
 商标分类
商标分类  商标转让
商标转让 
基于注意力机制和双路径深度残差网络的声场景分类方法与流程
 2021-01-28 16:01:02|
2021-01-28 16:01:02| 352|
352| 起点商标网
起点商标网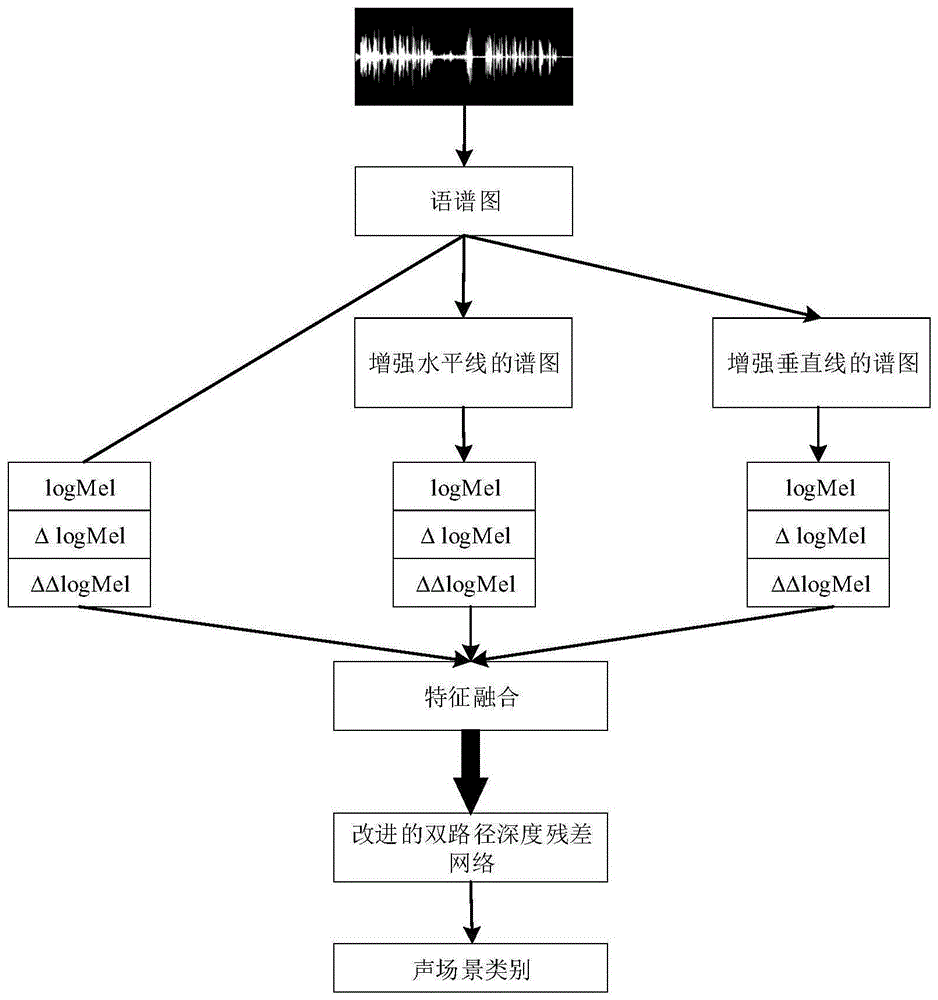
本发明属于声场景分类技术领域,具体涉及一种基于注意力机制和双路径深度残差网络的声场景分类方法。
背景技术:
声场景分类,就是训练计算机通过声音中所包含的信息将声音正确的划分到其所属的场景中。声场景分类技术在物联网设备、智能助听器、自动驾驶等领域有着广泛的应用,对声场景分类进行深入的研究具有十分重要的意义。
声场景分类最开始属于模式识别的一个子领域。上世纪九十年代,sawhney和maes首次提出了声场景分类的概念。他们录制了一份包含人行道、地铁、餐厅、公园、街道五类声场景的数据集,sawhney从录制的音频中提取了功率谱密度、相对光谱、滤波器组的频带三类特征,之后采用k最邻近和循环神经网络算法进行分类,取得了68%的准确率。二十世纪初期,机器学习领域快速发展,越来越多的学者尝试使用机器学习的方法来进行声音场景的划分。支持向量机、决策树等机器学习算法逐渐替代传统的hmm模型,被广泛的应用在了声场景分类和声事件检测任务中。同时,一些集成学习的方法如随机森林、xgboost进一步提升了声场景分类的效果。2015年,phan等人将声场景分类问题转化为回归问题,搭建了基于随机森林回归的模型,并在itc-irst和upc-talp两个数据库上分别将检测错误率降低了6%和10%。2012年,在imagenet图像分类竞赛中,krizhevsky提出了alexnet模型并一举获得了冠军。alexnet的巨大的成功,引发了深度学习的热潮,研究者也逐渐开始将深度学习的方法引入到声场景分类任务中。
此外,可以被用于声场景分类的声学特征有很多,如何将这些特征进行融合,以匹配深度学习的模型是未来一个重要的研究方向。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明公开了一种基于注意力机制和双路径深度残差网络的声场景分类方法,对三种变换后的信号分别求取对数梅尔谱图及其一阶二阶差分谱图,将其融合后分离出高频和低频部分,再输入具有注意力机制的双路径深度残差网络模型中,能够有效的捕获对分类结果有重要的影响的特征图,提升了声场景分类系统的准确性和鲁棒性。
技术方案:本发明采用如下技术方案:一种基于注意力机制和双路径深度残差网络的声场景分类方法,其特征在于,包括如下步骤:
步骤1、对原始语音信号进行预处理并计算原始语音频谱图,对原始语音频谱图中的水平线和垂直线分别进行增强得到水平频谱图和垂直频谱图,对水平频谱图和垂直频谱图分别变换得到新的两路时域信号;
步骤2、分别计算原始语音信号、新的两路时域信号的对数梅尔谱图以及一阶差分对数梅尔谱图和二阶差分对数梅尔谱图,并在通道维度上进行融合得到融合谱图;
步骤3、在频率轴上将融合谱图平均分割为高频谱图和低频谱图;
步骤4、搭建带有注意力层的双路径深度残差网络;
