
 商标分类
商标分类  商标转让
商标转让 
语音翻译装置、语音翻译方法以及记录介质与流程
 2021-01-28 17:01:41|
2021-01-28 17:01:41| 306|
306| 起点商标网
起点商标网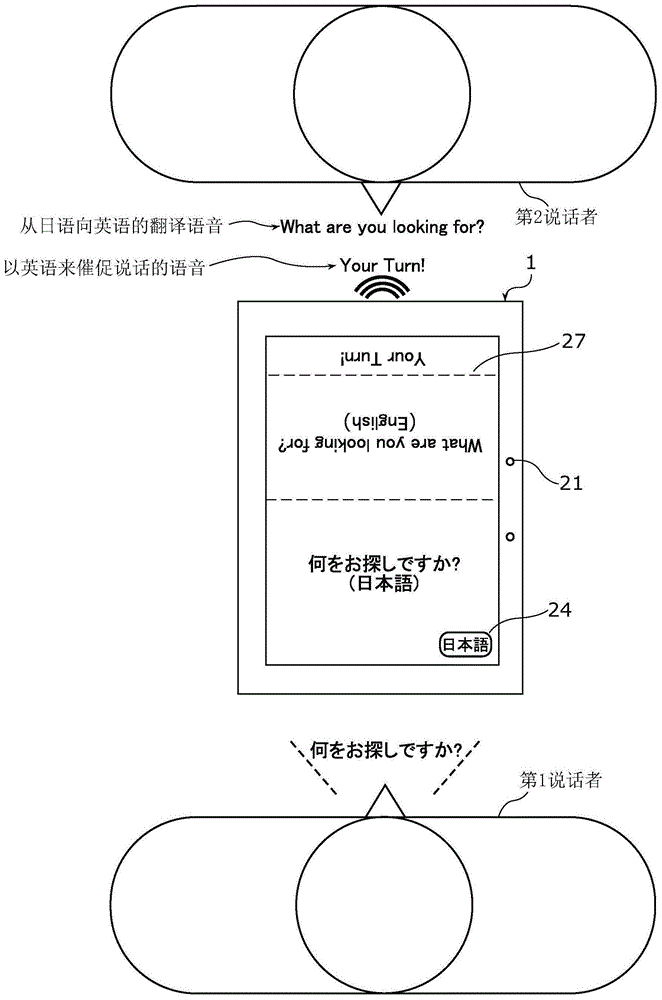
本申请涉及语音翻译装置、语音翻译方法以及记录介质。
背景技术:
例如在专利文献1中公开了一种翻译系统,具备:语音输入部,将第1语言说话者以及第1语言说话者的会话对方即第2语言说话者发出的语音转换为语音数据并输出;输入开关,在第1语言说话者发出语音期间以及第1语言说话者没有发出语音期间都进行声音的输入;语音输出部,对被输入的语音数据进行翻译,将翻译结果转换为语音并输出。
(现有技术文献)
(专利文献)
专利文献1专利第3891023号公报
然而,在专利文献1公开的技术中,在第1说话者以及第2说话者进行会话的情况下,在第1说话者以及第2说话者分别说话时,每当说话时都需要操作输入开关,这样,操作变得繁琐。在第1说话者以及第2说话者进行会话时,由于每次都需要操作输入开关,从而翻译系统的使用频度以及使用期间都会增加。
并且,在第1说话者以及第2说话者彼此对翻译系统进行操作的情况下,翻译系统的非持有者通常不能理解翻译系统的操作方法。因此,在进行翻译系统的操作时会花费功夫,这也将造成翻译系统的使用期间的增大。这样,在以往的翻译系统中存在因使用期间的增大而导致耗费能量的问题。
技术实现要素:
因此,本申请的目的在于提供一种通过简单的操作,就能够抑制语音翻译装置的能量消耗的增大的语音翻译装置、语音翻译方法以及记录介质。
本申请的一个形态所涉及的语音翻译装置,用于第1说话者与第2说话者的会话,所述第1说话者以第1语言说话,所述第2说话者是所述第1说话者的会话对方,并且以与所述第1语言不同的第2语言说话,所述语音翻译装置具备:语音检测部,从被输入到语音输入部的声音中,检测所述第1说话者以及所述第2说话者发出的语音的语音区间;显示部,通过由所述语音检测部检测的语音区间的语音被语音识别,从而所述显示部对该语音所示的所述第1语言被翻译成所述第2语言的翻译结果进行显示,并且,对从所述第2语言翻译成所述第1语言的翻译结果进行显示;以及说话指示部,在所述第1说话者说话后,将催促所述第2说话者说话的内容,经由所述显示部,以所述第2语言来输出,并且,在所述第2说话者说话后,将催促所述第1说话者说话的内容,经由所述显示部,以所述第1语言来输出。
并且,上述这些的一部分的具体的形态可以利用系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等记录介质来实现,也可以通过对系统、方法、集成电路、计算机程序以及记录介质进行任意的组合来实现。
发明效果
通过本申请的语音翻译装置等,能够通过简单的操作,来抑制语音翻译装置的能量消耗的增大。
附图说明
图1a示出了实施方式1中的语音翻译装置的外观、以及第1说话者说话时的第1说话者和第2说话者的语音翻译装置的使用场面的一个例子。
图1b示出了实施方式1中的语音翻译装置的外观、以及第2说话者说话时的第1说话者和第2说话者的语音翻译装置的使用场面的一个例子。
图1c示出了第1说话者和第2说话者在进行会话时的语音翻译装置的使用场面的另外的一个例子。
图2是示出实施方式1中的语音翻译装置的方框图。
图3是示出实施方式1中的语音翻译装置的工作的流程图。
图4是示出实施方式2中的语音翻译装置的方框图。
图5是示出实施方式2中的语音翻译装置的工作的流程图。
图6是示出实施方式2的变形例中的语音翻译装置的工作的流程图。
图7是示出实施方式3中的语音翻译装置的方框图。
图8是示出实施方式3中的语音翻译装置的工作的流程图。
图9是示出实施方式3的变形例中的语音翻译装置的方框图。
图10是示出实施方式4中的语音翻译装置的方框图。
图11是示出实施方式4中的语音翻译装置的工作的流程图。
符号说明
1、1a、1b、1c、1d语音翻译装置
21语音输入部
22语音检测部
23语音识别部
24优先说话输入部
25说话指示部
26翻译部
27显示部
28语音输出部
31声源方向估计部
31a控制部
32输入切换部
41第1波束成形部
42第2波束成形部
具体实施方式
本申请的一个形态所涉及的语音翻译装置,用于第1说话者与第2说话者的会话,所述第1说话者以第1语言说话,所述第2说话者是所述第1说话者的会话对方,并且以与所述第1语言不同的第2语言说话,所述语音翻译装置具备:语音检测部,从被输入到语音输入部的声音中,检测所述第1说话者以及所述第2说话者发出的语音的语音区间;显示部,通过由所述语音检测部检测的语音区间的语音被语音识别,从而所述显示部对该语音所示的所述第1语言被翻译成所述第2语言的翻译结果进行显示,并且,对从所述第2语言翻译成所述第1语言的翻译结果进行显示;以及说话指示部,在所述第1说话者说话后,将催促所述第2说话者说话的内容,经由所述显示部,以所述第2语言来输出,并且,在所述第2说话者说话后,将催促所述第1说话者说话的内容,经由所述显示部,以所述第1语言来输出。
据此,通过从第1说话者与第2说话者的会话中来检测各自的语音区间,从而能够获得将检测到的语音从第1语言翻译为第2语言的翻译结果,并能够获得将检测到的语音从第2语言翻译到所述第1语言的翻译结果。即,在该语音翻译装置中不需要进行用于翻译的输入操作,就能够按照第1说话者和第2说话者的各自的说话,自动地将检测到的语音的语言翻译为其他的语言。
并且,语音翻译装置能够在第1说话者说话后,输出用于催促第2说话者说话的内容,在第2说话者说话后,输出用于催促第1说话者说话的内容。据此,在该语音翻译装置,每当第1说话者和第2说话者各自说话时,无需进行开始说话的输入操作,就能够识别第1说话者与第2说话者说话的时机。
如以上所述,在语音翻译装置,由于无需进行用于开始说话的输入操作、以及用于对语言进行切换的输入操作等,因此具有优越的操作性。即,该语音翻译装置的操作不繁琐,因此能够抑制使用期间的增大。
因此,在语音翻译装置中,通过将操作变得简单,从而能够抑制语音翻译装置的能量消耗的增大。
尤其是在该语音翻译装置中,由于能够使操作变得简单,因此能够抑制误操作。
本申请的其他的形态所涉及的语音翻译方法,用于第1说话者与第2说话者的会话,所述第1说话者以第1语言说话,所述第2说话者是所述第1说话者的会话对方,并且以与所述第1语言不同的第2语言说话,在所述语音翻译方法中包括:从被输入到语音输入部的声音中,检测所述第1说话者以及所述第2说话者发出的语音的语音区间,通过对检测出的语音区间的语音进行语音识别,从而显示部对从该语音所示的所述第1语言被翻译成所述第2语言的翻译结果进行显示,并且对从所述第2语言翻译成所述第1语言的翻译结果进行显示,在所述第1说话者说话之后,将用于催促所述第2说话者说话的内容,经由所述显示部,以所述第2语言来输出,并且,在所述第2说话者说话之后,将用于催促所述第1说话者说话的内容,经由所述显示部,以所述第1语言来输出。
即使在这种语音翻译方法中也能够实现与上述的语音翻译装置相同的作用效果。
并且,本申请的其他的形态所涉及的记录介质是,记录有用于使计算机执行语音翻译方法的程序的计算机可读取的非暂时性的记录介质。
即使在这种记录介质也能够实现与上述的语音翻译装置相同的作用效果。
本申请的其他的形态所涉及的语音翻译装置还具备优先说话输入部,所述优先说话输入部在所述第1说话者或所述第2说话者发出的语音被语音识别的情况下,使进行了该语音识别的所述第1说话者或所述第2说话者发出的语音优先被再次进行语音识别。
据此,例如在第1说话者以及第2说话者进行会话中有说错的情况下,或者含糊不清的语音被翻译到中途的情况下等,通过对优先说话输入部进行操作,从而进行了说话的说话者被优先,进行了说话的该说话者能够再次得到说话的机会(能够重说)。因此,优先说话输入部在第1说话者以及第2说话者的一方的说话者发出的语音被语音识别后,即使移向另一方的说话者的语音的语音识别处理,也能够返回到对一方的说话者发出的语音的语音识别处理。据此,语音翻译装置能够确实地获得第1说话者以及第2说话者的语音,从而能够输出根据该语音而被翻译的翻译结果。
本申请的其他的形态所涉及的语音翻译装置具备:语音输入部,被输入所述第1说话者与所述第2说话者进行会话的语音;语音识别部,通过对由所述语音检测部检测到的语音区间的语音进行语音识别,从而转换为文本文件;翻译部,将由所述语音识别部转换的所述文本文件从所述第1语言翻译成所述第2语言,并且从所述第2语言翻译成所述第1语言;以及语音输出部,将由所述翻译部翻译的结果,通过语音来输出。
