
 商标分类
商标分类  商标转让
商标转让 
电子设备唤醒方法、装置、电子设备及存储介质与流程
 2021-01-28 17:01:55|
2021-01-28 17:01:55| 299|
299| 起点商标网
起点商标网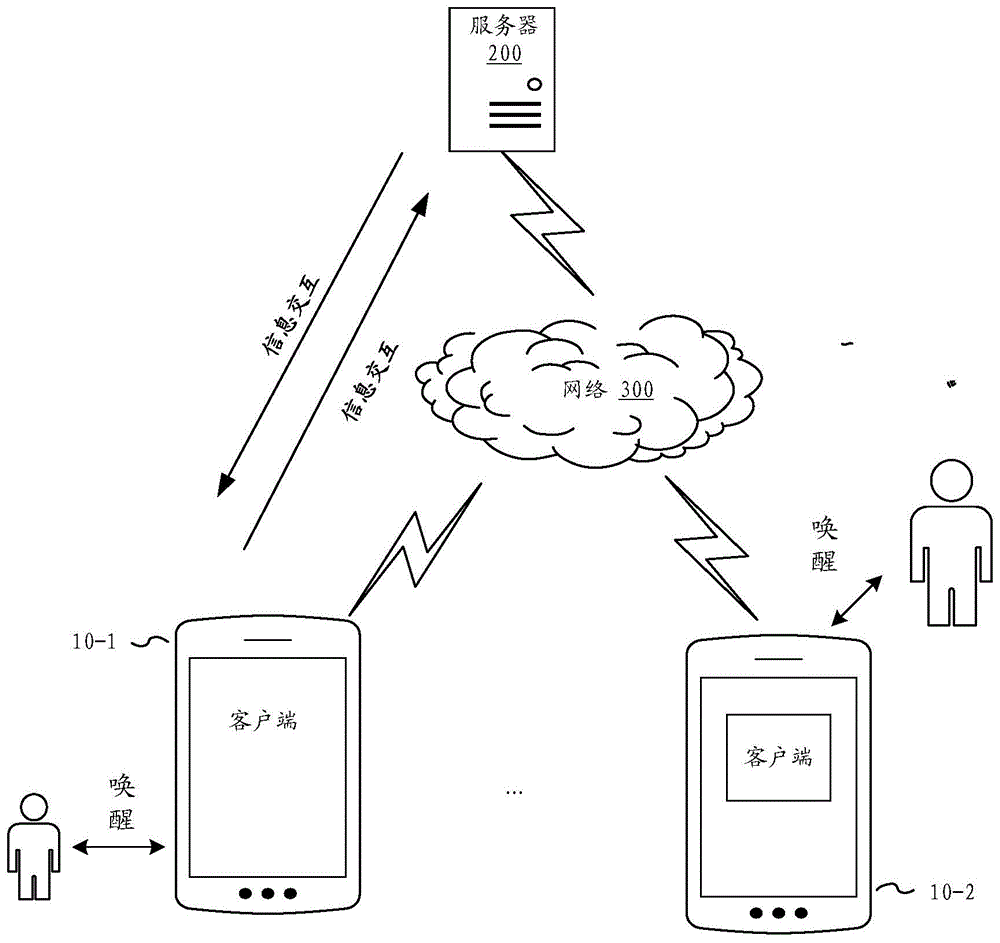
本发明涉及语音识别技术,尤其涉及电子设备唤醒方法、装置、电子设备及存储介质。
背景技术:
语音技术(speechtechnology)的关键技术有自动语音识别技术(asrautomaticspeechrecognition)和文字语音转换技术(ttstest-to-speech)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为最为便捷的人机交互方式之一。将语音技术应用于电子设备,实现唤醒电子设备的功能,即语音唤醒技术。通常语音唤醒(kwskeywordspotting)是通过设定一个固定的唤醒词,在用户说出唤醒词之后,终端上的语音识别功能,才会处于工作状态,否则处于休眠状态。
技术实现要素:
有鉴于此,本发明实施例提供一种电子设备唤醒方法、装置、电子设备及存储介质,能够实现在满足用户对唤醒词自定义的需求时,有效地降低计算复杂度提升响应速度,提升电子设备的唤醒性能,扩大了唤醒方案的适用场景,提升声音处理模型的鲁棒性和泛化能力。
本发明实施例的技术方案是这样实现的:
本发明实施例提供了一种电子设备唤醒方法,所述方法包括:
获取测试语音集合,并通过声音处理模型中的第一神经网络提取对应的测试语音特征集合;
通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征;
获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征;
根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,以实现基于所述唤醒判决的结果,通过电子设备执行与所述唤醒语音特征相匹配的任务。
本发明实施例还提供了一种电子设备唤醒装置,包括:
信息传输模块,用于获取测试语音集合;
信息处理模块,用于通过声音处理模型中的第一神经网络提取对应的测试语音特征集合;
所述信息处理模块,用于通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征;
所述信息处理模块,用于获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征;
所述信息处理模块,用于根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,以实现基于所述唤醒判决的结果,通过电子设备执行与所述唤醒语音特征相匹配的任务。
上述方案中,
所述信息处理模块,用于将所述测试语音特征集合输入所述第一神经网络的声学模型网络;
所述信息处理模块,用于当所述第一神经网络的关键词隐马尔科夫网络确定对应的置信度大于置信度阈值时,确定所述声学模型网络的隐藏输出层的输出特征为相应的测试特征。
上述方案中,
所述信息处理模块,用于通过文字语音转换服务器对唤醒词文本进行转换,获取对应的唤醒语音特征集合;
所述信息处理模块,用于通过所述第一神经网络对所述唤醒语音特征集合进行处理,确定与所述测试特征帧数相同的特征向量,并对所述特征向量进行平均处理,以提取对应的唤醒词特征。
上述方案中,
所述信息处理模块,用于通过所述文字语音转换服务器,根据发音词典将所述唤醒词文本所包含的每个字符转换成音节标识;
所述信息处理模块,用于构建所述音节标识与所述唤醒词文本所包含的字符之间的映射关系集合,形成不同的音节组合序列,作为所述唤醒语音特征集合中的元素。
上述方案中,
所述信息处理模块,用于确定所述测试特征和所述唤醒词特征的余弦相似度;
所述信息处理模块,用于基于所述测试特征和所述唤醒词特征的余弦相似度,确定对应的余弦相似度矩阵;
所述信息处理模块,用于通过所述声音处理模型中的第二神经网络,对所述余弦相似度矩阵进行处理,确定对应的判决结果累计值;
所述信息处理模块,用于基于所述判决结果累计值与所述累计值阈值的比较结果,确定唤醒判决的结果。
上述方案中,所述装置还包括:
训练模块,用于获取第一训练样本集合,其中所述第一训练样本集合为基础语音训练样本;
所述训练模块,用于对所述第一训练样本集合进行噪声添加处理,以形成相应的第二训练样本集合,其中,所述第二训练样本集合包括正例训练样本和负例训练样本;
所述训练模块,用于通过所述第一训练样本集合对所述声音处理模型中的第一神经网络进行训练,以确定所述第一神经网络的模型参数;
所述训练模块,用于通过所述第二训练样本集合对所述声音处理模型中的第二神经网络进行训练,以确定所述第二神经网络的模型参数。
上述方案中,
所述训练模块,用于确定与所述声音处理模型的使用环境相匹配的动态噪声阈值;
所述训练模块,用于根据所述动态噪声阈值对所述第一训练样本集合进行噪声添加处理,以形成与所述动态噪声阈值相匹配的第二训练样本集合。
上述方案中,
所述训练模块,用于确定与所述声音处理模型相对应的固定噪声阈值;
所述训练模块,用于根据所述固定噪声阈值对所述第一训练样本集合进行噪声添加处理,以形成与所述固定噪声阈值相匹配的第二训练样本集合。
上述方案中,
所述训练模块,用于通过所述声音处理模型中的第二神经网络处理所述唤醒词文本,形成对应的唤醒词特征;
所述训练模块,用于通过所述声音处理模型中的第二神经网络处理所述第二训练样本集合中的一个正例训练样本和全部负例训练样本,确定相应的训练结果;
所述训练模块,用于基于所述训练结果和所述唤醒词特征,确定所述正例训练样本和负例训练样本对应的余弦相似度矩阵特征,并通过所述余弦相似度矩阵特征确定所述第二神经网络的模型参数。
上述方案中,所述装置还包括:
显示模块,用于显示用户界面,所述用户界面中包括以不同类型用户的第一人称视角,对即时客户端中的任务信息处理环境进行观察的人称视角画面,所述用户界面中还包括任务控制组件和信息展示组件;
所述显示模块,用于通过所述用户界面利用信息展示组件展示所述唤醒语音特征相匹配的任务,以及相对的唤醒词;
所述显示模块,用于基于所述唤醒判决的结果,通过所述用户界面利用信息展示组件展示所述电子设备执行与所述唤醒语音特征相匹配的任务处理结果,以实现所述电子设备与用户的信息交互。
本发明实施例还提供了一种语电子设备,所述电子设备包括:
存储器,用于存储可执行指令;
处理器,用于运行所述存储器存储的可执行指令时,实现前述的电子设备唤醒方法。
本发明实施例还提供了一种计算机可读存储介质,存储有可执行指令,所述可执行指令被处理器执行时实现前序的电子设备唤醒方法。
本发明实施例具有以下有益效果:
本发明实通过获取测试语音集合,并通过声音处理模型中的第一神经网络提取对应的测试语音特征集合;通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征;获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征;根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,由此,可以实现基于唤醒判决的结果,通过电子设备执行与唤醒语音特征相匹配的任务,并且能够实现在满足用户对唤醒词自定义的需求时,有效地降低计算复杂度提升响应速度,提升电子设备的唤醒性能,扩大了唤醒方案的适用场景,提升声音处理模型的鲁棒性和泛化能力。
