
 商标分类
商标分类  商标转让
商标转让 
一种基于深度神经网络的双视角单通道语音分离方法与流程
 2021-01-28 17:01:23|
2021-01-28 17:01:23| 310|
310| 起点商标网
起点商标网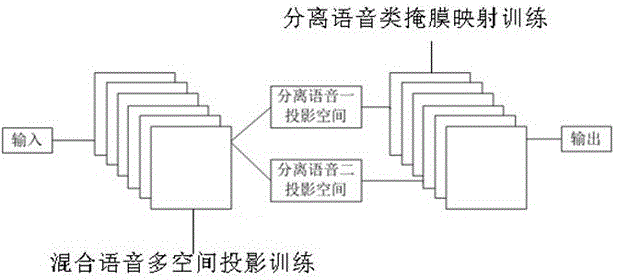
本发明涉及语音处理技术领域,更具体地说,涉及一种基于深度神经网络的双视角单通道语音分离方法。
背景技术:
语音分离在人机交互、公安侦听、军用通信等领域均有重要研究意义,如何将目标语音从这些复杂的场景中分离处理是应用中最大的挑战。同时语音的时频域特性动态变化且受干扰噪声影响存在复杂关系,这也是语音分离难以解决的主要原因。单通道语音分离作为其重要的一个分支受到了各领域研究者的关注,按其结合信息的方式可粗略分为无监督和有监督两类。
无监督方法有谱减法、维纳滤波及各种基于最优化准则的频域方法,这类方法主要思路在于估计噪声并抑制;另一方面,还有估计发声系统参数或分解语音信号空间的时域方法;除此之外,还有受视觉场景分析启发而设计的各种频域和时域结合的分离方法。
有监督方法主要有基于矩阵分类、隐马尔可夫和神经网络等的模型。该类方法主要思路在于利用信号的监督信息对各声源与混合语音建立各种模型,并采用训练好信号的最大后验概率等准则估计目标语音。同时,前期的基于神经网络的语音分离算法规模小、结构简单且缺少足够的训练数据,一定程度上限制了该类方法的拓展。
近年来,随着深度学习技术的兴起,该类方法不再受到各种假设的限制,能有效通过网络规模提升语音分离模型的泛化能力,但受到大规模场景的应用限制。
传统的无监督分离方法在信噪比较低的情况下参数难以估计,在不同空间上投影时对正交假设要求较高,因此无法有效估计。而且多为线性模型,不仅受容量限制,也无法挖掘输入对之间的复杂关系。而近年来的深度神经网络框架能解决上述问题,但仍然存在如下挑战:首先纯净语音和监督信息较难获取;其次学习过程中掩膜设计难度较大,需要大量数据,进一步限制了其在大规模数据集上的应用。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种基于深度神经网络的双视角单通道语音分离方法,能够解决传统基于神经网络的语音分离算法面临的两个问题:(1)纯净语音和监督信息难以获取;(2)复杂的掩膜设计流程;除此之外,也能在一定程度上缓减深度学习框架较高时间复杂度和参数爆炸及消失的困扰,以便扩展到大规模数据集上。
本发明解决其技术问题所采用的技术方案是:构造一种基于深度神经网络的双视角单通道语音分离方法,包括:
获取相关的语料库,包括单个纯净的说话人语音、多说话人的混合语音,并进行预处理;
对预处理后的语音数据进行混合语音多空间投影训练,实现对混合语音数据的投影分离;
对投影分离后的语音数据进行分离语音类掩膜映射训练,分离出两个说话人的语音数据。
其中,对初始语音数据进行预处理的步骤包括:
下载使用公认的公开混合语音或者纯净语音,检查语音数据的完整性,根据使用提示或者可考证文献的方法对数据进行清洗;
从不同的说话人中随机抽取2个说话人,并在对应的语料中随机抽取部分生成训练混合语音,剩余的作为测试混合语音,生成方式采用随机混合的方法,参考johnr.hershey提供的开源工具,混合语音数据的信噪比设定为-2.5到2.5db;
频域分离:对混合语音数据进行帧长为256、帧移为128的短时傅里叶变换,分析窗为汉宁窗,将短时傅里叶输出的绝对值作为混合语音数据的幅度谱;
时域分离:将混合语音数据划分为帧长为129的短信号。
其中,对预处理后的语音数据进行混合语音多空间投影训练的步骤包括:
使用公式(1)构建输入混合语音数据的稀疏网络,减少参数的相互依存关系,缓减过拟合,使用公式(2)编码非线性表达,避免前一层丢失过小的特征;
其中,公式(1)表示为:
y1=σ1(w1x+b1)(1)
式中,x表示混合语音信号,w1表示权重,b1表示偏置,σ1表示激活函数;y1为该层输出;
公式(2)表示为:
y2=σ2(w2y1+b2)(2)
式中,y1表示前一层输出,w2表示权重,b2表示偏置,σ2示激活函数,通过计算获取该层输出y2;
利用前一层输入,将投影空间分为两部分,从对应投影空间观察输入混合语音数据,利用投影空间的正交特性保证不同混合语音数据的可区分性;
