
 商标分类
商标分类  商标转让
商标转让 
智能体装置及其控制方法、智能体系统、存储介质与流程
 2021-01-28 16:01:34|
2021-01-28 16:01:34| 307|
307| 起点商标网
起点商标网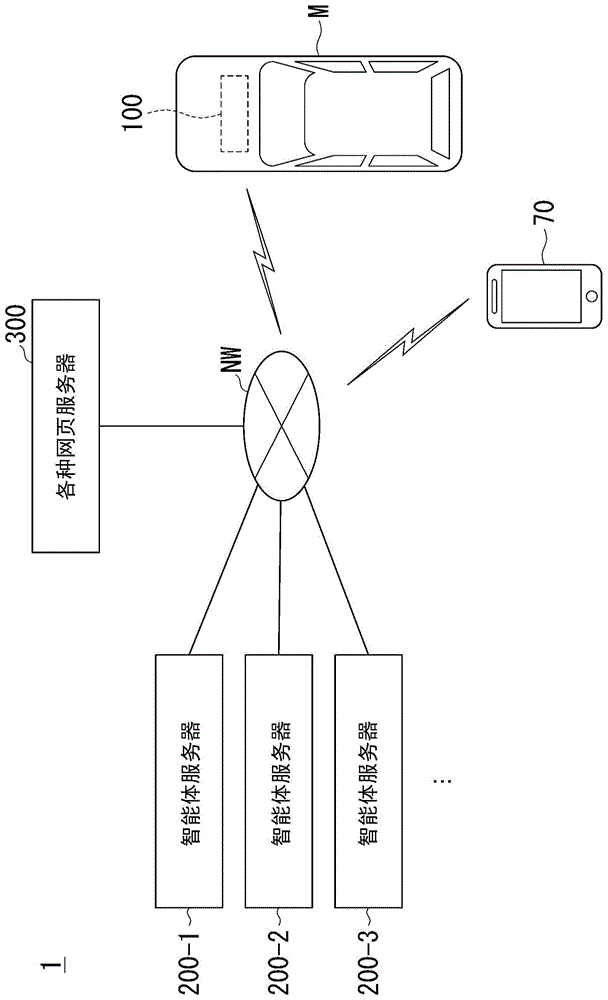
本发明涉及智能体装置、智能体系统、智能体装置的控制方法及存储介质。
背景技术:
以往,公开了与智能体功能相关的技术,所述智能体功能一边与车辆的利用者进行对话,一边提供与利用者的要求相应的与驾驶支援相关的信息、车辆的控制、其他应用程序等(日本特开2006-335231号公报)。
近年来,关于智能体功能向车辆的搭载,正在推进实用化,但是,关于针对每个车辆搭载的智能体功能中的服务的提供,没有充分进行研究。因此,在以往的技术中,关于智能体功能,存在使用性能不好的情况。
技术实现要素:
发明要解决的课题
本发明是考虑这样的情形而完成的,目的之一在于,提供一种能够提高智能体的使用性能的智能体装置、智能体系统、智能体装置的控制方法及存储介质。
用于解决课题的方案
本发明的智能体装置、智能体系统、服务器装置、智能体装置的控制方法及存储介质采用了以下的结构。
(1):本发明的一方案的智能体装置具备:显示控制部,其在智能体启动了的情况下使第一显示部显示智能体图像,所述智能体根据声音,提供包含使输出部输出通过声音进行的响应的服务;以及控制部,其基于接受通过声音进行的输入的外部终端所接受到的声音的大小,执行使第二显示部显示所述智能体图像的特定控制。
(2):在上述(1)的方案中,在接受通过声音进行的输入的外部终端所接受到的声音的大小小于规定的大小的情况下,所述控制部对所述第二显示部进行所述特定控制。
(3):在上述(1)或(2)的方案中,所述第二显示部由所述外部终端所具有。
(4):在上述(1)~(3)中的任一方案中,在所述控制部执行特定控制的情况下,所述显示控制部不使所述第一显示部显示所述智能体图像。
(5):在上述(1)~(4)中的任一方案中,在所述控制部不执行特定控制的情况下,所述显示控制部使所述第一显示部显示所述智能体图像。
(6):在上述(1)~(5)中的任一方案中,即便在所述外部终端所接受到的声音的大小小于规定的大小的情况下,在接受声音的输入的接受部接受到声音时,所述控制部也使所述第一显示部显示所述智能体图像。
(7):在上述(6)的方案中,所述接受部是设置于车辆、设施或规定位置的固定设置型的话筒。
(8):在上述(1)~(7)中的任一方案中,所述第一显示部是设置于车辆、设施或规定位置的固定设置型的显示部。
(9):在上述(1)~(8)中的任一方案中,所述外部终端是便携式的终端装置。
(10):在上述(1)~(9)中的任一方案中,在所述控制部执行着所述特定控制的情况下,所述显示控制部根据由所述外部终端发送的指示信息,使所述第一显示部显示所述智能体图像。
(11):在上述(1)~(9)中的任一方案中,所述智能体装置与所述外部终端协作,所述智能体根据所述外部终端所接受到的声音,提供包含使输出部输出通过声音进行的响应的服务。
(12):在上述(1)~(11)中的任一方案中,所述智能体装置与所述外部终端协作,所述显示控制部根据所述外部终端所接受到的规定的大小以上的声音,使所述第一显示部显示所述智能体图像,所述控制部根据所述外部终端所接受到的规定的大小以上的声音,不执行所述特定控制。
(13):本发明的一方案的智能体装置具备:显示控制部,其在智能体启动了的情况下,使以不限制视认者的形态设置的第一显示部显示智能体图像,所述智能体根据声音,提供包含使输出部输出通过声音进行的响应的服务;以及控制部,其在接受通过声音进行的输入的第一终端所接受到的声音的大小小于规定的大小的情况下,执行用于使第二显示部显示智能体图像的特定控制,所述第二显示部以将视认者限制为输入了所述第一终端所接受到的声音的利用者的形态设置。