附图说明
图1为本发明实施例提供的电子设备唤醒方法的使用场景示意图;
图2为本发明实施例提供的电子设备唤醒装置的组成结构示意图;
图3为本发明实施例所提供的电子设备的唤醒方法一个可选的数据结构示意图;
图4为本发明实施例所提供的电子设备的唤醒方法一个可选的数据结构示意图;
图5为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图;
图6为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图;
图7是本发明实施例提供的任务信息处理装置100的架构示意图;
图8是本发明实施例提供的区块链网络200中区块链的结构示意图;
图9是本发明实施例提供的区块链网络200的功能架构示意图;
图10为本发明实施例提供的电子设备唤醒方法的使用场景示意图;
图11为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图;
图12为本发明实施例提供的电子设备唤醒方法的模型结构示意图;
图13为本发明实施例提供的电子设备唤醒方法的模型结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,所描述的实施例不应视为对本发明的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
对本发明实施例进行进一步详细说明之前,对本发明实施例中涉及的名词和术语进行说明,本发明实施例中涉及的名词和术语适用于如下的解释。
1)人工神经网络:简称神经网络(neuralnetwork,nn),在机器学习和认知科学领域,是一种模仿生物神经网络结构和功能的数学模型或计算模型,用于对函数进行估计或近似。
2)模型参数:是使用通用变量来建立函数和变量之间关系的一个数量。在人工神经网络中,模型参数通常是实数矩阵。
3)自然语言理解:nlu(naturallanguageunderstanding),在对话系统中对用户所说的话进行语义的信息抽取,包括领域意图识别和槽填充(slotfilling)。
4)语音语义理解(speechtranslation):又称自动语音语义理解,是通过计算机将一种自然语言的语音语义理解为另一种自然语言的文本或语音的技术,一般可以由语义理解和机器语义理解两阶段组成。
5)响应于,用于表示所执行的操作所依赖的条件或者状态,当满足所依赖的条件或状态时,所执行的一个或多个操作可以是实时的,也可以具有设定的延迟;在没有特别说明的情况下,所执行的多个操作不存在执行先后顺序的限制。
6)隐马尔科夫模型(hmmhiddenmarkovmodel)是一种统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。在隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量则是可见的。hmm中的状态是hmm的基本组成部分;hmm的转移概率表示hmm的状态之间发生转换的概率;而每一个状态在可能输出的符号上都有一概率分布,即hmm的输出概率。其中,马尔可夫过程是一个不具备记忆特质的随机过程。该随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。
7)卷积神经网络(cnnconvolutionalneuralnetworks)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforwardneuralnetworks),是深度学习(deeplearning)的代表算法之一。卷积神经网络具有表征学习(representationlearning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariantclassification)。
8)模型训练,对图像数据集进行多分类学习。该模型可采用tensorflow、torch等深度学习框架进行构建,使用cnn等神经网络层的多层结合组成多分类模型。模型的输入为图像经过opencv等工具读取形成的三通道或原通道矩阵,模型输出为多分类概率,通过softmax等算法最终输出网页类别。在训练时,模型通过交叉熵等目标函数向正确趋势逼近。
9)终端,包括但不限于:普通终端、专用终端,其中所述普通终端与发送通道保持长连接和/或短连接,所述专用终端与所述发送通道保持长连接。
10)客户端,终端中实现特定功能的载体,例如移动客户端(app)是移动终端中特定功能的载体,例如执行报表制作的功能或者进行报表展示的功能。
11)组件(component),是小程序的视图的功能模块,也称为前端组件,页面中的按钮、标题、表格、侧边栏、内容和页脚等,组件包括模块化的代码以便于在小程序的不同的页面中重复使用。
12)小程序(miniprogram),是一种基于面向前端的语言(例如javascript)开发的、在超文本标记语言(html,hypertextmarkuplanguage)页面中实现服务的程序,由客户端(例如浏览器或内嵌浏览器核心的任意客户端)经由网络(如互联网)下载、并在客户端的浏览器环境中解释和执行的软件,节省在客户端中安装的步骤。例如,通过语音指令唤醒终端中的小程序实现在社交网络客户端中可以下载、运行用于实现机票购买、任务处理与制作、数据展示等各种服务的小程序。
13)交易(transaction),等同于计算机术语“事务”,交易包括了需要提交到区块链网络执行的操作,并非单指商业语境中的交易,鉴于在区块链技术中约定俗成地使用了“交易”这一术语,本发明实施例遵循了这一习惯。
例如,部署(deploy)交易用于向区块链网络中的节点安装指定的智能合约并准备好被调用;调用(invoke)交易用于通过调用智能合约在区块链中追加交易的记录,并对区块链的状态数据库进行操作,包括更新操作(包括增加、删除和修改状态数据库中的键值对)和查询操作(即查询状态数据库中的键值对)。
14)区块链(blockchain),是由区块(block)形成的加密的、链式的交易的存储结构。
例如,每个区块的头部既可以包括区块中所有交易的哈希值,同时也包含前一个区块中所有交易的哈希值,从而基于哈希值实现区块中交易的防篡改和防伪造;新产生的交易被填充到区块并经过区块链网络中节点的共识后,会被追加到区块链的尾部从而形成链式的增长。
15)区块链网络(blockchainnetwork),通过共识的方式将新区块纳入区块链的一系列的节点的集合。
16)账本(ledger),是区块链(也称为账本数据)和与区块链同步的状态数据库的统称。
其中,区块链是以文件系统中的文件的形式来记录交易;状态数据库是以不同类型的键(key)值(value)对的形式来记录区块链中的交易,用于支持对区块链中交易的快速查询。
17)智能合约(smartcontracts),也称为链码(chaincode)或应用代码,部署在区块链网络的节点中的程序,节点执行接收的交易中所调用的智能合约,来对账本数据库的键值对数据进行更新或查询的操作。
