
 商标分类
商标分类  商标转让
商标转让 
语音处理系统中的用户输入处理限制的制作方法
 2021-01-28 17:01:02|
2021-01-28 17:01:02| 324|
324| 起点商标网
起点商标网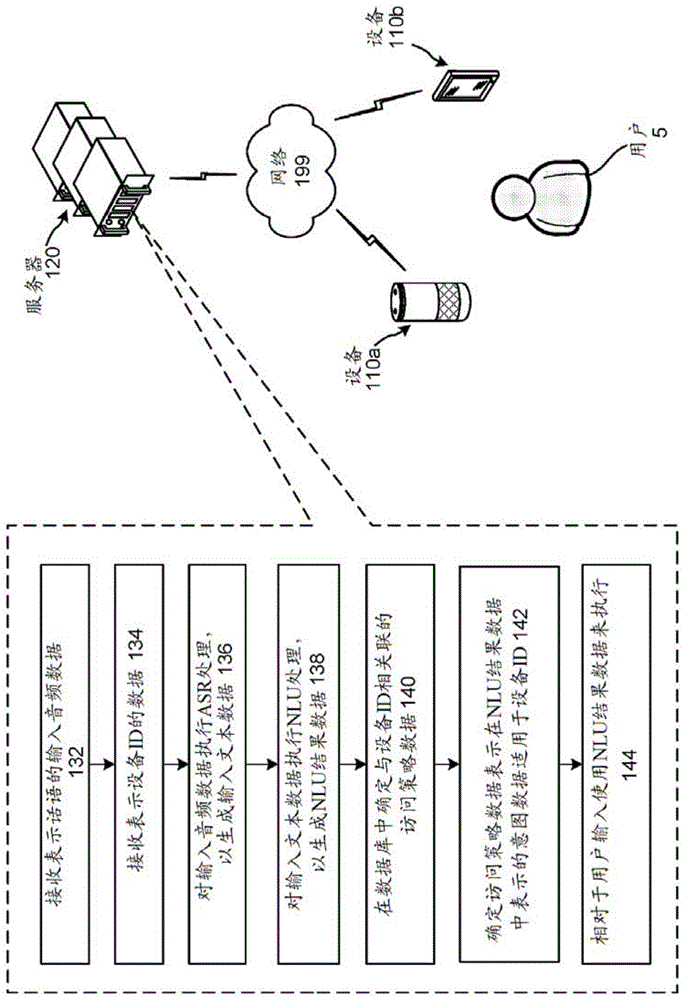
相关申请数据的交叉引用
该申请要求以yubao的名字于2018年1月31日提交的标题为“语音处理系统中的用户输入处理限制(userinputprocessingrestrictioninaspeechprocessingsystem)”的美国专利申请15/884,907的优先权。上述专利申请全文以引用方式并入本文。
背景技术:
语音辨识系统已经发展到人类可以用自己的声音与计算设备进行交互的程度。此类系统采用了基于各种质量的接收到的音频输入来识别由人类用户所说的字词的技术。语音辨识处理与自然语言理解处理的组合使得计算设备的基于语音的用户控制能够基于用户所说的命令执行任务。语音辨识处理和自然语言理解处理技术的组合在本文中被称为语音处理。语音处理还可以涉及将用户的语音转换成文本数据,所述文本数据之后可被提供给语音小程序(speechlet)。
语音处理可以由计算机、手持设备、电话计算机系统、信息亭和各种各样的其他设备使用以改善人机交互。
附图说明
为了更完全地理解本公开,现结合附图来参阅以下描述。
图1示出了根据本公开的实施例的配置有与儿童用户权限相关联的设备的系统。
图2示出了根据本公开的实施例的配置有儿童配置文件的系统。
图3是根据本公开的实施例的系统的部件的概念图。
图4是根据本公开的实施例的如何执行自然语言理解处理的概念图。
图5是根据本公开的实施例的如何执行自然语言理解处理的概念图。
图6是根据本公开的实施例的其中组合了传感器数据以辨识一个或多个用户的说明性架构的示意图。
图7是根据本公开的实施例的示出用户辨识处理的系统流程图。
图8是根据本公开的实施例的示出策略评估处理的系统流程图。
图9示出了根据本公开的实施例的由访问策略存储装置存储的访问策略数据。
图10示出了根据本公开的实施例的由访问策略存储装置存储的访问策略数据。
图11是根据本公开的实施例的示出后策略评估处理的系统流程图。
图12是根据本公开的实施例的概念性地示出设备的示例性部件的框图。
图13是根据本公开的实施例的概念性地示出服务器的示例性部件的框图。
图14示出了用于与语音处理系统一起使用的计算机网络的示例。
具体实施方式
自动语音辨识(asr)是涉及将表示语音的音频数据变换成表示该语音的文本数据的计算机科学、人工智能和语言学领域。自然语言理解(nlu)是涉及使计算机能够从包含自然语言的文本数据推导含义的计算机科学、人工智能和语言学领域。文本转语音(tts)是涉及使计算机能够输出合成语音的计算机科学、人工智能和语言学领域。asr、nlu和tts可以一起作为语音处理系统的一部分来使用。
语音处理系统正变得越来越普遍。语音处理系统可以包括使用户能够口头请求执行动作以及输出内容的语音用户界面(vui)。用户可以对着设备说话,该设备可以向分布式系统发送表示该话语的音频,并且该分布式系统可以处理该音频以确定响应(例如,用户请求的动作和/或内容)。例如,用户可以说“播放爵士乐”,则系统可确定用户想要输出爵士乐。又例如,用户可以说“给我叫辆车”,则系统可以确定用户希望预订车辆共乘行程。
由于此类系统变得更加稳健,因此越来越多类型的用户可以使用语音处理系统。例如,由于用于语音处理的设备变得越来越普遍,因此儿童可能成为这些设备的普通用户。
语音处理系统可以包括多种技能。每个技能可以被配置为执行各种动作和/或提供各种信息。例如,购物技能可以被配置为订购产品和/或服务,并且天气技能可以被配置为提供天气信息。对于一些语音处理系统,可以创建新的技能,因此越来越多的信息和动作不断地经由语音处理系统被提供给用户。
可能不希望允许所有用户在不受限制的情况下访问所有可能的响应,包括语音处理系统可以提供的所有动作和/或内容。例如,可能不希望儿童用语音处理系统购买产品或服务、用车辆共乘技能叫车、输出露骨的内容(例如,音乐或视频)等。
本公开利用语音处理系统的功能来过滤提供给用户(尤其是被确定为儿童的用户)的内容和/或动作。设备可以在设备识别符(id)级别被配置为“儿童设备”。因此,该设备可以与儿童相关联,并且至该设备的命令可以按与对于儿童来说安全和适用的命令相一致的方式被处理。例如,当用户(例如,成人用户或儿童用户)对着儿童设备说话时,该系统可以使用作为语音处理系统的一部分的asr和nlu技术来处理该话语,但对该话语的命令的最终执行可以包括基于调用的设备为儿童设备而确定儿童适用内容/动作。例如,如果用户对着儿童设备说“播放音乐”,则该系统可确定播放音乐的请求,确定该设备被指示为儿童设备,并且可以识别儿童适用音乐并输出儿童适用音乐。
除了包括儿童设备之外,系统还可并入有儿童配置文件。当用户对着设备说话时,该系统可以识别用户,确定用户的年龄(或年龄范围),并以确定适用于该用户年龄的内容/命令的方式执行该话语的命令。例如,如果用户对着未被配置为儿童设备的设备说“播放音乐”,则该系统可确定用户为儿童,确定儿童适用音乐并输出儿童适用音乐。
该系统可以被配置为使得儿童用户可能被限制调用某些技能。例如,该系统可以被配置为使得儿童用户可能能够调用音乐技能,但不能调用购物技能。
该系统还可以被配置为使得儿童用户可能被限制调用单个技能的某个功能。例如,该系统可配置有智能家居技能,并且儿童用户可能能够用智能家居技能开/关灯,但不能开门锁。
该系统可以包括统一施用于每个儿童用户和/或儿童设备的限制。此外,该系统可以包括专门针对特定儿童配置文件和/或设备的限制。这种专门的限制可以由与特定儿童用户相关联的成人用户生成(例如,父母为儿童设定权限)。不同的权限可以被配置用于不同的用户。例如,一个儿童用户可能能够调用比另一个儿童用户更多的智能家居技能功能。
图1示出了配置有儿童设备的系统。虽然附图和本公开的讨论以特定顺序示出了系统的某些操作步骤,但是在不脱离本公开的意图的情况下,可以以不同的顺序来执行所描述的步骤(以及移除或添加某些步骤)。在用户5本地的设备(110a/110b)和一个或多个服务器120可以跨一个或多个网络199通信。
用户5可以用自然语言对着设备110a说话(即,就像该用户在对着另一个人说话一样)。在该示例中的设备110a可以被认为是“儿童设备”。根据本公开,儿童设备可以呈可辨识为儿童设备的产品形式,或可以是“传统的”系统设备,但系统跟踪到该设备的id为儿童设备,使得使用本文公开的技术来执行从设备110a接收的命令。
设备110a可以生成表示话语的输入音频数据并将该输入音频数据发送到一个或多个服务器120,一个或多个服务器120接收(132)该输入音频数据。设备110a还可以将表示设备110a的设备识别符(id)的数据发送到一个或多个服务器120,一个或多个服务器120接收(134)该数据。一个或多个服务器120对输入音频数据执行(136)asr处理,以生成输入文本数据。
可替代地,用户5可以向设备110b提供文本输入(例如,经由虚拟或其他键盘)。输入文本数据可为自然语言(即,就像用户打字给另一个人一样)。在该示例中的设备110b可以被认为是“儿童设备”。设备110b可以呈可辨识为儿童设备(例如,面向儿童市场的平板计算机)的产品形式,或可以是“传统的”系统设备,但系统跟踪到该设备的id为儿童设备,使得使用本文公开的技术来执行从设备110b接收的命令。设备110b可生成表示输入文本的输入文本数据,并经由在设备110b上下载并由设备110b执行的伴随应用程序将该输入文本数据发送到一个或多个服务器120。
一个或多个服务器120对输入文本数据(例如,由asr处理生成或从设备110b接收)执行(138)nlu处理,以生成nlu结果数据。所述nlu结果数据包括表示话语或用户文本输入的推导意图的意图数据。例如,如果推导意图是要播放音乐,则意图数据可对应于<播放音乐>,如果推导意图为要预订车辆共乘行程,则意图数据可对应于<预订车辆>,等等。
一个或多个服务器120在存储访问策略数据的数据库中确定(140)与设备id相关联的访问策略数据,如果有的话。然后,一个或多个服务器120确定意图数据是否在与设备id相关联的访问策略数据中被表示。在访问策略数据中表示的意图数据可以对应于不适于该设备的用户调用的意图(例如,未授权儿童调用的意图)。如果一个或多个服务器120确定(142)访问策略数据表示意图数据(其表示当前用户输入)适用于设备id,则一个或多个服务器120相对于用户输入使用nlu结果数据来执行(144)。在一些情况下,相对于用户输入来执行可以包括执行动作(例如,预订车辆共乘交通工具、订匹萨、开灯、开门锁,等等)。在其他情况下,相对于用户输入来执行可以包括确定输出内容(例如,音乐、有声读物、食谱文本等)。
在步骤142中,一个或多个服务器120可确定访问策略数据表示意图数据以各种方式适用。如果访问策略数据对应于授权意图的白名单,则一个或多个服务器120可通过确定所述访问策略数据表示意图数据而确定意图数据是适用的。如果访问策略数据对应于未授权意图的黑名单,则一个或多个服务器120可通过确定所述访问策略不表示意图数据而确定意图数据是适用的。
如上所述,一个或多个服务器120可以从设备110接收设备id并可以确定与设备id相关联的一个或多个访问策略。可替代地,一个或多个服务器120可从设备110接收表示设备id的数据,确定该数据与数据库中的设备id相关联,然后确定与该设备id相关联的一个或多个访问策略。此外,一个或多个服务器120可以接收表示设备110的类型的数据,并确定与设备110的类型相关联的一个或多个访问策略。此外,一个或多个服务器120可从设备110接收表示设备id的数据,确定该设备id与数据库中的设备类型id相关联,然后确定与该设备类型id相关联的一个或多个访问策略。如果所存储访问策略中的一些或全部与设备类型而不是特定设备id相关联,则访问策略的存储要求可降低。
如相对于图1所述,一种系统可配置有儿童设备和相关联的儿童设备访问策略,使得使用儿童设备与系统交互的用户将被限制接收某些内容和/或调用某些动作。图2示出了配置有儿童配置文件的系统,使得该系统的特定用户将被限制接收某些内容和/或调用某些动作(而不管与用户交互的设备110如何)。
一个或多个服务器120可接收(132)表示用户5的所说话语的输入音频数据,并且可以对输入音频数据执行(136)asr处理以生成输入文本数据。可替代地,一个或多个服务器120可经由伴随应用程序从设备110b接收输入文本数据。一个或多个服务器对输入文本数据(例如,通过asr处理生成或从设备110b接收)执行(138)nlu处理,以生成nlu结果数据。如上所述,所述nlu结果数据包括表示话语或用户文本输入的推导意图的意图数据。
一个或多个服务器120确定(232)用户5的用户识别符(id)。如果一个或多个服务器120接收到表示话语的输入音频数据,则一个或多个服务器120可确定表示该话语的音频特性并可以将该音频特性与系统的各个用户的所存储音频特性进行比较以识别用户的所存储音频特性。所存储音频特性可以与各自的用户id相关联。用于确定用户5的身份和对应用户id的其他技术在下文被详细描述。
一个或多个服务器120在存储访问策略数据的数据库中确定(234)与用户id相关联的访问策略数据,如果有的话。然后,一个或多个服务器120确定意图数据(在nlu结果数据中表示)是否在与该用户id相关联的访问策略数据中被表示。如果一个或多个服务器120确定(236)访问策略数据表示意图数据(其表示当前用户输入)适用于用户id,则一个或多个服务器120相对于用户输入使用nlu结果数据来执行(144)。
该系统可使用如图3中所述的各种部件进行操作。各种部件可位于相同或不同的物理设备上。各种部件之间的通信可以直接或跨一个或多个网络199发生。