(14):本发明的一方案的智能体系统包括存储介质和智能体装置,所述存储介质存储有应用程序,所述应用程序使计算机进行如下处理:使接受通过声音进行的输入的接受部接受声音;将基于使所述接受部接受到的声音得到的信息向智能体装置发送;以及基于特定控制的指示而使第一特定显示部出现智能体图像,所述特定控制的指示根据基于所述发送的声音得到的信息而从智能体装置取得,所述智能体装置具备:显示控制部,其在智能体启动了的情况下,使第二特定显示部显示智能体图像,所述智能体根据声音,提供包含使输出部输出通过声音进行的响应的服务;以及控制部,其在所述接受部所接受到的声音的大小小于规定的大小的情况下,使所述计算机执行用于使第二特定显示部显示所述智能体图像的所述特定控制。
(15):本发明的一方案的智能体装置的控制方法使计算机进行如下处理:在智能体启动了的情况下使第一显示部显示智能体图像,所述智能体根据声音,提供包含使输出部输出通过声音进行的响应的服务;以及基于接受通过声音进行的输入的外部终端所接受到的声音的大小,执行用于使第二显示部显示所述智能体图像的特定控制。
(16):本发明的一方案的存储介质存储有程序,所述程序使计算机进行如下处理:在智能体启动了的情况下使第一显示部显示智能体图像,所述智能体根据声音,提供包含使输出部输出通过声音进行的响应的服务;以及基于接受通过声音进行的输入的外部终端所接受到的声音的大小,执行用于使第二显示部显示所述智能体图像的特定控制。
发明效果
根据(1)~(5)、(7)~(9)、(11)、(12)~(16),智能体装置在接受到的声音的大小小于规定的大小的情况下使规定的显示部显示智能体图像,由此,能够提高智能体的使用性能。
根据(6),智能体装置在接受声音的输入的接受部接受到声音的情况下,使所述第一显示部显示智能体图像,由此,能够实现反映了利用者的意图的控制。
根据(10),智能体装置根据由外部终端发送的指示信息,使第一显示部显示智能体图像,由此,能够实现反映了利用者的意图的控制。
附图说明
图1是包含智能体装置的智能体系统1的结构图。
图2是示出通用通信装置的功能结构的一例的图。
图3是示出第一实施方式的智能体装置的结构和搭载于车辆m的设备的图。
图4是示出显示·操作装置的配置例的图。
图5是示出扬声器单元的配置例的图。
图6是用于对声像定位的位置确定的原理进行说明的图。
图7是示出智能体服务器的结构和智能体装置的结构的一部分的图。
图8是示出通用终端装置和智能体装置被利用的场景的一例的图。
图9是示出由通用终端装置和智能体装置执行的处理的流程的一例的流程图(其一)。
图10是示出智能体通过通常出现控制而出现了的情形的一例的图。
图11是示出智能体通过通常出现控制而出现了的情形的另一例的图。
图12是示出智能体通过私人出现控制而出现了的情形的一例的图。
图13是示出由通用通信装置和智能体装置执行的特定指令处理的流程的一例的流程图(其二)。
图14是示出由第二实施方式的通用终端装置和智能体装置执行的处理的流程的一例的流程图。
图15是示出第三实施方式的车辆m1的话筒及显示器的配置的一例的图。
图16是示出由第三实施方式的智能体装置执行的处理的流程的一例的流程图。
图17是示出在第三实施方式中进行了私人出现控制的情形的一例的图。
图18是示出设置于自己家的智能体装置的一例的图。
图19是示出由通用终端装置70和智能体装置执行的处理的流程的一例的流程图。
具体实施方式
以下,参照附图,对本发明的智能体装置、智能体系统、智能体装置的控制方法及存储介质的实施方式进行说明。
<第一实施方式>