据此,能够在输入的语音被语音识别后,将该语音的语言翻译成其他的语言。即,语音翻译装置能够进行从第1说话者与第2说话者的会话的语音的获得到输出翻译语音后的结果为止的处理。因此,语音翻译装置即使不与外部服务器通信,也能够将第1说话者与第2说话者进行会话时的各自的语音彼此翻译。即使在语音翻译装置与外部服务器的通信困难的环境下也能够适用。
在本申请的其他的形态所涉及的语音翻译装置中,所述语音输入部被设置多个,所述语音翻译装置进一步具备:第1波束成形部,通过对被输入到多个所述语音输入部中的至少一部分的语音输入部的语音进行信号处理,从而将收集声音的指向性控制为所述第1说话者的语音的声源方向;第2波束成形部,通过对被输入到多个所述语音输入部中的至少一部分的语音输入部的语音进行信号处理,从而将收集声音的指向性控制为所述第2说话者的语音的声源方向;输入切换部,将获得的信号切换成所述第1波束成形部的输出信号、或所述第2波束成形部的输出信号;以及声源方向估计部,通过对被输入到多个所述语音输入部的语音进行信号处理,从而对声源方向进行估计,所述说话指示部,使所述输入切换部进行或者获得所述第1波束成形部的输出信号、或者获得所述第2波束成形部的输出信号的切换。
据此,通过声源方向估计部,能够估计说话者相对于语音翻译装置的方向。因此,输入切换部能够切换到适于说话者的方向的第1波束成形部的输出信号以及第2波束成形部的输出信号的任一方。即,由于能够使波束成形部的收集声音的指向性朝向声源方向,因此,在语音翻译装置,针对第1说话者以及第2说话者的语音,能够减少周围的噪声来收集声音。
在本申请的其他的形态所涉及的语音翻译装置中,所述语音输入部被设置多个,所述语音翻译装置进一步具备:声源方向估计部,通过对被输入到多个所述语音输入部的语音进行信号处理,来估计声源方向;以及控制部,使所述第1语言显示在,与相对于该语音翻译装置的所述第1说话者的位置对应的所述显示部的区域,使所述第2语言显示在,与相对于该语音翻译装置的所述第2说话者的位置对应的所述显示部的显示区域,所述控制部,对显示方向与由所述声源方向估计部估计的声源方向进行比较,该显示方向是从该语音翻译装置的显示部朝向所述第1说话者或所述第2说话者的显示方向,并且是在所述显示部的某一个显示区域一侧进行显示的方向,在所述显示方向与估计的声源方向实质上一致的情况下,使所述语音识别部以及所述翻译部执行工作,在所述显示方向与估计的声源方向不同的情况下,使所述语音识别部以及所述翻译部的工作停止。
据此,在显示于显示部的显示区域的语言的显示方向、与说话者说话的语音的声源方向实质上一致的情况下,能够确定说话者是以第1语言说话的第1说话者、还是以第2语言说话的第2说话者。在这种情况下,能够对第1说话者的语音以第1语言来进行语音识别、对第2说话者的语音能够以第2语言来进行语音识别。并且,在显示方向与声源方向不同的情况下,通过停止被输入的语音的翻译,从而能够抑制输入的语音没有被翻译或被误翻译。
据此,由于语音翻译装置能够确实地对第1语言的语音以及第2语言的语音进行语音识别,因此能够确实地对语音进行翻译。这样,在该语音翻译装置,由于能够抑制误翻译等,因此能够抑制语音翻译装置的处理量的增大。
在本申请的其他的形态所涉及的语音翻译装置中,在所述控制部使所述语音识别部以及所述翻译部停止工作的情况下,所述说话指示部再次输出催促以指示的语言来说话的内容。
据此,即使在显示方向与声源方向不同的情况下,通过说话指示部再次输出用于催促说话的内容,从而成为对象的说话者开始说话。这样,语音翻译装置能够确实地获得成为对象的说话者的语音,从而能够更确实地对语音进行翻译。
在本申请的其他的形态所涉及的语音翻译装置中,在所述显示方向与估计的声源方向不同的情况下,所述说话指示部在从所述控制部进行比较经过了规定期间之后,再次输出用于催促以指示的语言来说话的内容。
据此,通过从显示方向与声源方向进行比较之后空出规定期间,从而能够抑制第1说话者和第2说话者的语音混在一起被输入。据此,通过在规定期间经过后,再次输出用于催促说话的内容,从而成为对象的说话者开始说话。这样,语音翻译装置能够更确实地获得成为对象的说话者的语音,从而能够更确实地对语音进行翻译。
在本申请的其他的形态所涉及的语音翻译装置中,所述语音输入部被设置多个,所述语音翻译装置进一步具备:第1波束成形部,通过对被输入到多个所述语音输入部中的至少一部分的语音输入部的语音进行信号处理,从而将收集声音的指向性控制为所述第1说话者的语音的声源方向;第2波束成形部,通过对被输入到多个所述语音输入部中的至少一部分的语音输入部的语音进行信号处理,从而将收集声音的指向性控制为所述第2说话者的语音的声源方向;以及声源方向估计部,通过对所述第1波束成形部的输出信号以及所述第2波束成形部的输出信号进行信号处理,从而对声源方向进行估计。
据此,能够通过声源方向估计部来估计说话者相对于语音翻译装置的方向。这样,声源方向估计部能够对适于说话者的方向的第1波束成形部的输出信号以及第2波束成形部的输出信号进行信号处理,从而能够降低因信号处理而产生的运算成本。
在本申请的其他的形态所涉及的语音翻译装置中,所述说话指示部,在该语音翻译装置的启动时,将催促所述第1说话者说话的内容,经由所述显示部,以所述第1语言来输出,在由所述第1说话者发出的语音从所述第1语言被翻译成所述第2语言,且翻译结果被显示到所述显示部之后,将催促所述第2说话者说话的内容,经由所述显示部,以所述第2语言来输出。
据此,只要对在第1说话者以第1语言说话后,由第2说话者以第2语言来说话预先进行注册,这样,在语音翻译装置的启动时,催促第1说话者说话的内容就能够由第1语言输出,第1说话者则能够开始说话。这样,在语音翻译装置的启动时,能够抑制因第2说话者以第2语言进行说话而导致误翻译。
在本申请的其他的形态所涉及的语音翻译装置中,所述说话指示部在翻译开始后,使所述语音输出部将用于催促说话的语音,以规定的次数输出,在所述规定的次数的用于催促说话的语音被输出后,使所述显示部输出用于催促说话的消息。
据此,通过将用于催促说话的语音限制为规定的次数,从而能够抑制语音翻译装置的能量消耗的增大。
在本申请的其他的形态所涉及的语音翻译装置中,所述语音识别部输出对语音进行语音识别后的结果、以及该结果的可靠性分数,所述说话指示部,在从所述语音识别部获得的所述可靠性分数为阈值以下的情况下,不进行所述可靠性分数为阈值以下的语音的翻译,而将催促说话的内容,经由所述显示部以及所述语音输出部的至少一方来输出。
据此,在示出语音识别的精确度的可靠性分数为阈值以下的情况下,通过说话指示部再次输出催促说话的内容,从而,成为对象的说话者再次说话。因此,语音翻译装置能够确实地对成为对象的说话者的语音进行语音识别,从而能够更确实地对语音进行翻译。
尤其是,在由语音输出部通过语音对催促说话的内容进行输出的情况下,说话者能够容易地察觉没有进行正确的语音识别。
另外,上述的一部分的具体形态可以通过系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等记录介质来实现,也可以通过对系统、方法、集成电路、计算机程序或记录介质进行任意的组合来实现。
以下将要说明的实施方式均为示出本申请的一个具体的例子。以下的实施方式所示的数值、形状、材料、构成要素、构成要素的配置位置以及连接形态、步骤、步骤的顺序等均为一个例子,其主旨并非是对本申请进行限定。并且,对于以下的实施方式的构成要素之中的没有记载在独立技术方案中的构成要素,作为任意的构成要素来说明。并且,在所有的实施方式中,都能够对各个内容进行组合。
以下参照附图对本申请的一个形态所涉及的语音翻译装置、语音翻译方法以及记录介质进行具体说明。
(实施方式1)
<构成:语音翻译装置1>
图1a示出了实施方式1中的语音翻译装置1的外观、以及第1说话者说话时的第1说话者和第2说话者的语音翻译装置1的使用场面的一个例子。图1b示出了实施方式1中的语音翻译装置1的外观、以及第2说话者说话时的第1说话者和第2说话者的语音翻译装置1的使用场面的一个例子。
如图1a以及图1b所示,语音翻译装置1是为了第1说话者和第2说话者进行会话,而在第1说话者和第2说话者之间对会话进行双向翻译的装置,在此,第1说话者以第1语言说话,第2说话者是第1说话者的会话对方,以与第1语言不同的第2语言来说话。即,语音翻译装置1是,在第1说话者和第2说话者的两个不同的语言之间,对第1说话者和第2说话者发出的(说出的)各自的语言进行识别,将说话内容翻译成彼此对方的语言的装置。例如,语音翻译装置1将第1说话者说出的第1语言翻译成第2语言并输出,将第2说话者说出的第2语言翻译成第1语言并输出。并且,第1语言以及第2语言例如是日语、英语、法语、德语、汉语等。