设备110a可以向一个或多个服务器120发送输入音频数据311。在被一个或多个服务器120接收到后,输入音频数据311可被发送到协调器(orchestrator)部件330。协调器部件330可以包括存储器和逻辑,所述逻辑使得协调器部件330能够向系统的各个部件传输各种数据片和数据形式,以及执行如本文中所述的其他操作。
协调器部件330向语音处理部件340发送输入音频数据311。语音处理部件340的asr部件350将输入音频数据311转录为输入文本数据。由asr部件350输出的输入文本数据表示一个或多于一个(例如,呈n-最佳(n-best)列表形式)假设(hypotheses),该一个或多于一个假设表示在输入音频数据311中表示的话语。asr部件350基于输入音频数据311与预建立的语言模型之间的相似度来解译输入音频数据311中的话语。例如,asr部件350可以将输入音频数据311与声音模型(例如,子词单位,诸如音素等)和声音序列进行比较,以识别与输入音频数据311中表示的话语的声音序列匹配的字词。asr部件350向语音处理部件340的nlu部件360发送由其生成的输入文本数据。从asr部件350发送到nlu部件360的输入文本数据可以包括得分最高的假设,或可以包括具有多个假设的n-最佳列表。n-最佳列表可以另外包括与其中表示的每个假设相关联的相应得分。每个得分可以指示被执行以生成与该得分相关联的假设的asr处理的置信度。
可替代地,设备110b可以向一个或多个服务器120发送输入文本数据313。在被一个或多个服务器120接收到后,输入文本数据313可被发送到协调器部件330。协调器部件430可以将输入文本数据313发送到nlu部件360。
nlu部件360试图对输入其中的输入文本数据中表示的短语或语句进行语义解译。即,nlu部件360基于输入文本数据中表示的字词来确定与输入文本数据中表示的短语或语句相关联的一个或多个含义。nlu部件360确定表示用户希望执行的动作的意图以及允许设备(例如,设备110a、设备110b、一个或多个服务器120、语音小程序390、一个或多个语音小程序服务器325等)执行该意图的输入文本数据片。例如,如果输入文本数据对应于“播放adele的音乐”,则nlu部件360可确定系统输出adele的音乐的意图并且可以将“adele”识别为艺术家。又例如,如果输入文本数据对应于“天气如何”,则nlu部件360可确定系统输出与设备110的地理位置相关联的天气信息的意图。
“语音小程序”可为在一个或多个服务器120上运行的软件,其类似于在传统计算设备上运行的软件应用程序。即,语音小程序390可以使一个或多个服务器120能够执行特定功能,以提供数据或产生一些其他所请求的输出。一个或多个服务器120可配置有多于一个的语音小程序390。例如,天气服务语音小程序可以使一个或多个服务器120能够提供天气信息,汽车服务语音小程序可以使一个或多个服务器120能够预订关于出租车或车辆共乘服务的行程,订披萨语音小程序可以使一个或多个服务器120能够相对于餐厅的在线订购系统订披萨,通信语音小程序可以使系统能够执行消息收发或多端点通信等。语音小程序390可在一个或多个服务器120与其他设备(诸如本地设备110)之间协同操作以完成某些功能。至语音小程序390的输入可来自语音处理交互或通过其他交互或输入源而来。
语音小程序390可以包括可专用于特定语音小程序390或可在不同语音小程序390之间共享的硬件、软件、固件等。语音小程序390可以是一个或多个服务器120的一部分(如图3所示),或者可以整个(或部分)位于单独的语音小程序服务器325内。一个或多个语音小程序服务器325可与一个或多个服务器120内的语音小程序390通信和/或直接与协调器部件330或与其他部件通信。除非另有明确说明,否则对语音小程序、语音小程序设备或语音小程序部件的引用可以包括在一个或多个服务器120内操作的语音小程序部件(例如,作为语音小程序390)和/或在一个或多个语音小程序服务器325内操作的语音小程序部件。
语音小程序390可以被配置为执行一个或多个动作。执行这样的一个或多个动作的能力有时可以被称为“技能”。即,技能可以使语音小程序390能够执行特定功能,以提供数据或产生由用户所请求的一些其他输出。特定语音小程序390可以被配置为执行多于一个技能/动作。例如,天气服务技能可涉及向一个或多个服务器120提供天气信息的天气语音小程序,汽车服务技能可涉及预订关于出租车或车辆共乘服务的行程的汽车服务语音小程序,订披萨技能可涉及相对于餐厅的在线订购系统订披萨的餐厅语音小程序,等等。
语音小程序390可以与实现不同类型的技能的一个或多个语音小程序服务器325通信。技能的类型包括家庭自动化技能(例如,使用户能够控制诸如灯、门锁、摄像头、恒温器等家庭设备的技能)、娱乐设备技能(例如,使用户能够控制诸如智能电视等娱乐设备的技能)、视频技能、新闻简报技能,以及不与任何预配置类型的技能相关联的自定义技能。
在某些情况下,由语音小程序390提供的数据可以呈适于输出给用户的形式。在其他情况下,由语音小程序390提供的数据可以呈不适于输出给用户的形式。这样的情况包括语音小程序390提供文本数据,而音频数据适于输出给用户。
一个或多个服务器120可以包括tts部件380,tts部件380使用一种或多种不同的方法从文本数据生成音频数据。然后,由tts部件380生成的音频数据可以由设备110作为合成语音输出。在称为单元选择的一种合成方法中,tts部件380参照所记录的语音的数据库来匹配文本数据。tts部件380选择所记录的语音中的匹配单元并将这些单元连结在一起以形成输出音频数据。在称为参数合成的另一种合成方法中,tts部件380改变诸如频率、音量和噪声等参数以创建包括人工语音波形的输出音频数据。参数合成使用计算机化的语音发生器,有时被称为声码器。
一个或多个服务器120可以包括用户配置文件存储装置370。用户配置文件存储装置370可以包括与和系统交互的各个用户、用户组等有关的各种信息。用户配置文件存储装置370可以包括一个或多个客户配置文件。每个客户配置文件可以与不同的客户id相关联。客户配置文件可能是一组用户特有的伞配置文件。即,客户配置文件涵盖两个或更多个单独的用户配置文件,每个用户配置文件与相应的用户id相关联。例如,客户配置文件可以是家庭配置文件,该家庭配置文件涵盖与单个家庭的多个用户相关联的用户配置文件。客户配置文件可包括其所涵盖的所有用户配置文件共享的偏好。涵盖在单个客户配置文件下的每个用户配置文件可以另外包括与其相关联的用户特有的偏好。即,每个用户配置文件可包括与由同一客户配置文件涵盖的一个或多个其他用户配置文件不同的偏好。用户配置文件可以是独立的配置文件或可以被涵盖在客户配置文件下。如图所示,用户配置文件存储装置370被实现为一个或多个服务器120的一部分。然而,本领域技术人员将理解,用户配置文件存储装置370可以例如经由一个或多个网络199与一个或多个服务器120通信。
每个用户配置文件可与相应的用户id相关联。用户配置文件可以包括各种信息,诸如表示与所述用户配置文件相关联的设备的一个或多个设备id;表示与所述用户配置文件相关联的用户的各种特性的信息,诸如用户年龄;表示与用户配置文件相关联的用户所属的年龄范围的信息;和/或表示用户配置文件是否对应于儿童用户配置文件的标志或其他指示。
一个或多个服务器120可以包括设备配置文件存储装置385。可替代地,设备配置文件存储装置385可以例如经由一个或多个网络199与一个或多个服务器120通信。设备配置文件存储装置385可包括与相应的设备110相关联的设备配置文件。每个设备配置文件可与相应的设备id相关联。设备配置文件可以包括各种信息,诸如表示与所述设备配置文件相关联的用户配置文件的一个或多个用户id;表示与所述设备配置文件相关联的设备110的位置(例如,地理位置或在建筑物内的位置)的位置信息;互联网协议(ip)地址信息;和/或表示设备配置文件是否对应于儿童设备配置文件的标志或其他指示。
一个或多个服务器120可以包括用户辨识部件395,用户辨识部件395辨识与输入到系统的数据相关联的一个或多个用户,如下所述。
一个或多个服务器120可以包括存储访问策略数据的访问策略存储装置375。单个访问策略可为系统级访问策略,因为该访问策略可被默认为与系统的所有儿童设备id和/或儿童用户id相关联。例如,如图9中所示,系统级访问策略可以防止与儿童设备id相关联的设备和/或与儿童用户id相关联的儿童用户调用购物语音小程序的<购买>意图或智能家居语音小程序的<开门锁>意图,同时使同一设备能够调用与其他语音小程序相关联的其他意图。针对特定语音小程序390的特定意图的系统级访问策略可以由语音小程序390(或相关联技能)的开发者提供给系统或以其他方式被配置用于通过该系统进行操作。如上所述,系统级访问策略可以是默认访问策略。这样,系统级访问策略可以由成人用户更改,如下所述。
系统可以被配置为并入有用户权限,并且仅在用户批准的情况下才能执行本文公开的活动。这样,本文所述的传感器、系统和技术将通常被配置为适当地限制处理,并且仅以确保符合所有适用法律、法规、标准等的方式处理用户信息。例如,系统可仅以与用户权限(例如,与经验证的家长同意书)一致的方式并根据适用法律(例如,1998年的儿童在线隐私保护法案(coppa)、儿童互联网保护法案(cipa)等)接收和存储儿童相关信息(例如,与系统的用户界面交互所需的信息)。该系统和技术可以在地理基础上执行,以确保符合一个或多个系统的一个或多个部件和/或用户所在的各个行政辖区和实体内的法律。
访问策略存储装置375还可以存储设备id和/或用户id特有的访问策略。可以基于从有权控制访问策略的用户(例如,具有与儿童设备id和/或儿童用户id相关联的成人用户配置文件id的成人用户)接收的输入来创建这样的访问策略。成人用户可以经由与系统相关联的伴随应用程序或网站来控制与特定儿童设备id和/或儿童用户id相关联的访问策略。例如,伴随应用程序或网站可以向成人用户提供相对于特定儿童设备id和/或儿童用户id被启用的意图。成人用户可以控制哪些被启用的意图可以由设备(与儿童设备id相关联)的用户和/或与儿童用户id相关联的用户访问。当成人用户提供表示儿童设备id和/或儿童用户id应无法调用特定意图的输入时,系统写入对应的访问策略并将该对应的访问策略作为访问策略数据存储在访问策略存储装置375中。成人用户还可以对着系统说出哪些意图针对给定用户id、设备id或设备类型id应该被启用。
图10示出了可由访问策略存储装置375存储的设备id和用户id特有的访问策略。如图所示,语音小程序和对应的意图可以与设备id和/或用户id以及相应的权限相关联。虽然图10示出了由访问策略存储装置375存储的访问策略可包括表示何时允许或不允许特定唯一id调用特定意图的访问策略,但本领域技术人员将理解,所存储访问策略可仅表示何时不允许特定唯一id调用特定意图。相反地,在某些实现方式中,所存储访问策略可仅表示何时允许特定唯一id调用特定意图。因此,本领域技术人员将理解,访问策略存储装置375中的访问策略数据可以以各种形式表示,这些形式包括白名单、黑名单、自定义权限表、某些当日时间特有的权限,等等。
如上所述,儿童访问策略可特定于意图。本领域技术人员将理解,儿童访问策略也可特定于语音小程序390和/或技能。例如,访问策略可以防止与儿童设备id相关联的设备和/或与儿童用户id相关联的儿童用户调用购物语音小程序和/或技能。
鉴于前述内容,本领域技术人员将理解,访问策略存储装置375中存储的访问策略数据可以响应于系统的用户的动作和/或系统级访问策略的变化而被更新或以其他方式更改。虽然访问策略存储装置375中存储的访问策略数据可以被更新或以其他方式更改,但这可能不会影响由一个或多个服务器120执行的语音处理,因为如下所述,访问策略存储装置375可以直到后nlu处理才被查询。
