
 商标分类
商标分类  商标转让
商标转让 
一种智能家居语音识别模型的生产方法与流程
 2021-01-28 17:01:41|
2021-01-28 17:01:41| 334|
334| 起点商标网
起点商标网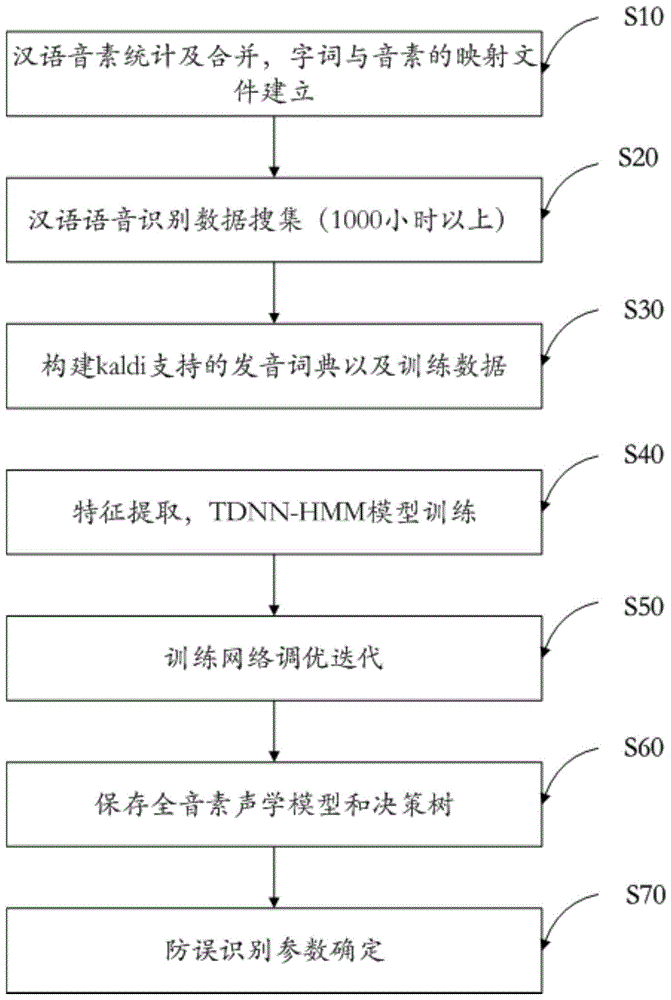
本发明涉及智能家居领域和语音识别技术领域,尤其涉及一种智能家居语音识别模型的生产方法。
背景技术:
随着人工智能技术的发展和人们生活水平的提高,智能家居产品渐渐走进了人们的生活。目前来说,智能家居产品智能化的主要途径就是语音识别能力。而语音识别能力的高低直接影响用户体验,从而决定该产品是否可用。
语音识别能力的高低是模型和解码器共同作用的结果,该模型是声学模型和解码图的总称。在不同的智能家居项目中,命令词是不同的,但解码器往往可以通用,而模型需要根据命令词重新生产,这个过程是复杂且耗时的。模型的生产流程包括但不限于数据采集、数据审核处理、语言和声学模型训练,模型测试,调参迭代。小型的智能家居语音识别系统一般要支持二十个左右的命令词,而一个支持二十个左右的命令词的语音识别模型生产周期至少需要两周,而这个生产周期的确定还是建立在语音识别技术掌握足够成熟,生产工具足够自动化的情况下的。这种模型生产方式是智能家居语音识别模型的主流生产方式。
经过分析,我们可以看出这种模型生产方式存在三点弊端:1,生产成本高。包括时间成本、金钱成本和人力成本。时间成本高,从客户确定命令词到产出语音识别模型至少两周的时间,时间过长,导致客户黏度降低。经济成本高,在模型的生产流程中需要数据采集,采集的是自然人的语音,在这个过程中要支付给被采集对象一定的经济报酬。人力成本高,数据审核需要人耳对每条音频数据进行审查检错,工作量大且耗时,需要多人同时进行。2,模型复用性太低。因为命令词的不同,导致要采集新的数据,每个新的智能家居语音识别项目都要重新生产模型。就针对当前项目,更麻烦的,客户如果想新加个别的命令词,那么要为该词采集数据、审核处理数据、模型重新训练并调试。只有当客户想删减命令词时,模型才可复用。因此,无论对当前项目还是以后项目,模型复用性都太低。3,数据利用率太低。每个智能家居项目都会采集不同的数据,现有的模型生产方式只利用当前项目的数据训练,无法利用其他数据对当前项目的模型进行性能增强,数据利用率太低。
技术实现要素:
本发明的主要目的在于提出一种智能家居语音识别模型的生产方法,能有效地解决目前智能家居语音识别模型的主流生产方式存在的三点弊端:生产成本高(时间成本,人力成本,经济成本)、模型复用性太低、数据利用率太低。
对于语音识别模型的生产方法,本发明提供了一种一劳永逸的方法:即前期通过一系列方法固定模型生产所需的数据文件,形成一个数据固定参数固定的生产系统。使用这个生产系统,每次只需根据所需命令词快速高效地生产出模型。此方法可在几秒之内产出模型,目前主流方法产出同样性能的模型至少需要两周。本发明的具体发明内容如下:
通过搜集海量数据,训练优化固定一个通用的汉语全音素声学模型,模型经过降维或压缩迭代后,体积和计算速度在嵌入式平台上的表现满足离线智能家居语音识别的性能要求。根据每个智能家居语音识别的命令词确定出所需识别的音素,该音素集合的种类个数一定小于或等于全音素模型所支持的音素种类个数。根据命令词和命令词的音素序列按一定规则构造填充词及其音素序列,生成发音词典,设置一定的命令词和填充词的比例生成语言模型,继而构造出解码图。即通过大数据训练一个全音素的声学模型,经工程实践调优,该声学模型在嵌入式系统中达到了计算速度和准确率的最佳平衡点。并且为该模型制定好平衡准确率和误识别的方案。