在本实施方式的图1a以及图1b示出了,1名第1说话者和1名第2说话者面对面进行会话的样子。另外,也可以用于多名第1说话者和多名第2说话者的会话中。
另外,第1说话者以及第2说话者可以利用语音翻译装置1进行面对面的会话,也可以如图1c所示,左右并排说话。图1c示出了在第1说话者和第2说话者进行会话时的语音翻译装置1的使用场面的其他的一个例子。在这种情况下,语音翻译装置1可以变更显示方式。这种语音翻译装置1如图1a、图1b以及图1c所示,能够以横向或纵向的状态来使用。
语音翻译装置1是智能手机以及平板电脑终端等第1说话者能够携带的便携式终端。
图2是示出实施方式1中的语音翻译装置1的方框图。
如图2所示,语音翻译装置1具备:语音输入部21、语音检测部22、优先说话输入部24、说话指示部25、语音识别部23、翻译部26、显示部27、语音输出部28、电源部29。
[语音输入部21]
语音输入部21是供第1说话者和第2说话者进行会话时的语音输入的传声器,以能够与语音检测部22通信的方式而被连接。即,语音输入部21获得(收集)声音,将获得的声音转换为电信号,将转换的电信号即音响信号输出到语音检测部22。另外,也可以将语音输入部21获得的音响信号存储到存储部等。
另外,语音输入部21也可以作为适配器来构成。在这种情况下,语音输入部21通过传声器被安装在语音翻译装置1来发挥作用,获得通过传声器得到的音响信号。
[语音检测部22]
语音检测部22是从被输入到语音输入部21的声音中,检测第1说话者以及第2说话者说话的语音区间的装置,以能够与语音输入部21以及语音识别部23进行通信的方式来连接。具体而言,语音检测部22根据由从语音输入部21获得的音响信号示出的音量,将音量变大的瞬间与音量变小的瞬间视为语音的分界处,对音响信号中的语音区间的开始时刻以及结束时刻进行检测(检测说话的结束)。在此,语音区间表示说话者的每说出一句话的语音,也可以包括一句话的语音中的开始时刻到结束时刻的期间。
语音检测部22对根据音响信号而检测到的语音区间进行检测,即根据音响信号来检测第1说话者和第2说话者的会话中的各自的语音,将示出检测到的语音的语音信息输出到语音识别部23。
[说话指示部25]
说话指示部25是在第1说话者说话后,将催促第2说话者说话的内容,经由显示部27,通过第2语言来输出,并且,在第2说话者说话后,将催促第1说话者说话的内容,通过第1语言来输出的装置。即,说话指示部25为了第1说话者和第2说话者能够进行会话,而以不同的时机,将催促第1说话者或第2说话者说话的内容即说话指示文本信息输出到显示部27。并且,说话指示部25将催促第1说话者或第2说话者说话的内容即说话指示语音信息输出到语音输出部28。在这种情况下,说话指示部25将与输出到显示部27的说话指示文本信息所示的内容相同的内容的说话指示语音信息输出到语音输出部28。另外,说话指示部25也可以不将说话指示语音信息输出到语音输出部28,通过语音的催促说话的内容的输出并非是必需的。
在此,说话指示文本信息是示出催促第1说话者或第2说话者说话的内容的文本文件。并且,说话指示语音信息是示出催促第1说话者或第2说话者说话的内容的语音。
并且,说话指示部25输出指示命令,该指示命令用于翻译部26将第1语言翻译成第2语言,或者用于翻译部26将第2语言翻译成第1语言。例如,由于在第1说话者说话后,第2说话者将会说话,因此,说话指示部25将用于以第2语言来对第2说话者发出的语音进行语音识别的指示命令输出到语音识别部23,将用于使语音识别后的语音从第2语言翻译成第1语言的指示命令输出到翻译部26。并且,第1说话者说话后的情况也是同样。
并且,说话指示部25在第1说话者以及第2说话者之中的一方说话者说话之后,将用于催促另一方的说话者说话的内容即说话指示文本信息输出到显示部27。在一方的说话者发出的语音由翻译部26翻译后的翻译结果被输出的时刻或输出之后,说话指示部25将说话指示文本信息输出到显示部27,将说话指示语音信息输出到语音输出部28。
并且,说话指示部25在从后述的优先说话输入部24获得指示命令时,针对刚刚说话后的说话者,再次将用于催促说话的内容即说话指示文本信息输出到显示部27,将说话指示语音信息输出到语音输出部28。
并且,说话指示部25在该语音翻译装置1启动时,将催促第1说话者说话的内容,经由显示部27通过第1语言来输出。即在第1说话者为语音翻译装置1的持有者的情况下,说话指示部25催促第1说话者开始说话。并且,说话指示部25在第1说话者发出的语音从第1语言被翻译成第2语言,并且翻译结果被显示到显示部27之后,将催促第2说话者说话的内容,经由显示部27通过第2语言来输出。在使用第1语言的第1说话者的说话被翻译成第2语言之后,第2说话者以第2语言说话,说出的第2语言被翻译成第1语言。通过反复进行这样的工作,第1说话者与第2说话者的会话能够顺利进行。
并且,说话指示部25在翻译开始后,使语音输出部28以规定的次数来输出用于催促说话的语音。也就是说,由于会有第2说话者不马上说话、或没有听清的情况等,因此,说话指示部25以规定的次数来输出用于催促说话的语音。说话指示部25在输出了规定次数的用于催促说话的语音之后,使显示部27输出用于催促说话的消息。也就是说,在以规定的次数输出用于催促说话的语音而没有效果的情况下,为了抑制电力的消耗,而使显示部27显示用于催促说话的消息。
说话指示部25以能够与语音识别部23、优先说话输入部24、翻译部26、显示部27以及语音输出部28进行通信的方式来连接。
[优先说话输入部24]
优先说话输入部24是在第1说话者或第2说话者开始说话并被语音识别的情况下,能够再次使该说话的第1说话者或第2说话者的说话优先(或连续),由语音识别部23进行语音识别的装置。即,优先说话输入部24针对刚刚进行了说话的说话者,也就是说针对说出的语音被进行语音识别的说话者,能够再次给予进行了说话的第1说话者或第2说话者的说话的机会。换而言之,即使第1说话者以及第2说话者的一方的说话者发出的语音的语音识别结束,并且移向用于另一方的说话者的语音的语音识别的处理,优先说话输入部24也能够使处理返回到用于对一方的说话者说出的语音进行语音识别的处理。
优先说话输入部24是用于从语音翻译装置1的操作者接受输入的操作输入部。例如,在开始说话的说话者有说错的情况下,或者含糊不清的语音被翻译到中途的情况下,在语音检测部22不进行语音检测的区间成为规定区间以上时,正如会有语音翻译装置1识别为结束说话的可能性的情况等那样,刚刚开始说话的说话者会有想继续说话的情况。因此,优先说话输入部24使刚刚开始说话的说话者说出的语音优先由语音识别部23进行语音识别,并且使翻译部26翻译。据此,优先说话输入部24将指示命令输出到说话指示部25,该指示命令是用于使说话指示部25再次输出催促说话的内容即说话指示文本信息以及说话指示语音信息。操作者是第1说话者以及第2说话者的至少一方,在本实施方式中为第1说话者。
在本实施方式中,优先说话输入部24是与语音翻译装置1的显示部27被一体设置的触摸传感器。在这种情况下,在语音翻译装置1的显示部27可以显示作为优先说话输入部24的、用于接受一方的说话者的操作的操作键。
在本实施方式中,语音识别部23在将语音识别从第1语言切换到第2语言时,为了使切换前的第1语言优先进行语音识别并被翻译,将作为第1语言的优先键的优先说话输入部24显示到显示部27。并且,语音识别部23在将语音识别从第2语言切换到第1语言时,为了使切换前的第2语言优先进行语音识别并被翻译,将作为第2语言优先键的优先说话输入部24显示到显示部27。这种优先键至少在翻译后被显示到显示部27。
[语音识别部23]
语音识别部23通过对由语音检测部22检测到的语音区间的语音进行语音识别,来转换为文本文件。具体而言,语音识别部23在获得由语音检测部22检测到的语音信息时,对由语音信息示出的语音进行语音识别。例如,在由语音信息示出的语音为第1语言的情况下,用第1语言对该语音进行语音识别,在语音信息示出的语音为第2语言的情况下,用第2语言对该语音进行语音识别。语音识别部23在以第1语言对语音进行语音识别的情况下,生成示出语音识别后的语音的内容的第1文本文件,将生成的第1文本文件输出到翻译部26。并且,语音识别部23在以第2语言对语音进行了语音识别的情况下,生成示出语音识别后的语音的内容的第2文本文件,将生成的第2文本文件输出到翻译部26。
[翻译部26]
翻译部26是翻译装置,将由语音识别部23转换的文本文件从第1语言翻译成第2语言,且从第2语言翻译成第1语言。具体而言,翻译部26在从语音识别部23获得作为文本文件的第1文本文件时,从第1语言翻译成第2语言。即,翻译部26生成将第1文本文件翻译成第2语言的第2翻译文本文件。并且,翻译部26在从语音识别部23获得作为文本文件的第2文本文件时,从第2语言翻译成第1语言。即,翻译部26生成将第2文本文件翻译成第1语言的第1翻译文本文件。