图4示出了如何对输入文本数据执行nlu处理。通常,nlu部件360试图对输入至其的文本数据中表示的文本进行语义解译。即,nlu部件360基于文本数据中表示的单个字词和/或短语来确定文本数据背后的含义。nlu部件360解译文本数据以推导用户输入的意图或期望动作以及允许设备(例如,设备110a、设备110b、一个或多个服务器120、一个或多个语音小程序服务器325等)完成该动作的文本数据片。例如,如果nlu部件360接收到对应于“请告诉我天气”的文本数据,则nlu部件360可确定用户想要系统输出天气信息。
nlu部件360可以处理包括单次所说话语的若干假设的文本数据。例如,如果asr部件350输出包括asr假设的n-最佳列表的文本数据,则nlu部件360可以相对于文本数据中表示的所有(或一部分)asr假设来处理该文本数据。尽管asr部件350可输出asr假设的n-最佳列表,但nlu部件360可以被配置为仅相对于n-最佳列表中得分最高的asr假设来进行处理。
nlu部件360可以通过对文本数据进行语法分析(parsing)和/或标记来注释该文本数据。例如,对于文本“告诉我seattle的天气情况”,nlu部件360可以将“seattle”标记为天气信息的位置。
nlu部件360可以包括一个或多个辨识器463。每个辨识器463可以与不同的语音小程序390相关联。每个辨识器463可以相对于输入到nlu部件360的文本数据进行处理。每个辨识器463可以与nlu部件360的其他辨识器463并行操作。
每个辨识器463可以包括命名实体辨识(ner)部件462。ner部件462尝试识别可用于相对于输入其中的文本数据来分析含义的语法和词汇信息。ner部件462识别文本数据中对应于命名实体的部分,命名实体可以适用于通过与实现ner部件462的辨识器463相关联的语音小程序390执行的处理。ner部件462(或nlu部件360的其他部件)还可确定字词是否是指其身份未在文本数据中明确提到的实体,例如“他”、“她”、“它”或其他指代、外指等。
每个辨识器463,并且更具体地每个ner部件462,可以与特定的语法模型和/或数据库473、一组特定的意图/动作478和特定的个性化词库486相关联。每个地名录484可包括与特定用户5和/或设备110相关联的语音小程序索引词汇信息。例如,地名录a(484a)包括语音小程序索引词汇信息486aa到486an。用户的音乐语音小程序词汇信息例如可能包括专辑名、艺术家姓名和歌曲名,而用户的联系人列表语音小程序词汇信息可能包括联系人的姓名。由于每个用户的音乐收藏和联系人列表可能不同,这种个性化信息改善了实体解析。
ner部件462施用与语音小程序390(与实现ner部件462的辨识器463相关联)相关联的语法模型476和词汇信息486,以确定对文本数据中的一个或多个实体的提及。以这种方式,ner部件462识别进行后期处理可能需要的“词槽(slot)”(对应于文本数据中的一个或多个特定字词)。ner部件462还可以用类型(例如,名词、地点、城市、艺术家姓名、歌曲名等)来标注每个词槽。
每个语法模型476包括通常在关于与语法模型476有关的特定语音小程序390的语音中发现的实体名称(即,名词),而词汇信息486对于输入音频数据311或输入文本数据313源自的用户5和/或设备110是个性化的。例如,与购物语音小程序相关联的语法模型476可包括在人们讨论购物时通常使用的字词的数据库。
称为命名实体解析的下游过程实际上将文本数据的一部分链接到系统已知的实际特定实体。为了执行命名实体解析,nlu部件360可以利用存储在实体库存储装置482中的地名录信息(484a-484n)。地名录信息484可以用来匹配具有不同实体(诸如歌曲名、联系人姓名等)的文本数据。地名录484可以链接到用户(例如,特定地名录可与特定用户的音乐收藏相关联),可以链接到某些语音小程序390(例如,购物语音小程序、音乐语音小程序、视频语音小程序、通信语音小程序等),或者可以以各种其他方式组织。
每个辨识器463还可以包括意图分类(ic)部件464。ic部件464对文本数据进行语法分析以确定与语音小程序390相关联(与实现ic部件464的辨识器463相关联)的潜在地表示用户输入的一个或多个意图。意图对应于响应于用户输入要被执行的动作。ic部件464可与链接到意图的字词的数据库478通信。例如,音乐意图数据库可以将诸如“安静”、“关闭音量”和“静音”等字词和短语链接到<静音>意图。ic部件464通过将文本数据中的字词和短语与和语音小程序390相关联的意图数据库478中的字词和短语进行比较来识别潜在意图,语音小程序390与实现ic部件464的辨识器463相关联。
可由特定ic部件464识别的意图被链接到具有待填充的“词槽”的语音小程序(即,与实现ic部件464的辨识器463相关联的语音小程序390)特有语法框架476。语法框架476的每个词槽对应于文本数据的被系统认为对应于实体的部分。例如,对应于<播放音乐>意图的语法框架476可能对应于诸如“播放{艺术家姓名}”、“播放{专辑名}”、“播放{歌曲名}”、“播放由{艺术家姓名}演唱的{歌曲名}”等文本数据句子结构。然而,为了使解析更加灵活,语法框架476可以不被结构化为句子,而是基于使词槽与语法标签关联。
例如,ner部件462可以在辨识文本数据中的命名实体之前对文本数据进行语法分析以基于语法规则和/或模型将字词识别为主语、宾语、动词、介词等。ic部件464(由相同的辨识器463实现为ner部件462)可以使用所识别的动词来识别意图。然后,ner部件462可确定与所识别的意图相关联的语法模型476。例如,针对对应于<播放音乐>的意图的语法模型476可以指定适用于播放所识别的“宾语”和任何宾语修饰语(例如,介词短语)的一系列词槽,诸如{艺术家姓名}、{专辑名}、{歌曲名}等。然后,ner部件462可以搜索与语音小程序390(与实现ner部件462的辨识器463相关联)相关联的词库486中的对应字段,从而尝试将文本数据中先前被ner部件462标记为语法宾语或宾语修饰语的字词和短语与在词库486中所识别的那些字段进行匹配。
ner部件462可以执行语义标记,所述语义标记为根据字词或字词组合的类型/语义对字词或字词组合进行的标注。ner部件462可以使用启发式语法规则对文本数据进行语法分析,或可使用如下技术来构造模型,诸如隐马尔可夫模型、最大熵模型、对数线性模型、条件随机场(crf)等。例如,由音乐语音小程序辨识器实现的ner部件462可以对对应于“播放由滚石乐队(therollingstones)演唱的《妈妈的小帮手》(mother’slittlehelper)”的文本数据进行语法分析并将该文本数据标记为{动词}:“播放”,{宾语}:“《妈妈的小帮手》”,{宾语介词}:“由”,和{宾语修饰语}:“滚石乐队”。ner部件462基于与音乐语音小程序相关联的字词数据库将“播放”识别为动词,ic部件464(也由音乐语音小程序辨识器实现)可确定“播放”对应于<播放音乐>意图。在这个阶段,尚不确定“《妈妈的小帮手》”和“滚石乐队”的含义,但基于语法规则和模型,ner部件462已确定这些短语的文本与文本数据中表示的用户输入的语法宾语(即,实体)有关。
然后,使用链接到意图的框架来确定应该搜索哪些数据库字段以确定这些短语的含义,诸如搜索用户的地名录484来获得与框架词槽的相似处。例如,<播放音乐>意图的框架可能指示试图基于{艺术家姓名}、{专辑名}和{歌曲名}来解析所识别的宾语,并且同一意图的另一个框架可能指示试图基于{艺术家姓名}来解析宾语修饰语,并基于链接到{艺术家姓名}的{专辑名}和{歌曲名}来解析宾语。如果对地名录484的搜索未使用地名录信息来解析词槽/字段,则ner部件462可以搜索与语音小程序390相关联的通用字词的数据库(在知识库472中)。例如,如果文本数据包括“播放由滚石乐队演唱的歌曲”,则在不能确定被称为由“滚石乐队”演唱的“歌曲”的专辑名或歌曲名之后,ner部件462可以在语音小程序词汇表中搜索字词“歌曲”。在替代方案中,通用字词可以在地名录信息之前进行检查,或可以尝试两者,从而可能产生两个不同的结果。
ner部件462可以标记文本数据以赋予其含义。例如,ner部件462可以将“播放由滚石乐队演唱的《妈妈的小帮手》”标记为:{语音小程序}音乐、{意图}<播放音乐>、{艺术家姓名}滚石乐队、{媒体类型}歌曲,以及{歌曲名}《妈妈的小帮手》。又例如,ner部件462可以将“播放由滚石乐队演唱的歌曲”标记为:{语音小程序}音乐、{意图}<播放音乐>、{艺术家姓名}滚石乐队,以及{媒体类型}歌曲。
nlu部件360可以生成跨语音小程序n-最佳列表数据540,跨语音小程序n-最佳列表数据540可以包括由每个辨识器463输出的一系列nlu假设(如在图5中示出)。辨识器463可以输出由通过辨识器463操作的ner部件462和ic部件464生成的带标记文本数据,如上所述。由ner部件462标注的包括意图指示符以及文本/词槽的带标记文本数据的每个条目可以被分组为在跨语音小程序n-最佳列表数据540中表示的nlu假设。每个nlu假设还可以与该nlu假设的一个或多个相应的得分相关联。例如,跨语音小程序n-最佳列表数据540可以如下表示,其中每一行表示一nlu假设:
[0.95]意图:<播放音乐>艺术家姓名:ladygaga歌曲名:《扑克脸》(pokerface)
[0.95]意图:<播放视频>艺术家姓名:ladygaga视频名:《扑克脸》
[0.01]意图:<播放音乐>艺术家姓名:ladygaga专辑名:《扑克脸》
[0.01]意图:<播放音乐>歌曲名:《扑克脸》
nlu部件360可以将跨语音小程序n-最佳列表数据540发送到修剪部件550。修剪部件550可以根据在跨语音小程序n-最佳列表数据540中表示的带标记文本数据的条目的相应得分来对所述条目进行排序。然后,修剪部件550可以相对于跨语音小程序n-最佳列表数据540执行得分阈值法。例如,修剪部件550可以选择跨语音小程序n-最佳列表数据540中表示的带标记文本数据的与满足(例如,达到和/或超过)阈值置信度得分的置信度得分相关联的条目。修剪部件550还可以或可替代地执行若干次带标记文本数据条目阈值法。例如,修剪部件550可以选择最大阈值数量的得分最高的带标记文本数据条目。修剪部件550可以生成包括所选的带标记文本数据条目的跨语音小程序n-最佳列表数据560。修剪部件550的目的是创建带标记文本数据条目的减少的列表,使得资源更密集的下游过程可以仅对最可能表示用户输入的带标记文本数据条目进行操作。
nlu部件360还可以包括精简词槽填充部件552。精简词槽填充部件552可从由修剪部件550输出的带标记文本数据条目中表示的词槽取得文本数据,并将该文本数据更改为使该文本数据更容易地由下游部件进行处理。精简词槽填充部件552可以执行不涉及诸如参考知识库等繁重操作的低延迟操作。精简词槽填充部件552的目的是将字词替换为可由下游系统部件更容易地理解的其他字词或值。例如,如果带标记文本数据条目包括字词“明天”,则精简词槽填充部件552可将字词“明天”替换为实际日期以进行下游处理。类似地,精简词槽填充部件552可将字词“cd”替换为“专辑”或字词“光盘”。然后,替换的字词被包括在跨语音小程序n-最佳列表数据560中。
nlu部件360将跨语音小程序n-最佳列表数据560发送到实体解析部件570。实体解析部件570可以应用规则或其他指令,以使来自先前阶段的标签或令牌标准化为意图/词槽表示。精确变换可以依赖于语音小程序390。例如,对于旅游语音小程序,实体解析部件570可以将对应于“boston机场”的文本数据变换成指代该机场的标准bos三字母码。实体解析部件570可以是指用于特定地识别跨语音小程序n-最佳列表数据560中表示的每个带标记文本数据条目的每个词槽中提及的精确实体的知识库。特定意图/词槽组合也可以与特定的源关联,这然后可以被用于解析文本数据。在“播放由滚石乐队演唱的歌曲”的示例中,实体解析部件570可以参考个人音乐目录、亚马逊音乐帐户、用户配置文件数据等。实体解析部件570可以输出包括更改后的n-最佳列表的文本数据,该更改后的n-最佳列表是基于跨语音小程序n-最佳列表数据560并且包括关于在词槽中提及的特定实体的更详细的信息(例如,实体id)和/或可最终由语音小程序390使用的更详细的词槽数据。nlu部件360可以包括多个实体解析部件570,并且每个实体解析部件570可以特定于一个或多个语音小程序390。