智能体装置是实现智能体系统的一部分或全部的装置。以下,作为智能体装置的一例,对搭载于车辆(以下,车辆m)并具备多个种类的智能体功能的智能体装置进行说明。所谓智能体功能,例如是如下功能:一边与车辆m的利用者进行对话,一边进行基于利用者的讲话中所包含的要求(指令)的各种信息提供,或者居间于网络服务。智能体功能中,可以存在具有进行车辆内的设备(例如与驾驶控制、车身控制相关的设备)的控制等的功能的智能体功能。
智能体功能例如除了识别利用者的声音的声音识别功能(将声音文本化的功能)之外,还综合地利用自然语言处理功能(理解文本的构造、意思的功能)、对话管理功能、经由网络而检索其他装置或检索自身装置所持有的规定的数据库的网络检索功能等来实现。这些功能的一部分或全部可以利用ai(artificialintelligence)技术来实现。用于进行这些功能的结构的一部分(尤其是,声音识别功能、自然语言处理解释功能)也可以搭载于能够与车辆m的车载通信装置或被带入到车辆m内的通用通信装置进行通信的智能体服务器(外部装置)。在以下的说明中,将结构的一部分搭载于智能体服务器且智能体装置与智能体服务器协同配合而实现智能体系统作为前提。将智能体装置与智能体服务器协同配合而假想地出现的服务或其提供主体(服务·实体)称作智能体。
<整体结构>
图1是包含智能体装置100的智能体系统1的结构图。智能体系统1例如具备通用通信装置70、智能体装置100-1、100-2、多个智能体服务器200-1、200-2、200-3、…、信息处理服务器300。在不对智能体装置100-1、100-2进行区分的情况下,存在简称作智能体装置100的情况。智能体服务器200的附图标记的末尾的连字符以下的数字设为用于区分智能体的标识符。在不对是哪一个智能体服务器进行区分的情况下,存在简称作智能体服务器200的情况。在图1中示出了3个智能体服务器200,但是,智能体服务器200的数量既可以是2个,也可以是4个以上。
各智能体服务器200由互不相同的智能体系统的提供者运营。因此,本发明中的智能体是由互不相同的提供者实现的智能体。作为提供者,例如可以举出机动车制造商、网络服务商、电子商贸商、便携终端的销售者等,任意的主体(法人、团体、个人等)都能够成为智能体系统的提供者。
智能体装置100经由网络nw而与智能体服务器200通信。网络nw例如包括互联网、蜂窝网、wi-fi网、wan(wideareanetwork)、lan(localareanetwork)、公用线路、电话线、无线基地站等中的一部分或全部。网络nw连接有各种网页服务器500,智能体服务器200或智能体装置100经由网络nw而能够从各种网页服务器500取得网页。
智能体装置100与车辆m的利用者进行对话,将来自利用者的声音向智能体服务器200发送,或者将从智能体服务器200得到的回答以声音输出、图像显示的形式向利用者提示。
[通用通信装置]
图2是示出通用通信装置70的功能结构的一例的图。通用通信装置70是智能手机、平板终端等可移动型或便携型的装置。通用通信装置70例如具备显示部71、扬声器72、话筒73、通信部74、配对执行部75、声响处理部76、控制部77及存储部78。在存储部78中存储有协作应用程序(协作应用79)。协作应用79既可以由未图示的应用提供服务器提供,也可以由车辆m提供。
协作应用79基于利用者对通用通信装置700进行了的操作,将通用通信装置70取得的信息向智能体装置100发送,将由智能体装置100发送的信息向利用者提供。
显示部71包括lcd(liquidcrystaldisplay)、有机el(electroluminescence)显示器等显示装置。显示部71基于控制部77的控制而显示图像。扬声器72基于控制部77的控制而输出声音。话筒73收集由利用者输入的声音。