在此,第1语言示出的第1文本文件的内容与第2语言示出的第2翻译文本文件的内容一致。并且,第2语言示出的第2文本文件的内容与第1语言示出的第1翻译文本文件的内容一致。
在翻译部26生成第2翻译文本文件时,对第2翻译文本文件的内容进行识别,生成示出识别的第2翻译文本文件的内容的第2语言的翻译语音。并且,在翻译部26生成第1翻译文本文件时,对第1翻译文本文件的内容进行识别,生成示出识别的第1翻译文本文件的内容的第1语言的翻译语音。另外,基于第1翻译文本文件以及第2翻译文本文件的翻译语音的生成也可以由语音输出部28执行。
在翻译部26生成第2翻译文本文件或第1翻译文本文件时,将生成的第2翻译文本文件或第1翻译文本文件输出到显示部27。并且,在翻译部26生成第2语言的翻译语音、或第1语言的翻译语音被生成时,将生成的第2语言的翻译语音或第1语言的翻译语音输出到语音输出部28。
翻译部26以能够与说话指示部25、语音识别部23、显示部27以及语音输出部28通信的方式而被连接。
[显示部27]
显示部27例如是液晶面板或有机el面板等显示器,以能够与说话指示部25以及翻译部26通信的方式而被连接。具体而言,显示部27是显示器,通过语音检测部22所检测到的语音区间的语音被语音识别,来显示该语音所示的第1语言被翻译成第2语言的翻译结果,并且显示第2语言被翻译成第1语言的翻译结果。显示部27对从翻译部26获得的第1文本文件、第2文本文件、第1翻译文本文件以及第2翻译文本文件进行显示。并且,在显示部27对这些文本文件进行显示后或进行显示的同时,向第1说话者或第2说话者显示用于催促说话的内容即说话指示文本信息。
另外,显示部27按照相对于语音翻译装置1的第1说话者与第2说话者的位置关系,来变更对文本文件进行显示的画面布局。例如图1a以及图1b所示,显示部27在第1说话者说话时,将被语音识别的第1文本文件显示到位于第1说话者一侧的显示部27的显示区域,将翻译后的第2翻译文本文件显示到位于第2说话者一侧的显示部27的显示区域。并且,显示部27在第2说话者说话时,将被语音识别的第2文本文件显示到位于第2说话者一侧的显示部27的显示区域,将翻译后的第1翻译文本文件显示到位于第1说话者一侧的显示部27的显示区域。在上述的情况下,显示部27显示第1文本文件和第2翻译文本文件的文字的朝向,并将第1翻译文本文件和第2文本文件的文字的朝向相反来显示。另外,如图1c所示,在第1说话者与第2说话者左右并排进行会话时,显示部27使第1文本文件和第2文本文件的文字的朝向相同来显示。
[语音输出部28]
语音输出部28是从翻译部26获得作为翻译部26进行翻译后的结果的翻译语音,并对获得的翻译语音进行输出的扬声器,以与翻译部26以及说话指示部25能够通信的方式而被连接。即,语音输出部28在第1说话者进行了说话的情况下,对与被显示在显示部27的第2翻译文本文件相同的内容的翻译语音进行再生并输出。并且,语音输出部28在第2说话者进行了说话的情况下,对与被显示在显示部27的第1翻译文本文件相同的内容的翻译语音进行再生并输出。
并且,语音输出部28在获得说话指示语音信息时,向第1说话者或第2说话者再生并输出作为说话指示语音信息所示的催促说话的内容的语音。语音输出部28在输出第1翻译文本文件或第2翻译文本文件的翻译语音之后,对说话指示语音信息所示的语音进行再生并输出。
[电源部29]
电源部29例如是一次电池或二次电池等,经由布线与语音输入部21、语音检测部22、优先说话输入部24、说话指示部25、语音识别部23、翻译部26、显示部27以及语音输出部28等电连接。电源部29向语音检测部22、优先说话输入部24、说话指示部25、语音识别部23、翻译部26、显示部27以及语音输出部28等提供电力。
<工作>
利用图3对具有以上这种构成的语音翻译装置1的工作进行说明。
图3是示出实施方式1中的语音翻译装置1的工作的流程图。
在语音翻译装置1预先进行如下的设定,第1说话者用第1语言说话,第2说话者用第2语言说话。在此,假定第1说话者以及第2说话者中的一方的说话者先开始说话的情况。第1说话者启动语音翻译装置1,语音翻译装置1开始进行第1说话者以及第2说话者的会话翻译。
首先,如图3所示,在第1说话者与第2说话者进行会话时,在发出语音之前,启动语音翻译装置1。语音翻译装置1获得声音(s11),生成示出获得的声音的音响信号。在本实施方式中,当一方的说话者开始说话时,语音翻译装置1获得一方的说话者发出的语音。如图1a所示,在一方的说话者为第1说话者的情况下,当说出“何をお探しですか?(在找什么?)”时,语音输入部21获得该说出的语音。语音输入部21获得声音,将获得的声音转换为电信号,将转换的电信号即音响信号输出到语音检测部22。
接着,语音检测部22从语音输入部21获得音响信号,通过从音响信号所示的声音中检测一方的说话者的语音区间(s12),从而将检测出的语音作为一方的说话者的语音来提取。作为一个例子,如图1a所示,从被输入到语音输入部21的声音中,检测第1说话者的“何をお探しですか?”这一语音区间,并提取检测到的语音。语音检测部22将示出提取的一方的说话者的语音的语音信息输出到语音识别部23。
说话指示部25将用于以一方的说话者说话的语言进行语音识别的指示命令输出到语音识别部23,并将用于将语音识别后的语音从一方的语言翻译为另一方的语言的指示命令输出到翻译部26。即,说话指示部25输出用于对语音识别部23的识别语言进行切换的指示命令,以使语音识别部23能够对一方的说话者说出的语言进行识别。并且,说话指示部25输出用于对翻译语言进行切换的指示命令,以使翻译部26能够根据由语音识别部23进行语音识别后的语言,来以希望的语言进行翻译。
例如,在语音识别部23获得指示命令时,将识别语言从第2语言切换为第1语言、或将识别语言从第1语言切换为第2语言。并且,翻译部26在获得指示命令时,将翻译语言从第2语言切换到第1语言、或从第1语言切换为第2语言。
接着,语音识别部23在获得指示命令和语音信息时,对由语音信息示出的语音进行语音识别(s13)。例如,在一方的说话者的语言是第1语言的情况下,语音识别部23将识别语言选择为第1语言,以选择的第1语言,对由语音信息示出的语音进行语音识别。即,语音识别部23将语音信息所示的语音转换为第1语言的文本文件,将转换的第1文本文件输出到翻译部26。并且,在一方的说话者的语言为第2语言的情况下,语音识别部23将识别语言选择为第2语言,以选择的第2语言,对语音信息所示的语音进行语音识别。即,语音识别部23将语音信息所示的语音转换为第2语言的文本文件,将转换的第2文本文件输出到翻译部26。
作为一个例子,如图1a所示,语音识别部23将由语音信息示出的语音“何をお探しですか?”转换为第1文本文件“何をお探しですか?”。
接着,翻译部26从语音识别部23获得文本文件,并从第1语言以及第2语言之中的一方的语言翻译为另一方的语言(s14)。即,翻译部26在文本文件为第1语言的第1文本文件时则翻译成第2语言,并生成作为翻译结果的第2翻译文本文件。并且,翻译部26在文本文件为第2语言的第2文本文件时则翻译成第1语言,并生成作为翻译结果的第1翻译文本文件。作为一个例子,如图1a所示,翻译部26将第1语言的第1文本文件“何をお探しですか?”翻译成第2语言,生成第2翻译文本文件“whatareyoulookingfor?”。
接着,翻译部26将生成的第2语言的第2翻译文本文件或第1语言的第1翻译文本文件输出到显示部27。显示部27对第2翻译文本文件或第1翻译文本文件进行显示(s15)。作为一个例子,如图1a所示,显示部27显示第2翻译文本文件“whatareyoulookingfor?”。
并且,翻译部26在第2翻译文本文件被生成时,生成将该第2翻译文本文件转换为语音后的第2语言的翻译语音。并且,翻译部26在第1翻译文本文件被生成时,生成将该第1翻译文本文件转换为语音后的第1语言的翻译语音。翻译部26将生成的第2语言的翻译语音或第1语言的翻译语音输出到语音输出部28。语音输出部28输出第2语言的翻译语音或第1语言的翻译语音(s16)。作为一个例子,如图1a所示,语音输出部28通过语音来输出第2翻译文本文件“whatareyoulookingfor?”。并且,步骤s15以及s16的处理可以在同一个定时来执行,处理也可以是相反的。