实体解析部件570可能不会成功地解析每个实体以及填充跨语音小程序n-最佳列表数据560中表示的每个词槽。这可能导致实体解析部件570输出不完整的结果。nlu部件360可包括排名器部件590。排名器部件590可以将特定的置信度得分分配给输入其中的每个带标记文本数据条目。带标记文本数据条目的置信度得分可以表示系统在相对于该带标记文本数据条目执行的nlu处理中的置信度。特定的带标记文本数据条目的置信度得分可以受到带标记文本数据条目是否有未填充词槽的影响。例如,如果与第一语音小程序相关联的带标记文本数据条目包括全部被填充/解析的词槽,则与至少一些词槽未被实体解析部件570填充/解析的另一个带标记文本数据条目相比,该带标记文本数据条目可被分配更高的置信度得分。
排名器部件590可应用重新评分、偏置或其他技术来确定得分最高的带标记文本数据条目。要做到这一点,排名器部件590可能不仅要考虑由实体解析部件570输出的数据,而且可能还要考虑其他数据591。其他数据591可以包括各种信息。其他数据591可包括语音小程序390评级或人气数据。例如,如果一个语音小程序390具有特别高的评级,则排名器部件590可以增加由与语音小程序390相关联的辨识器463输出的带标记文本数据条目的得分。其他数据591还可以包括关于已经针对与当前用户输入相关联的用户id和/或设备id启用的语音小程序390的信息。例如,与由与未启用的语音小程序390相关联的辨识器463输出的带标记文本数据条目相比,排名器部件590可以将更高的得分分配给由与启用的语音小程序390相关联的辨识器463输出的带标记文本数据条目。其他数据591还可以包括指示用户使用历史的数据,诸如与当前用户输入相关联的用户id是否定期地与调用特定语音小程序390的用户输入相关联或在一天内的特定时段这样做。其他数据591可以另外包括指示日期、时间、位置、天气、设备110的类型、用户id、设备id、情景以及其他信息的数据。例如,排名器部件590可以考虑任何特定语音小程序390当前处于活动状态(例如,正在播放音乐、正在玩游戏等)的时间。
在由排名器部件590排名之后,nlu部件360可以向协调器部件330输出nlu结果数据585。nlu结果数据585可包括具有与第一语音小程序390a相关联的带标记文本数据的第一nlu结果数据585a,具有与第二语音小程序390b相关联的带标记文本数据的第二nlu结果数据585b,等等。nlu结果数据585可以包括对应于由排名器部件590确定的得分最高的带标记文本数据条目(例如,呈n-最佳列表的形式)的带标记文本数据。可替代地,nlu结果数据585可包括对应于由排名器部件390确定的得分最高的带标记文本数据条目的带标记文本数据。
如上所详细描述,一个或多个服务器120可以包括使用各种数据辨识一个或多个用户的用户辨识部件395。如图6所示,用户辨识部件395可包括一个或多个子部件,该一个或多个子部件包括视觉部件608、音频部件610、生物特征部件612、射频(rf)部件614、机器学习(ml)部件616、以及辨识置信度部件618。在一些情况下,用户辨识部件395可监测来自一个或多个子部件的数据和确定,以确定与输入到系统的数据相关联的一个或多个用户的身份。用户辨识部件395可输出用户辨识数据695,用户辨识数据695可以包括与系统认为输入到系统的数据所源自的用户相关联的用户id。用户辨识数据695可用于通知由协调器330(或其子部件)执行的过程,如下所述。
视觉部件608可以从能够提供图像的一个或多个传感器(例如,摄像头)或指示运动的传感器(例如,运动传感器)接收数据。视觉部件608可以执行面部辨识或图像分析来确定用户的身份,并将该身份与和用户相关联的用户配置文件数据关联。在一些情况下,当用户正面向摄像头时,视觉部件608可以执行面部辨识并以高置信度来识别该用户。在其他情况下,视觉部件608可具有低置信度的用户身份,并且用户辨识部件395可以利用来自附加部件的确定来确定用户的身份。视觉部件608可以结合其他部件使用,以确定用户的身份。例如,用户辨识部件395可以使用来自视觉部件608的数据与来自音频部件610的数据来识别在由用户正面对的设备110捕获音频的同时哪个用户的面部看起来在说什么,以便识别说话的用户。
该系统可包括生物特征传感器,所述生物特征传感器将数据传输到生物特征部件612。例如,生物特征部件612可以接收对应于指纹、虹膜或视网膜扫描、热扫描、用户的重量、用户的大小、压力(例如,在地板传感器内)等的数据,并可确定对应于用户的生物特征配置文件。例如,生物特征部件612可以区分用户与来自电视的声音。因此,生物特征部件612可以将生物特征信息并入用于确定用户的身份的置信水平。由生物特征部件612输出的生物特征信息可以与特定用户配置文件数据相关联,使得生物特征信息唯一地识别用户的用户配置文件数据。
rf部件614可以使用rf定位来跟踪用户可以携带或佩戴的设备。例如,用户(和与该用户相关联的用户配置文件数据)可以与计算设备相关联。所述计算设备可发射rf信号(例如,wi-fi、
在一些情况下,设备110可以包括一些rf或其他检测处理能力,使得说话的用户可以将他/她的个人设备(诸如电话)扫描到设备110、将他/她的个人设备(诸如电话)敲入到设备110或以其他方式向设备110确认他/她的个人设备(诸如电话)。以这种方式,用户可以在系统进行“登记”,以便系统确定是谁讲了特定话语。这种登记可在说话之前、期间或之后发生。
ml部件616可跟踪各个用户的行为,作为确定用户的身份的置信水平的因素。举例来说,用户可以遵循固定的时间表,使得用户在白天位于第一位置(例如,在工作或在学校)。在这个示例中,ml部件616将过去的行为和/或趋势作为考虑因素来确定向系统提供输入的用户的身份。因此,ml部件616可以使用历史数据和/或随时间推移的使用模式来提高或降低用户的身份的置信水平。
在一些情况下,辨识置信度部件618接收来自各种部件608、610、612、614和616的确定,并且可以确定与用户的身份相关联的最终置信水平。在一些情况下,置信水平可确定动作是否被执行。例如,如果用户输入包括开门锁的请求,则置信水平可能需要高于可比执行与播放播放列表或发送消息相关联的用户请求所需的置信水平阈值更高的阈值。置信水平或其他得分数据可以被包括在用户辨识数据695中。
音频部件610可以从能够提供音频信号的一个或多个传感器(例如,一个或多个传声器)接收数据,以促进辨识用户。音频部件610可以对音频信号进行音频辨识来确定用户的身份和相关联的用户id。在一些情况下,可以在计算设备(例如,本地服务器)处配置一个或多个服务器120的各方面。因此,在一些情况下,在计算设备上操作的音频部件610可以分析所有声音,以促进辨识用户。在一些情况下,音频部件610可以执行语音辨识,以确定用户的身份。
音频部件610还可以基于输入到系统中用于语音处理的输入音频数据311来执行用户识别。音频部件610可确定指示输入音频数据311是否源自特定用户的得分。例如,第一得分可以指示输入音频数据311源自与第一用户id相关联的第一用户的可能性,第二得分可指示输入音频数据311源自与第二用户id相关联的第二用户的可能性,等等。音频部件610可通过比较表示输入音频数据311的音频特性与用户的所存储音频特性来执行用户辨识。
图7示出了用户辨识部件395的音频部件610使用诸如输入音频数据311的音频数据来执行用户辨识。除了如上所述输出文本数据之外,asr部件350还可以输出asr置信度数据702,asr置信度数据702可以被传递到用户辨识部件395。音频部件610使用各种数据执行用户辨识,该各种数据包括输入音频数据311、对应于与已知用户相对应的样本音频数据的训练数据704、asr置信度数据702和其他数据706。音频部件610可以输出用户辨识置信度数据708,用户辨识置信度数据708反映输入音频数据311表示由一个或多个特定用户所说的话语的某个置信度。用户辨识置信度数据708可包括经验证用户的指示符(诸如对应于话语的说话者的用户id)以及置信度值,诸如如下讨论的数值或分级值。用户辨识置信度数据708可以由用户辨识部件395的各种其他部件用来辨识用户。
训练数据704可以被存储在用户辨识存储装置710中。用户辨识存储装置710可被包括在一个或多个服务器120中,或例如经由一个或多个网络199与一个或多个服务器120通信。此外,用户辨识存储装置710可以是配置文件存储装置370的一部分。用户辨识存储装置710可以是基于云的存储装置。
存储在用户辨识存储装置710中的训练数据704可以被存储为波形和/或对应的特征/向量。训练数据704可以对应于来自各种音频样本的数据,每个音频样本与已知用户的用户id相关联。音频样本可对应于一个或多个用户的语音配置文件数据。例如,系统已知的每个用户可以与某一组训练数据704相关联。因此,训练数据704可以包括用户的语音的生物特征表示。音频部件610可以使用训练数据704来与输入音频数据311进行比较,以确定讲出输入音频数据311中表示的话语的用户的身份。存储在用户辨识存储装置710中的训练数据704因此可以与系统的多个用户相关联。存储在用户辨识存储装置710中的训练数据704也可以与捕获到相应话语的设备110相关联。
为了执行用户辨识,音频部件610可确定输入音频数据311所源自的设备110。例如,输入音频数据311可以与指示设备110(例如,设备id)的标签或其他元数据相关联。设备110或一个或多个服务器120可以这样标记输入音频数据311。用户辨识部件395可向用户辨识存储装置710发送信号,其中该信号仅请求与输入音频数据311所源自的设备110(例如,设备id)相关联的训练数据704。这可以包括确定包括设备id的用户配置文件数据,然后仅输入(向音频部件610)与对应于用户配置文件数据的用户id相关联的训练数据704。这限制了音频部件610在运行时辨识用户时应考虑的可能的训练数据704的全集,并因此通过减少需要被处理的训练数据704的量来减少执行用户辨识的时间量。可替代地,用户辨识部件395可以访问系统可用的所有(或一些其他子集)的训练数据704。
如果音频部件610将训练数据704接收为音频波形,则音频部件610可确定一个或多个波形的特征/向量,或以其他方式将一个或多个波形转换成可以由音频部件610用于实际执行用户辨识的数据格式(例如,指纹)。同样,如果音频部件610将输入音频数据311接收为音频波形,则音频部件610可确定一个或多个波形的特征/向量,或以其他方式将一个或多个波形转换成输入音频数据311唯一的指纹。指纹可以是唯一但不可逆的,使得指纹对基础音频数据来说是唯一的,但不能用于再现该基本音频数据。音频部件610可以通过比较表示输入音频数据311的特征/向量/指纹与从用户辨识存储装置710接收的训练特征/向量/指纹(从用户辨识存储装置710接收或从训练数据704确定)来识别说出在输入音频数据311中表示的话语的用户。
音频部件610可以包括评分部件712,计分部件712确定指示由输入音频数据311表示的话语是否由特定用户(由训练数据704表示)说出的相应得分。音频部件610还可以包括置信度部件714,置信度部件714确定用户辨识操作(诸如评分部件712的那些操作)的整体置信度和/或由评分部件712潜在地识别的每个用户的单独置信度。来自评分部件712的输出可以包括执行用户辨识所相对的所有用户(例如,与和输入音频数据311相关联的设备id相关联的所有用户id)的得分。例如,该输出可以包括第一用户id的第一得分、第二用户id的第二得分、第三用户id的第三得分等。虽然示出为两个单独的部件,但是评分部件712和置信度部件714可以被组合成单个部件,或者可以被分成两个以上部件。