18)共识(consensus),是区块链网络中的一个过程,用于在涉及的多个节点之间对区块中的交易达成一致,达成一致的区块将被追加到区块链的尾部,实现共识的机制包括工作量证明(pow,proofofwork)、权益证明(pos,proofofstake)、股份授权证明(dpos,delegatedproof-of-stake)、消逝时间量证明(poet,proofofelapsedtime)等。
图1为本发明实施例提供的电子设备唤醒方法的使用场景示意图,参见图1,终端(包括终端10-1和终端10-2)上设置有能够执行不同功能相应客户端其中,所属客户端为终端(包括终端10-1和终端10-2)通过网络300从相应的服务器200中获取不同的相应信息进行浏览,终端通过网络300连接服务器200,网络300可以是广域网或者局域网,又或者是二者的组合,使用无线链路实现数据传输,其中,终端(包括终端10-1和终端10-2)可以通过用户的语音指令进行唤醒,具体来说,语音技术的关键技术有自动语音识别技术和语音合成技术以及声纹识别技术。其中可以将语音技术应用于电子设备,实现唤醒电子设备的功能,即语音唤醒技术。通常语音唤醒是通过设定一个固定的唤醒词,在用户说出唤醒词之后,终端上的语音识别功能,才会处于工作状态,否则处于休眠状态。
其中,本申请实施例所提供的智能设备唤醒方法是基于人工智能实现的,人工智能(artificialintelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
在本申请实施例中,主要涉及的人工智能软件技术包括上述语音处理技术和机器学习等方向。例如,可以涉及语音技术(speechtechnology)中的语音识别技术(automaticspeechrecognition,asr),其中包括语音信号预处理(speechsignalpreprocessing)、语音信号频域分析(speechsignalfrequencyanalyzing)、语音信号特征提取(speechsignalfeatureextraction)、语音信号特征匹配/识别(speechsignalfeaturematching/recognition)、语音的训练(speechtraining)等。
例如可以涉及机器学习(machinelearning,ml),机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习通常包括深度学习(deeplearning)等技术,深度学习包括人工神经网络(artificialneuralnetwork),例如卷积神经网络(convolutionalneuralnetwork,cnn)、循环神经网络(recurrentneuralnetwork,rnn)、深度神经网络(deepneuralnetwork,dnn)等。
可以理解的是,该方法可以应用于智能设备(intelligentdevice)上,智能设备可以是任何一种具有语音唤醒功能的设备,例如可以是智能终端、智能家居设备(如智能音箱、智能洗衣机等)、智能穿戴设备(如智能手表)、车载智能中控系统(通过语音指令唤醒终端中执行不同任务的小程序)或者ai智能医疗设备(通过语音指令进行唤醒触发)等。
作为一个示例,终端(包括终端10-1和终端10-2)用于布设所电子设备唤醒电子设备唤醒装置以实现本发明所提供的电子设备唤醒方法,以通过获取测试语音集合,并通过声音处理模型中的第一神经网络提取对应的测试语音特征集合;通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征;获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征;根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,以实现基于所述唤醒判决的结果,通过电子设备执行与所述唤醒语音特征相匹配的任务。
当然在通过声音处理模型对电子设备进行唤醒之前,还需要对声音处理模型进行训练,具体包括:获取第一训练样本集合,其中所述第一训练样本集合为基础语音训练样本;对所述第一训练样本集合进行噪声添加处理,以形成相应的第二训练样本集合,其中,所述第二训练样本集合包括正例训练样本和负例训练样本;通过所述第一训练样本集合对所述声音处理模型中的第一神经网络进行训练,以确定所述第一神经网络的模型参数;通过所述第二训练样本集合对所述声音处理模型中的第二神经网络进行训练,以确定所述第二神经网络的模型参数。
下面对本发明实施例的电子设备唤醒装置的结构做详细说明,电子设备唤醒装置可以各种形式来实施,如带有电子设备唤醒功能的专用终端,也可以为设置有电子设备唤醒功能的手机或者平板电脑,例如前序图1中的终端。图2为本发明实施例提供的电子设备唤醒装置的组成结构示意图,可以理解,图2仅仅示出了电子设备唤醒装置的示例性结构而非全部结构,根据需要可以实施图2示出的部分结构或全部结构。
本发明实施例提供的电子设备唤醒装置包括:至少一个处理器201、存储器202、用户接口203和至少一个网络接口204。电子设备唤醒装置中的各个组件通过总线系统205耦合在一起。可以理解,总线系统205用于实现这些组件之间的连接通信。总线系统205除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图2中将各种总线都标为总线系统205。
其中,用户接口203可以包括显示器、键盘、鼠标、轨迹球、点击轮、按键、按钮、触感板或者触摸屏等。
可以理解,存储器202可以是易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。本发明实施例中的存储器202能够存储数据以支持终端(如10-1)的操作。这些数据的示例包括:用于在终端(如10-1)上操作的任何计算机程序,如操作系统和应用程序。其中,操作系统包含各种系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用程序可以包含各种应用程序。
在一些实施例中,本发明实施例提供的电子设备唤醒装置可以采用软硬件结合的方式实现,作为示例,本发明实施例提供的声音处理模型可以是采用硬件译码处理器形式的处理器,其被编程以执行本发明实施例提供的声音处理模型的语义处理方法。例如,硬件译码处理器形式的处理器可以采用一个或多个应用专用集成电路(asic,applicationspecificintegratedcircuit)、dsp、可编程逻辑器件(pld,programmablelogicdevice)、复杂可编程逻辑器件(cpld,complexprogrammablelogicdevice)、现场可编程门阵列(fpga,field-programmablegatearray)或其他电子元件。
作为本发明实施例提供的电子设备唤醒装置采用软硬件结合实施的示例,本发明实施例所提供的电子设备唤醒装置可以直接体现为由处理器201执行的软件模块组合,软件模块可以位于存储介质中,存储介质位于存储器202,处理器201读取存储器202中软件模块包括的可执行指令,结合必要的硬件(例如,包括处理器201以及连接到总线205的其他组件)完成本发明实施例提供的声音处理模型的语义处理方法。
