
 商标分类
商标分类  商标转让
商标转让 
智能语音识别方法及装置与流程
 2021-01-28 16:01:47|
2021-01-28 16:01:47| 260|
260| 起点商标网
起点商标网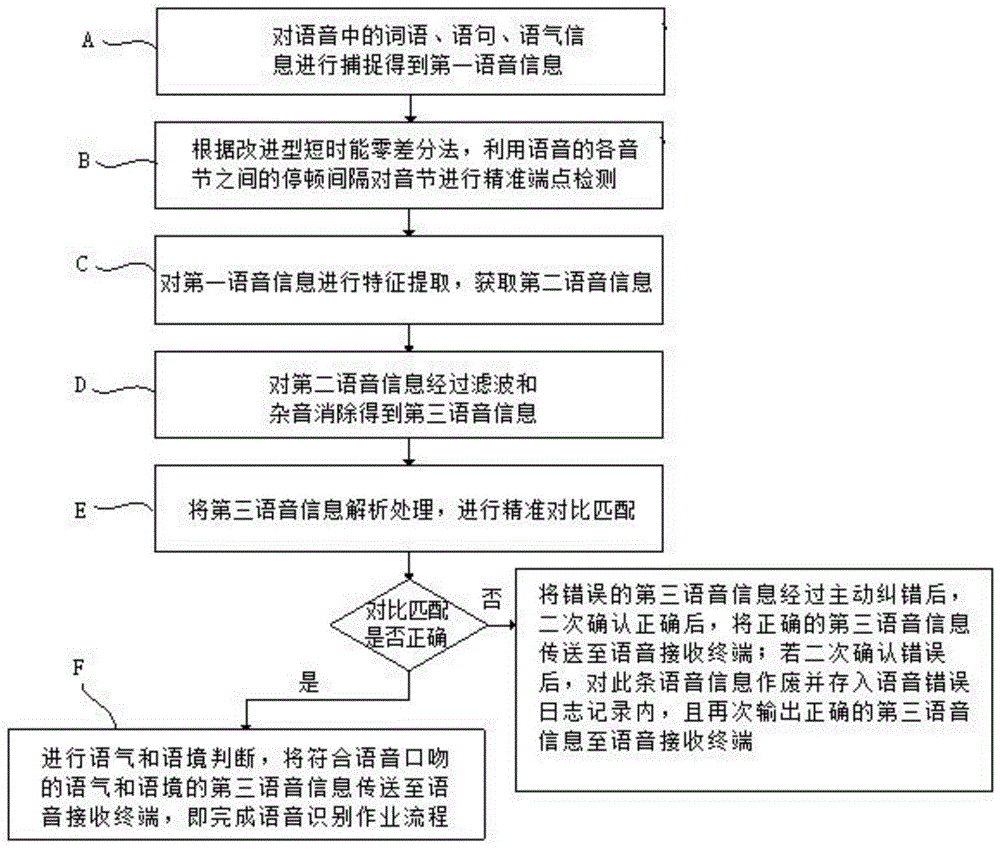
本申请涉及语音识别技术领域,具体涉及智能语音识别方法及装置。
背景技术:
语音,即语言的物质外壳,是语言的外部形式,是最直接地记录人的思维活动的符号体系,它是人的发音器官发出的具有一定社会意义的声音,语音的物理基础主要有音高、音强、音长、音色,这也是构成语音的四要素。
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
随着现在科技技术的日益发展,在智能领域中,语音识别为重要一环,而现有的语音识别方法在实施过程中,错误率较高,易由于语音文字和字节存在高度相似,易造成识别错误,从而降低语音的匹配识别精准度,同时也体现不出语音的主要含义,大多为语气统一的机器式口吻识别,不可根据语音中语气、字里行间以及阴阳顿挫停顿时间来判断语音的感情,从而满足不了语音的多感情识别需求。
技术实现要素:
本申请实施例提供一种智能语音识别方法,包括:对语音中的词语、语句、语气信息进行捕捉得到第一语音信息;根据改进型短时能零差分法,利用所述语音的各音节之间的停顿间隔对音节进行精准端点检测;对所述第一语音信息进行特征提取,获得第二语音信息;对所述第二语音信息经过滤波和杂音消除得到第三语音信息;将所述第三语音信息解析处理,进行精准对比匹配;在所述第三语音信息匹配正确后,进行语气和语境判断,将符合语音口吻的语气和语境的所述第三语音信息传送至语音接收终端,即完成语音识别作业流程。
根据一些实施例,所述智能语音识别方法还包括:获取所述语音中的常用词组、常用语句以及常用词音节,同时也获取所述语音中的关键词组、关键语句以及关键词音节;对所述常用词语、常用语句、常用语词音节、关键词语、关键语句、关键词音节进行特征提取放进所述第二语音信息。
根据一些实施例,所述智能语音识别方法还包括:所述第三语音信息统一录入大数据库。
根据一些实施例,所述将所述第三语音信息解析处理,进行精准对比匹配,包括:采用云计算对所述第三语音信息进行精准对比匹配;以所述大数据库内的原始录入信息和后入信息作为根据,判断对比匹配是否正确。
根据一些实施例,所述智能语音识别方法还包括:在所述第三语音信号数据匹配发生错误时,将错误的所述第三语音信息经过主动纠错后,二次确认正确后,将正确的所述第三语音信息传送至语音接收终端;若二次确认错误后,对此条语音信息作废并存入语音错误日志记录内,且再次输出正确的所述第三语音信息至语音接收终端。
根据一些实施例,所述智能语音识别方法,其中,所述常用词组、常用语句以及常用词音节包括:称谓词组、指代词组、语气助词、谦辞和敬辞词组、惯用成语以及其他词组,其中,称谓词组包括“你”、“我”、“他”、“你们”、“我们”、“他们”、“父亲”、“母亲”以及“妻子”;指代词组为用抽象概念代替具体事物,语气助词包括“啊”、“呀”以及“了”;谦辞和敬辞词组为尊敬和谦虚词组,可包括“敬爱的”、“小女”以及“愚见”;惯用成语为“步步高升”、“心想事成”以及“万事如意”;其他词组为日常生活语句;所述关键词语、关键语句、关键词音节包括多音词组、冷僻词组、一语双关词组、多重含义词组、错别和混淆词组以及其他关键词组。