接着,说话指示部25判断是否从优先说话输入部24获得了指示命令(s17)。例如,在一方的说话者想再次说话的情况下,语音翻译装置1的操作者对优先说话输入部24进行操作。据此,优先说话输入部24在接受到操作时,将指示命令输出到说话指示部25。
在说话指示部25从优先说话输入部24获得了指示命令的情况下(s17的“是”),语音识别部23以及翻译部26即使在一方的说话者的语音识别以及翻译的处理结束以及中断、或移向用于对另一方的说话者的语音进行语音识别的处理的情况下,也能够返回到对一方的说话者说出的语音进行语音识别以及翻译的处理。说话指示部25针对刚刚说出的语音被语音识别了的一方的说话者,为了使该一方的说话者说出的语音优先进行语音识别,从而再次将催促一方的说话者说话的内容即说话指示文本信息输出到显示部27。显示部27对从说话指示部25获得的说话指示文本信息进行显示(s18)。作为一个例子,显示部27对说话指示文本信息“もう一度発話して下さい(请再说一遍)”进行显示。
并且,在说话指示部25从优先说话输入部24获得了指示命令的情况下,将催促一方的说话者说话的内容即说话指示语音信息输出到语音输出部28。语音输出部28通过语音来输出从说话指示部25获得的说话指示语音信息(s19)。作为一个例子,语音输出部28通过语音来输出说话指示语音信息“もう一度発話して下さい”。
在这种情况下,语音翻译装置1针对另一方的说话者显示“thankyouforyourpatience.”等,可以通过语音来输出,也可以什么都不输出。另外,步骤s18、s19的处理可以同时进行,处理也可以相反。
并且,说话指示部25也可以将说话指示语音信息以规定的次数输出到语音输出部28。说话指示部25在以规定的次数输出了说话指示语音信息之后,也可以使显示部27输出说话指示语音信息的消息。
于是,语音翻译装置1结束处理。据此,一方的说话者通过再次说话,从而语音翻译装置1能够从步骤s11开始处理。
另外,说话指示部25在没能从优先说话输入部24获得指示命令的情况下(s17的“否”),将催促另一方的说话者说话的内容即说话指示文本信息输出到显示部27。例如,这种情况是一方的说话者没有必要再次进行说话,语音被正确识别的情况。显示部27对从说话指示部25获得的说话指示文本信息进行显示(s21)。作为一个例子,如图1a所示,显示部27显示说话指示文本信息“yourturn!”。
并且,在说话指示部25不能从优先说话输入部24获得指示命令的情况下,将催促另一方的说话者说话的内容即说话指示语音信息输出到语音输出部28。语音输出部28通过语音来输出从说话指示部25获得的说话指示语音信息(s22)。作为一个例子,语音输出部28通过语音来输出说话指示语音信息“yourturn!”。另外,步骤s21、s22的处理可以同时进行,也可以相反。
并且,说话指示部25也可以将用于催促说话的语音,以规定的次数输出到语音输出部28。说话指示部25也可以在用于催促说话的语音以规定的次数输出后,使用于催促说话的消息输出到显示部27。
于是,语音翻译装置1结束处理。据此,通过一方的说话者再次说话,语音翻译装置1从步骤s11开始处理。
这样,通过第1说话者首先操作语音翻译装置1,语音翻译装置1就能够对第1说话者与第2说话者的会话进行翻译。
另外,由于另一方的说话者针对一方的说话者的说话的处理与上述相同,因此省略其说明。
<作用效果>
接着,对本实施方式中的语音翻译装置1的作用效果进行说明。
如以上所述,本实施方式中的语音翻译装置1用于对第1说话者与第2说话者的会话进行翻译,第1说话者以第1语言说话,第2说话者是第1说话者的会话对方,以与第1语言不同的第2语言说话,语音翻译装置1具备:语音检测部22,从被输入到语音输入部21的声音中,检测第1说话者以及第2说话者发出的语音的语音区间;显示部27,通过由语音检测部22检测到的语音区间的语音被语音识别,从而显示部27对该语音所示的第1语言被翻译成第2语言的翻译结果进行显示,并且,对从第2语言翻译成第1语言的翻译结果进行显示;说话指示部25,在第1说话者说话后,将催促第2说话者说话的内容,经由显示部27,以第2语言来输出,并且,在第2说话者说话后,将用于催促第1说话者说话的内容,经由显示部27,由第1语言来输出。
据此,通过从第1说话者与第2说话者的会话中检测各自的语音区间,从而能够获得将检测到的语音从第1语言翻译成第2语言的翻译结果,以及将检测到的语音从第2语言翻译到第1语言的翻译结果。即,在该语音翻译装置1中,即使不进行用于翻译的输入操作,也能够按照第1说话者与第2说话者各自的说话,来自动地将检测到的语音的语言翻译成其他的语言。
并且,语音翻译装置1通过在第1说话者说话之后,输出催促第2说话者说话的内容,从而能够在第2说话者说话之后,输出催促第1说话者说话的内容。据此,在该语音翻译装置1中可以不必按照第1说话者与第2说话者的各自的说话来进行开始说话的输入操作,就能够识别第1说话者与第2说话者的说话时机。
这样,在语音翻译装置1可以不必进行用于开始说话的输入操作、或者用于语言切换的输入操作等,从而具有良好的操作性。即,该语音翻译装置1的操作简便,因此能够抑制使用期间的增大。
因此,在语音翻译装置1通过简单的操作,就能够抑制语音翻译装置1的能量消耗的增大。尤其是在该语音翻译装置1由于能够使操作简单,因此能够抑制误操作。
并且,本实施方式中的语音翻译方法用于第1说话者与第2说话者的会话,第1说话者第1语言说话,第2说话者是第1说话者的会话对方,以与第1语言不同的第2语言说话,在该语音翻译方法中包括:从被输入到语音输入部21的声音中,检测第1说话者以及第2说话者发出的语音的语音区间;通过检测到的语音区间的语音被语音识别,从而显示部27对该语音所示的第1语言被翻译成第2语言的翻译结果进行显示,并且,对从第2语言翻译成第1语言的翻译结果进行显示;在第1说话者说话后,将催促第2说话者说话的内容,经由显示部27,以第2语言来输出,并且,在第2说话者说话后,将用于催促第1说话者说话的内容,经由显示部27,由第1语言来输出。
即使在该语音翻译方法中,也能够实现与上述的语音翻译装置1相同的作用效果。
并且,本实施方式中的记录介质为记录有用于使计算机执行语音翻译方法的程序的计算机可读取的非暂时性的记录介质。
即使在该记录介质,也能够实现与上述的语音翻译装置1同样的效果。
本实施方式中的语音翻译装置1进一步具备优先说话输入部24,在第1说话者或第2说话者说话并被语音识别的情况下,使第1说话者或第2说话者发出的语音优先被再次进行语音识别。
据此,例如在第1说话者以及第2说话者等说话者有说错的情况下,或者含糊不清的语音被翻译途中等情况下,通过对优先说话输入部24进行操作,从而能够使进行了说话的说话者优先,这样,进行了说话的该说话者能够再次得到说话的机会(能够再次重新进行说话)。为此,优先说话输入部24即使在第1说话者以及第2说话者的一方的说话者发出的语音的语音识别结束后,处理移向用于另一方的说话者的语音的语音识别的处理,也能够返回到对一方的说话者说出的语音进行语音识别的处理。据此,由于语音翻译装置1能够确实地获得第1说话者以及第2说话者的语音,因此能够输出根据该语音进行翻译的翻译结果。
本实施方式中的语音翻译装置1进一步具备:语音输入部21,被输入第1说话者与第2说话者进行会话的语音;语音识别部23,通过对由语音检测部22检测到的语音区间的语音进行语音识别,从而转换为文本文件;翻译部26,将由语音识别部23转换后的文本文件从第1语言翻译成第2语言,并且,从第2语言翻译成第1语言;语音输出部28,将翻译部26翻译的结果通过语音来输出。
据此,能够在对被输入的语音进行语音识别后,将该语音的语言翻译成其他的语言。即,语音翻译装置1能够进行从第1说话者与第2说话者进行会话的语音的获得,到输出翻译语音后的结果为止的处理。因此,语音翻译装置1即使不与外部服务器通信,也能够对第1说话者与第2说话者会话时的各自的语音相互进行翻译。即使在语音翻译装置1与外部服务器通信困难的环境下也能够适用。
在本实施方式中的语音翻译装置1,说话指示部25在该语音翻译装置1的启动时,将催促第1说话者说话的内容,经由显示部27,以第1语言来输出,由第1说话者说出的语音从第1语言被翻译到第2语言,在翻译结果被显示到显示部27之后,将用于催促第2说话者说话的内容,经由显示部27,以第2语言来输出。
据此,在第1说话者以第1语言说话后,以第2语言预先将第2说话者的说话进行注册,这样,在语音翻译装置1的启动时,当催促第1说话者说话的内容以第1语言被输出时,第1说话者就能够开始说话。因此,在语音翻译装置1的启动时,能够抑制因第2说话者以第2语言进行说话而造成的误翻译。
在本实施方式中的语音翻译装置1中,说话指示部25在翻译开始后,使语音输出部28以规定的次数对用于催促说话的语音进行输出,在用于催促说话的语音以规定的次数的输出结束后,使显示部27输出用于催促说话的消息。