处理两个说话人,则使用公式(3)、(4)进行处理:
y31=w3y2(3)
y32=(1-w))y2(4)
公式(3)和(4)中,w3表示输入混合语音数据的权重,确保不同的数据在不同空间表达不同,y31,y32分别表示区别化处理过程输出;
将不同空间表达的信号y31,y32输入网络:
s1=σ1(w41y31+b41)(5)
s2=σ1(w42y32+b42)(6)
公式(5)和(6)中,s1,s2分别表示说话人1和2的输出的投影分离后的语音数据,w41,w42表示不同投影空间的基向量组成的矩阵;
设计约束误差view1err并使其接近于0,使得不同说话人在不同的特征空间表达,其计算公式如下:
其中,对投影分离后的语音数据进行分离语音类掩膜映射训练,分离出两个说话人的语音数据包括步骤:
设计分离语音类掩膜映射器,确保有效增强目标语音并抑制干扰语音,其采用的类掩膜映射器设计如公式(8)所示:
公式(8)中,∈确保不能除0,t1,t2为类似标签信息的矩阵,确保某个时刻只有一个说话人的状态激活;
分离出的两个说话人语音分别为:
其中,分离出两个说话人的语音数据的步骤之后,还包括步骤:
由前述实例分离出的语音合并为新的混合语音,如公式(10)所示:
设y为输入混合语音,计算还原语音与原始混合语音之间的均方误差,优化器设置为如公式(11)所示:
统计混合语音分离结果的各项技术指标。
区别于现有技术,本发明的基于深度神经网络的双视角单通道语音分离方法,通过混合语音多空间投影,能有效利用语音信号在不同空间表达能力不同的特性,增强该语音信号的特征表达能力,在一定程度上提升说话人分离的性能,简单有效;通过分离语音类掩膜映射,有别于传统深度神经网络的框架,本发明能有效选择相应说话人的特征,达到传统掩膜的功能,提高深度学习框架的泛化能力,避免掩膜设计,且只需一个解码器,避免传统解码时多个解码器、多套参数学习引起的参数爆炸和参数消失问题。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的逻辑示意图。
图2是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的分离语音类掩膜映射训练第一步骤的示意图。
图3是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的分离语音类掩膜映射训练第二步骤的示意图。
图4是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的混合语音的频谱图。
图5是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的进行语音分离后的一部分语音频谱图。
图6是本发明提供的一种基于深度神经网络的双视角单通道语音分离方法的进行语音分离后的另一部分语音频谱图。。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
参阅图1,本发明提供了一种基于深度神经网络的双视角单通道语音分离方法,包括:
获取相关的语料库,包括单个纯净的说话人语音、多说话人的混合语音,并进行预处理;
对预处理后的语音数据进行混合语音多空间投影训练,实现对混合语音数据的投影分离;
对投影分离后的语音数据进行分离语音类掩膜映射训练,分离出两个说话人的语音数据。
其中,对初始语音数据进行预处理的步骤包括:
下载使用公认的公开混合语音或者纯净语音,检查语音数据的完整性,根据使用提示或者可考证文献的方法对数据进行清洗;
从不同的说话人中随机抽取2个说话人,并在对应的语料中随机抽取部分生成训练混合语音,剩余的作为测试混合语音,生成方式采用随机混合的方法,参考johnr.hershey提供的开源工具,混合语音数据的信噪比设定为-2.5到2.5db;
频域分离:对混合语音数据进行帧长为256、帧移为128的短时傅里叶变换,分析窗为汉宁窗,将短时傅里叶输出的绝对值作为混合语音数据的幅度谱;
时域分离:将混合语音数据划分为帧长为129的短信号。
其中,对预处理后的语音数据进行混合语音多空间投影训练的步骤包括:
使用公式(1)构建输入混合语音数据的稀疏网络,减少参数的相互依存关系,缓减过拟合,使用公式(2)编码非线性表达,避免前一层丢失过小的特征;
