
 商标分类
商标分类  商标转让
商标转让 
一种基于语义识别的智能评分方法、装置及存储介质与流程
 2021-01-28 16:01:00|
2021-01-28 16:01:00| 343|
343| 起点商标网
起点商标网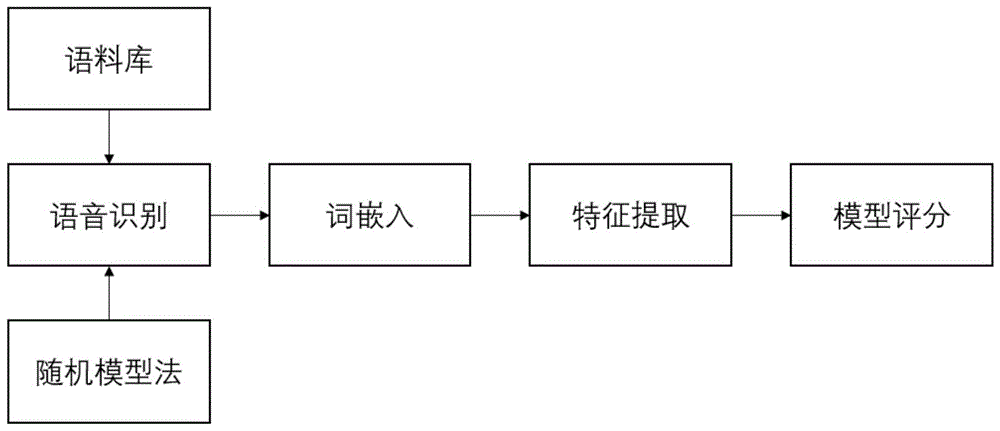
本发明涉及语义识别领域,具体涉及一种基于语义识别的智能评分方法、装置及存储介质。
背景技术:
各类大小型机械设备在实际应用中出现故障时,需要向设备报修系统报障进行维修,报修系统通常派技术人员与客户对接,并在与客户的沟通中提出维修意见。目前,报修系统的服务水平只有根据维修后设备的实际情况来评价,这种方法效率较低,且忽视了技术人员与客户交流时是否具有专业性和良好的沟通技巧,这些因素可以影响客户体验以及对该报修系统的评价。同样,在通信、银行等服务业中,存在客服与客户的电话沟通过程,通常客服的每次服务由客户来进行评分,但存在评分不够客观和很多客户不评分的问题。本发明的目的在于从语言的角度对这些服务的进行智能评分。
在机械领域,语义识别技术使用在如汽车语音导航和智能机器人在服务行业,语义识别技术则主要用于智能问答、业务办理等项目上,这些应用的目的主要在于去人工化。实际上,这些基于语义识别技术的应用项目并没有十分成熟,人工服务具有不可替代的优势。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种基于语义识别的智能分析方法、装置及存储介质。本发明以智能技术辅助人工服务,从语言的角度对机械设备报修系统的服务进行评分,可以有效提升报修系统的整体服务水平和客户体验。
本发明采用如下技术方案:
一种基于语义识别的智能评分方法,包括如下步骤:
s1对语音信息进行识别,将语音信息转化为文本形式,得到语音文本;
s2训练词向量,以数据矩阵的形式表示语音文本;
s3利用卷积神经网络提取语音文本的语义特征;
s4根据s2中截断补齐后的语音文本和语义特征,得到对服务水平进行评分。
所述s1中,语音信息是指维修技术人员与客户对接的语音记录。
优选的,将语音信息转化为文本形式是基于bbc语料库,采用随机模型法对语音信息进行转化。
优选的,s2中,训练词向量使用word2vec算法训练语音文本的词向量,对高频词汇进行随机降采样处理。
优选的,设置滑动窗口为5。
所述s3中,卷积神经网络使用卷积核的横向维度等于词汇量的维度,纵向维度为2、3和4,多个卷积核提取到的一维特征向量经过池化层后进行拼接,形成一维向量作为语义文本的语义特征。
优选的,s4根据语音文本和特征,得到对服务水平进行评分,具体是采用两层双向lstm网络,每个双向lstm神经元输出一个单维向量,在双向lstm网络与输出层之间加入了attention机制,输出结果经过attention机制给每个单维向量分配权重,最后一层为softmax层,输出报修系统的评分。
所述softmax层使用交叉熵计算损失函数。
一种实现基于语音识别的智能评分方法的评分装置,包括:
采集模块,采集客户与服务人员交流的语音及文本,并将语音信息转化为文本形式,得到语音文本;
词嵌入模块,训练词汇量,以数据矩阵的形式表示语音文本;
特征提取模块,对数据矩阵进行语义特征提取;
评分模块,将语义特征与截断补齐后的语音文本作为评分模块的输入得到对服务水平的评分。
一种存储介质,用于存储智能方法。
本发明的有益效果:
(1)将语义识别技术与人工服务结合起来,在保留了人工服务优点的同时,提出建立基于语义识别的智能评分方法对人工服务水平进行智能评分;
(2)利用卷积神经网络提取维修技术人员语音文本中的上下文信息特征,加入到输入数据中,评分模型中使用了attention机制,提高了模型对关键信息的重视程度,增强了语音文本的表达能力。
附图说明
图1是本发明的工作流程图;
图2是本发明的评分模型示意图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例
如图1及图2所示,基于随机模型法将语音数据转化为文本数据,该方法涉及到三种技术:动态时间规划(dtw),隐马尔可夫模型(hmm)理论和矢量量化(vq)技术。
一种基于语义识别的智能评分方法,用于机械领域中,保修人员与服务人员在交流过程中的语音及文字服务水平的评价方法。
包括如下步骤:
s1对语音信息进行识别,将语音信息转化为文本形式,得到语音文本;
主要识别记录维修技术人员的语音信息并转换为文本文字,语音信息主要是通讯app的语音聊天记录或者电话沟通记录,还可以采集文本信息,主要是通讯app的文字聊天记录。
s2训练词向量,以数据矩阵的形式表示语音文本;
利用word2vec训练文本的词向量,词向量的长度为200,高频词汇的随机降采样设置0.003,滑动窗口为5,词向量长度为200,加入负采样减少计算量。
完成词向量训练后文本可以表示成为一个数据矩阵,矩阵的每行代表一个词,行数即代表文本长度。
该步骤采用词嵌入(embedding)模块进行处理。
并对语音文本进行截断补齐,使不同输入到评分模型的语音文本长度均相同,补齐长度为语音文本长度的均值,长度不足的部分补0,超过的部分截断处理。
s3利用卷积神经网络提取语音文本的语义特征;
采用卷积神经网络挖掘语音文本的上下文信息,经过多个卷积的计算处理,从文本矩阵中提取到多个一维的特征向量,经过池化层后拼接成一个单维的特征向量,将特征向量拼接到语音文本中,作为评分模型的输入。
卷积神经网络的构成包括多个卷积核、最大池化层及全连接层。
s4根据s2中截断补齐后语音文本和语义特征,得到对服务水平进行评分
是基于双向lstm网络搭建,网络的层数为2。模型在双向lstm网络与输出层之间加入了attention机制,用于突出一些关键词汇的作用,如“自由度”、“使用寿命”等词语在体现专业性上更为关键。经过attention机制赋予关键词更高的权重,利用softmax层对语音文本进行评分,softmax层使用交叉熵计算损失函数,输出1×5的向量,可以对报修系统的服务水平进行评分,评分结果从“不合格”到“优秀”分为五个等级。
如图2所示,双向lstm层数为2,隐含层神经元数为256,dropout设置0.2,attention机制的初始权重均为1,pooling选择maxpooling,softmax输出向量的维度为5.
一种基于语义识别的智能评分装置,包括
采集模块,采集客户与服务人员交流的语音及文本,并将语音信息转化为文本形式,得到语音文本;
词嵌入模块,训练词汇量,以数据矩阵的形式表示语音文本;
特征提取模块,对数据矩阵进行语义特征提取;
评分模块,将语义特征与截断补齐后的语音文本作为评分模块的输入得到对服务水平的评分。
一种存储介质,用于存储本方法软件程序的介质。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