据此,通过以规定的次数来停止用于催促说话的语音,因此,能够抑制语音翻译装置1的能量消耗的增大。
(实施方式2)
<构成>
利用图4对本实施方式的语音翻译装置1a的构成进行说明。
图4是示出实施方式2中的语音翻译装置1a的方框图。
在本实施方式中,对声源方向进行估计之处与实施方式1不同。
关于本实施方式中的其他的构成,在没有特殊记载的情况下,与实施方式1相同,并且对于相同的构成赋予相同的符号,并省略详细说明。
如图4所示,语音翻译装置1a除了语音检测部22、优先说话输入部24、说话指示部25、语音识别部23、翻译部26、显示部27、语音输出部28以及电源部29以外,还具备多个语音输入部21、以及声源方向估计部31。
[多个语音输入部21]
多个语音输入部21构成传声器阵列。具体而言,传声器阵列由彼此分离配置的2个以上的传声器单元构成,获得语音,并从获得的语音中获得被转换为电信号的音响信号。
多个语音输入部21将获得的音响信号输出到声源方向估计部31。并且,多个语音输入部21的至少一个将音响信号输出到语音检测部22。在本实施方式中,一个语音输入部21与语音检测部22以能够通信的方式来连接,将音响信号输出到语音检测部22。
在本实施方式中,在语音翻译装置1a设置了两个语音输入部21。一方的语音输入部21与另一方的语音输入部21,以语音的1/2波长以下的距离隔开的状态而被配置。
[声源方向估计部31]
声源方向估计部31通过对被输入到多个语音输入部21的语音进行信号处理,来估计声源方向。具体而言,声源方向估计部31在获得了来自语音检测部22的语音信息、和来自多个语音输入部21的音响信号时,算出到达构成传声器阵列的多个语音输入部21的每一个的语音的时间差(相位差),例如通过延迟时间估计法等来估计声源方向。即,只要语音检测部22能够检测语音区间,就意味着第1说话者或第2说话者的语音被输入到语音输入部21,声源方向估计部31以语音信息的获得作为触发,来开始声源方向的估计。
声源方向估计部31将示出估计的结果即声源方向的声源方向信息,输出到说话指示部25。
[说话指示部25]
说话指示部25具有控制部31a,对使显示部27进行显示的状态进行控制。具体而言,控制部31a使第1语言显示在与相对于语音翻译装置1a的第1说话者的位置对应的显示部27的显示区域,使第2语言显示在与相对于语音翻译装置1a的第2说话者的位置对应的显示部27的显示区域。例如图1a所示,与第1说话者的位置对应的显示部27的显示区域是,以日语显示的第1说话者一侧的显示部27的显示区域。并且,与第2说话者的位置对应的显示部27的显示区域是,以英语显示的第2说话者一侧的显示部27的显示区域。
控制部31a对显示方向与声源方向估计部31所估计的声源方向进行比较,所述显示方向是从该语音翻译装置1a的显示部27朝向第1说话者或第2说话者的显示方向,并且是在显示部27的某一个显示区域一侧进行显示的方向。控制部31a在显示方向与声源方向实质上一致的情况下,使语音识别部23以及翻译部26执行工作。例如图1a所示,当第1说话者说话时,示出被输入到语音翻译装置1a的第1说话者的语音的内容的第1文本文件,被显示在第1说话者侧(或面对第1说话者一侧)的显示区域。在这种情况下,显示方向为从显示部27朝向第1说话者的方向,由声源方向估计部31估计的声源方向也是从显示部27朝向第1说话者的方向。
另外,控制部31a在显示方向与声源方向不同的情况下,使语音识别部23以及翻译部26的工作停止。当第1说话者说话时,即使示出第1说话者的语音的内容的第1文本文件被显示在第1说话者侧的显示区域,在声源方向估计部31所估计的声源方向为从显示部27朝向第2说话者的方向的情况下,显示方向与估计的声源方向也会不一致。例如,在第1说话者说话后,第1说话者不操作优先说话输入部24而继续进行说话的情况下,会有与会话无关的周围的声音被收集到语音输入部21的情况等。
并且,在控制部31a使语音识别部23以及翻译部26停止工作的情况下,说话指示部25再次输出以指示的语言进行的催促说话的内容。例如,由于显示方向与估计的声源方向不一致,因此不知道是哪一方的说话者进行了说话,语音识别部23则不知道是以第1语言来对语音进行语音识别、还是以第2语言来进行语音识别。并且,即使第1说话者进行了说话,也有不能对其语音进行语音识别的情况,从而不能进行翻译。因此,控制部31a使语音识别部23以及翻译部26停止工作。
<工作>
利用图5对具有以上这种构成的语音翻译装置1a的工作进行说明。
图5是示出实施方式2中的语音翻译装置1a的工作的流程图。
关于与图3同样的处理赋予相同的符号,并适宜地省略说明。
语音翻译装置1a获得声音(s11),生成示出获得的声音的音响信号。
接着,声源方向估计部31判断是否从语音检测部22获得了语音信息(s12a)。
声源方向估计部31在没有从语音检测部22获得语音信息的情况下(s12a的“否”),由于是语音检测部22不能从音响信号检测到语音的情况,因此,声源方向估计部31不能获得语音信息。也就是说,是第1说话者以及第2说话者没有进行会话的情况。在这种情况下,反复步骤s12a的处理。
在声源方向估计部31从语音检测部22获得了语音信息的情况下(s12a的“是”),是第1说话者以及第2说话者的至少一方说话了的情况。在这种情况下,声源方向估计部31算出从多个语音输入部21的每一个获得的音响信号中包含的语音的时间差(相位差),对声源方向进行估计(s31)。声源方向估计部31将示出作为估计的结果的声源方向的声源方向信息输出到说话指示部25。
接着,声源方向估计部31的控制部31a判断显示方向与估计的声源方向实质上是否一致(s32)。
控制部31a在显示方向与声源方向不同的情况下(s32的“否”),使语音识别部23以及翻译部26的工作停止。在控制部31a使语音识别部23以及翻译部26工作停止的情况下,说话指示部25再次输出以指示的语言进行的催促说话的内容。
具体而言,说话指示部25将用于催促一方的说话者说话的内容的说话指示文本信息,输出到显示部27。显示部27对从说话指示部25获得的说话指示文本信息进行显示(s33)。
并且,说话指示部25将用于催促一方的说话者说话的内容的说话指示语音信息输出到语音输出部28。语音输出部28以语音来输出从说话指示部25获得的说话指示语音信息(s34)。
于是,语音翻译装置1a结束处理。据此,通过一方的说话者再次进行说话,从而语音翻译装置1a从步骤s11开始处理。
控制部31a在显示方向与声源方向实质上一致的情况下(s32的“是”),使语音识别部23以及翻译部26执行工作。于是,语音翻译装置1a进入步骤s13,进行与图3同样的处理。
<作用效果>
接着,对本实施方式中的语音翻译装置1a的作用效果进行说明。
如以上所述,在本实施方式中的语音翻译装置1a,语音输入部21被设置多个。并且,语音翻译装置1a进一步具备:声源方向估计部31,通过对被输入到多个语音输入部21的语音进行信号处理,来估计声源方向;以及控制部31a,使第1语言显示在,与相对于该语音翻译装置1a的第1说话者的位置对应的显示部27的显示区域,使第2语言显示在与相对于该语音翻译装置1a的第2说话者的位置对应的显示部27的显示区域。于是,控制部31a对显示方向与声源方向估计部31估计的声源方向进行比较,在显示方向与声源方向实质上一致的情况下,使语音识别部23以及翻译部26执行工作,在显示方向与声源方向不一致的情况下,使语音识别部23以及翻译部26停止工作,所述显示方向是从该语音翻译装置1a的显示部27朝向第1说话者或第2说话者的显示方向,并且是在显示部27的某一个显示区域一侧进行显示的方向。
据此,在被显示在显示部27的显示区域的语言的显示方向、与说话者发出的语音的声源方向实质上一致的情况下,能够确定说话者是以第1语言说话的第1说话者、还是以第2语言说话的第2说话者。在这种情况下,能够以第1语言来对第1说话者的语音进行语音识别,以第2语言来对第2说话者的语音进行语音识别。并且,在显示方向与声源方向不同的情况下,通过停止被输入的语音的翻译,从而能够抑制输入的语音没有被翻译或被误翻译。
据此,由于语音翻译装置1a能够确实地对第1语言的语音以及第2语言的语音进行语音识别,因此,能够确实地对语音进行翻译。这样,在该语音翻译装置1a,通过抑制误翻译等,从而能够抑制语音翻译装置1a的处理量的增大。
在本实施方式中的语音翻译装置1a,在控制部31a使语音识别部23以及翻译部26停止工作的情况下,说话指示部25再次输出以指示的语言进行的催促说话的内容。