固定这个声学模型,当新的语音识别命令词确定后,无需再采集数据、审核数据和训练调优声学模型,只需按制定好的方案自动构造出解码图即可。此时既完成了整个语音识别模型的生产流程。当新的语音识别命令词确定后,本发明的语音识别模型生产流程与目前主流的语音识别模型生产方式相比,省去了数据采集、数据审核以及声学模型训练调参迭代的流程,使得整个模型生产流程可以瞬间自动完成,完全无需人工干预。大大节约了时间成本、人力成本和金钱成本。另外,本发明的模型生产流程中的声学模型,由于是通过海量数据训练调优后的,数据量大使神经网络对每个音素的训练更加充分,声学模型的性能也要比目前只根据每个项目的命令词采集的数据训练出的声学模型性能更好,并且该声学模型可以无限复用智能家居的任何汉语语音识别项目。
为实现上述目的,本发明提供一种智能家居语音识别模型的生产方法,包括生产数据文件的固定、生产系统的搭建以及生产流程的介绍,包括以下步骤:
s1、汉语音素统计及合并,字词与音素的映射文件建立;
s2、汉语语音识别数据搜集;
s3、构建kaldi支持的发音词典以及训练数据;
s4、特征提取,tdnn-hmm模型训练;
s5、训练网络调优迭代;
s6、保存全音素声学模型和决策树;
s7、防误识别参数确定。
进一步地,步骤s1具体包括:
汉语全部音素确定,形成音素表,所述音素表是汉语所有字和词与自定义的音素的映射文件;根据智能家居语音识别的应用场景和人类发音特点,对相近音素进行合并,以提高声学模型的鲁棒性。
进一步地,步骤s2具体包括:
汉语开源语音数据搜集,可搜集到至少1000小时的音频数据。
进一步地,步骤s3、s4具体包括:
所述发音词典由所述确定和合并后的音素按kaldi的格式构造而成,并按kaldi的格式处理数据;
利用kaldi提取搜集来的大数据的mfcc特征,并搭建一个tdnn-hmm网络,训练所述的确定和合并后的音素。
进一步地,步骤s5、s6具体包括:
根据智能家居语音识别实际应用场景,设置合理的测试集,根据此测试集对步骤s4中的声学模型网络参数调优,寻求出在嵌入式系统中所述声学模型在准确率和计算速度之间的最佳平衡点;
保留所述全音素声学模型文件和决策树文件。
进一步地,步骤s7具体包括:
为所述声学模型寻找平衡准确率和误识率的方法,即根据命令词生成对应的填充词以及填充词的音素序列,并实验论证出最优词频参数。
进一步地,还包括步骤s8:
智能家居语音识别命令词导入,以确定此次生产出的模型需要识别哪些词;
根据这些命令词,在已准备的汉字字词与音素序列的映射文件中寻找每个命令词所对应的音素序列,保存成发音词典。
进一步地,还包括步骤s9:
对所述发音词典构造填充词及其音素序列;对命令词进行一定的处理形成相应的填充词,按同样的方式处理形成填充词的音素序列。
进一步地,还包括步骤s10:
词汇表,根据所述生产系统的命令词和填充词的词频参数,利用所述的命令词和填充词形成词汇表,并根据所述词汇表通过srilm生成一阶语言模型。
进一步地,还包括步骤s11:
导入本智能家居语音识别模型的生产系统中全音素声学模型及其决策树;
通过所述的生成或者导入的全音素声学模型、决策树、发音词典以及语言模型构建hclg解码图和解码图的词汇表。
本发明提供了一种一劳永逸的方法,即通过对音素处理、大量数据搜集以及训练网络优化等方法固定一个通用的全音素的声学模型和决策树,每次生产模型只需要提供命令词,无需再次采集处理数据训练声学模型,根据命令词自动构建解码图即可完成模型生产,并且该模型自动平衡好准确率与误识率的关系,生产过程只需几秒钟,大大缩短了模型生产周期。并且有效地解决目前智能家居语音识别模型的通用生产方式存在的生产成本高(时间成本,人力成本,经济成本)、模型复用性太低、数据利用率太低的问题。
附图说明