通信部74是用于与智能体装置100通信的通信接口。配对执行部75例如使用bluetooth(注册商标)等无线通信,执行与智能体装置100的配对。声响处理部76对被输入的声音进行声响处理。
控制部77通过cpu(centralprocessingunit)等处理器执行协作应用79(软件)来实现。控制部77控制通用通信装置70的各部分(例如显示部71、扬声器72等)。控制部77针对智能体装置100而管理使自身装置输入的信息,管理通过智能体装置100得到的信息。
[车辆]
图3是示出第一实施方式的智能体装置100的结构和搭载于车辆m的设备的图。在车辆m中,例如搭载有一个以上的话筒10、显示·操作装置20、扬声器单元30、导航装置40、车辆设备50、车载通信装置60、乘员识别装置80及智能体装置100。存在通用通信装置70被带入到车室内并作为通信装置而被使用的情况。这些装置通过can(controllerareanetwork)通信线等多路通信线、串行通信线、无线通信网等而互相连接。图2所示的结构只不过是一例,既可以省略结构的一部分,也可以还追加别的结构。
话筒10是收集在车室内产生的声音的收音部。显示·操作装置20是显示图像并且能够接受输入操作的装置(或装置群)。显示·操作装置20例如包括作为触摸面板而构成的显示器装置。显示·操作装置20也可以还包括hud(headupdisplay)、机械式的输入装置。扬声器单元30例如包括配设于车室内的互不相同的位置的多个扬声器(声音输出部)。显示·操作装置20也可以在智能体装置100和导航装置40间共用。关于它们的详情后述。
导航装置40具备导航hmi(humanmachineinterface)、gps(globalpositioningsystem)等位置测定装置、存储有地图信息的存储装置、及进行路径搜索等的控制装置(导航控制器)。话筒10、显示·操作装置20及扬声器单元30中的一部分或全部也可以作为导航hmi而被使用。导航装置40搜索用于从由位置测定装置确定出的车辆m的位置移动至由利用者输入的目的地的路径(导航路径),使用导航hmi而输出引导信息,以便车辆m能够沿着路径行驶。路径搜索功能也可以处于能够经由网络nw而访问的导航服务器中。在该情况下,导航装置40从导航服务器取得路径而输出引导信息。智能体装置100也可以以导航控制器为基础而构筑,在该情况下,导航控制器与智能体装置100硬件上构成为一体。
车辆设备50例如包括发动机、行驶用马达等驱动力输出装置、发动机的启动马达、车门锁定装置、车门开闭装置、空调装置等。
车载通信装置60例如是能够利用蜂窝网、wi-fi网而访问网络nw的无线通信装置。
乘员识别装置80例如包括就座传感器、车室内相机、图像识别装置等。就座传感器包括设置于座位的下部的压力传感器、安装于座椅安全带的张力传感器等。车室内相机是设置于车室内的ccd(chargecoupleddevice)相机、cmos(complementarymetaloxidesemiconductor)相机。图像识别装置对车室内相机的图像进行解析,识别每个座位的利用者的有无、面部朝向等。在本实施方式中,乘员识别装置80是就座位置识别部的一例。
图4是示出显示·操作装置20的配置例的图。显示·操作装置20例如包括第一显示器22、第二显示器24、操作开关assy26。显示·操作装置20也可以还包括hud28。
在车辆m中,例如存在设置有转向盘sw的驾驶员座ds、和相对于驾驶员座ds设置于车宽方向(图中y方向)的副驾驶员座as。第一显示器22是从仪表板中的驾驶员座ds与副驾驶员座as的中间附近延伸至与副驾驶员座as的左端部对置的位置的横长形状的显示器装置。第二显示器24设置于驾驶员座ds与副驾驶员座as的车宽方向上的中间附近且第一显示器22的下方。例如,第一显示器22和第二显示器24均作为触摸面板而构成,具备lcd(liquidcrystaldisplay)、有机el(electroluminescence)、等离子体显示器等作为显示部。操作开关assy26是拨码开关、按钮式开关等聚集而成的。显示·操作装置20将由利用者进行了的操作的内容向智能体装置100输出。第一显示器22或第二显示器24显示的内容可以由智能体装置100决定。