据此,即使在显示方向与声源方向不同的情况下,通过说话指示部25再次输出用于催促说话的内容,从而成为对象的说话者开始说话。因此,语音翻译装置1a能够确实地获得成为对象的说话者的语音,这样,能够更确实地对语音进行翻译。
即使在本实施方式中的语音翻译装置1a,也能够实现与实施方式1同样的作用效果。
(实施方式2的变形例)
关于本变形例中的其他的构成,在没有特殊记载的情况下,与实施方式1同样,对于相同的构成赋予相同的符号,并省略与相同的构成有关的详细说明。
利用图6对这种构成的语音翻译装置1a的工作进行说明。
图6是示出实施方式2的变形例中的语音翻译装置1a的工作的流程图。
关于与图5相同的处理,赋予相同的符号,并适宜地省略说明。
在语音翻译装置1a的处理中,在经过了步骤s11至s31的处理之后,在步骤s32为“否”的情况下,控制部31a判断在显示方向与声源方向的比较后是否经过了规定期间(s32a)。
控制部31a在显示方向与声源方向的比较之后没有经过规定期间的情况下(s32a的“否”),将处理返回到步骤s32a。
控制部31a在显示方向与声源方向的比较之后经过了规定期间的情况下(s32a的“是”),处理进入步骤s33,进行与图5相同的处理。
这样,在本变形例中的语音翻译装置1a,在显示方向与声源方向不同的情况下,说话指示部25在控制部31a进行比较之后经过了规定期间之后,再次输出以指示的语言进行的催促说话的内容。
据此,通过空出显示方向与声源方向的比较之后的规定期间,从而能够抑制第1说话者与第2说话者的语音被混在一起输入。据此,通过在规定期间后,再次输出用于催促说话的内容,从而,成为对象的说话者开始说话。这样,语音翻译装置1a能够更确实地获得成为对象的说话者的语音,从而能够更确实地对语音进行翻译。
即使在本变形例中的语音翻译装置1a,也能够实现与实施方式2同样的作用效果。
(实施方式3)
<构成>
利用图7对本实施方式的语音翻译装置1b的构成进行说明。
图7是示出实施方式3中的语音翻译装置1b的方框图。
本实施方式与实施方式1等不同之处是声源方向的估计。
关于本实施方式中的其他的构成,在没有特殊记载的情况下,与实施方式1等相同,对于相同的构成赋予相同的符号,并省略有关相同的构成的详细说明。
语音翻译装置1b除了具备语音检测部22、优先说话输入部24、说话指示部25、语音识别部23、翻译部26、显示部27、语音输出部28、电源部29以及声源方向估计部31以外,还具备多个语音输入部21、第1波束成形部41、第2波束成形部42、以及输入切换部32。
[多个语音输入部21]
多个语音输入部21构成传声器阵列。多个语音输入部21的每一个将获得的音响信号输出到第1波束成形部41以及第2波束成形部42。在本实施方式中,以采用两个语音输入部21为例。
[第1波束成形部41以及第2波束成形部42]
第1波束成形部41通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音的音响信号进行信号处理,从而将收集声音的指向性控制为第1说话者的语音的声源方向。并且,第2波束成形部42通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音的音响信号进行信号处理,从而将收集声音的指向性控制成第2说话者的语音的声源方向。在本实施方式中,第1波束成形部41以及第2波束成形部42对从多个语音输入部21的每一个获得的音响信号进行信号处理。
据此,通过第1波束成形部41以及第2波束成形部42将收集声音的指向性控制为规定方向,从而能够抑制规定方向以外的声音的输入。规定方向例如是第1说话者以及第2说话者各自说话时的各自的语音的声源方向。
在本实施方式中,第1波束成形部41被配置在第1说话者一侧,以能够与多个语音输入部21的每一个通信的方式来连接,第2波束成形部42被配置在第2说话者一侧,以能够与多个语音输入部21的每一个通信的方式来连接。第1波束成形部41以及第2波束成形部42分别对从多个语音输入部21的每一个获得的音响信号进行信号处理,并将作为该信号处理的结果的音响处理信号输出到输入切换部32。
[说话指示部25]
说话指示部25使输入切换部32进行或者获得第1波束成形部41的输出信号、或者获得第2波束成形部42的输出信号的切换。具体而言,说话指示部25在从声源方向估计部31获得了示出作为估计的结果的声源方向的声源方向信息时,对声源方向信息所示的声源方向、与波束成形部的收集声音的指向性即规定方向进行比较。说话指示部25选择声源方向与规定方向实质上一致或接近的方向的波束成形部。
说话指示部25以输出从第1波束成形部41以及第2波束成形部42选择的波束成形部的输出信号的方式,将切换命令输出到输入切换部32。
[输入切换部32]
输入切换部32是获得第1波束成形部41的输出信号以及第2波束成形部42的输出信号,并对输出到语音检测部22的输出信号进行切换的装置。输入切换部32将获得的信号切换为第1波束成形部41的输出信号、或第2波束成形部42的输出信号。具体而言,输入切换部32通过获得来自说话指示部25的切换命令,从而,从第1波束成形部41的输出信号切换为第2波束成形部42的输出信号、或从第2波束成形部42的输出信号切换为第1波束成形部41的输出信号。输入切换部32通过切换命令,将第1波束成形部41的输出信号输出到语音检测部22,或者将第2波束成形部42的输出信号输出到语音检测部22。
输入切换部32以能够与第1波束成形部41、第2波束成形部42、语音检测部22以及说话指示部25通信的方式而被连接。
<工作>
对以上这种构成的语音翻译装置1b的工作进行说明。
图8是示出实施方式3中的语音翻译装置1b的工作的流程图。
对于与图5等相同的处理赋予相同的符号,并适宜地省略说明。
如图8所示,在语音翻译装置1b的处理中,在经过了步骤s11、s12a、s31以及s32的处理之后,在控制部31a判断为显示方向与声源方向实质上一致的情况下(s32的“是”),说话指示部25将切换命令输出到输入切换部32(s51)。
具体而言,在第1说话者与第2说话者进行了说话的前提下,在两个语音输入部21,第1波束成形部41针对第1说话者的说话的灵敏度比第2说话者的高,第2波束成形部42针对第2说话者的说话的灵敏度比第1说话者高。
因此,若显示方向是第1说话者侧的显示部27的显示区域,第1波束成形部41就能够对第1说话者的说话具有高的灵敏度,这样,说话指示部25将切换命令输出到输入切换部32,以使第1波束成形部41的输出信号被输出。在这种情况下,当输入切换部32获得切换命令时,则输出第1波束成形部41的输出信号。
并且,若显示方向是第2说话者侧的显示部27的显示区域,则第2波束成形部42就能够对第2说话者的说话具有高的灵敏度,这样,说话指示部25将切换命令输出到输入切换部32,以使第2波束成形部42的输出信号被输出。在这种情况下,当输入切换部32获得切换命令时,则输出第2波束成形部42的输出信号。
于是,语音翻译装置1b进入步骤s12,进行与图5同样的处理。
<作用效果>
接着,对本实施方式中的语音翻译装置1b的作用效果进行说明。
如以上所示,在本实施方式中的语音翻译装置1b中,语音输入部21被设置多个。并且,语音翻译装置1b进一步具备:第1波束成形部41,通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音进行信号处理,从而将收集声音的指向性控制为第1说话者的语音的声源方向;第2波束成形部42,通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音进行信号处理,从而将收集声音的指向性控制为第2说话者的语音的声源方向;输入切换部32,将获得的信号切换成第1波束成形部41的输出信号、或第2波束成形部42的输出信号;以及声源方向估计部31,通过对被输入到多个语音输入部21的语音进行信号处理,从而对声源方向进行估计。于是,说话指示部25使输入切换部32进行或者获得第1波束成形部41的输出信号、或者获得第2波束成形部42的输出信号的切换。
据此,能够通过声源方向估计部31,来对说话者相对于语音翻译装置1b的方向进行估计。因此,输入切换部32能够切换成适于说话者的方向的第1波束成形部41的输出信号以及第2波束成形部42的输出信号任一个。即,由于能够使波束成形部的收集声音的指向性朝向声源方向,因此,在语音翻译装置1b针对第1说话者以及第2说话者的语音能够减少周围的噪声来收集声音。
即使在本实施方式中的语音翻译装置1b,也能够实现与实施方式1等同样的作用效果。
(实施方式3的变形例)
利用图9对本变形例的语音翻译装置1c进行说明。
图9是示出实施方式3的变形例中的语音翻译装置1c的方框图。