步骤5、将所述步骤3中的高频谱图和低频谱图输入步骤4中的深度残差网络,输出原始语音信号所属的声场景类别。
优选的,所述步骤1中:
其中,xh为水平频谱图,xp为垂直频谱图,x为原始语音频谱图;κ和λ为权重平滑因子;f和t分别表示频率和时间;最小化代价函数j,令θj/θxh=0和θj/θxp=0,则可求得水平频谱图xh和垂直频谱图xp。
优选的,所述步骤2中:
so(t,f)=(sx(t,f),sh(t,f),sp(t,f))
其中,sa表示融合谱图;sx表示原始语音信号的对数梅尔谱图以及一阶差分对数梅尔谱图和二阶差分对数梅尔谱图;sh表示由水平频谱图生成的对数梅尔谱图以及一阶差分对数梅尔谱图和二阶差分对数梅尔谱图;sp表示由垂直频谱图生成的对数梅尔谱图以及一阶差分对数梅尔谱图和二阶差分对数梅尔谱图;t和f分别表示时间轴和频率轴。
优选的,所述步骤5包括如下步骤:
步骤51、高频谱图和低频谱图输入深度残差网络的双路径后分别输出高频特征图和低频特征图;
步骤52、高频特征图和低频特征图在频率轴维度上进行融合得到融合特征图,通过融合特征图得到多通道特征图,通过多通道特征图计算得到注意力系数;
步骤53、将注意力系数应用于多通道特征图得到加权特征图;
步骤54、将加权特征图展开为一维的特征向量,通过特征向量输出原始语音信号所属的声场景类别。
优选的,所述步骤52中:
mp(t,f)=(mp1(t,fl),mp2(t,fh))
其中,mp(t,f)表示融合特征图;mp1(t,fl)和mp2(t,fh)分别表示低频特征图和高频特征图;t表示特征图的高度;f、fl和fh分别表示融合特征图、低频特征图和高频特征图的宽度。
优选的,所述步骤52中:
α=σ(w2relu(w1z))
其中,α∈rc表示注意力系数向量;
优选的,所述步骤53中:
其中,
优选的,深度残差网络的每个路径中包括残差块;
残差块中包括依次连接的批量归一化层、relu激活层、卷积层、批量归一化层、relu激活层和卷积层,输出低频特征图和高频特征图;
低频特征图和高频特征图融合后输入依次连接的批量归一化层、relu激活层和卷积块,卷积块中包括依次连接的卷积层和批量归一化层,输出多通道特征图;
多通道特征图输入依次连接的全局平均池化层和全连接层,输出注意力系数向量;
注意力系数向量和多通道特征图合并后输入依次连接的平铺层、全连接层和softmax层,输出分类结果。
优选的,所述步骤1中预处理包括:对原始语音信号降采样或升采样到48khz,然后进行预加重、分帧和加窗处理;在分帧时,每2048个采样点分为一帧,帧重叠率为50%;在加窗时,采用的窗函数为汉明窗。
有益效果:本发明具有如下有益效果:
(1)本发明将原始音频、增强语谱图水平线的信号和增强语谱图垂直线的信号的对数梅尔谱图和差分谱图进行融合,使得融合谱图不仅体现出了音频的静态特性、动态特性,而且增强了特征的表达能力,有效提升了声场景分类的准确率;
(2)、本发明将融合谱图中的高频部分和低频部分进行分离,并搭建双路径的深度残差网络分别建模,极大的体现了频谱图中高频和低频具有不同的物理含义这一特点;高低频分离建模使得模型可以更好的捕获高频分量、低频分量的时频特性,利用这些特性能更准确的区分出相似的声场景;
