
 商标分类
商标分类  商标转让
商标转让 
一种合成音乐的方法和装置与流程
 2021-01-28 17:01:26|
2021-01-28 17:01:26| 289|
289| 起点商标网
起点商标网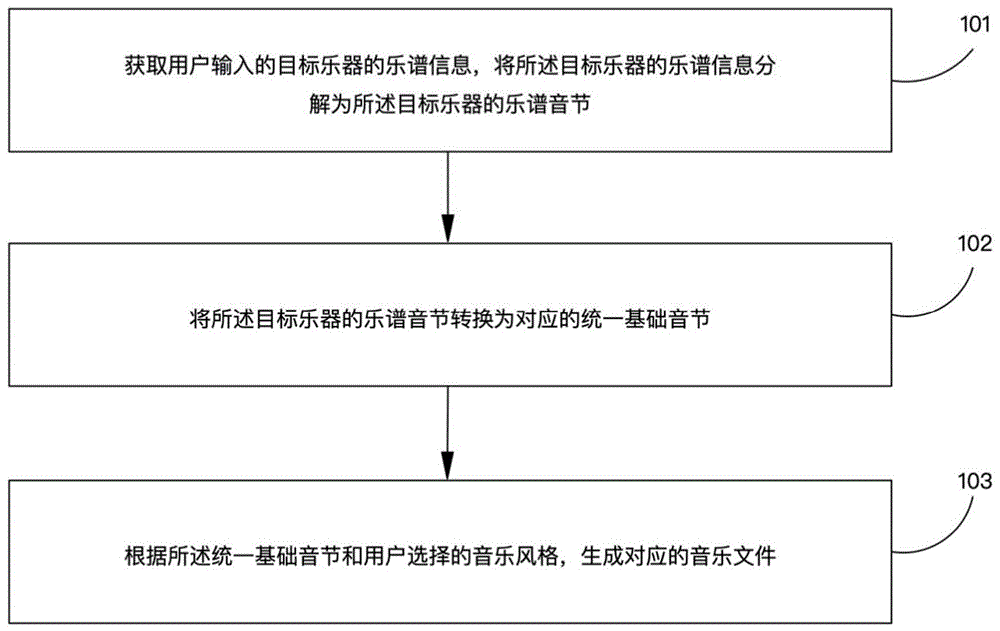
本发明涉及音频技术领域,特别涉及一种合成音乐的方法和装置。
背景技术:
tts(texttospeech,从文本到语音)技术是人机对话的一部分,是同时运用语言学和心理学的杰出之作,在内置芯片的支持之下,通过神经网络的设计,把文字智能地转化为自然语音流。tts技术对文本文件进行实时转换,转换时间之短可以秒计算。在其特有智能语音控制器作用下,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。tts技术即将覆盖国标一、二级汉字,具有英文接口,自动识别中、英文,支持中英文混读。所有声音采用真人普通话为标准发音,实现了120-150个汉字/分钟的快速语音合成,朗读速度达3-4个汉字/秒,使用户可以听到清晰悦耳的音质和连贯流畅的语调。tts技术作为语音合成应用的一种,能够将储存于电脑中的文件,如帮助文件或者网页,转换成自然语音输出。tts技术不仅能帮助有视觉障碍的人阅读计算机上的信息,更能增加文本文档的可读性。tts应用包括语音驱动的邮件以及声音敏感系统,并常与声音识别程序一起使用。
然而,现有的tts技术无法将乐谱信息转换为对应的音乐文件,无法满足用户制作音乐的需求。
技术实现要素:
本发明提供了一种合成音乐的方法和装置,以解决现有技术无法满足用户制作音乐的需求的缺陷。
本发明提供了一种合成音乐的方法,包括以下步骤:
获取用户输入的目标乐器的乐谱信息,将所述目标乐器的乐谱信息分解为所述目标乐器的乐谱音节;
将所述目标乐器的乐谱音节转换为对应的统一基础音节;
根据所述统一基础音节和用户选择的音乐风格,生成对应的音乐文件。
可选地,所述的方法,还包括:
生成统一基础音节对应关系表;
所述将所述目标乐器的乐谱音节转换为对应的统一基础音节,包括:
根据所述目标乐器的乐谱音节,查询所述统一基础音节对应关系表,得到与所述目标乐器的乐谱音节对应的统一基础音节;
其中,所述统一基础音节对应关系表包括多种乐器的所有乐谱音节与统一基础音节的对应关系,所述多种乐器包括目标乐器。
可选地,所述生成统一基础音节对应关系表,包括:
统计多种乐器的发音规则,画出梅尔频谱,并获取多种乐器的所有乐谱音节在梅尔频谱上的位置;
按照距离统计分布,对多种乐器的所有乐谱音节在梅尔频谱上的位置进行归类,将距离相近的乐谱音节归为同一类,并确定与同一类乐谱音节对应的统一基础音节;
根据多种乐器的所有乐谱音节与统一基础音节的对应关系,生成统一基础音节对应关系表。
可选地,所述的方法,还包括:
生成音乐风格模型;
所述根据所述统一基础音节和用户选择的音乐风格,生成对应的音乐文件,包括:
将所述统一基础音节和用户选择的音乐风格输入到所述音乐风格模型,获取所述音乐风格模型输出的音乐文件。