根据一些实施例,所述特征提取采用梅尔频率倒谱系数方式提取代表语音基本特征的参数作为所述第二语音信息。
根据一些实施例,所述大数据库的输出端单向电连接有存储模块,所述存储模块的数量至少为四块,每块所述存储模块的容量最小为2tb,所述存储模块的存储周期为90天。
根据一些实施例,所述语境判断包括“喜”、“怒”、“忧”、“惧”、“爱”、“憎”以及“欲”,且所述判断的依据为语音中的语气、语境以及字节停顿时间。
本申请实施例还提供一种智能语音识别装置,包括语言捕捉模块、音节端点检测模块、提取模块、滤波和杂音消除模块、服务器和语境情感预测模块,所述语言捕捉模块对语音中的词语、语句、语气信息进行捕捉得到第一语音信息;所述音节端点检测模块根据改进型短时能零差分法,利用所述语音的各音节之间的停顿间隔对音节进行精准端点检测;所述提取模块对所述第一语音信息进行特征提取,获得第二语音信息;所述滤波和杂音消除模块对所述第二语音信息经过滤波和杂音消除得到第三语音信息;所述服务器将所述第三语音信息解析处理,进行精准对比匹配;所述语境情感预测模块在所述第三语音信号数据匹配正确后,进行语气和语境判断,将符合语音口吻的语气和语境的信号数据传送至语音接收终端,即完成语音识别作业流程。
本申请实施例提供的技术方案,通过对语音中的词语、语句、语气信息进行捕捉,可利用语音信号各音节之间的停顿间隔对音节进行精准端点检测,去除杂波,提升信息的清晰度和准确度,对正确语音信息进行快速精准识别匹配传递,同时也可对语音信息进行多感情识别,对匹配错误的语音信息进行二次纠错,进一步增强语音信息识别的精准度,防止出现语音识别匹配错误。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种智能语音识别方法的流程示意图。
图2为本申请实施例提供的另一种智能语音识别方法的流程示意图。
图3为本申请实施例提供的一种智能语音识别装置的示意图。
图4为本申请实施例提供的常用词组、常用词音节的系统框架图。
图5为本申请实施例提供的关键词组、关键词音节的系统框架图。
图6为本申请实施例提供的音节端点检测模块的检测结果图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
应当理解,本申请的权利要求、说明书及附图中的术语“第一”、“第二”等是用于区别不同对象,而不是用于描述特定顺序。本申请的说明书和权利要求书中使用的术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
图1为本申请实施例提供的一种智能语音识别方法的流程示意图,流程执行如下。
a、对语音中的词语、语句、语气信息进行捕捉得到第一语音信息。
b、根据改进型短时能零差分法,利用语音的各音节之间的停顿间隔对音节进行精准端点检测。
改进型短时能零差分法具体建立在短时能量和短时平均过零率差分阔值相互结合的基础上,可对语音信息进行精准检测,提升语音音节检测的精准度。
音节端点检测模块的检测算法如下:
用en表示第n帧信号xn(m)的语音短时能量,且m为瞬时信号端点采集点,如下公式所示。
一帧语音信号中波形通过零电平的频率称之为短时过零率,如下公式所示。
公式中,sgn【·】为符号函数,即