评分部件712和置信度部件714可以实现如本领域已知的一个或多个经训练的机器学习模型(诸如神经网络、分类器等)。例如,评分部件712可以使用概率线性判别分析(plda)技术。plda评分确定输入音频数据特征向量对应于与特定用户id相关联的特定训练数据特征向量的可能性。plda评分可以为每个被考虑的训练特征向量生成相似性得分并且可以输出训练数据特征向量与输入音频数据特征向量最紧密对应的用户的得分和用户id的列表。评分部件712还可以使用其他技术,诸如gmm、生成贝叶斯模型等,以确定相似性得分。
置信度部件714可以输入各种数据来考虑音频部件610关于将用户id链接到输入音频数据311的得分的置信度,该各种数据包括asr置信度数据702、音频长度(例如,输入音频数据311的帧数)、音频状况/质量数据(诸如信号干扰数据或其他度量数据)、指纹数据、图像数据或其他数据。置信度部件714也可以考虑由评分部件712输出的相似性得分和用户id。因此,置信度部件714可确定asr置信度数据702中表示的较低asr置信度,或较差的输入音频质量,或其他因素,可能会导致音频部件610的较低置信度。而asr置信度数据702中表示的较高asr置信度,或较好的输入音频质量,或其他因素,可能会导致音频部件610的较高置信度。对置信度的精确确定可取决于对置信度部件714以及其中使用的模型的配置和训练。置信度部件714可以使用多个不同的机器学习模型/技术(诸如gmm、神经网络等)进行操作。例如,置信度部件714可以是被配置为将由评分部件712输出的得分映射到置信度的分类器。
音频部件610可以输出表示单个用户id或呈n-最佳列表形式的多个用户id的用户辨识置信度数据708。例如,音频部件610可以输出表示与输入音频数据311源自的设备110的设备id相关联的每个用户id的用户辨识置信度数据708。
用户辨识置信度数据708可包括特定得分(例如,0.0-1.0、0-1000,或系统被配置为进行操作的任何数值范围)。因此,系统可输出具有置信度得分的用户id的n-最佳列表(例如,用户id1-0.2、用户id2-0.8)。可替代地或另外,用户辨识置信度数据708可包括分级辨识指示符。例如,第一范围(例如,0.0-0.33)的所计算辨识得分可被输出为“低”,第二范围(例如,0.34-0.66)的所计算辨识得分可被输出为“中等”,并且第三范围(例如,0.67-1.0)的所计算辨识得分可以被输出为“高”。因此,系统可输出具有分级得分的用户id的n-最佳列表(例如,用户id1-低、用户id2-高)。组合式分级得分与置信度得分输出也是可能的。用户辨识置信度数据708可以仅包括与由音频部件610确定的得分最高的用户id相关的信息,而不包括用户id及其相应得分和/或分级的列表。得分和分级可以基于由置信度部件714确定的信息。音频部件610还可以输出得分/分级正确的置信度值,其中置信度值指示音频部件610在用户辨识置信度数据708中的置信度。置信度值可以由置信度部件714来确定。
在确定用户辨识置信度数据708时,置信度部件714可确定不同的用户id的置信度得分之间的差值。例如,如果第一用户id置信度得分和第二用户id置信度得分之间的差值较大并且第一用户id置信度得分高于阈值,则音频部件610能够辨识到第一用户id与和用户id置信度得分之间的差值较小的情况相比具有高得多的置信度的输入音频数据311相关联。
音频部件610可以执行某一阈值法,以避免不正确的用户辨识置信度数据708被输出。例如,音频部件610可以将由置信度部件714输出的置信度得分与置信度阈值进行比较。如果置信度得分不高于置信度阈值(例如,“中等”或更高的置信度),则音频部件610可以不输出用户辨识置信度数据708,或者可以仅在该数据708中包括用户id无法确定的指示。此外,音频部件610可以不输出用户辨识置信度数据708,直到阈值量的输入音频数据311被累积并处理。因此,音频部件610可等待直到阈值量的输入音频数据311已被处理,之后再输出用户辨识置信度数据708。接收到的输入音频数据311的量也可被置信度部件714考虑在内。
用户辨识部件395可组合来自部件608-618的数据以确定特定用户的身份。作为音频部件610的基于音频的用户辨识操作的一部分,音频部件610可以使用其他数据706来通知用户辨识处理。音频部件610的经训练模型或其他部件可以被训练成将其他数据706作为执行辨识时的输入特征。其他数据706可以包括取决于系统配置的各种各样的数据类型,并且可以得自其他传感器、设备或存储装置,诸如用户配置文件数据等。其他数据706可包括输入音频数据311被捕获的当日时间、输入音频数据311被捕获的周中此日、由asr部件350输出的文本数据、nlu结果数据585和/或其他数据。
在一个示例中,其他数据706可包括图像数据或视频数据。例如,可以对与接收到的输入音频数据311相关联的图像数据或视频数据(例如,与输入音频数据311同时接收)执行面部辨识。面部辨识可以由视觉部件608或者由一个或多个服务器120的另一部件执行。面部辨识过程的输出可以由音频部件610使用。即,面部辨识输出数据可以结合对输入音频数据311和训练数据704的特征/向量的比较用于执行更准确的用户辨识。
其他数据706还可以包括设备110的位置数据。位置数据可以特定于设备110所在的建筑物。例如,如果设备110位于用户a的卧室,则这样的位置可以提高与用户a的用户id相关联的用户辨识置信度,而降低与用户b的用户id相关联的用户辨识置信度。
其他数据706还可以包括与设备110的配置文件相关的数据。例如,其他数据706还可以包括指示设备110的类型的类型数据。不同类型的设备可以包括,例如,智能手表、智能电话、平板计算机以及车辆。可以在与设备110相关联的配置文件中指示设备的类型。例如,如果输入音频数据311接收自的设备110是属于用户a的智能手表或车辆,则设备110属于用户a这一事实可以提高与用户a的用户id相关联的用户辨识置信度,而降低与用户b的用户id相关联的用户辨识置信度。可替代地,如果输入音频数据311接收自的设备110是公共或半公共设备,则系统可以使用关于设备110的位置的信息来交叉检查其他潜在的用户定位信息(诸如日历数据等),以潜在地缩窄执行用户辨识所相对的潜在用户id。
其他数据706可另外包括与设备110相关联的地理坐标数据。例如,与车辆相关联的配置文件数据可以指示多个用户id。车辆可包括在车辆捕获输入音频数据311时指示车辆的纬度和经度坐标的全球定位系统(gps)。因此,如果车辆位于对应于用户a的工作位置/建筑物的坐标处,则这可提高与用户a的用户id相关联的用户辨识置信度,而降低与车辆相关联的配置文件数据中指示的所有其他用户id的用户辨识置信度。可在与设备110相关联的用户配置文件数据中指示全局坐标和相关联的位置(例如,工作、家等)。全局坐标和相关联的位置可以与用户配置文件存储装置370中的相应的用户id相关联。
其他数据706也可以包括关于特定用户的活动的在相对于输入音频数据311执行用户辨识时可有用的其他数据/信号。例如,如果用户最近输入了密码以禁用家庭安全警报,并且从家里的设备110接收到话语,则来自家庭安全警报的关于使用户禁用、禁用时间等的信号可以反映在其他数据706中并被音频部件610考虑在内。如果已知与特定用户相关联的移动设备(例如电话、磁贴、加密狗、或其他设备)被检测到靠近设备110(例如,物理上接近,连接到相同的wi-fi网络,或以其他方式在附近),则这可以反映在其他数据706中并被音频部件610考虑在内。
由音频部件610输出的用户辨识置信度数据708可以由用户辨识部件395的其他部件使用和/或可以被发送到一个或多个语音小程序390、协调器330或系统的其他部件。
如所描述的,一个或多个服务器120可以执行nlu处理以生成nlu结果数据585,以及执行用户辨识处理以生成用户辨识数据695。用户辨识处理可以与nlu处理并行(或至少部分地并行)执行。nlu结果数据585和用户辨识数据695两者可分别通过nlu部件360和用户辨识部件395被发送到协调器部件330。通过与nlu处理至少部分地并行执行用户辨识处理,可最小化协调器部件330接收用户辨识数据695与协调器部件330接收nlu结果数据585之间的时间,这可降低在任何给定时间接收大量用户输入的稳健系统中的协调器处理延迟。
具体地,用户辨识数据695和nlu结果数据585可被发送到协调器部件330的访问策略引擎810(在图8中示出)。访问策略引擎810可用作网守,因为当表示用户输入的数据被认为不适用于用户年龄(或年龄范围)时,访问策略引擎810可以防止语音小程序390对表示该输入的数据进行处理。
通过实现访问策略引擎810的后nlu处理,nlu部件360能够在没有来自用户的身份和年龄的影响的情况下进行处理。这最终使得nlu部件360能够确定用户的最准确的意图,而不管该意图是否被认为不适用于该用户。其结果是,该系统可以处理用户输入,以确定该输入的准确代表的意图并简单地实现在适当的情况下防止语音小程序390满足用户输入的策略。
如图8所示,访问策略引擎810从用户辨识部件395接收用户辨识数据695并从nlu部件360接收包括意图数据的nlu结果数据585。如果nlu结果数据585包括与各种语音小程序390相关联的nlu结果数据的n-最佳列表,则访问策略引擎810(或协调器部件330的另一部件)可识别nlu结果数据中得分最高的条目,其中该得分最高的条目包括表示被确定最能代表用户输入的意图的意图数据。
用户辨识处理可确定当前用户所属的年龄范围。年龄范围可以在用户辨识数据695中表示。说明性的年龄范围包括:0-3岁、4-6岁、7-10岁等等。说明性的年龄范围也可包括儿童、青春期前、青少年等等。年龄范围数据可在与相应的设备id相关联的设备配置文件数据中表示。用户辨识部件395可以实现一个或多个机器学习模型来确定当前用户的年龄范围。
用户辨识部件395的一个或多个模型可以根据各种机器学习技术来训练和操作。这样的技术可以包括,例如,神经网络(诸如深度神经网络和/或递归神经网络)、推理引擎、经训练分类器等。经训练分类器的示例包括支持向量机(svm)、神经网络、决策树、结合决策树的adaboost(“自适应增强”的缩写),以及随机森林。以svm为例,svm是具有相关联学习算法的监督学习模型,所述相关联学习算法分析数据并辨识数据中的模式,并且通常用于分类和回归分析。给定一组训练示例,每个训练示例被标记为属于两个类别(例如,垃圾邮件活动或非垃圾邮件活动)中的一个,svm训练算法建立将新的示例分配到一个类别或另一个类别中的模型,从而使该模型成为非概率二元线性分类器。更复杂的svm模型可利用识别多于两个类别的训练集而建立,其中svm确定哪个类别最类似于输入数据。svm模型可被映射,使得单独的类别的示例由明显的间隙分开。然后,新的示例被映射到相同的空间,并且被预测属于基于它们所落在的间隙的那一侧的类别。分类器可以发出指示数据最匹配哪个类别的“得分”。该得分可以提供对数据与类别的匹配程度的指示。在示例中,由用户辨识部件395实现的一个或多个机器习得模型可为用从已知年龄的用户接收的语音的正例训练的。
为了应用机器学习技术,机器学习过程本身需要训练。训练机器学习部件,诸如用户辨识部件395,需要针对训练示例建立“地面真值”。在机器学习中,术语“地面真值”是指训练集的分类针对监督学习技术的准确性。可以使用各种技术来训练模型,包括反向传播、统计学习、监督学习、半监督学习、随机学习,或其他已知技术。
可替代地或另外,用户辨识数据695可包括对应于当前用户输入可能源自的用户的一个或多个用户id。访问策略引擎810可确定得分最高的用户id(或在用户辨识数据695中仅表示了一个用户id的情况下的用户id)。然后,访问策略引擎810可在用户配置文件存储装置370中确定与所确定的用户id相关联的用户配置文件数据。具体地,访问策略引擎810可确定在与用户id相关联的用户配置文件数据中表示的年龄信息(例如,特定年龄或年龄范围)。