作为示例,处理器201可以是一种集成电路芯片,具有信号的处理能力,例如通用处理器、数字信号处理器(dsp,digitalsignalprocessor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,其中,通用处理器可以是微处理器或者任何常规的处理器等。
作为本发明实施例提供的电子设备唤醒装置采用硬件实施的示例,本发明实施例所提供的装置可以直接采用硬件译码处理器形式的处理器201来执行完成,例如,被一个或多个应用专用集成电路(asic,applicationspecificintegratedcircuit)、dsp、可编程逻辑器件(pld,programmablelogicdevice)、复杂可编程逻辑器件(cpld,complexprogrammablelogicdevice)、现场可编程门阵列(fpga,field-programmablegatearray)或其他电子元件执行实现本发明实施例提供的声音处理模型的语义处理方法。
本发明实施例中的存储器202用于存储各种类型的数据以支持电子设备唤醒装置的操作。这些数据的示例包括:用于在电子设备唤醒装置上操作的任何可执行指令,如可执行指令,实现本发明实施例的从声音处理模型的语义处理方法的程序可以包含在可执行指令中。
在另一些实施例中,本发明实施例提供的电子设备唤醒装置可以采用软件方式实现,图2示出了存储在存储器202中的电子设备唤醒装置,其可以是程序和插件等形式的软件,并包括一系列的模块,作为存储器202中存储的程序的示例,可以包括电子设备唤醒装置,电子设备唤醒装置中包括以下的软件模块:信息传输模块2081,信息处理模块2082。当电子设备唤醒装置中的软件模块被处理器201读取到ram中并执行时,将实现本发明实施例提供的声音处理模型的语义处理方法,下面介绍本发明实施例中电子设备唤醒装置中各个软件模块的功能,具体包括:
信息传输模块2081,用于获取测试语音集合。
信息处理模块2082,用于通过声音处理模型中的第一神经网络提取对应的测试语音特征集合。
所述信息处理模块2082,用于通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征。
所述信息处理模块2082,用于获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征。
所述信息处理模块2082,用于根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,以实现基于所述唤醒判决的结果,通过电子设备执行与所述唤醒语音特征相匹配的任务。
结合图2示出的电子设备唤醒装置说明本发明实施例提供的电子设备唤醒方法,在介绍本申请所提供的电子设备唤醒方法之前,首先介绍相关技术中电子设备唤醒方式,其中,参考图3和图4,其中,图3为本发明实施例所提供的电子设备的唤醒方法一个可选的数据结构示意图,图4为本发明实施例所提供的电子设备的唤醒方法一个可选的数据结构示意图;具体来说:参考图3对于电子设备的唤醒主要可以包括:1)单模型自定义唤醒方案,例如keyword/fillerhiddenmarkovmodel(hmm)模型方案和lstmfeatureextractorsystem方案,以keyword/fillerhmmmodel为例,可以包括声学模型和hmm解码网络两部分,其中声学模型可以使用dnn/cnn/lstm等网络结构,输出单元包含所有可能的发音单元(例如发音单元可以选择音节或者音素等,每一个发音单元对应一个hmm状态),训练数据为通用的语音训练数据集;hmm解码网络由keywordhmm和fillerhmm组成,其中keywordhmm由组成唤醒词的所有发音单元对应的hmm状态串联组成,fillerhmm由一组非唤醒词发音单元对应的hmm状态组成。在唤醒词检测过程中,用户的语音信息可以按照固定窗大小送入解码网络,利用维特比解码算法查找最优解码路径,最终的唤醒判决可以简单的判断最优解码路径是否经过keywordhmm路径,也可以通过计算更加复杂的置信度等策略来进行判决。但是由于只使用单模型结构,其对语音信息的识别的性能在远场或者噪声较高的复杂应用场景下很难达到工业应用的水准,不利于大规模的部署与使用在电子设备中。
2)参考图4,以lstmkwssystem为例,可以分为lstm特征提取器和置信度计算两部分,其中lstm特征提取器中的lstm声学模型输出采用字单元,特征提取器抽取lstm模型最后一层隐层输出,将多帧输出拼接在一起作为置信度计算模块使用的特征;但是用户在使用新唤醒词之前,需要经过一个注册的过程,即需语音输入n条唤醒词语音,其中n条语音长度可以不一样长度,假设这n条语音的平均帧数是k,那么经过lstm特征抽取器后,每条语音分别取最后k帧的lstm隐层输出拼接作为输出特征(如果不够k,则在前面补0),将n个输出特征平均后作为唤醒词特征;而在唤醒使用过程中,用户输入的语音按照大小为k帧的滑动窗送入lstm特征提取器后,同样将输出拼接作为测试特征;在置信度计算过程中,计算该测试特征与唤醒词特征的余弦相似度,可以得到置信度得分,与预设的阈值比较来进行唤醒判决。但是这一过程中,需要用户在注册过程中语音输入若干次唤醒词数据,使用过程比较繁琐,并且对用户输入的语音质量有一定的要求,复杂语音环境中的用户语音指令由于无法识别,将会影响用户的使用体验。进一步地,还可以将语音数据送入云端的asr识别器进行识别,云端识别通常采用更大规模的声学模型,并结合大语言模型,经过解码器解码后来进行二遍判决,但是由于这一验证过程需要经过网络与云端进行交互,因此增加了电子设备的反应延迟时间,同时没有与网络连接的电子设备由于不能够使用云端的asr识别器,因此不能够添加新的唤醒词,不利用用户根据使用情况对唤醒词的灵活切换。
为解决上述缺陷,参考图5,图5为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图,其中用户可以通过语音指令中的唤醒词对电子设备进行操作,电子设备执行与唤醒语音特征相匹配的任务;其中,带有电子设备唤醒装置的专用设备可以封装于图1所示的中终端中,以执行前序图2所示的电子设备唤醒装置中的相应软件模块,用户通过相应的客户端可以获得任务信息并进行展示,并在处理过程中通过本申请所提供的电子设备唤醒方法触发相应的任务信息处理进程(例如通过语音信息唤醒微信中各种任务处理功能的小程序进程)。下面针对图5示出的步骤进行说明。
步骤501:获取测试语音集合,并通过声音处理模型中的第一神经网络提取对应的测试语音特征集合。
其中,用户可以通过相应的语音指令对电子设备进行语音控制,执行与唤醒语音特征相匹配的任务,来替代传统的手动操作,具体来说,对于不同类型的电子设备的各种操作,可以预先配置相应的唤醒词,用户只需要通过语音指令说出所需任务操作对应的唤醒词,即可通过语音控制方式,控制电子设备执行相应的操作。例如:当电子设备为车载智能中控系统时,电子设备的唤醒词为“打开歌曲”,由于智能设备可以随时采集到音频数据,电子设备可以采集到音频数据“打开音乐”,从而识别“打开音乐”是否为唤醒词,并通过电子设备执行与所述唤醒语音特征相匹配的任务,实现电子设备播放歌曲。