(3)、本发明在深度残差网络中引入注意力机制,对多通道的融合特征图在通道维度上进行注意力加权操作,使得对最终分类结果有着积极作用的特征图在后面的全连接层中获得更高的关注度,有效提升了模型的分类效果,使得整个系统的识别率极大提升。
附图说明
图1为本发明改进的声场景分类方法的总体结构图;
图2为本发明带有注意力层的双路径深度残差网络结构图;
图3为本发明的注意力网络结构图;
图4为本发明方法和其他4类声场景分类方法分类结果的对比图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
本发明公开了一种基于注意力机制和双路径深度残差网络的声场景分类方法,如图1所示,包括如下步骤:
步骤1、对音频样本中的原始语音信号x进行预处理,然后进行傅里叶变换得到原始语音频谱图x,通过分别增强原始语音频谱图x中的水平线和垂直线将其分解为新的水平频谱图xh和垂直频谱图xp。
预处理包括将所有音频样本中的原始语音信号统一降采样或升采样到48khz,然后进行预加重、分帧和加窗处理。在分帧时,每2048个采样点分为一帧,帧重叠率为50%;在加窗时,所采用的窗函数为汉明窗。
因为水平频谱图xh和垂直频谱图xp的和等于信号的能量谱,所以在求解水平频谱图xh和垂直频谱图xp时可以构建代价j(xh,xp):
其中,κ和λ为权重平滑因子;f和t分别表示频率和时间;最小化代价函数j,令
步骤2、将水平频谱图xh和垂直频谱图xp进行傅里叶反变换,得到新的由水平频谱图生成的时域信号xh和由垂直频谱图生成的时域信号xp,然后分别提取由水平频谱图生成的时域信号xh、由垂直频谱图生成的时域信号xp和原始语音信号x的对数梅尔谱图,并进一步计算其各自的一阶差分对数梅尔谱图和二阶差分对数梅尔谱图。
步骤3、将步骤2中求得的三组对数梅尔谱图、一阶差分对数梅尔谱图和二阶差分对数梅尔谱图进行融合,并按照高频和低频进行切分。
步骤3将步骤2中由水平频谱图生成的时域信号xh、由垂直频谱图生成的时域信号xp和原始语音信号x的对数梅尔谱图及其一阶差分对数梅尔谱图、二阶差分对数梅尔谱图在通道维度上进行拼接,形成融合谱图sa(t,f):
sa(t,f)=(sx(t,f),sh(t,f),sp(t,f))
其中,sx、sh和sp分别表示原始语音信号x、由水平频谱图生成的时域信号xh和由垂直频谱图生成的时域信号xp的三个谱图,sa表示融合谱图,t和f分别表示时间轴和频率轴。
融合谱图体现出原始语音信号的静态特性、动态特性,具有良好特征表达能力。
然后在频率轴上将融合谱图sa(t,f)平均切割为高频谱图sa(t,fl)和低频谱图sa(t,fh),其中fl和fh分别表示低频谱图和高频谱图的频率轴。
步骤4、搭建带有注意力层的双路径的深度残差网络模型。
步骤5、将步骤3中得到的高频和低频谱图输入步骤4中搭建好的深度残差网络,得到最终的音频场景标签。
双路径的深度残差网络对高频谱图和低频谱图分别进行建模,并将两个路径分别获得的特征图在频率轴维度上进行融合:
mp(t,f)=(mp1(t,fl),mp2(t,fh))