图5是示出扬声器单元30的配置例的图。扬声器单元30例如包括扬声器30a~30h。扬声器30a设置于驾驶员座ds侧的窗柱(所谓的a柱)。扬声器30b设置于靠近驾驶员座ds的车门的下部。扬声器30c设置于副驾驶员座as侧的窗柱。扬声器30d设置于靠近副驾驶员座as的车门的下部。扬声器30e设置于靠近右侧后部座位bs1侧的车门的下部。扬声器30f设置于靠近左侧后部座位bs2侧的车门的下部。扬声器30g设置于第二显示器24的附近。扬声器30h设置于车室的顶棚(roof)。
在该配置中,例如,在专门使扬声器30a及30b输出了声音的情况下,声像会定位于驾驶员座ds附近。在专门使扬声器30c及30d输出了声音的情况下,声像会定位于副驾驶员座as附近。在专门使扬声器30e输出了声音的情况下,声像会定位于右侧后部座位bs1附近。在专门使扬声器30f输出了声音的情况下,声像会定位于左侧后部座位bs2附近。在专门使扬声器30g输出了声音的情况下,声像会定位于车室的前方附近,在专门使扬声器30h输出了声音的情况下,声像会定位于车室的上方附近。不限定于此,扬声器单元30能够通过使用混音器、放大器调整各扬声器输出的声音的分配,来使声像定位于车室内的任意的位置。
[智能体装置]
返回图3,智能体装置100具备管理部110、智能体功能部150-1、150-2、150-3、配对应用执行部152。管理部110例如具备声响处理部112、按每个智能体wu(wakeup)判定部114、协作控制部115、显示控制部116、声音控制部118。在不对是哪一个智能体功能部进行区分的情况下,简称作智能体功能部150。示出了3个智能体功能部150,这不过是与图1中的智能体服务器200的数量对应的一例,智能体功能部150的数量既可以是2个,也可以是4个以上。图3所示的软件配置是为了说明而简易地示出,实际上,例如既可以在智能体功能部150与车载通信装置60之间介入有管理部110,也可以任意地改变。
智能体装置100的各构成要素例如通过cpu等硬件处理器执行程序(软件)来实现。这些构成要素中的一部分或全部既可以通过lsi(largescaleintegration)、asic(applicationspecificintegratedcircuit)、fpga(field-programmablegatearray)、gpu(graphicsprocessingunit)等硬件(包括电路部;circuitry)来实现,也可以通过软件与硬件的协同配合来实现。
程序既可以预先保存于hdd(harddiskdrive)、闪存器等存储装置(具备非暂时性的存储介质的存储装置)中,也可以保存于dvd、cd-rom等可装卸的存储介质(非暂时性的存储介质)并通过将存储介质装配于驱动装置而安装。
管理部110通过执行os(operatingsystem)、中间件等程序而发挥功能。
管理部110的声响处理部112对被输入的声音进行声响处理,以使得成为适于识别针对每个智能体预先设定的唤醒词的状态。
按每个智能体wu判定部114与智能体功能部150-1、150-2、150-3分别对应地存在,识别针对每个智能体预先设定的唤醒词。按每个智能体wu判定部114从进行了声响处理的声音(声音流)识别声音的意思。首先,按每个智能体wu判定部114基于声音流中的声音波形的振幅和零交叉来检测声音区间。按每个智能体wu判定部114也可以进行通过基于混合高斯分布模型(gmm;gaussianmixturemodel)的帧单位的声音识别及非声音识别而实现的区间检测。