步骤502:通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征。
在本发明的一些实施例中,通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征,可以通过以下方式实现:
将所述测试语音特征集合输入所述第一神经网络的声学模型网络;当所述第一神经网络的关键词隐马尔科夫网络确定对应的置信度大于置信度阈值时,确定所述声学模型网络的隐藏输出层的输出特征为相应的测试特征。其中,本申请所提供的声音处理模型包括:第一神经网络和第二神经网络,其中,第一神经网络包括声学模型网络和关键词隐马尔科夫网络,具体来说,通过第一神经网络的声学模型网络可以获取测试语音集合中语音信息的fbank特征,具体来说测试语音集合中的每一条测试语音的音频特征数据可以是任一种表示声音特点的特征,例如梅尔频率倒谱系数(mfccmelfrequencycepstrumcoefficient)、滤波器组(fbankfilterbank)特征等。从而根据音频特征数据确定待识别音频是否满足智能设备的唤醒条件。其中,fbank特征是以类似于人耳对听到的声音进行处理的方式来提取得到的,具体通过对已分帧的测试语音集合中的每一条音频信息的音频进行傅里叶变换、能量谱计算和mel等操作,获取的能够表征每一帧音频数据的数组(也被称为fbank特征向量),该数组即为fbank特征,并通过所确定的fbank特征进一步地通过关键词隐马尔科夫网络确定对应的测试特征。其中,声学模型可以是dnn模型、cnn模型、长短期记忆网络lstm模型等各种神经网络模型,本申请对此不做限定。进一步地,对于唤醒语音特征集合,则可以通过第一神经网络的声学模型网络可以获取对应的fbank特征,并进一步的获取唤醒词特征。
步骤503:获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征。
在本发明的一些实施例中,获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征,可以通过以下方式实现:
通过文字语音转换服务器对唤醒词文本进行转换,获取对应的唤醒语音特征集合;通过所述第一神经网络对所述唤醒语音特征集合进行处理,确定与所述测试特征帧数相同的特征向量,并对所述特征向量进行平均处理,以提取对应的唤醒词特征。其中,用户在新添加新的唤醒词时,可以仅输入唤醒词文本,通过部署于云端的文字语音转换服务器对唤醒词文本进行转换,其中,本发明实施例可结合云技术或区块链网络技术实现,云技术(cloudtechnology)是指在广域网或局域网内将硬件、软件及网络等系列资源统一起来,实现数据的计算、储存、处理和共享的一种托管技术,也可理解为基于云计算商业模式应用的网络技术、信息技术、整合技术、管理平台技术及应用技术等的总称。技术网络系统的后台服务需要大量的计算、存储资源,如视频网站、图片类网站和更多的门户网站,因此云技术需要以云计算作为支撑。
需要说明的是,云计算是一种计算模式,它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。提供资源的网络被称为“云”。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用,随时扩展,按使用付费。作为云计算的基础能力提供商,会建立云计算资源池平台,简称云平台,一般称为基础设施即服务(iaas,infrastructureasaservice),在资源池中部署多种类型的虚拟资源,供外部客户选择使用。云计算资源池中主要包括:计算设备(可为虚拟化机器,包含操作系统)、存储设备和网络设备。
在本发明的一些实施例中,通过云端的tts服务器可以利用唤醒文本生成n个不同的唤醒词语音(读音),形成不同帧长的特征向量,举例来说,用户可以根据不同的使用场景对唤醒词文本进行任意修改,tts服务器根据发音词典将所述唤醒词文本所包含的每个字符转换成音节标识,以提取对应的唤醒词特征。
在本发明的一些实施例中,还可以通过所述文字语音转换服务器,根据发音词典将所述唤醒词文本所包含的每个字符转换成音节标识;构建所述音节标识与所述唤醒词文本所包含的字符之间的映射关系集合,形成不同的音节组合序列,作为所述唤醒语音特征集合中的元素。具体来说,唤醒词文本为中文时,每个汉字为一个字符,每个字符的读音对应音节标识。例如,唤醒词文本信息为“难”字,其读音可以是第二声,也可以是第四声,每个读音分配一个标识id(identifier)用于作为音节标识,进而构建音节标识与唤醒词文本所包含的字符之间的映射关系集合,形成不同的音节组合序列,作为唤醒语音特征集合中的元素,进一步地,当醒词文本信息为“薄”字其读音可以是第二声“bao”,也可以是第二声“bo”,每个读音分配一个标识id(identifier)用于作为音节标识,进而构建音节标识与唤醒词文本所包含的字符之间的映射关系集合,形成不同的音节组合序列,作为唤醒语音特征集合中的元素。
步骤504:根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决。
由此,可以实现基于所述唤醒判决的结果,通过电子设备执行与所述唤醒语音特征相匹配的任务。
在本发明的一些实施例中,根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,可以通过以下方式实现:
确定所述测试特征和所述唤醒词特征的余弦相似度;基于所述测试特征和所述唤醒词特征的余弦相似度,确定对应的余弦相似度矩阵;通过所述声音处理模型中的第二神经网络,对所述余弦相似度矩阵进行处理,确定对应的判决结果累计值;基于所述判决结果累计值与所述累计值阈值的比较结果,确定唤醒判决的结果。其中,第二神经网络包括任意类型的二分类神经网络,用于基于测试特征和所述唤醒词特征确定是否唤醒电子设备执行相应的任务,其中,二分类网络可以将输入的特征分成两类,具体表现为输出为0或1。在检测到第一神经网络被激活时,作为第二神经网络的二分类网络被激活,从而利用测试特征和唤醒词特征的余弦相似度进行进一步的判决。二分类网络的模型参数量远小于传统的检测网络模型的模型参数量,因此可以降低系统的计算量。同时二分类网络实现了在较小模型参数量的情况下能够有效地抑制掉大部分的误唤醒,从而显著地减少计算量、缩短延迟并提高智能设备响应的正确率。相比于仅使用复杂的单模型神经网络进行语音唤醒技术而言,本申请所提供的电子设备唤醒方法在电子设备的远场、噪音复杂度较高的应用场景下可以普遍应用,在低延迟的情况下正确地唤醒电子设备,提高智能设备整体的易用性。
当然,在执行本申请所提供的电子设备唤醒方法之前需要对第一神经网络和第二神经网络进行训练,继续参考图6,图6为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图,其中用户可以通过语音指令中的唤醒词对电子设备进行操作,电子设备执行与唤醒语音特征相匹配的任务;其中,带有电子设备唤醒装置的专用设备可以封装于图1所示的中终端中,以执行前序图2所示的电子设备唤醒装置中的相应软件模块,用户通过相应的客户端可以获得任务信息并进行展示,并在处理过程中通过本申请所提供的电子设备唤醒方法触发相应的任务信息处理进程(例如通过语音信息唤醒微信中各种任务处理功能的小程序进程)。下面针对图6示出的步骤进行说明。