语音信号帧的非语音部分,非语音短时能量mn和短时平均过零率zn变化缓慢,而在非语音和语音部分的过渡部分这两个参数急剧变化,因此通过判断这两个参数就可以找到语音信号起始点和结束点,由于语音信号的浊音短时能量和短时过零率变化明显,而清音只有短时过零率变化明显。
c、对第一语音信息进行特征提取,获得第二语音信息。
对第一语音信息进行特征提取,采用梅尔频率倒谱系数方式提取代表语音基本特征的参数作为第二语音信息。
d、对第二语音信息经过滤波和杂音消除得到第三语音信息。
e、将第三语音信息解析处理,进行精准对比匹配。
采用云计算对第三语音信息进行精准对比匹配,以大数据库内的原始录入信息和后入信息作为根据,判断对比匹配是否正确。
f、在第三语音信息匹配正确后,进行语气和语境判断,将符合语音口吻的语气和语境的第三语音信息传送至语音接收终端,即完成语音识别作业流程。
语境判断包括“喜”、“怒”、“忧”、“惧”、“爱”、“憎”以及“欲”,且判断的依据为语音中的语气、语境以及字节停顿时间。
在第三语音信号数据匹配发生错误时,将错误的第三语音信息经过主动纠错后,二次确认正确后,将正确的第三语音信息传送至语音接收终端;若二次确认错误后,对此条语音信息作废并存入语音错误日志记录内,且再次输出正确的所述第三语音信息至语音接收终端。
图2为本申请实施例提供的另一种智能语音识别方法的流程示意图,流程执行如下。
a、对语音中的词语、语句、语气信息进行捕捉得到第一语音信息。
a1、获取语音中的常用词组、常用语句以及常用词音节,同时也获取语音中的关键词组、关键语句以及关键词音节。
常用词组、常用语句以及常用词音节如图4所示,包括:称谓词组、指代词组、语气助词、谦辞和敬辞词组、惯用成语以及其他词组。其中,称谓词组包括“你”、“我”、“他”、“你们”、“我们”、“他们”、“父亲”、“母亲”以及“妻子”。指代词组为用抽象概念代替具体事物,语气助词包括“啊”、“呀”以及“了”。谦辞和敬辞词组为尊敬和谦虚词组,可包括“敬爱的”、“小女”以及“愚见”。惯用成语为“步步高升”、“心想事成”以及“万事如意”。其他词组为日常生活语句。
关键词语、关键语句、关键词音节如图5所示,包括多音词组、冷僻词组、一语双关词组、多重含义词组、错别和混淆词组以及其他关键词组,囊括各类关键词组和关键词音节,提高关键词组和关键词音节的整体全面度。
b、根据改进型短时能零差分法,利用语音的各音节之间的停顿间隔对音节进行精准端点检测。
改进型短时能零差分法具体建立在短时能量和短时平均过零率差分阔值相互结合的基础上,可对语音信息进行精准检测,提升语音音节检测的精准度。
音节端点检测模块的检测算法如下:
用en表示第n帧信号xn(m)的语音短时能量,且m为瞬时信号端点采集点,如下公式所示。
一帧语音信号中波形通过零电平的频率称之为短时过零率,如下公式所示。
公式中,sgn【·】为符号函数,即
音节端点检测模块的检测结果图如图6所示,横坐标为时间,纵坐标为音节端点范围。
语音信号帧的非语音部分,非语音短时能量mn和短时平均过零率zn变化缓慢,而在非语音和语音部分的过渡部分这两个参数急剧变化,因此通过判断这两个参数就可以找到语音信号起始点和结束点,由于语音信号的浊音短时能量和短时过零率变化明显,而清音只有短时过零率变化明显。
c、对第一语音信息进行特征提取,获得第二语音信息。
对第一语音信息进行特征提取,采用梅尔频率倒谱系数方式提取代表语音基本特征的参数作为第二语音信息。