访问策略引擎810可以识别存储在访问策略存储装置375中的、与用户辨识数据695或用户配置文件数据中表示的年龄范围或年龄相关联的访问策略数据805。然后,访问策略引擎810,或更具体地访问策略引擎810的策略评估部件820,可确定语音小程序390是否应当能够相对于nlu结果数据585进行执行,或者由于用户输入不适用于用户年龄范围或年龄,nlu结果数据585是否不应该被发送到语音小程序390。具体地,策略评估部件820可确定nlu结果数据585中表示的意图数据是否在与年龄范围或年龄相关联的访问策略数据805中被表示。
如所描述的,用户辨识数据695可以表示用户id或用户id的n-最佳列表。访问策略引擎810可以识别存储在访问策略存储装置375中的、与用户id(或在n-最佳列表的情况下,得分最高的用户id)相关联的访问策略数据805。然后,策略评估部件820可确定nlu结果数据585中表示的意图数据是否在访问策略数据805中被表示。
如上所述,访问策略引擎810可以确定与用户辨识数据695或用户配置文件数据中表示的年龄、年龄范围或用户id相关联的访问策略数据805。某些系统可能不配置有用户辨识处理功能。可替代地或另外,某些系统可配置有儿童设备。在这样的系统中,访问策略引擎810接收表示与向一个或多个服务器120发送用户输入数据(例如,输入音频数据311或输入文本数据313)的设备110相关联的设备id的数据。访问策略引擎810可以识别存储在访问策略存储装置375中的、与设备id相关联的访问策略数据805。然后,策略评估部件820可确定nlu结果数据585中表示的意图数据是否在访问策略数据805中被表示。
设备110可以与特定年龄或年龄范围的用户相关联。在接收到设备id之后,访问策略引擎810可在设备配置文件存储装置385中确定与设备id相关联的设备配置文件数据。特别地,访问策略引擎810可确定在与设备id相关联的设备配置文件数据中表示的年龄信息(例如,特定年龄或年龄范围)。然后,访问策略引擎810可以识别存储在访问策略存储装置375中的、与设备配置文件数据中表示的年龄范围或年龄相关联的访问策略数据805。然后,策略评估部件820可确定nlu结果数据585中表示的意图数据是否在访问策略数据805中被表示。
如上所述,策略评估部件820可以确定在nlu结果数据585中表示的意图是否被认为适用于当前用户。单个语音小程序390可以与各种意图相关联。因此,语音小程序390可以能够针对特定用户id针对某个意图数据而非其他意图数据来执行。例如,单个语音小程序390可适用于相对于与用户id相关联的第一意图数据而非第二意图数据来执行。
可替代地,策略评估部件820可以确定语音小程序390,而非语音小程序的单独的意图,是否被认为适用于当前用户。例如,策略评估部件820可确定包括在nlu结果数据585(或其得分最高的条目)中的表示语音小程序390的数据是否在访问策略数据805中被表示,而不是策略评估部件820确定意图数据是否在访问策略数据805中被表示。
协调器部件330可响应于策略评估部件的处理来执行各种操作(如在图11中示出)。下面相对于图11的讨论是指策略评估部件820确定意图数据是否在访问策略数据805中被表示。本领域技术人员将理解,在策略评估部件820确定表示语音小程序390的数据是否在访问策略数据805中被表示时,协调器部件330可以执行类似的操作,如上所述。
如果策略评估部件820确定意图数据在访问策略数据805中被表示,从而表示用户输入的推导意图不适用于当前用户,则协调器部件330可使输出文本数据1110被发送到包括显示器的在当前用户的用户配置文件数据中表示的设备110(例如,设备110b)。该提示可为意图不可确知(例如,输出文本数据1110可以对应于“我无法处理您的命令”)。可替代地,该提示可以特定于一个或多个意图。例如,对于<购买>意图,输出文本数据1110可对应于“我注意到您正试图买东西。请找成人帮助您进行购买。”
可替代地,输出文本数据1110可以尝试使用户转向适用于用户年龄的意图。例如,如果nlu结果数据585表示<买书>意图数据并且这种意图数据在访问策略数据805中被表示,则协调器部件330(或其部件)可以生成对应于“我注意到您正试图买书,您愿意通过听有声读物来代替吗?”的输出文本数据1110,其中输出文本数据1110的后面部分对应于儿童适用的<播放有声读物>意图。建议的意图应该类似于请求的意图或以其他方式与请求的意图相关,但为儿童适用的。
除了或替代使设备110显示输出文本,协调器部件330还可以使与当前用户的用户配置文件数据相关联的设备110呈现对应于预配置的提示的输出音频。协调器部件330可将输出文本数据1110发送到tts部件380,tts部件380生成对应于输出文本数据1110的输出音频数据1120并将输出音频数据1120发送到协调器部件330。协调器部件330可将输出音频数据1120发送到包括一个或多个扬声器的一个或多个设备(例如,设备110a和/或设备110b)。
可替代地,如果nlu结果数据585中得分最高的意图数据被确定为不适用于当前用户(如由策略评估部件820确定),则访问策略引擎810可以顺着nlu结果数据585的n-最佳列表工作,直到策略评估部件820确定适用的意图数据。如果所确定的儿童适用的意图数据不与满足阈值nlu置信度得分的nlu置信度得分相关联,则协调器部件330可使输出文本数据1110和/或输出音频数据1120被呈现给用户。可替代地,如果所确定的儿童适用的意图数据与满足阈值nlu置信度得分的nlu置信度得分相关联,则协调器部件330可如下所述将数据发送到语音小程序390。阈值nlu置信度得分可以被配置的相对较高,以确保意图数据在并非得分最高的意图时仍然充分地表示用户的意图。
可替代地,如果策略评估部件820确定意图数据在访问策略数据805中被表示,从而表示用户输入的推导意图不适用于当前用户,则协调器部件330可调用被配置为生成输出数据(例如,输出文本数据和/或输出音频数据)的语音小程序,该输出数据表示系统需要成人许可来进一步处理所述用户输入,从而确定最终的动作或内容。该语音小程序可使设备110输出音频并且/或者呈现对应于所生成的输出数据的文本。然后,设备110可以接收对应于话语的音频并将对应于音频的音频数据发送到一个或多个服务器120。用户辨识部件395可确定说出该话语的成人用户(与儿童不适用输入所源自的儿童用户相关联)。asr部件350可以将音频数据转换成文本数据,并且nlu部件360可确定所述话语对应于可以为儿童用户处理儿童不适用输入的指示。响应于上述的用户辨识部件395和nlu部件360的确定,协调器330可以将nlu结果数据585(或nlu结果数据585中与得分最高的意图数据相关联的一部分)发送到与nlu结果数据585(或其部分)相关联的语音小程序390。
可替代地,如果策略评估部件820确定意图数据在访问策略数据805中被表示,从而表示用户输入的推导意图不适用于当前用户,则协调器部件330可确定与当前调用的设备相关联的成人配置设备。例如,协调器部件330可确定包括当前调用的设备的配置文件数据,并确定包括在相同的配置文件数据中的成人配置设备。协调器部件330也可确定哪个成人配置设备与存在指示符相关联。系统可以基于例如特定设备在过去的阈值量的时间内(例如,在过去的2分钟内)接收用户输入来将该设备与存在指示符相关联,该设备是当前正被驾驶的汽车。为了确保存在指示符与成人用户相关联,系统可确定用户的身份(例如,使用用户辨识处理)并将用户的id与存在指示符相关联。然后,协调器330可使与成人用户和存在指示符相关联的所有设备以及可能不与存在指示符相关联的某些成人设备(例如,智能电话、平板计算机等)输出请求关于系统是否可以处理访问策略数据805中表示的意图数据的输入的通知。如果成人用户指示系统可以处理意图数据,则该系统可执行此类批准的处理。
如果策略评估部件820确定意图数据在访问策略数据805中未被表示,从而表示该意图数据适用于当前用户的年龄范围或年龄,则协调器部件330可以将nlu结果数据585(或nlu结果数据585中与得分最高的意图数据相关联的一部分)发送到与nlu结果数据585(或其部分)相关联的语音小程序390。
协调器部件330还可以向语音小程序390发送附加数据,诸如表示用户年龄范围或年龄的数据1130。语音小程序390可以使用此类数据1130来基于用户年龄等对协调器330不能执行的内容进行附加过滤。例如,如果用户请求播放音乐,则语音小程序390可以提供适用于用户年龄的音乐;如果用户请求问题的答案,则语音小程序390可以提供用户年龄适用的响应;如果用户请求可听地输出故事,则语音小程序390可以提供用户年龄适用的书籍内容;等等。尽管策略评估部件820可确定意图数据适用于用户年龄或年龄范围(例如,基于意图数据在访问策略数据805中未被表示),但策略评估部件820可能无法适当地适于对与意图数据相关联的输出内容进行过滤,而语音小程序390可非常适合。
例如,用户输入可以对应于“给我播放jay-z的音乐。”nlu部件360可确定这样的输入对应于<播放音乐>意图。策略评估部件820可确定<播放音乐>意图数据在访问策略数据805中未被表示,因此指示协调器部件330将nlu结果数据585发送到音乐语音小程序。协调器部件330还可以发送表示用户年龄或年龄范围的音乐语音小程序数据1130。音乐语音小程序可以确定对应于与对应于“jay-z”的艺术家相关联的歌曲的音频数据。通过接收表示用户年龄或年龄范围的数据1130,音乐语音小程序可以对所识别的歌曲音频数据进行过滤,仅剩下不带脏话的那些歌曲音频数据。对音乐音频数据的此类过滤通过策略评估部件820来进行可能是不可能的,并且在没有协调器330向语音小程序390提供表示用户年龄或年龄范围的数据的情况下可能也是不可能的。
访问策略存储装置375中的访问策略可能是仅在某些时段适用的基于时间的策略。例如,这样的访问策略可以指示<播放音乐>意图在成人认为儿童应该做家庭作业的某个时段未被授权。还例如,这样的访问策略可指示与某个设备id相关联的输入不应该在儿童应该睡觉的夜间被处理。时间信息可以包括在发送到访问策略引擎的访问策略数据805中,并且可以在确定当前用户输入是否被授权时由策略评估部件820使用。
协调器部件330可以发送到语音小程序390的附加数据(其可以被包括作为数据1130的一部分)还可以包括指示词(directive)。说明性的指示词可包括:不提供含脏话的内容;打开显式语言过滤;不进行销售交易;关闭购买;不提供政治内容;等等。为了确保附加数据包括可以由语音小程序390操作的指示词,语音小程序390的开发者(或对应技能的开发者)可以为系统提供语音小程序390的执行可以相对的潜在指示词。在确定将哪些指示词发送到语音小程序390时,协调器部件330可考虑从语音小程序/技能开发者接收到的指示词。所述指示词可以被附加到存储在访问策略存储装置375中的访问策略。
可能存在这样的情况,其中语音小程序390基于nlu结果数据585和表示用户年龄或年龄范围的数据确定其不能提供适用于当前用户的内容。例如,如果用户输入对应于“给我播放jay-z的音乐”并且用户为5岁,则语音小程序390可确定其无法提供任何用户适用的音乐(例如,无法提供对应于没有脏话的歌曲的任何音频数据)。在这样的情况下,语音小程序390可以向协调器部件330提供对此类确定的指示,并且协调器部件330可以使预生成的输出文本数据1110和/或对应的输出音频数据1120被呈现给用户。
在其他实现方式中,协调器部件330(或其部件)可被配置为访问地名录484等,并确定意图/词槽组合是否适用于当前用户id和/或设备id。例如,协调器部件330可被配置为确定nlu解析的词槽为“adele”的<播放音乐>意图适用于特定用户id或设备id,而nlu解析的词槽为“jay-z”的<播放音乐>意图不适用于该用户id或设备id。