步骤601:获取第一训练样本集合,其中所述第一训练样本集合为基础语音训练样本。
步骤602:对所述第一训练样本集合进行噪声添加处理,以形成相应的第二训练样本集合。
其中,所述第二训练样本集合包括正例训练样本和负例训练样本。
在本发明的一些实施例中,对所述第一训练样本集合进行噪声添加处理,以形成相应的第二训练样本集合,可以通过以下方式实现:
确定与所述声音处理模型的使用环境相匹配的动态噪声阈值;根据所述动态噪声阈值对所述第一训练样本集合进行噪声添加处理,以形成与所述动态噪声阈值相匹配的第二训练样本集合。中由于声音处理模型的使用环境不同(电子设备的使用环境不同),与所述声音处理模型的使用环境相匹配的动态噪声阈值也不相同,例如,学术翻译的使用环境中,与所述声音处理模型的使用环境相匹配的动态噪声阈值需要小于阅读机器人阅读文章的环境中的动态噪声阈值。
在本发明的一些实施例中,对所述第一训练样本集合进行噪声添加处理,以形成相应的第二训练样本集合,可以通过以下方式实现:
确定与所述声音处理模型相对应的固定噪声阈值;根据所述固定噪声阈值对所述第一训练样本集合进行噪声添加处理,以形成与所述固定噪声阈值相匹配的第二训练样本集合。其中,当声音处理模型固化于相应的硬件机构中,例如车载终端,使用环境为口语指令时,由于噪声较为单一,通过固定声音处理模型相对应的固定噪声阈值,能够有效提神声音处理模型的训练速度,减少用户的等待时间,使得声音处理模型更加适应车载使用环境。
步骤603:通过所述第一训练样本集合对所述声音处理模型中的第一神经网络进行训练,以确定所述第一神经网络的模型参数。
步骤604:通过所述第二训练样本集合对所述声音处理模型中的第二神经网络进行训练,以确定所述第二神经网络的模型参数。
在本发明的一些实施例中,通过所述第二训练样本集合对所述声音处理模型中的第二神经网络进行训练,以确定所述第二神经网络的模型参数,可以通过以下方式实现:
通过所述声音处理模型中的第二神经网络处理所述唤醒词文本,形成对应的唤醒词特征;通过所述声音处理模型中的第二神经网络处理所述第二训练样本集合中的一个正例训练样本和全部负例训练样本,确定相应的训练结果;基于所述训练结果和所述唤醒词特征,确定所述正例训练样本和负例训练样本对应的余弦相似度矩阵特征,并通过所述余弦相似度矩阵特征确定所述第二神经网络的模型参数。由此,通过第二神经网络处理第二训练样本集合中的一个正例训练样本和全部负例训练样本可以保证第二神经网络的低误唤醒率,避免电子设备的频繁误唤醒。
进一步地,在本发明的一些实施例中,为了实现通过区块链网络存储相应的数据,本发明所提供的电子设备唤醒方法还包括:
将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息送至区块链网络,以使所述区块链网络的节点将所述用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息填充至新区块,且当对所述新区块共识一致时,将所述新区块追加至区块链的尾部。
结合前序图1所示,本发明实施例所提供的电子设备唤醒方法可以通过相应的云端设备实现,例如:终端(包括终端10-1和终端10-2)通过网络300连接位于云端的服务器200,网络300可以是广域网或者局域网,又或者是二者的组合。值得说明的是,服务器200可为实体设备,也可为虚拟化设备。
在本发明的一些实施例中所述方法还包括:
接收所述区块链网络中的其他节点的数据同步请求;响应于所述数据同步请求,对所述其他节点的权限进行验证;当所述其他节点的权限通过验证时,控制当前节点与所述其他节点之间进行数据同步,以实现所述其他节点获取用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息。
在本发明的一些实施例中,电子设备唤醒方法还包括:
响应于查询请求,解析所述查询请求以获取对应的对象标识;根据所述对象标识,获取区块链网络中的目标区块内的权限信息;对所述权限信息与所述对象标识的匹配性进行校验;当所述权限信息与所述对象标识相匹配时,在所述区块链网络中获取相应的用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息;响应于所述查询指令,将所获取的相应的用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息向相应的客户端进行推送,以实现归属于用户的不同电子设备获取所述区块链网络中所保存的相应的用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息,减少用户在更换电子设备后需要重复输入新的唤醒词。
参见图7,图7是本发明实施例提供的任务信息处理装置100的架构示意图,包括区块链网络200(示例性示出了共识节点210-1至共识节点210-3)、认证中心300、业务主体400和业务主体500,下面分别进行说明。
区块链网络200的类型是灵活多样的,例如可以为公有链、私有链或联盟链中的任意一种。以公有链为例,任何业务主体的电子设备例如用户终端和服务器,都可以在不需要授权的情况下接入区块链网络200;以联盟链为例,业务主体在获得授权后其下辖的电子设备(例如终端/服务器)可以接入区块链网络200,此时,成为区块链网络200中的客户端节点。
在一些实施例中,客户端节点可以只作为区块链网络200的观察者,即提供支持业务主体发起交易(例如,用于上链存储数据或查询链上数据)功能,对于区块链网络200的共识节点210的功能,例如排序功能、共识服务和账本功能等,客户端节点可以缺省或者有选择性(例如,取决于业务主体的具体业务需求)地实施。从而,可以将业务主体的数据和业务处理逻辑最大程度迁移到区块链网络200中,通过区块链网络200实现数据和业务处理过程的可信和可追溯。
区块链网络200中的共识节点接收来自不同业务主体(例如图1中示出的业务主体400和业务主体500)的客户端节点(例如,图1中示出的归属于业务主体400的客户端节点410、以及归属于电子设备的系统500的客户端节点510)提交的交易,执行交易以更新账本或者查询账本,执行交易的各种中间结果或最终结果可以返回业务主体的客户端节点中显示。
例如,客户端节点410/510可以订阅区块链网络200中感兴趣的事件,例如区块链网络200中特定的组织/通道中发生的交易,由共识节点210推送相应的交易通知到客户端节点410/510,从而触发客户端节点410/510中相应的业务逻辑。
下面以多个业务主体接入区块链网络以实现唤醒词以及相应的任务信息的管理为例,说明区块链网络的示例性应用。
参见图7,管理环节涉及的多个业务主体,如业务主体400可以是基于人工智能的任务信息处理装置,业务主体500可以是带有任务信息处理功能的显示系统,从认证中心300进行登记注册获得各自的数字证书,数字证书中包括业务主体的公钥、以及认证中心300对业务主体的公钥和身份信息签署的数字签名,用来与业务主体针对交易的数字签名一起附加到交易中,并被发送到区块链网络,以供区块链网络从交易中取出数字证书和签名,验证消息的可靠性(即是否未经篡改)和发送消息的业务主体的身份信息,区块链网络会根据身份进行验证,例如是否具有发起交易的权限。业务主体下辖的电子设备(例如终端或者服务器)运行的客户端都可以向区块链网络200请求接入而成为客户端节点。