c1、对常用词语、常用语句、常用语词音节、关键词语、关键语句、关键词音节进行特征提取放进第二语音信息。
对常用词语、常用语句、常用语词音节、关键词语、关键语句、关键词音节进行特征提取,采用梅尔频率倒谱系数方式提取代表语音基本特征的参数作为第二语音信息。
d、对第二语音信息经过滤波和杂音消除得到第三语音信息。
d1、第三语音信息统一录入大数据库。
e、将第三语音信息解析处理,进行精准对比匹配。
采用云计算对第三语音信息进行精准对比匹配,以大数据库内的原始录入信息和后入信息作为根据,对云计算对比匹配加以佐证,判断对比匹配是否正确。
f、在第三语音信息匹配正确后,进行语气和语境判断,将符合语音口吻的语气和语境的第三语音信息传送至语音接收终端,即完成语音识别作业流程。
语境判断包括“喜”、“怒”、“忧”、“惧”、“爱”、“憎”以及“欲”,且判断的依据为语音中的语气、语境以及字节停顿时间,满足语音识别匹配的多感情需求,增多语音的情感丰富度。
第三语音信息经过语气和语境判断,根据语音词语的语气、字里行间以及阴阳顿挫停顿作为判断依据,将符合语音口吻的语气和语境的第三语音信息传送至语音接收终端,若传送期间出现传输失败、语音字节出现丢失情况,对语音信号数据进行及时撤回,再次将正确的语音信号数据传送至语音接收终端,即完成语音识别作业流程。
在第三语音信号数据匹配发生错误时,将错误的第三语音信息经过主动纠错后,二次确认正确后,将正确的第三语音信息传送至语音接收终端;若二次确认错误后,对此条语音信息作废并存入语音错误日志记录内,且再次输出正确的所述第三语音信息至语音接收终端。
语音错误日志记录包括错字记录日志、错句记录日志以及音节错误记录日志,可分别对错字、错句以及音节错误进行日志记录存储,且语音错误日志的运行系统为java软件,语音错误日志含有时间戳,可对每条日志信息进行时间标记,便于使用者后期根据时间进行查询语音错误日志记录中所需信条,且语音错误日志的错误找寻时间小于5min,加快使用者找寻错误日志信条的速率,节省错误日志信条的用时。
图3为本申请实施例提供的一种智能语音识别装置的示意图。
智能语音识别装置包括语言捕捉模块、音节端点检测模块、提取模块、滤波和杂音消除模块、服务器、语境情感预测模块。
语言捕捉模块对语音中的词语、语句、语气信息进行捕捉得到第一语音信息。音节端点检测模块根据改进型短时能零差分法,利用语音的各音节之间的停顿间隔对音节进行精准端点检测。提取模块对第一语音信息进行特征提取,获得第二语音信息。滤波和杂音消除模块对第二语音信息经过滤波和杂音消除得到第三语音信息。服务器将第三语音信息解析处理,进行精准对比匹配。语境情感预测模块在第三语音信号数据匹配正确后,进行语气和语境判断,将符合语音口吻的语气和语境的信号数据传送至语音接收终端,即完成语音识别作业流程。
大数据库的输出端单向电连接有存储模块,所述存储模块的数量至少为四块,每块所述存储模块的容量最小为2tb,所述存储模块的存储周期为90天。
以上对申请的具体实施例进行了描述。需要理解的是,申请并不局限于上述特定实施方式,其中未尽详细描述的设备和结构应该理解为用本领域中的普通方式予以实施;本领域技术人员可以在权利要求的范围内做出各种变形或修改做出若干简单推演、变形或替换,这并不影响申请的实质内容。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