其中,公式(1)表示为:
y1=σ1(w1x+b1)(1)
式中,x表示混合语音信号,w1表示权重,b1表示偏置,σ1表示激活函数;y1为该层输出;
公式(2)表示为:
y2=σ2(w2y1+b2)(2)
式中,y1表示前一层输出,w2表示权重,b2表示偏置,σ2示激活函数,通过计算获取该层输出y2;
利用前一层输入,将投影空间分为两部分,从对应投影空间观察输入混合语音数据,利用投影空间的正交特性保证不同混合语音数据的可区分性;
处理两个说话人,则使用公式(3)、(4)进行处理:
y31=w3y2(3)
y32=(1-w3)y2(4)
公式(3)和(4)中,w3表示输入混合语音数据的权重,确保不同的数据在不同空间表达不同,y31,y32分别表示区别化处理过程输出;
将不同空间表达的信号y31,y32输入网络:
s1=σ1(w41y31+b41)(5)
s2=σ1(w42y32+b42)(6)
公式(5)和(6)中,s1,s2分别表示说话人1和2的输出的投影分离后的语音数据,w41,w42表示不同投影空间的基向量组成的矩阵;
设计约束误差view1err并使其接近于0,使得不同说话人具备不同的特征空间表达,其计算公式如下:
其中,对投影分离后的语音数据进行分离语音类掩膜映射训练,分离出两个说话人的语音数据包括步骤:
设计分离语音类掩膜映射器,确保有效增强目标语音并抑制干扰语音,其采用的类掩膜映射器设计如公式(8)所示:
公式(8)中,∈确保不能除0,t1,t2为类似标签信息的矩阵,确保某个时刻只有一个说话人的状态激活;
分离出的两个说话人语音分别为:
其中,分离出两个说话人的语音数据的步骤之后,还包括步骤:
由前述实例分离出的语音合并为新的混合语音,如公式(10)所示:
设y为输入混合语音,计算还原语音与原始混合语音之间的均方误差,优化器设置为如公式(11)所示:
统计混合语音分离结果的各项技术指标。
实施例1
(1)实验数据
以混合语音分离为例,对任意两个说话人的混合语音进行分离研究;研究数据来自语音技术研究中心cstrvctk的语料库,包括109名英语母语说话人使用不同口音所说的数据库,每个说话人朗读约400个句子,阅读内容为不同组的新闻语句,每组均通过贪心算法选择以最大化语境和语音覆盖。所有语音数据采用相同的语音设备采集,采样频率位24位96khz,并转换为16位,并采用stpk降采样到16khz;
(2)实验过程
按照图1所示的流程,采用如下步骤对109个说话人的混合语音进行分离:
步骤s1:获取语料库原始数据;
下载使用公认的公开混合语音或者纯净语音,检查语音数据的完整性,根据使用提示或者可考证文献的方法对数据进行清洗。
步骤s2:对语音原始数据进行预处理;
从cstrvctk语料库的109个说话人中随机抽取两个说话人,并随机抽取350个语句生成训练的混合语音,剩余的50条混合作为测试语音。混合语音的信噪比为-2.5--2.5db,生成方式采用johnr.hershey提供的开源工具;
当进行频域分离时,对信号进行帧长为256,帧移为128的短时傅里叶变换,分析窗为汉宁窗,将短时傅里叶输出的绝对值作为语音信号的幅度谱,以幅度谱作为网络的输入。当进行时域分离时,将信号划分为帧长129的短信号作为网络输入。
步骤s3:混合语音多空间投影训练;
首先使用公式(1)构建输入混合语音的稀疏网络,减少参数的相互依存关系,缓减过拟合,使用公式(2)编码非线性表达,避免前一层丢失过小的特征:
y1=σ1(w1x+b1)(1)
公式(1)中,表示混合语音信号,w1表示权重,b1表示偏置,σ1表示relu激活函数,通过计算获取该层输出y1;
y2=σ2(w2y1+b2(2)
公式(2)中,y1表示前一层输出,w2表示权重,b2表示偏置,σ2示sigmoid激活函数,通过计算获取该层输出y2;
其次利用前一层输入,将投影空间分为两部分,从对应投影空间观察输入信号,利用投影空间的正交特性保证不同信号的可区分性;
如果处理两个说话人,则使用公式(3)、(4)进行处理:
y31=w3y2(3)
y32=(1-w3)y2(4)
公式(3)和(4)中,w3表示输入信号的权重,确保不同的信号在不同空间表达不同,y31,y32分别表示区别化处理过程输出;
将不同空间表达的信号y31,y32输入网络:
s1=σ1(w41y31+b41)(5)