业务主体400的客户端节点410用于显示用户界面,用户界面中包括以不同类型用户的第一人称视角,对即时客户端中的任务信息处理环境进行观察的人称视角画面,所述用户界面中还包括任务控制组件和信息展示组件;通过所述用户界面利用信息展示组件展示所述唤醒语音特征相匹配的任务,以及相对的唤醒词;基于所述唤醒判决的结果,通过所述用户界面利用信息展示组件展示所述电子设备执行与所述唤醒语音特征相匹配的任务处理结果,以实现所述电子设备与用户的信息交互,并将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息发送至区块链网络200。
其中,将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息发送至区块链网络200,可以预先在客户端节点410设置业务逻辑,当形成相应的唤醒词以及相应的任务信息时,客户端节点410将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息自动发送至区块链网络200,也可以由业务主体400的业务人员在客户端节点410中登录,手动打包将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息,并将其发送至区块链网络200。在发送时,客户端节点410根据将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息生成对应更新操作的交易,在交易中指定了实现更新操作需要调用的智能合约、以及向智能合约传递的参数,交易还携带了客户端节点410的数字证书、签署的数字签名(例如,使用客户端节点410的数字证书中的私钥,对交易的摘要进行加密得到),并将交易广播到区块链网络200中的共识节点210。
区块链网络200中的共识节点210中接收到交易时,对交易携带的数字证书和数字签名进行验证,验证成功后,根据交易中携带的业务主体400的身份,确认业务主体400是否是具有交易权限,数字签名和权限验证中的任何一个验证判断都将导致交易失败。验证成功后签署节点210自己的数字签名(例如,使用节点210-1的私钥对交易的摘要进行加密得到),并继续在区块链网络200中广播。
区块链网络200中的共识节点210接收到验证成功的交易后,将交易填充到新的区块中,并进行广播。区块链网络200中的共识节点210广播的新区块时,会对新区块进行共识过程,如果共识成功,则将新区块追加到自身所存储的区块链的尾部,并根据交易的结果更新状态数据库,执行新区块中的交易:对于提交更新将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息的交易,在状态数据库中添加包括将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息的键值对。
业务主体500的业务人员在客户端节点510中登录,输入唤醒词以及相应的任务信息或者目标对象查询请求,客户端节点510根据唤醒词以及相应的任务信息或者目标对象查询请求生成对应更新操作/查询操作的交易,在交易中指定了实现更新操作/查询操作需要调用的智能合约、以及向智能合约传递的参数,交易还携带了客户端节点510的数字证书、签署的数字签名(例如,使用客户端节点510的数字证书中的私钥,对交易的摘要进行加密得到),并将交易广播到区块链网络200中的共识节点210。
区块链网络200中的共识节点210中接收到交易,对交易进行验证、区块填充及共识一致后,将填充的新区块追加到自身所存储的区块链的尾部,并根据交易的结果更新状态数据库,执行新区块中的交易:对于提交的更新某一将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息的交易,根据人工识别结果更新状态数据库中该唤醒词以及相应的任务信息对应的键值对;对于提交的查询某个唤醒词以及相应的任务信息的交易,从状态数据库中查询唤醒词以及相应的任务信息对应的键值对,并返回交易结果。
值得说明的是,在图7中示例性地示出了将用户标识、唤醒词集合、电子设备唤醒记录信息、电子设备任务执行信息直接上链的过程,但在另一些实施例中,对于唤醒词以及相应的任务信息的数据量较大的情况,客户端节点410可将唤醒词以及相应的任务信息的哈希以及相应的唤醒词以及相应的任务信息的哈希成对上链,将原始的唤醒词以及相应的任务信息以及相应的唤醒词以及相应的任务信息存储于分布式文件系统或数据库。客户端节点510从分布式文件系统或数据库获取到唤醒词以及相应的任务信息以及相应的唤醒词以及相应的任务信息后,可结合区块链网络200中对应的哈希进行校验,从而减少上链操作的工作量。
作为区块链的示例,参见图8,图8是本发明实施例提供的区块链网络200中区块链的结构示意图,每个区块的头部既可以包括区块中所有交易的哈希值,同时也包含前一个区块中所有交易的哈希值,新产生的交易的记录被填充到区块并经过区块链网络中节点的共识后,会被追加到区块链的尾部从而形成链式的增长,区块之间基于哈希值的链式结构保证了区块中交易的防篡改和防伪造。
下面说明本发明实施例提供的区块链网络的示例性的功能架构,参见图9,图9是本发明实施例提供的区块链网络200的功能架构示意图,包括应用层201、共识层202、网络层203、数据层204和资源层205,下面分别进行说明。
资源层205封装了实现区块链网路200中的各个节点210的计算资源、存储资源和通信资源。
数据层204封装了实现账本的各种数据结构,包括以文件系统中的文件实现的区块链,键值型的状态数据库和存在性证明(例如区块中交易的哈希树)。
网络层203封装了点对点(p2p,pointtopoint)网络协议、数据传播机制和数据验证机制、接入认证机制和业务主体身份管理的功能。
其中,p2p网络协议实现区块链网络200中节点210之间的通信,数据传播机制保证了交易在区块链网络200中的传播,数据验证机制用于基于加密学方法(例如数字证书、数字签名、公/私钥对)实现节点210之间传输数据的可靠性;接入认证机制用于根据实际的业务场景对加入区块链网络200的业务主体的身份进行认证,并在认证通过时赋予业务主体接入区块链网络200的权限;业务主体身份管理用于存储允许接入区块链网络200的业务主体的身份、以及权限(例如能够发起的交易的类型)。
共识层202封装了区块链网络200中的节点210对区块达成一致性的机制(即共识机制)、交易管理和账本管理的功能。共识机制包括pos、pow和dpos等共识算法,支持共识算法的可插拔。
交易管理用于验证节点210接收到的交易中携带的数字签名,验证业务主体的身份信息,并根据身份信息判断确认其是否具有权限进行交易(从业务主体身份管理读取相关信息);对于获得接入区块链网络200的授权的业务主体而言,均拥有认证中心颁发的数字证书,业务主体利用自己的数字证书中的私钥对提交的交易进行签名,从而声明自己的合法身份。