接着,按每个智能体wu判定部114将检测到的声音区间中的声音文本化,设为文字信息。然后,按每个智能体wu判定部114判定文本化了的文字信息是否符合唤醒词。在判定为是唤醒词的情况下,按每个智能体wu判定部114使对应的智能体功能部150启动。与按每个智能体wu判定部114相当的功能也可以搭载于智能体服务器200。在该情况下,管理部110将由声响处理部112进行了声响处理的声音流向智能体服务器200发送,在智能体服务器200判定为是唤醒词的情况下,按照来自智能体服务器200的指示,智能体功能部150启动。各智能体功能部150也可以始终启动且自行进行唤醒词的判定。在该情况下,无需管理部110具备按每个智能体wu判定部114。
智能体功能部150与对应的智能体服务器200协同配合而使智能体出现,根据车辆m的利用者的讲话,提供包含使输出部输出通过声音进行的响应的服务。在智能体功能部150中可以包含被赋予了控制车辆设备50的权限的功能部。智能体功能部150中可以存在经由配对应用执行部152而与通用通信装置70协作来与智能体服务器200通信的功能部。例如,对智能体功能部150-1赋予了控制车辆设备50的权限。智能体功能部150-1经由车载通信装置60而与智能体服务器200-1通信。智能体功能部150-2经由车载通信装置60而与智能体服务器200-2通信。智能体功能部150-3经由配对应用执行部152而与通用通信装置70协作来与智能体服务器200-3通信。
配对应用执行部152例如与通用通信装置70进行配对,使智能体功能部150-3与通用通信装置70连接。智能体功能部150-3也可以通过利用了usb(universalserialbus)等的有线通信而连接于通用通信装置70。以下,存在将智能体功能部150-1与智能体服务器200-1协同配合而出现的智能体称作智能体1,将智能体功能部150-2与智能体服务器200-2协同配合而出现的智能体称作智能体2,将智能体功能部150-3与智能体服务器200-3协同配合而出现的智能体称作智能体3的情况。
协作控制部115在接受通过声音进行的输入的通用通信装置70接受到的声音的大小为规定的大小以下的情况下,使通用通信装置70执行用于使通用通信装置70的显示部显示智能体图像的特定控制。关于该处理的详情在后述的[协作处理的概要]中说明。所谓“规定的大小”,例如也可以是40db以下,优选30db的输入,也可以是被判定为车辆m的讲话的通常的声音的大小以下的情况。还可以在对车辆m的行驶音、环境音等进行了补偿的基础上来进行判定。
显示控制部116根据由智能体功能部150作出的指示,使第一显示器22或第二显示器24显示图像。以下,设为使用第一显示器22。显示控制部116通过一部分的智能体功能部150的控制,例如生成在车室内进行与利用者的交流的拟人化了的智能体的图像(以下,称作智能体图像),使第一显示器22显示所生成的智能体图像。智能体图像例如是对利用者搭话的形态的图像。智能体图像例如可以包含至少由观看者(利用者)识别到表情、面部朝向的程度的面部图像。例如,智能体图像可以是,在面部区域中呈现模仿眼睛、鼻子的部件,基于面部区域中的部件的位置而识别表情、面部朝向。智能体图像是被观看者立体地感受并通过包含三维空间中的头部图像而智能体的面部朝向被识别的图像。智能体图像也可以是智能体的动作、举止、姿态等被识别而包含主体(身躯、手脚)的图像。智能体图像也可以是动画图像。