s2=σ1(w42y32+b42)(6)
公式(5)和(6)中,s1,s2分别表示说话人1和2的混合语音多空间投影训练模型输出,w41,w42表示不同投影空间的基向量组成的矩阵,本实施例设置为258,其它参数含义和前述公式相同;
最后,为了确保混合语音多空间投影训练的有效,设计约束误差view1err,使得不同说话人在不同的特征空间表达。如图4所示,其计算公式如下:
公式(7)中,需要保证该式尽可能接近0。
本实施例实验结果如表1所示,分别测试了1427步和50000步的结果。
表1view1err实验数据相同步数下对比,表格内数据为对应目标函数值
实验表明,该误差指标呈现单调递减下降趋势。为了验证整体有效性,两次实验采用了不同的随机种子,从表1中可以发现,随着测试步数的增加,该误差指标能有较大程度的下降,最低值达到了0.0205。充分表明了模型的有效性,保证了不同说话人在不同空间可分性能力;
步骤s4:分离语音类掩膜映射训练;
首先设计分离语音类掩膜映射器,如图2和图3中
公式(8)中,∈确保不能除0,本实施例中取∈=10e-11,t1,t2为类似标签信息的矩阵,确保某个时刻只有一个说话人的状态激活,本实施例中可以根据损失函数确定激活的说话人的矩阵元素设置为1,其它设置为0;
其次,此层分离出的两个说话人语音分别为:
公式(9)中注意对两个说话人的幅度谱均取绝对值;
初始语音频谱图如图4所示,分离后不同说话人的语音频谱图如图5和图6所示,本实施例实验结果如表2所示。
表2mask实验数据相同步数下对比,表格内数据为对应目标函数值
仍然随机两次实验,第一次执行1427步,第二次执行50000步。目标函数mask指标整体呈现小幅波动递减趋势,在前20步下降最快,在2425步之后基本处于平缓。但特别需要注意的是在第一次实验中,在440步的时候,该指标下降到14.26,为本次实验早期的极小值。而在第二次实验中,在1262步,达到了5.06,是早期极小值。尽管该指标后期仍然有小幅下降,如35000步的时候甚至降低到3.14,但该现象能为我们降低复杂度提供一定的指示作用。
步骤s5:合并分离语音,将还原语音与混合语音进行实验比对;
首先,由前述实例分离出的语音合并为新的混合语音,如下式所示:
其次,设y为输入混合语音,则可以计算还原语音与原始混合语音之间的均方误差。优化器设置为如下公式所示:
最后,统计混合语音分离结果的各项技术指标;
本实施例实验结果如表3和4所示,表3为本模型损失函数optimizer的性能曲线,与view1err指标出现类似的现象。表4为还原后语音与原始输入的混合语音之间的均方误差性能。
表3optimizer实验数据相同步数下对比,表格内数据为对应目标函数值
表4reconstructerror实验数据相同步数下对比,表格内数据为对应目标函数值
可以发现,本发明的方法能在一定程度上保证有效还原混合语音,在第1740步的时候,下降到了0.0215,还原混合语音的能力得到了有效的验证。同时,本实施例实验表明,上述各项指标在加权交叉验证的情况下能进一步以较少的循环次数获取相对较优的性能,有利于将本发明推广到大规模数据集上进行测试,具有较好的泛化能力。
实施例2
参数等设置方式同实施例1,针对传统基于神经网络的语音分离算法,本实施例测试如下两类:(1)比较混合语音和分离后语音频谱;(2)极小化与混合语音真实掩膜的最小均方误差;
首先观察频谱图,可以发现,本发明能有效将混合语音分离,分离后的语音听觉效果良好,频谱图清晰,能正确表示各自的特征,重构误差如表4所示;
其次以mse为目标时,采用测度为sdr、sir、stoi、pesq,其结果见下表:
根据以上实验结果,可以得出如下结论:
(1)相比于其它方法,在sdr上的指标性能基本持平;
(2)在sir指标上,性能分别提升了3;在stoi指标上,分别提升了0.21;在pesq上,性能提升了0.92,证明了本发明策略更具优势;
同时比对前述所有实施例的数据结果,证明本发明在单gpu电脑上运行复杂度相对传统深度框架有一定程度的下降,如果以并行方式处理,效果更佳;同时在各项数据指标性能上的提升,进一步验证了本发明算法较好的泛化能力。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



