成问题集到phone_sets_out文件,将生成的phone_sets_out写到questions.int。编译question得到question.qst文件,而后建立决策树tree,每个叶子节点的音素集实现状态绑定。三音素子模型的解码和对齐与步骤4中一致。步骤6:进行线性判别分析和最大似然线性变换,并进行解码和对齐。首先引入瑞利商的概念:其中x为非零向量,而a为n*n的hermitan矩阵。它有一个很重要的性质为它的最大值等于矩阵a最大的特征值,而最小值等于矩阵a的最小的特征值。而后推广到广义瑞利商:其中x为非零向量,而a,b为n*n的hermitan矩阵,b是正定的,我们可以将上式转化为这样我们就知道它的最大值就是矩阵的最大特征值,其最小值也对应该矩阵的最小特征值。假设我们的数据集为d=(x1,y1),(x2,y2),...,(xm,ym),其中任意样本xi为n维向量,yi∈c1,c2,...,ck,nj(j=1,2,...,k)为第j类样本的个数,xj(j=1,2,...,k)为第j类样本的结合,而uj(j=1,2,...,k)为第j类样本的均值向量,是第j类样本的协方差矩阵。假设我们要投影到的低维空间维度为d,对应的基向量为(w1,w2,...,wd),基向量组成的矩阵为w,它是一个n*d的矩阵。那么我们的优化目标为:但仔细观察公式发现分子和分母的结果都是矩阵,不是标量,无法作为一个标量函数来优化。一般来说,我们可以用其他的一些替代优化目标来实现。常见的一个lda多类优化目标函数为:这样j(w)的优化就变成:这样右侧就可以直接用广义瑞利商的性质求出最大的d个值,此时对应的矩阵w为这最大的d个特征值对应的特征向量张成的矩阵。假设输入的数据集为:d=(x1,y1),(x2,y2),...,(xm,ym)其中x为n维向量。yi∈c1,c2,...,ck,希望降维到维数d,输出为样本为降维后的样本集。首先计算类内散度矩阵sw和类间散度矩阵sb,然后计算矩阵sw-1sb,再计算该矩阵的最大d个特征值和对应的d个特征向量(w1,w2,...,wd),得到投影矩阵。对样本集中的每一个样本特征xi转化为新的样本zi=wtxi,最后得到新的输出样本集d′=(z1,y1),(z2,y2),...,(zm,ym)。然后对新的输出样本集d′进行最大似然线性变换,它是一个平方特征变换矩阵,用于建模方差,解决完全协方差的参数量大的问题。相比于完全协方差,该方法的每个高斯分量有两个方差矩阵:和hr,可以在多个高斯分量之间共享,最终的方差矩阵:使用最大似然估计结合em算法求解对应的参数。估计出lda变换矩阵m,特征经过lda变换,用转换后的特征重新训练gmm,然后计算mllt的统计量,更新mllt矩阵t,更新模型的均值以及转换矩阵m←tm,然后写入文件中;步骤7:进行说话人自适应训练、fmllr(基于特征空间的最大似然线性回归)以及快速训练。首先对特征进行fmllr,而后训练gmm模型,对自适应模型进行解码及测试,根据fmllr模型对数据进行对齐,可以看出核心任务是对特征码本做fmllr以达到说话人自适应的目的,然后进行快速训练,对快速训练得到的模型进行解码测试,然后采用快速训练得到的模型对数据进行对齐,最后对开发数据集进行对齐。步骤8:训练hmm-dnn模型,对语音数据添加噪声来得到有噪音的数据,并进行模型训练。之前的语音识别框架都是基于gmm-hmm的,然而浅层的模型结构的建模能力有限,不能捕捉获取数据特征之间的高阶相关性。而hmm-dnn系统利用dnn很强的表现学习能力,再配合hmm的系列化建模能力,在很多大规模语音识别任务中都超过了gmm模型。图给出一个hmm-dnn系统的结构图。在这个框架中,hmm用来描述语音信号的动态变化,用dnn的每个输出节点来估计连续密度hmm的某个状态的后验概率。hmm-dnn模型的主要训练步骤如下:(1)首先训练一个状态共享的三音素gmm-hmm汉语识别系统,使用决策树来决定如何共享状态。设训练完成的系统为gmm-hmm。(2)用步骤1得到的gmm-hmm初始化一个新隐马尔可夫模型(包括转移概率,观测概率,隐马尔可夫模型的状态),并生成一个hmm-dnn模型,设该模型为hmm-dnn1。(3)预训练hmm-dnn1系统中的深度神经网络,得到的深度神经网络为ptdnn。(4)使用gmm-hmm系统对语音训练数据作排列,得到的数据设为align-raw。(5)使用步骤4得到的数据对ptdnn的参数作微调。设得到的深度神经网络为dnn。(6)利用dnn与hmm-dnn1和最大似然算法重新估计隐马尔可夫中的参数(转移概率,观测概率),设新得到的系统为hmm-dnn2。(7)如果步骤6的精度不再提高则退出算法,否则使用dnn和hmm-dnn2产生新的语音训练数据的排列数据,然后回到步骤5。(8)利用训练数据估计概率p(qt)的值。通过对语音数据添加噪声来得到有噪音的数据,而后对其进行训练,训练细节和dnn部分一样。然后对数据通过延时神经网络进行训练。添加噪音进行训练的流程较为简单,和dnn训练模型基本一致,计算cmvn及统计量,将四种噪声加入原始数据上,提取fbank特征,计算cmvn及统计量,训练模型,解码测试。当前第1页1 2 3
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询




tips