通过在意图级别或语音小程序级别上实施访问策略引擎810和策略评估部件820,与在用户输入级别的预nlu处理上实施访问策略引擎和策略评估部件820相比,待由访问策略引擎810或策略评估部件820处理的数据的幅度是有限的。这是因为系统被配置有有限数量的意图和语音小程序390,而用户输入可以无穷的变化形式来提供。
尽管如此,在用户输入级别的预nlu处理上实施访问策略引擎810和策略评估部件820可能是有益的。这对于识别儿童用户输入包括被认为不适用于用户年龄或年龄范围的字词(例如,粗话或脏话)来说可能是有益的。如果用户输入起源为输入音频数据311或输入文本数据313,则访问策略引擎810可以接收asr结果数据。访问策略引擎810可以确定与如上所述的用户的用户id、设备id、年龄或年龄范围相关联的访问策略数据805。访问策略数据805可以包括对应于不适当字词的文本数据。策略评估部件820可确定asr结果数据或输入文本数据313中的字词是否在访问策略数据805中表示。如果asr结果数据或输入文本数据313中的字词在访问策略数据805中被表示,则协调器部件330可输出预生成的响应,如上所述。如果asr结果数据或输入文本数据313中的字词在访问策略数据805中未被表示,则nlu部件360可以相对于asr结果数据或输入文本数据313进行处理,并且访问策略引擎810和策略评估部件820可相对于nlu结果数据585进行操作,如上所述。
如所述的,访问策略引擎810和策略评估部件820可在用户输入级别的预nlu处理上操作。即,访问策略引擎810和策略评估部件820可以在用户输入级别上相对于由一个或多个服务器120接收到的每个用户输入来进行操作。可替代地,访问策略引擎810和策略评估部件820可在用户输入级别的后nlu处理上操作。更具体地,访问策略引擎810和策略评估部件820可以在用户输入级别上仅相对于与特定语音小程序(例如,信息提供语音小程序)相关联的nlu结果数据585来进行操作。通过将这样的处理仅限于信息提供(和其他类似的)语音小程序(例如,用户可以使用几乎无限的输入变型来调用的语音小程序),可以防止访问策略引擎810和策略评估部件820在用户输入级别上相对于调用要求更形式主义的输入(因为这样的形式主义的输入不大可能包括粗鲁或脏话内容)的语音小程序(诸如车辆共乘语音小程序、音乐语音小程序等)的用户输入进行操作。
图12是概念性地示出了可以与系统一起使用的设备110的框图。图13是概念性地示出了远程设备(诸如一个或多个服务器120)的示例性部件的框图,该远程设备可帮助进行asr处理、nlu处理等。多个服务器120可以被包括在该系统中,诸如用于执行asr处理的一个或多个服务器120、用于执行nlu处理的一个或多个服务器120,等等。在操作中,这些设备(或设备组)中的每一个可包括驻留在相应设备(110/120)上的计算机可读和计算机可执行指令,如将在下面进一步讨论。
这些设备(110/120)中的每一个可以包括可各自包括用于处理数据和计算机可读指令的中央处理单元(cpu)的一个或多个控制器/处理器(1204/1304),以及用于存储相应设备的数据和指令的存储器(1206/1306)。存储器(1206/1306)可以单独地包括易失性随机存取存储器(ram)、非易失性只读存储器(rom)、非易失性磁阻存储器(mram),和/或其他类型的存储器。每个设备(110/120)还可以包括用于存储数据和控制器/处理器可执行指令的数据存储部件(1208/1308)。每个数据存储部件(1208/1308)可以单独地包括一个或多个非易失性存储装置类型,诸如磁性存储装置、光学存储装置、固态存储装置等。每个设备(110/120)还可以通过相应的输入/输出设备接口(1202/1302)连接到可移除或外部非易失性存储器和/或存储装置(诸如可移除存储卡、存储密钥驱动器、联网存储装置等)。
用于操作每个设备(110/120)及其各种部件的计算机指令可以在运行时使用存储器(1206/1306)作为暂时“工作的”存储装置由相应设备的一个或多个控制器/一个或多个处理器(1204/1304)执行。设备的计算机指令可以非暂时性方式被存储在非易失性存储器(1206/1306)、存储装置(1208/1308)或一个或多个外部设备中。可替代地,除了软件之外或者代替软件,一些或所有的可执行指令还可以被嵌入在相应设备上的硬件或固件中。
每个设备(110/120)包括输入/输出设备接口(1202/1302)。各种部件可通过输入/输出设备接口(1202/1302)连接,如将在下面进一步讨论。此外,每个设备(110/120)可以包括用于在相应设备的部件之间传送数据的地址/数据总线(1224/1324)。除了(或代替)跨总线(1224/1324)连接到其他部件,设备(110/120)内的每个部件也可以直接连接到其他部件。
参考图12,设备110可包括连接到各种部件的输入/输出设备接口1202,所述各种部件诸如音频输出部件,诸如扬声器1212、有线耳机或无线耳机(未示出),或其他能够输出音频的部件。设备110还可以包括音频捕获部件。音频捕获部件可以是,例如,传声器1220或传声器阵列、有线耳机或无线耳机(未示出)等。如果包括传声器阵列,则至声音的原点的大概距离可以通过声学定位基于由该阵列的不同传声器捕获的声音之间的时间和振幅差异来确定。设备110可以另外包括用于显示内容的显示器1216。
经由一个或多个天线1214,输入/输出设备接口1202可以经由无线局域网(wlan)(诸如wifi)电台、蓝牙和/或无线网络电台,诸如能够与诸如长期演进(lte)网络、wimax网络、3g网络、4g网络、5g网络等无线通信网络进行通信的电台,连接到一个或多个网络199。也可以支持有线连接,诸如以太网。通过一个或多个网络199,该系统可以跨联网环境进行分布。i/0设备接口(1202/1302)还可包括允许数据在诸如服务器集合中的不同物理服务器或其他部件等设备之间进行交换的通信部件。
一个或多个设备110和一个或多个服务器120的部件可以包括他们自己的专用处理器、存储器和/或存储装置。可替代地,一个或多个设备110和一个或多个服务器120的部件中的一个或多个可分别利用一个或多个设备110和一个或多个服务器120的i/o接口(1202/1302)、一个或多个处理器(1204/1304)、存储器(1206/1306)和/或存储装置(1208/1308)。因此,针对本文讨论的各种部件,asr部件350可具有其自己的一个或多个i/o接口、一个或多个处理器、存储器和/或存储装置;nlu部件360可以具有其自己的一个或多个i/o接口、一个或多个处理器、存储器和/或存储装置;等等。
如上所述,可以在单个系统中使用多个设备。在这样的多设备系统中,每个设备可以包括用于执行系统处理的不同方面的不同部件。所述多个设备可包括重叠部件。设备110和一个或多个服务器120的部件,如本文所述,是说明性的,并且可定位为独立的设备,或者可以整体或部分地被包括作为更大的设备或系统的部件。
如图14所示,多个设备(110a-110g、120、325)可以包含该系统的部件,并且所述设备可以通过一个或多个网络199连接。一个或多个网络199可以包括本地网络或专用网络,或者可以包括广域网,诸如因特网。设备可以通过有线或无线连接被连接到一个或多个网络199。例如,语音检测设备110a、智能电话110b、智能手表110c、平板计算机110d、车辆110e、显示设备110f和/或智能电视110g可以通过无线服务提供商、通过wifi或蜂窝网络连接等连接到一个或多个网络199。其他设备被包括为网络连接支持设备,诸如一个或多个服务器120、一个或多个语音小程序服务器325等等。支持设备可以通过有线连接或无线连接而连接到一个或多个网络199。联网设备可以使用一个或多个内置或所连接的传声器或其他音频捕获设备来捕获音频,并由asr部件、nlu部件或者相同设备或经由一个或多个网络199连接的另一设备的其他部件(诸如一个或多个服务器120的asr部件350、nlu部件360等)执行处理。
本申请可以关于描述了本申请的各方面的以下条款来理解:
1.一种方法,其包括:
从第一设备接收对应于第一话语的第一音频数据;
接收表示与所述第一设备相关联的第一设备识别符(id)的第一数据;
对所述第一音频数据执行自动语音辨识(asr)处理,以生成第一文本数据;
对所述第一文本数据执行自然语言理解(nlu)处理,以生成包括第一意图数据的第一nlu结果数据;
在对所述第一文本数据执行nlu处理之后,在访问策略存储部件中识别与所述第一设备id相关联的第一访问策略数据,所述第一访问策略数据表示将被限制发送到语音小程序部件的至少一个意图;
确定所述第一意图数据在所述第一访问策略数据中被表示;
在确定所述第一意图数据在所述第一访问策略数据中被表示之后,生成表示所述第一话语被限制进行进一步处理的第二文本数据;
对所述第二文本数据执行文本转语音(tts)处理,以生成对应于所述第二文本数据的第二音频数据;以及
使所述第一设备输出对应于所述第二音频数据的第一音频。
2.如条款1所述的计算机实现方法,其还包括:
从所述第一设备接收对应于第二话语的第二音频数据;
接收表示所述第一设备id的第二数据;
对所述第二音频数据执行asr处理,以生成第二文本数据;
对所述第二文本数据执行nlu处理,以生成包括第二意图数据的第二nlu结果数据;
在对所述第二文本数据执行nlu处理之后,在所述访问策略存储部件中识别与所述第一设备id相关联的所述第一访问策略数据;
确定所述第一访问策略数据允许将所述第二nlu结果数据发送到第一语音小程序部件;
在所述第一访问策略数据允许将所述第二nlu结果数据发送到第一语音小程序部件之后,将所述第二nlu结果数据发送到第一语音小程序部件;以及
从所述第一语音小程序部件接收第一输出数据。
3.如条款1或2所述的计算机实现方法,其还包括:
从所述第一设备接收对应于第二话语的第三音频数据;
接收表示所述第一设备id的第二数据;
对所述第三音频数据执行asr处理,以生成第三文本数据;
对所述第三文本数据执行nlu处理,以生成第二nlu结果数据,所述第二nlu结果数据包括表示与所述第二话语相关联的第一语音小程序部件的第三数据;
在对所述第二文本数据执行nlu处理之后,在所述访问策略存储部件中识别与所述第一设备id相关联的所述第一访问策略数据,所述第一访问策略数据进一步表示被限制接收nlu结果数据的至少一个语音小程序部件;
确定所述第一语音小程序部件在所述第一访问策略数据中被表示;
在确定所述第一语音小程序部件在所述第一访问策略数据中被表示之后,生成表示所述第二话语被限制进行进一步处理的第四音频数据;
使所述第一设备输出对应于所述第四音频数据的第二音频。
4.如条款1、2或3所述的计算机实现方法,其还包括:
从所述第一设备接收对应于第二话语的第三音频数据;
对所述第三音频数据执行asr处理,以生成第三文本数据;
对所述第三文本数据执行nlu处理,以确定所述第二话语对应于将所述第一nlu结果数据发送到与所述第一nlu结果数据相关联的第一语音小程序的指示;
确定表示所述第二音频数据的音频特性;
确定所述音频特性对应于与用户id相关联的所存储音频特性;
确定所述用户id对应于成人用户;以及
基于所述第二话语对应于所述指示以及所述用户id对应于成人用户,将所述第一nlu结果数据发送到所述第一语音小程序。
5.一种系统,其包括:
至少一个处理器;和
至少一个存储器,所述至少一个存储器包括在由所述至少一个处理器执行时使所述系统进行以下操作的指令:
从第一设备接收表示呈自然语言的第一用户输入的第一数据;
接收与和所述第一用户输入相关联的第一识别符(id)相关联的第二数据;
确定表示所述第一用户输入的所述自然语言的含义的第一意图数据;