可选地,所述生成音乐风格模型,包括:
获取多个音乐人的音乐作品,对所述音乐作品进行风格分类;
将分类后的音乐作品作为训练数据,提取训练数据的音频特征,并将所述音频特征与统一基础音节形成对应关系;
基于所述对应关系进行机器学习训练,生成音乐风格模型。
本发明还提供了一种合成音乐的装置,包括:
获取模块,用于获取用户输入的目标乐器的乐谱信息,将所述目标乐器的乐谱信息分解为所述目标乐器的乐谱音节;
转换模块,用于将所述目标乐器的乐谱音节转换为对应的统一基础音节;
第一生成模块,用于根据所述统一基础音节和用户选择的音乐风格,生成对应的音乐文件。
可选地,所述的装置,还包括:
第二生成模块,用于生成统一基础音节对应关系表;
所述转换模块,具体用于根据所述目标乐器的乐谱音节,查询所述统一基础音节对应关系表,得到与所述目标乐器的乐谱音节对应的统一基础音节;
其中,所述统一基础音节对应关系表包括多种乐器的所有乐谱音节与统一基础音节的对应关系,所述多种乐器包括目标乐器。
可选地,所述第二生成模块,具体用于统计多种乐器的发音规则,画出梅尔频谱,并获取多种乐器的所有乐谱音节在梅尔频谱上的位置;按照距离统计分布,对多种乐器的所有乐谱音节在梅尔频谱上的位置进行归类,将距离相近的乐谱音节归为同一类,并确定与同一类乐谱音节对应的统一基础音节;根据多种乐器的所有乐谱音节与统一基础音节的对应关系,生成统一基础音节对应关系表。
可选地,所述的装置,还包括:
第三生成模块,用于生成音乐风格模型;
所述第一生成模块,具体用于将所述统一基础音节和用户选择的音乐风格输入到所述音乐风格模型,获取所述音乐风格模型输出的音乐文件。
可选地,所述第三生成模块,具体用于获取多个音乐人的音乐作品,对所述音乐作品进行风格分类;将分类后的音乐作品作为训练数据,提取训练数据的音频特征,并将所述音频特征与统一基础音节形成对应关系;基于所述对应关系进行机器学习训练,生成音乐风格模型。
本发明能够基于用户录入的乐谱信息(例如,古筝谱)以及选择的音乐风格(例如,郎朗风格),生成相应的音乐文件,帮助没有音乐基础的用户参与到音乐制作中,从而满足用户制作音乐的需求。
附图说明
图1为本发明实施例中的一种合成音乐的方法流程图;
图2为本发明实施例中的另一种合成音乐的方法流程图;
图3为本发明实施例中的一种合成音乐的装置结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种合成音乐的方法,如图1所示,包括以下步骤:
步骤101,获取用户输入的目标乐器的乐谱信息,将所述目标乐器的乐谱信息分解为所述目标乐器的乐谱音节;
其中,用户输入的目标乐器的乐谱信息可以为文字乐谱,也可以为图片乐谱。当用户输入文字乐谱时,可以直接将文字乐谱识别并分解为目标乐器的乐谱音节;当用户输入图片乐谱时,可以通过图像识别,生成目标乐器的乐谱音节。
例如,目标乐器可以是钢琴、古筝或笛子;乐谱信息可以是钢琴谱、古筝谱或笛谱,可以是宫商角徵羽,或者哆来咪发唆拉西哆等。
步骤102,将所述目标乐器的乐谱音节转换为对应的统一基础音节;