关于本变形例中的其他的构成,在没有特殊的记载的情况下,与实施方式1等相同,对于相同的构成赋予相同的符号,并省略与相同的构成有关的详细说明。
如图9所示,第1波束成形部41以及第2波束成形部42以能够与多个语音输入部21的每一个通信的方式来连接,且以能够与声源方向估计部31以及输入切换部32通信的方式来连接。
在第1波束成形部41以及第2波束成形部42被输入来自多个语音输入部21的每一个的音响信号。第1波束成形部41以及第2波束成形部42通过对被输入的每个音响信号进行信号处理,从而将作为信号处理的结果的每个音响处理信号输出到声源方向估计部31以及输入切换部32。
即,在本变形例中,多个语音输入部21的每一个以能够与第1波束成形部41以及第2波束成形部42通信的方式来连接,与声源方向估计部31以不能通信的方式来连接。
这样,在声源方向估计部31,通过第1波束成形部41以及第2波束成形部42,被输入针对说话者的语音的声源方向的收集声音的指向性高的音响信号。
并且,在本变形例中的语音翻译装置1c,语音输入部21被设置多个。并且,语音翻译装置1c进一步具备:第1波束成形部41,通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音进行信号处理,从而将收集声音的指向性控制为第1说话者的语音的声源方向;第2波束成形部42,通过对被输入到多个语音输入部21中的至少一部分的语音输入部21的语音进行信号处理,从而将收集声音的指向性控制为第2说话者的语音的声源方向;以及声源方向估计部31,通过对第1波束成形部41的输出信号、以及第2波束成形部42的输出信号进行信号处理,从而对声源方向进行估计。
据此,能够由声源方向估计部31来估计相对于说话者的方向。因此,声源方向估计部31对适于说话者的方向的第1波束成形部41的输出信号以及第2波束成形部42的输出信号进行信号处理,从而能够降低信号处理的运算成本。
即使在本变形例中的语音翻译装置1c,也能够实现与上述的实施方式1等相同的作用效果。
(实施方式4)
<构成>
利用图10对本实施方式的语音翻译装置1d的构成进行说明。
图10是示出实施方式4中的语音翻译装置1d的方框图。
本实施方式与实施方式1等不同之处是,语音翻译装置1d具有分数计算部43。
关于本实施方式中的构成,在没有特殊记载的情况下,与实施方式1等相同,针对相同的构成赋予相同的符号,并省略与相同的构成有关的详细的说明。
如图10所示,语音翻译装置1d的语音识别部23具备分数计算部43。
[分数计算部43]
分数计算部43将语音被语音识别后的结果、以及通过对该结果的可靠性分数进行计算而算出的可靠性分数输出到说话指示部25。可靠性分数示出,对从语音检测部22获得的语音信息所示的语音进行语音识别时的语音识别的精确度(类似度)。例如,分数计算部43对语音信息所示的语音被转换后的文本文件、与语音信息所示的语音进行比较,算出表示文本文件与该语音的类似度的可靠性分数。
另外,分数计算部43也可以不具备在语音识别部23中,可以是与语音识别部23独立的其他的装置。
[说话指示部25]
说话指示部25通过对从语音识别部23的分数计算部43获得的可靠性分数进行评价,来判断语音识别的精确度。具体而言,说话指示部25判断从语音识别部23的分数计算部43获得的可靠性分数是否为阈值以下。说话指示部25在可靠性分数为阈值以下的情况下,不进行可靠性分数为阈值以下的语音的翻译,而是将催促说话的内容经由显示部27以及语音输出部28的至少一方来输出。说话指示部25在可靠性分数比阈值高的情况下,进行语音的翻译。
<工作>
对以上这种构成的语音翻译装置1d的工作进行说明。
图11是示出实施方式4中的语音翻译装置1d的工作的流程图。
针对与图3同样的处理赋予相同的符号,并适宜地省略说明。
在语音翻译装置1d的处理中,在经过了步骤s11至s13的处理之后,语音识别部23的分数计算部43算出语音识别结果的可靠性分数,将算出的可靠性分数输出到说话指示部25(s61)。
接着,说话指示部25从语音识别部23的分数计算部43获得可靠性分数,判断获得的可靠性分数是否为阈值以下(s62)。
说话指示部25在可靠性分数为阈值以下的情况下(s62的“是”),不进行可靠性分数为阈值以下的语音的翻译,经由显示部27,再次输出作为用于催促说话的内容的说话指示文本信息(s18)。于是,语音翻译装置1d进入步骤s19,进行与图3等相同的处理。
说话指示部25在可靠性分数比阈值高的情况下(s62的“否”)、进入步骤s14,进行与图3等相同的处理。
<作用效果>
接着,对本实施方式中的语音翻译装置1d的作用效果进行说明。
如以上所示,在本实施方式中的语音翻译装置1d中,语音识别部23对语音被语音识别后的结果、以及该结果的可靠性分数进行输出,说话指示部25在从语音识别部23获得的可靠性分数为阈值以下的情况下,不进行可靠性分数为阈值以下的语音的翻译,而是将催促说话的内容经由显示部27以及语音输出部28的至少一方来输出。
据此,只要示出语音识别的精确度的可靠性分数为阈值以下,说话指示部25就再次输出用于催促说话的内容,从而成为对象的说话者再次说话。因此,语音翻译装置1d能够确实地对成为对象的说话者的语音进行语音识别,从而能够更确实地对语音进行翻译。
尤其是,在语音输出部28通过语音对催促说话的内容进行输出时,说话者能够容易地注意到语音识别没有被正确地进行。
即使在本实施方式中的语音翻译装置1d,也能够实现与上述的实施方式1等同样的作用效果。
(其他变形例等)
以上基于实施方式1至4以及实施方式2、3的变形例对本申请进行了说明,但是本申请并非受这些实施方式1至4以及实施方式2、4等所限。
例如在上述各实施方式1至4以及实施方式2、3的变形例所涉及的语音翻译装置、语音翻译方法以及记录介质中,可以将第1说话者以及1个以上的第2说话者的各自的语音经由网络发送到云服务器,并保存在云服务器,也可以仅将对这些各自的语音进行识别后的第1文本文件以及第2文本文件经由网络发送到云服务器,并保存在云服务器。
并且,在上述各实施方式1至4以及实施方式2、3的变形例所涉及的语音翻译装置、语音翻译方法以及记录介质中,语音识别部以及翻译部也可以不搭载于语音翻译装置。在这种情况下,语音识别部以及翻译部也可以是被搭载在云服务器上的引擎。语音翻译装置可以将获得的语音信息发送到云服务器,也可以从云服务器获得文本文件、翻译文本文件、翻译语音,这些是根据语音信息,由云服务器进行语音识别和翻译的结果。
并且,上述的各实施方式1至4以及实施方式2、3的变形例所涉及的语音翻译方法是通过利用计算机的程序来实现的,这些程序可以被存储在存储装置。
并且,上述的各实施方式1至4以及实施方式2、3的变形例所涉及的语音翻译装置、语音翻译方法以及其程序中包含的各处理部,典型的可以由作为集成电路的lsi来实现。这些可以被分别制成一个芯片,也可以将其中的一部分或全部制成一个芯片。
并且,集成电路化并非受lsi所限,也可以由专用电路或通用处理器来实现。在lsi制造后,也可以利用可编程的fpga(fieldprogrammablegatearray:现场可编程门阵列)、或能够对lsi内部的电路单元的连接或设定进行重构的可重装处理器。
另外在上述的各实施方式1至4以及实施方式2、3的变形例,各构成要素可以由专用的硬件构成,也可以通过执行适于各构成要素的软件程序来实现。各构成要素也可以通过cpu或处理器等程序执行部读出并执行被记录在硬盘或半导体存储器等记录介质中的软件程序来实现。
并且,以上所使用的数字均为用于对本申请进行说明的例子,本申请的实施方式1至4以及实施方式2、3的变形例并非受这些例子中的数字所限。
并且,方框图中的功能块的划分为一个例子,可以将多个功能块作为一个功能块来实现,也可以将一个功能块分为多个,也可以将一部分的功能移向其他的功能块。并且,具有类似的功能的多个功能块的功能也可以由单一的硬件或软件并行或分时处理。
并且,流程图中的各步骤被执行的顺序由于是为了对本申请进行具体说明的例子,因此,也可以是上述以外的顺序。并且,上述步骤的一部分也可以与其他的步骤同时(并行)执行。
另外,针对实施方式1至4以及实施方式2、3的变形例执行本领域技术人员所能够想到的各种变形而得到的形态、以及在不脱离本申请的主旨范围内对实施方式1至4以及实施方式2、3的变形例中的构成要素以及功能进行任意组合而实现的形态均包括在本申请范围内。
本申请能够适用于,以不同的语言说话的多个说话者在进行会话时,为了意思疏通而使用的语音翻译装置、语音翻译方法以及记录介质。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