图1为本发明提供的一种智能家居语音识别模型的生产方法的生产数据文件的准备与生成的流程图;
图2为提供的一种智能家居语音识别模型的生产方法的基本应用的流程图;
图3为本发明实施例一提供的一种智能家居语音识别模型的生产方法的实施流程图;
图4为本发明实施例二提供的一种智能家居语音识别模型的生产方法的实施流程图;
图5为本发明提供的一种智能家居语音识别模型的生产方法的生产数据文件的准备与生成的流程图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
为实现上述目的,本发明提供的一种智能家居语音识别模型的生产方法,包括生产系统的搭建以及生产流程的介绍。如图1所示:生产系统的搭建工作包括如下:
s1、汉语音素统计及合并,字词与音素的映射文件建立;
s2、汉语语音识别数据搜集;
s3、构建kaldi支持的发音词典以及训练数据;
s4、特征提取,tdnn-hmm模型训练;
s5、训练网络调优迭代;
s6、保存全音素声学模型和决策树;
s7、防误识别参数确定。
汉语全部音素确定,形成音素表。根据智能家居语音识别的应用场景和人类发音特点,对相近音素进行合并,如前鼻音和后鼻音,以提高声学模型的鲁棒性。此音素表是汉语所有字和词与自定义的音素的映射文件。
汉语开源语音数据搜集,可搜集到至少1000小时以上的音频数据。
根据第一步确定和合并的音素按kaldi的格式构造发音字典,并按kaldi的格式处理数据。
利用kaldi提取搜集来的大数据的mfcc特征,并搭建一个tdnn-hmm网络,训练第一步确定和合并后的音素。
根据智能家居语音识别实际应用场景,设置合理的测试集,根据此测试集对上步的声学模型网络参数调优,寻求出在嵌入式系统中该声学模型在准确率跟计算速度下的最佳平衡点,保留该全音素声学模型文件和决策树文件。
为该声学模型寻找平衡准确率和误识率的方法,即根据命令词生成对应的填充词以及填充词的音素序列,并实验论证出最优词频参数。
如图2所示,当一个智能家居的语音识别项目的命令词确定后,本发明的语音识别模型的生产流程如下:
根据这些命令词,从上述生产系统的音素表中自动匹配出音素序列。
根据这些命令词,对命令词进行一定的处理形成相应的填充词,按同样的处理形成填充词的音素序列。
根据上述生产系统的命令词和填充词的词频参数,利用上步的命令词和填充词形成词汇表。并根据这个词汇表通过srilm生成一阶语言模型。
导入上述生产系统中全音素声学模型及其决策树。
通过全音素声学模型、决策树、发音词典以及语言模型构建hclg解码图及其所需的词汇表。
实施例一
本实施例简单介绍了,如何应用本发明为一个新的智能家居模块快速高效地生产出所需的语音识别模型以及形成完整的可交付的产品的过程,即从客户提供命令词开始至提供一个具有语音识别的智能家居产品为止。本实施例是本发明的应用过程,应用前提是上述模型生产所需原料是准备齐全的,并且生产系统是搭建完成的。
如图3所示,在本实施例中,一种智能家居语音识别模型的生产方法,包括:
s10、智能家居语音识别命令词导入,以告诉此次生产出的模型需要识别哪些词;
s20、根据这些命令词,在已准备的汉字字词与音素序列的映射文件中寻找每个命令词所对应的音素序列,保存成发音词典。
s30、对上步构建的发音词典,构造填充词及其音素序列。对命令词进行一定的处理形成相应的填充词,按同样的处理形成填充词的音素序列。
s40、根据本发明生产系统的命令词和填充词的词频参数,利用上步的命令词和填充词形成词汇表。并根据这个词汇表通过srilm生成一阶语言模型。
s50、导入本发明生产系统中全音素声学模型及其决策树。
s60、通过上述步骤中生成或者导入的全音素声学模型、决策树、发音词典以及语言模型构建hclg解码图和解码图的词汇表。