具体地,可以根据所述目标乐器的乐谱音节,查询统一基础音节对应关系表,得到与所述目标乐器的乐谱音节对应的统一基础音节;
其中,统一基础音节对应关系表包括多种乐器的所有乐谱音节与统一基础音节的对应关系,所述多种乐器包括目标乐器。
步骤103,根据所述统一基础音节和用户选择的音乐风格,生成对应的音乐文件。
具体地,可以将所述统一基础音节和用户选择的音乐风格输入到音乐风格模型,获取音乐风格模型输出的音乐文件。
其中,音乐文件可以是纯音乐文件。
本发明实施例能够基于用户录入的乐谱信息(例如,古筝谱)以及选择的音乐风格(例如,郎朗风格),生成相应的音乐文件(例如,郎朗风格的古筝曲),帮助没有音乐基础的用户参与到音乐制作中,从而满足用户制作音乐的需求。
本发明实施例提供了另一种合成音乐的方法,如图2所示,包括以下步骤:
步骤201,生成统一基础音节对应关系表;
具体地,可以统计多种乐器的发音规则,画出梅尔频谱,并获取多种乐器的所有乐谱音节在梅尔频谱上的位置;按照距离统计分布,对多种乐器的所有乐谱音节在梅尔频谱上的位置进行归类,将距离相近的乐谱音节归为同一类,并确定与同一类乐谱音节对应的统一基础音节;根据多种乐器的所有乐谱音节与统一基础音节的对应关系,生成统一基础音节对应关系表。
步骤202,生成音乐风格模型;
具体地,可以获取多个音乐人的音乐作品,对所述音乐作品进行风格分类;将分类后的音乐作品作为训练数据,提取训练数据的音频特征,并将所述音频特征与统一基础音节形成对应关系;基于所述对应关系进行机器学习训练,生成音乐风格模型。
其中,训练数据的音频特征可以是mfcc(mel-frequencycepstralcoefficients,梅尔频率倒谱系数)。梅尔频率是基于人耳听觉特性提出来的,与hz频率成非线性对应关系。mfcc则是利用梅尔频率与hz频率之间的对应关系,计算得到的hz频谱特征,主要用于语音数据特征提取和降低运算维度。例如:对于一帧有512维(采样点)数据,经过mfcc后可以提取出最重要的40维(一般而言)数据,同时也达到了将维的目的。mfcc一般会经过以下步骤:预加重,分帧,加窗,快速傅里叶变换(fft),梅尔滤波器组和离散余弦变换(dct)。其中,最重要的步骤是fft和梅尔滤波器组,这两个步骤进行了主要的降维操作。
本实施例中,基于音频特征与统一基础音节之间的对应关系,可以使用rnn(recurrentneuralnetwork,循环神经网络)进行机器学习训练,生成音乐风格模型。其中,循环神经网络是指一个随着时间的推移,重复发生的结构。在自然语言处理(nlp)和语音图像等多个领域均有非常广泛的应用。rnn网络和其他网络最大的不同就在于rnn能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。如同人类能够凭借自己过往的记忆更好地认识这个世界一样。rnn也实现了类似于人脑的这一机制,对所处理过的信息留存有一定的记忆,而不像其他类型的神经网络并不能对处理过的信息留存记忆。