其中,mp1(t,fl)、mp2(t,fh)和mp(t,f)分别表示低频路径p1输出的低频特征图、高频路径p2输出的高频特征图和融合特征图。
本发明的一种实施例中,图2为本发明带有注意力层的高低频双路径的深度残差网络的结构图。深度残差网络模型中每个路径均包含4个残差块,残差块中的结构依次为:批量归一化(bn)层、relu激活层、卷积层、bn层、relu激活层、卷积层,两个卷积层中卷积核的大小均为3×3。通过4个残差块进行特征提取之后,将两个路径上所获得的特征图在频率轴维度上进行融合,然后将融合特征图mp(t,f)通过bn层、relu激活层、两个卷积块,最终获得包含768个通道的多通道特征图m(t,f),卷积块中的结构依次为卷积层、bn层,卷积层中卷积核的大小为1×1。
图3为注意力网络结构图。将多通道特征图m(t,f)送入注意力网络,在通道维度上进行注意力加权,在注意力网络中依次进行以下操作:
(1)对输入的多通道特征图m(t,f)在通道维度上进行全局平均池化,将一个通道上的整个空间特征编码为一个全局特征:
上式中m表示多通道特征图,z∈rc是全局平均池化之后的输出向量,t、f和c分别表示多通道特征图的高度、宽度和通道数。
(2)将长度为c的一维特征向量z输入包含两层的全连接层的dnn模型,并计算输出:
α=fdnn(z,w)=σ(g(z,w))=σ(w2relu(w1z))
上式中α∈rc是dnn模型的输出,即注意力系数向量。
(3)将得到的注意力系数向量作用于多通道特征图的各通道,对通道进行加权,得到加权特征图
其中,
将加权特征图通过平铺(flatten)层展开为一个一维的特征向量,最后通过全连接层和softmax层得到模型的输出,即原始语音信号所属的场景类别。
图4显示了本发明改进的声场景分类方法和其他4类声场景分类方法分类结果对比。根据本发明改进的声场景分类方法,在数据集上对比了5种分类模型:高斯混合模型(gmm)、k最邻近(knn)、支撑向量机(svm)、随机森林(rf)和本发明提出的双路径的深度残差网络模型。使用从音频中提取的988维特征向量作为gmm、knn、svm、rf模型的输入,其中gmm中高斯分布的个数为12个,每个高斯分布具有不同的标准协方差矩阵;knn模型在分类时最邻近的k取7;svm的惩罚系数为1.8,采用高斯核函数,分类方式为ovo,即一对一分类;rf中包含的决策树个数为200,决策树在进行节点分裂时采用基尼指数作为最优特征选择标准。基尼指数表示在样本集合中一个随机选中的样本被分错的概率,基尼指数=样本被选中的概率×样本被分错的概率,基尼指数的性质与信息熵一样,度量随机变量的不确定度的大小:基尼指数越大,表示数据的不确定性越高;基尼指数越小,表示数据的不确定性越低;基尼指数为0,表示数据集中的所有样本都是同一类别。所选取的原始语音数据集中包含机场、公共汽车、地铁、地铁站、公园、广场、购物商场、步行街道、交通街道和电车轨道10类声场景,共14400条音频数据。实验结果表明,本发明所提出的改进的声场景分类方法在数据集上达到了81.6%的平均准确率,远高于其他4种声场景识别方法。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