声音控制部118根据由智能体功能部150作出的指示,使扬声器单元30所包含的扬声器中的一部分或全部输出声音。声音控制部118也可以进行使用多个扬声器单元30而使智能体声音的声像定位于与智能体图像的显示位置对应的位置的控制。所谓与智能体图像的显示位置对应的位置,例如是被预测为利用者感到智能体图像正在讲出智能体声音的位置,具体而言,是智能体图像的显示位置附近(例如,2~3[cm]以内)的位置。所谓声像定位,例如是通过调节向利用者的左右耳传递的声音的大小来设定利用者感到的声源的空间上的位置。
图6是用于对声像定位的位置确定的原理进行说明的图。在图6中,为了简化说明,示出了使用上述的扬声器30b、30d及30g的例子,但是,可以使用扬声器单元30所包含的任意的扬声器。声音控制部118控制连接于各扬声器的放大器(amp)32及混音器34而使声像定位。例如,在使声像定位于图6所示的空间位置mp1的情况下,声音控制部118通过控制放大器32及混音器34,使扬声器30b进行最大强度的5%的输出,使扬声器30d进行最大强度的80%的输出,使扬声器30g进行最大强度的15%的输出。其结果是,从利用者p的位置感到声像定位在了图6所示的空间位置mp1。
在使声像定位于图6所示的空间位置mp2的情况下,声音控制部118通过控制放大器32及混音器34,使扬声器30b进行最大强度的45%的输出,使扬声器30d进行最大强度的45%的输出,使扬声器30g进行最大强度的45%的输出。其结果是,从利用者p的位置感到声像定位在了图6所示的空间位置mp2。这样,通过调整设置于车室内的多个扬声器和从各扬声器输出的声音的大小,使声像被定位的位置变化。更详细而言,声像定位的位置基于声源原本所持有的声音特性、车室内环境的信息、头部传递函数(hrtf;head-relatedtransferfunction)而定,所以,声音控制部118通过以预先利用感官试验等得到的最佳的输出分配控制扬声器单元30,使声像定位于规定的位置。
[智能体服务器]
图7是示出智能体服务器200的结构和智能体装置100的结构的一部分的图。以下,与智能体服务器200的结构一起,对智能体功能部150等的动作进行说明。在此,省略关于从智能体装置100到网络nw的物理上的通信的说明。
智能体服务器200具备通信部210。通信部210例如是nic(networkinterfacecard)等网络接口。而且,智能体服务器200例如具备声音识别部220、自然语言处理部222、对话管理部224、网络检索部226、响应文生成部228。这些构成要素例如通过cpu等硬件处理器执行程序(软件)来实现。这些构成要素中的一部分或全部既可以通过lsi、asic、fpga、gpu等硬件(包括电路部;circuitry)来实现,也可以通过软件与硬件的协同配合来实现。程序既可以预先保存于hdd、闪存器等存储装置(具备非暂时性的存储介质的存储装置)中,也可以保存于dvd、cd-rom等可装卸的存储介质(非暂时性的存储介质)并通过将存储介质装配于驱动装置而安装。
智能体服务器200具备存储部250。存储部250通过上述各种存储装置来实现。在存储部250中保存有个人简介252、字典db(数据库)254、知识库db256、响应规则db258等数据、程序。
在智能体装置100中,智能体功能部150将声音流或进行了压缩、编码等处理的声音流向智能体服务器200发送。智能体功能部150可以在识别到能够进行本地处理(不经由智能体服务器200的处理)的声音指令的情况下,进行通过声音指令要求的处理。所谓能够进行本地处理的声音指令,是通过参照智能体装置100所具备的存储部(未图示)而能够回答的声音指令,在智能体功能部150-1的情况下,是控制车辆设备50的声音指令(例如,打开空调装置的指令等)。因此,智能体功能部150也可以具有智能体服务器200所具备的功能的一部分。