s70、使用全音素声学模型、解码图和解码图的词汇表对输入语音进行解码。
s80、对解码出的命令词进行命令词解析,转化成智能家居的操作指令,并进行语音播报。
实施例二
本实施例是本发明提供给智能家居产品的另一个应用场景与功能的体现。在智能家居产品的开发方与客户在早期的产品技术沟通中,有一个重要环节就是命令词的确定。由于人类的发音特点与语音识别技术的特点,命令词选择的好坏直接影响语音识别的准确率。比如两个字的命令词不仅识别率差而且误识率又高,人耳听觉不太响亮的音节组成的命令词识别率往往要低。所以,在前期的技术沟通中,研发人员一般会引导客户正确地选择命令词。
这个过程中,研发人员依据的是技术原理和开发经验,但客户如果对语音识别不太了解的话会对研发人员产生质疑,不太会相信命令词的选择会影响语音识别的准确率。这时候,本发明可以在现场提供一个快速、直观且具有说服力的实验:依据客户提出的几个命令词的备选方案,本发明瞬间生产出语音识别模型,此过程是全自动化的过程,在几秒之内就可以完成。完成后客户直接可以在现场进行人工测试与体验,在同样的现场环境下,对每个备选的命令词用大概相同的音量和相等的距离,至少朗读测试20遍就可以确定出哪个命令词好识别。比如某个指令客户计划采用的命令词为“关机”,而研发人员的建议是“关闭空调”,则本发明在现场可将这两个词当做待选命令词生产出语音识别模型,这个模型同时含有“关机”词条和“关闭空调”词条。正常情况下,客户只需经过短暂的测试与体验后,即可得出结论“关闭空调”比“关机”要好识别,继而有力地说服客户选择“关闭空调”作为该指令的命令词。
如图4所示,在本实施例中,一种智能家居语音识别模型的生产方法,包括:
s10、开发人员将本发明所述的模型生产系统和所需数据文件植入远程服务器或本地电脑,作为开发人员现场为客户生产模型的硬件和软件平台;
s20、在模型生产系统中录入命令词,以告诉此次生产出的模型需要识别哪些词;
s30、根据这些命令词,在已准备的汉字字词与音素序列的映射文件中寻找每个命令词所对应的音素序列,保存成发音词典。
s40、对上步构建的发音词典,构造填充词及其音素序列。对命令词进行一定的处理形成相应的填充词,按同样的处理形成填充词的音素序列。
s50、根据本发明生产系统的命令词和填充词的词频参数,利用上步的命令词和填充词形成词汇表。并根据这个词汇表通过srilm生成一阶语言模型。
s60、导入本发明生产系统中全音素声学模型及其决策树。
s70、通过上述步骤中生成或者导入的全音素声学模型、决策树、发音词典以及语言模型构建hclg解码图和解码图的词汇表。
s80、为录入的每个命令词tts合成相应的音频文件,方便客户测试与体验;
s90、使用全音素声学模型、解码图和解码图的词汇表对输入语音进行解码。客户用大概相同的音量和相等的距离,对待定的命令词测试体验,至少朗读测试20遍,记录准确率;
s100、对另一份命令词重复上述s20-s90的步骤,比较两个待定命令词的准确率,即可得出使用哪个命令词较易识别,从而确定使用哪个命令词。
本发明提供了一种一劳永逸的方法,即通过对音素处理、大量数据搜集以及训练网络优化等方法固定一个通用的全音素的声学模型和决策树,每次生产模型只需要提供命令词,无需再次采集处理数据训练声学模型,根据命令词自动构建解码图即可完成模型生产,并且该模型自动平衡好准确率与误识率的关系,生产过程只需几秒钟,大大缩短了模型生产周期。并且有效地解决目前智能家居语音识别模型的通用生产方式存在的生产成本高(时间成本,人力成本,经济成本)、模型复用性太低、数据利用率太低的问题。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