账本管理用于维护区块链和状态数据库。对于取得共识的区块,追加到区块链的尾部;执行取得共识的区块中的交易,当交易包括更新操作时更新状态数据库中的键值对,当交易包括查询操作时查询状态数据库中的键值对并向业务主体的客户端节点返回查询结果。支持对状态数据库的多种维度的查询操作,包括:根据区块向量号(例如交易的哈希值)查询区块;根据区块哈希值查询区块;根据交易向量号查询区块;根据交易向量号查询交易;根据业务主体的账号(向量号)查询业务主体的账号数据;根据通道名称查询通道中的区块链。
应用层201封装了区块链网络能够实现的各种业务,包括交易的溯源、存证和验证等。
由此,当用户更换电子设备以执行不同使用环境中的任务时,仅需要通过区块链网络即可以获取用户通过不同电子设备利用唤醒词执行相应的任务,方便用户在不同的终端中及时准确地对电子设备进行唤醒,提升唤醒处理的便捷性以及安全性。
下面以车载使用环境中的车载系统唤醒过程为例,对本申请所提供的电子设备唤醒方法进行说明,图10为本发明实施例提供的电子设备唤醒方法的使用场景示意图,本发明所提供的电子设备唤醒方法可以作为云服务的形式服务各个类型的客户(例如:封装于车载终端或者封装于不同的移动电子设备中),其中,用户界面中包括以不同类型用户的第一人称视角,对即时客户端中的任务信息处理环境进行观察的人称视角画面,所述用户界面中还包括任务控制组件和信息展示组件;通过所述用户界面利用信息展示组件展示所述唤醒语音特征相匹配的任务,以及相对的唤醒词;基于所述唤醒判决的结果,通过所述用户界面利用信息展示组件展示所述电子设备执行与所述唤醒语音特征相匹配的任务处理结果,以实现所述电子设备与用户的信息交互,例如,用户可以通过语音指令利用唤醒词,触发车载系统执行音乐播放功能或者唤醒车载微信中的地图小程序使用。
具体来说,参考图11,图11为本发明实施例提供的电子设备唤醒方法一个可选的流程示意图,具体包括:
步骤1101:获取用户语音信息中的fbank特征,通过第一神经网络模型确定作为测试特征的m帧特征。
其中,参考图12,图12为本发明实施例提供的电子设备唤醒方法的模型结构示意图,用户输入的语音信息提取对应的fbank特征后,可以输入第一神经网络模型进行逐帧的计算,并将lstm特定隐层输出缓存在一个大小为m帧的缓存当中,m为能够大致覆盖完整唤醒词的长度(如100帧),当第一神经网络模型的hmm解码网络通过置信度计算得到的置信度超过预设的阈值时,第一神经网络模型被触发,此时将该缓存中的m帧特征作为测试特征送入第二神经网络模型进行验证。
步骤1102:输入唤醒词文本,并确定唤醒词特征。
具体来说,当用户定制新唤醒词时,需要进行一个注册的过程,该过程中不需要进行语音输入,只需要输入唤醒词文本,该文本送至云端的tts服务器生成n个不同的唤醒词语音,这些语音经过第一神经网络模型处理后,可以得到n个m帧长度的特征,将这n个m帧特征平均后得到唤醒词特征。
步骤1103:计算测试特征的每一帧特征和唤醒词特征的每一帧分别对应的余弦相似度。
其中,参考图13,图13为本发明实施例提供的电子设备唤醒方法的模型结构示意图,可以将测试特征的每一帧特征和唤醒词特征的每一帧分别计算余弦相似度,可以得到一个n*n维的余弦相似度矩阵,由于第二神经网络模型可以采用dnn或lstm等模型结构,因此相似度矩阵中的特征可以直接展开作为一个n*n维特征送入一个dnn模型,也可以作为一个n帧特征(每一帧特征n维),送入一个lstm模型,模型的输出层节点数为2,即模型为二分类模型,其中类别0代表不唤醒,类别1代表唤醒,判决时根据类别1的得分是否超过预设的阈值来进行判决(lstm模型采用最后一帧结果作为最终结果)。由于该模型只进行二分类,因此可以在模型参数量很小的情况下得到很好的性能。
进一步地,该第二神经网络模型的训练数据包含正样本和负样本两部分,其中正样本包含若干个任意唤醒词的数据,每一个唤醒词录制少量语音数据,负样本为各种非唤醒词数据,其中可以加入大量音乐、电视等噪声及各种远场环境下的合成或真实数据(其中噪声数据通常不包含在第一神经网络模型训练数据中,因此可以与第一神经网络模型形成良好的互补)。数据的生成方法为,对正样本集中的每一个唤醒词,分别将对应的唤醒词正样本数据和全部负样本数据送入第一神经网络模型,当第一神经网络模型被触发时,保存此时缓存中的特征,与预先生成的该唤醒词对应的唤醒词特征计算,可以分别得到正样本和负样本的余弦相似度矩阵特征数据,第二神经网络模型利用以上数据可以在唤醒率略微下降的情况下,有效抑制掉大部分的误唤醒,从而显著提升唤醒性能。其中,由于声音处理模型可以固化或封装于车载终端或者与车载环境相匹配的电子设备中,车载环境的噪音声源相对固定,例如,同一品牌的同一型号车辆的发动机噪音在相同的噪音分贝区间中,车载环境的现实人声噪音的声源数量不超过和载人数,车载环境的虚拟人声噪音的声源数量与车载电子音乐的播放类型相关联。由于在声音处理模型的训练阶段所构造的训练样本均是针对车载是使用环境所设置,因此所获取的与车载环境相对应的带有噪声的语句样本与声音处理模型的实际使用环境更加吻合,使得经过训练的声音处理模型能够针对相应的车载使用环境,在全双工语音环境下,实现唤醒电子设备的判断,减少了对声音处理模型的训练时间,同时使得后经过训练的声音处理模型能够更好的在车载全双工语音环境下有效提升电子设备唤醒的效率与准确率,也减少了全双工环境的模型训练等待时间。
步骤1104:通过相应的二分类模型,获得相应的判决结果,以确定是否唤醒电子设备。
由此,通过本申请所提供的电子设备唤醒方法,第一神经网络的验证过程采用lstm声学模型和置信度判决的方案对输入语音进行唤醒判断,同时抽取lstm模型的特定隐层输出作为特征缓存;当第一神经网络触发后,第二神经网络模型将唤醒点及其周围一定时间窗内的缓存特征拼接作为测试特征;同时当用户设置唤醒词时,系统使用tts引擎合成该唤醒词的若干语音样本,将这些语音样本送入第一神经网络处理,并按同样方法将唤醒点及周围时间窗内的特定层输出拼接作为唤醒词特征,保存至设备端;在第二神经网络的验证过程中,首先将测试特征的每一帧特征和唤醒词特征的每一帧分别计算余弦相似度,可以得到一个余弦相似度矩阵特征,第二神经网络模型利用该特征,经过dnn或者lstm模型来进行是否唤醒的二分类判决,由此,不但扩大了方案的适用场景,同时可以使用少量唤醒词数据训练得到一个具有很好鲁棒性和泛化能力的模型,在训练中可以有效利用大量的音乐、电视等各种噪声场景数据来训练模型有效抑制掉大部分的误唤醒,显著提升唤醒性能。
有益技术效果:
本发明实施例提供的电子设备唤醒方法通过获取测试语音集合,并通过声音处理模型中的第一神经网络提取对应的测试语音特征集合;通过所述声音处理模型中的第一神经网络,基于所述测试语音特征集合,确定相应的测试特征;获取唤醒语音特征集合,并通过声音处理模型中的第一神经网络提取对应的唤醒词特征;根据所述测试特征和所述唤醒词特征,通过所述声音处理模型中的第二神经网络进行唤醒判决,由此,可以实现基于唤醒判决的结果,通过电子设备执行与唤醒语音特征相匹配的任务,并且能够实现在满足用户对唤醒词自定义的需求时,有效地降低计算复杂度提升响应速度,提升电子设备的唤醒性能,扩大了唤醒方案的适用场景,提升声音处理模型的鲁棒性和泛化能力。
以上所述,仅为本发明的实施例而已,并非用于限定本发明的保护范围,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