步骤203,获取用户输入的目标乐器的乐谱信息,将所述目标乐器的乐谱信息分解为所述目标乐器的乐谱音节;
步骤204,根据所述目标乐器的乐谱音节,查询统一基础音节对应关系表,得到与所述目标乐器的乐谱音节对应的统一基础音节;
步骤205,将所述统一基础音节和用户选择的音乐风格输入到音乐风格模型,获取音乐风格模型输出的音乐文件;
步骤206,播放所述音乐文件。
本发明实施例生成统一基础音节对应关系表和音乐风格模型,能够基于统一基础音节对应关系表和音乐风格模型,以及用户录入的乐谱信息(例如,古筝谱)和音乐风格(例如,郎朗风格),生成相应的音乐文件,并将生成的音乐文件(例如,郎朗风格的古筝曲)播放给用户,帮助没有音乐基础的用户参与到音乐制作中,从而满足用户制作音乐以及播放音乐的需求。
本发明实施例还提供了一种合成音乐的装置,如图3所示,包括:
获取模块301,用于获取用户输入的目标乐器的乐谱信息,将所述目标乐器的乐谱信息分解为所述目标乐器的乐谱音节;
转换模块302,用于将所述目标乐器的乐谱音节转换为对应的统一基础音节;
第一生成模块303,用于根据所述统一基础音节和用户选择的音乐风格,生成对应的音乐文件;
播放模块304,用于播放所述音乐文件。
进一步地,上述装置,还包括:
第二生成模块,用于生成统一基础音节对应关系表;
相应地,上述转换模块302,具体用于根据所述目标乐器的乐谱音节,查询所述统一基础音节对应关系表,得到与所述目标乐器的乐谱音节对应的统一基础音节;
其中,所述统一基础音节对应关系表包括多种乐器的所有乐谱音节与统一基础音节的对应关系,所述多种乐器包括目标乐器。
具体地,上述第二生成模块,具体用于统计多种乐器的发音规则,画出梅尔频谱,并获取多种乐器的所有乐谱音节在梅尔频谱上的位置;按照距离统计分布,对多种乐器的所有乐谱音节在梅尔频谱上的位置进行归类,将距离相近的乐谱音节归为同一类,并确定与同一类乐谱音节对应的统一基础音节;根据多种乐器的所有乐谱音节与统一基础音节的对应关系,生成统一基础音节对应关系表。
进一步地,上述装置,还包括:
第三生成模块,用于生成音乐风格模型;
相应地,上述第一生成模块303,具体用于将所述统一基础音节和用户选择的音乐风格输入到所述音乐风格模型,获取所述音乐风格模型输出的音乐文件。
具体地,上述第三生成模块,具体用于获取多个音乐人的音乐作品,对所述音乐作品进行风格分类;将分类后的音乐作品作为训练数据,提取训练数据的音频特征,并将所述音频特征与统一基础音节形成对应关系;基于所述对应关系进行机器学习训练,生成音乐风格模型。
本发明实施例生成统一基础音节对应关系表和音乐风格模型,能够基于统一基础音节对应关系表和音乐风格模型,以及用户录入的乐谱信息(例如,古筝谱)和音乐风格(例如,郎朗风格),生成相应的音乐文件,并将生成的音乐文件(例如,郎朗风格的古筝曲)播放给用户,帮助没有音乐基础的用户参与到音乐制作中,从而满足用户制作音乐以及播放音乐的需求。
结合本文中所公开的实施例描述的方法中的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