在访问策略存储部件中至少部分地基于所述第一id来识别第一访问策略数据;
确定所述第一访问策略数据表示所述第一意图数据未被授权给所述第一id;以及
在确定所述第一访问策略数据表示所述第一意图数据未被授权给所述第一id之后,使所述第一设备输出表示所述第一用户输入被限制进行进一步处理的第一内容。
6.如条款5所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定表示所述第二用户输入的第二意图数据;
确定所述第一访问策略数据表示所述第二意图数据被授权给所述第一id;以及
在确定所述第一访问策略数据表示所述第二意图数据被授权给所述第一id之后,相对于所述第二意图数据进行执行。
7.如条款5或6中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从所述第一设备接收对应于第二用户输入的第三数据;
确定所述第二用户输入对应于将所述第一意图数据发送到与所述第一意图数据相关联的第一语音小程序的指示;
确定表示所述第二用户输入的特性;
确定所述特性对应于与用户id相关联的所存储特性;
确定所述用户id对应于成人用户;以及
基于所述指示以及所述用户id对应于成人用户,将所述第一意图数据发送到所述第一语音小程序。
8.如条款5、6或7中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第二用户输入的第二意图数据;
确定表示所述第三数据的特性;
确定所述特性对应于与用户id相关联的所存储特性;
在所述访问策略存储部件中识别与所述用户id相关联的第二访问策略数据;
确定所述第二访问策略数据表示所述第二意图数据未被授权给所述用户id;以及
在确定所述第二访问策略数据表示所述第二意图数据未被授权给所述用户id之后,使所述第二设备输出表示所述第二用户输入被限制进行进一步处理的第二内容。
9.如条款5、6、7或8中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定与所述第二用户输入相关联的语音小程序部件:
确定表示所述第二用户输入的第二意图数据;
确定所述第一访问策略数据表示所述语音小程序部件被授权相对于从所述第一设备接收的用户输入进行处理;以及
在确定所述第二访问策略数据表示所述语音小程序部件未被授权相对于从所述第一设备接收的用户输入进行处理之后,将所述第二意图数据发送到所述语音小程序部件。
10.如条款5、6、7、8或9中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第三数据的特性;
确定所述特性对应于与第一用户id相关联的所存储特性;
确定所述第一用户id是成人用户id;
确定所述成人用户id与第二用户id相关联;
确定所述第二用户id是儿童用户id;
确定所述第三数据指示意图;以及
生成表示所述意图未被授权给所述第二用户id的第二访问策略数据。
11.如条款5、6、7、8、9或10中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第二用户输入的第二意图数据;
确定表示所述第三数据的特性;
确定所述特性对应于与用户年龄范围相关联的所存储特性;
在所述访问策略存储部件中识别与所述用户年龄范围相关联的第二访问策略数据;
确定所述第二访问策略数据表示所述第二意图数据被授权给所述用户年龄范围;以及
在确定所述第二访问策略数据表示所述第二意图数据被授权给所述用户年龄范围之后,相对于所述第二意图数据进行执行。
12.如条款5、6、7、8、9、10或11中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定表示所述第二用户输入的第二意图数据,所述第二意图数据与第一置信度得分相关联;
确定表示所述第二用户输入的第三意图数据,所述第三意图数据与第二置信度得分相关联,所述第二置信度得分小于所述第一置信度得分;
至少部分地基于所述第一置信度得分大于所述第二置信度得分,确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id;
在确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id之后,确定所述第二置信度得分满足置信度得分阈值;以及
在确定所述第二置信度得分满足所述置信度得分阈值之后,确定所述第一访问策略数据表示所述第三意图数据被授权给所述第一id。
13.如条款5、6、7、8、9、10、11或12中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定表示所述第二用户输入的第二意图数据;
确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id;
在确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id之后,确定与所述第二意图数据相关联的第三意图数据;
确定所述第一访问策略数据表示所述第三意图数据被授权给所述第一id;
生成表示所述第三意图数据的第五数据;以及
使所述第一设备输出对应于所述第五数据的第二内容。
14.如条款5、6、7、8、9、10、11、12或13中任一项所述的系统,其中所述至少一个存储器还包括在由所述至少一个处理器执行时进一步使所述系统进行以下操作的指令:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第二用户输入的第二意图数据;
确定表示所述第三数据的特性;
确定所述特性对应于与用户id相关联的所存储特性;
在与所述用户id相关联的用户配置文件数据中确定表示用户的年龄的第四数据;以及
向与所述第二用户输入相关联的语音小程序部件发送:
所述第二意图数据,和
表示所述年龄的第五数据。
15.一种方法,其包括:
从第一设备接收表示呈自然语言的第一用户输入的第一数据;
接收与和所述第一用户输入相关联的第一识别符(id)相关联的第二数据;
确定表示所述第一用户输入的所述自然语言的含义的第一意图数据;
在访问策略存储部件中至少部分地基于所述第一id来识别第一访问策略数据;
确定所述第一访问策略数据表示所述第一意图数据未被授权给所述第一id;以及
在确定所述第一访问策略数据表示所述第一意图数据未被授权给所述第一id之后,使所述第一设备输出表示所述第一用户输入被限制进行进一步处理的第一内容。
16.如条款15所述的方法,其还包括:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定表示所述第二用户输入的第二意图数据;
确定所述第一访问策略数据表示所述第二意图数据被授权给所述第一id;以及
在确定所述第一访问策略数据表示所述第二意图数据被授权给所述第一id之后,相对于所述第二意图数据进行执行。
17.如条款15或16中任一项所述的方法,其还包括:
从所述第一设备接收对应于第二用户输入的第三数据;
确定所述第二用户输入对应于将所述第一意图数据发送到与所述第一意图数据相关联的第一语音小程序的指示;
确定表示所述第二用户输入的特性;
确定所述特性对应于与用户id相关联的所存储特性;
确定所述用户id对应于成人用户;以及
基于所述指示以及所述用户id对应于成人用户,将所述第一意图数据发送到所述第一语音小程序。
18.如条款15、16或17中任一项所述的方法,其还包括:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第二用户输入的第二意图数据;
确定表示所述第三数据的特性;
确定所述特性对应于与用户id相关联的所存储特性;
在所述访问策略存储部件中识别与所述用户id相关联的第二访问策略数据;
确定所述第二访问策略数据表示所述第二意图数据未被授权给所述用户id;以及
在确定所述第二访问策略数据表示所述第二意图数据未被授权给所述用户id之后,使所述第二设备输出表示所述第二用户输入被限制进行进一步处理的第二内容。
19.如条款15、16、17或18中任一项所述的方法,其还包括:
从所述第一设备接收表示第二用户输入的第三数据;
接收与所述第一id相关联的第四数据;
确定表示所述第二用户输入的第二意图数据;
确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id;
在确定所述第一访问策略数据表示所述第二意图数据未被授权给所述第一id之后,确定与所述第二意图数据相关联的第三意图数据;
确定所述第一访问策略数据表示所述第三意图数据被授权给所述第一id;
生成表示所述第三意图数据的第五数据;以及
使所述第一设备输出对应于所述第五数据的第二内容。
20.如条款15、16、17、18或19中任一项所述的方法,其还包括:
从第二设备接收表示第二用户输入的第三数据;
确定表示所述第二用户输入的第二意图数据;
确定表示所述第三数据的特性;
确定所述特性对应于与用户id相关联的所存储特性;
在与所述用户id相关联的用户配置文件数据中确定表示用户的年龄的第四数据;以及
向与所述第二用户输入相关联的语音小程序部件发送:
所述第二意图数据,和
表示所述年龄的第五数据。
本文所公开的概念可以应用于许多不同的设备和计算机系统中,包括例如通用计算系统、语音处理系统和分布式计算环境。
本公开的上述方面旨在是说明性的。上述方面被选去解释本公开的原理和应用,而不是意图为详尽的或限制本公开。所公开的方面的许多修改和变化对本领域技术人员来说是显而易见的。计算机和语音处理领域的普通技术人员应该认识到,本文所述的部件和过程步骤可以是与其他部件或步骤或者部件或步骤的组合可互换的,并且仍然实现本公开的益处和优点。然而,对本领域技术人员显而易见的是,可以在不具有本文公开的这些具体细节和步骤中的一些或全部的情况下实践本公开。
所公开的系统的各方面可被实现为计算机方法或制品,诸如存储器设备或非暂态计算机可读存储介质。所述计算机可读存储介质可为计算机可读取的并且可包括用于使计算机或其他设备执行在本公开中描述的过程的指令。所述计算机可读存储介质可以由易失性计算机存储器、非易失性计算机存储器、硬盘驱动器、固态存储器、闪盘驱动器、可移动磁盘和/或其他介质来实现。此外,系统的部件可以被实现为固件或硬件,诸如声学前端(afe),其包括(除其他事项外)模拟和/或数字滤波器(例如,被配置为至数字信号处理器(dsp)的固件的滤波器)。
除非另外特别说明或在所用上下文中以其它方式被理解,否则如“能够”、“可以”、“可能”、“也许”、“例如”等本文所用的条件语言通常意图传达:某些实施例包括而其他实施例不包括某些特征、元素和/或步骤。因此,此类条件语言通常并非意图暗示特征、元素和/或步骤无论如何都是一个或多个实施例必需的,或者一个或多个实施例必须包括用于在借助和不借助其他输入或提示下决定是否包括这些特征、元素和/或步骤或者是否要在任何特定实施例中执行这些特征、元素和/或步骤的逻辑。术语“包含”、“包括”、“具有”等是同义的且以开放式方式包含性地使用,并且不排除附加元素、特征、动作、操作等等。此外,术语“或”以其包含性意义(而不是以其排他性意义)使用,使得在例如用于连接一系列元素时,术语“或”意指列表中的元素中的一个、一些或所有元素。
除非另有特别说明,否则如短语“x、y、z中的至少一个”等析取语言根据所用上下文通常被理解为表示项目、术语等可以是x、y或z或它们的任意组合(例如,x、y和/或z)。因此,此类析取语言一般不意图也不应暗示某些实施例要求各自存在x中的至少一个、y中的至少一个或z中的至少一个。
如在本公开中使用的,术语“一”或“一个”可以包括一个或多个项目,除非另有特别说明。另外,除非另有特别说明,否则短语“基于”意指“至少部分地基于”。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