智能体装置100当取得声音流后,声音识别部220进行声音识别并将文本化了的文字信息输出,自然语言处理部222针对文字信息一边参照字典db254一边进行意思解释。字典db254中,对于文字信息,抽象化了的意思信息建立了对应关系。字典db254也可以包含同义词、近义词的一览信息。声音识别部220的处理和自然语言处理部222的处理可以不明确分阶段,而是接受自然语言处理部222的处理的结果而声音识别部220修正识别的结果等相互影响地进行。
自然语言处理部222例如在识别到“今天的天气是”、“天气怎么样”等意思作为识别的结果的情况下,生成置换为标准文字信息“今天的天气”的指令。由此,在请求的声音存在了表述差异的情况下,也能够容易地进行与要求相符的对话。另外,自然语言处理部222例如也可以使用利用了概率的机器学习处理等人工智能处理来识别文字信息的意思,生成基于识别的结果的指令。
对话管理部224基于自然语言处理部222的处理的结果(指令),一边参照个人简介252、知识库db256、响应规则db258,一边决定针对车辆m的利用者进行的讲话的内容。个人简介252包含针对每个利用者保存的利用者的个人信息、兴趣偏好、过去的对话的履历等。知识库db256是规定了事物的关系性的信息。响应规则db258是规定了针对指令而智能体应该进行的动作(回答、设备控制的内容等)的信息。
对话管理部224也可以通过使用从声音流得到的特征信息而与个人简介252进行对照,来确定利用者。在该情况下,个人简介252中,例如声音的特征信息与个人信息建立了对应关系。所谓声音的特征信息,例如是与声音的高度、语调、节奏(声音的高低的模式)等说话方式的特征、基于梅尔频率倒谱系数(melfrequencycepstrumcoefficients)等的特征量相关的信息。声音的特征信息例如是在利用者的初始登记时使利用者对规定的单词、文章等进行发声,通过识别发出的声音而得到的信息。
对话管理部224在指令是要求能够经由网络nw而检索的信息的指令的情况下,使网络检索部226进行检索。网络检索部226经由网络nw而访问各种网页服务器500,取得期望的信息。所谓“能够经由网络nw而检索的信息”,例如是处于车辆m的周边的餐厅的由一般用户评价的评价的结果,是与当天的车辆m的位置相应的天气预报。
响应文生成部228以使得由对话管理部224决定出的讲话的内容向车辆m的利用者传达的方式生成响应文,并将所生成的响应文向智能体装置100发送。响应文生成部228也可以在确定了利用者是在个人简介中登记了的利用者的情况下,呼叫利用者的名字,生成模仿利用者的说话方式的说话方式的响应文。在对话管理部224决定为向利用者提供音乐的情况下,响应文生成部228的处理省略,基于网络检索部226的检索的结果而得到的乐曲的信息被向智能体功能部150提供。以下,在不对响应文和乐曲等向利用者提供的信息进行区分的情况下,存在称作“响应信息”的情况。
智能体功能部150当取得响应文后,指示声音控制部118进行声音合成并输出声音。智能体功能部150指示显示控制部116与声音输出相配合地显示智能体的图像。这样,假想地出现的智能体对车辆m的利用者进行响应的智能体功能得以实现。
[协作处理的概要]
通过通用终端装置70(外部终端)和智能体装置100协作,智能体向乘员提供服务。图8是示出通用终端装置70和智能体装置100被利用的场景的一例的图。例如,当车辆m的乘员使协作应用79启动后,通用通信装置70与智能体装置100协作。并且,当乘员向通用终端装置70的话筒73输入声音后,智能体装置100取得从正在协作的通用终端装置70输入的声音,基于所取得的信息,使显示·操作装置20、扬声器单元30、通用终端装置70的显示部71及通用终端装置70的扬声器72中的一个以上的功能结构出现智能体。所谓“出现”,是智能体以乘员能够识别的形态呈现。所谓“出现”,例如是智能体作为声音而由扬声器输出,智能体图像显示于显示部。
显示·操作装置20所包含的显示部是“第一显示部”的一例。通用通信装置70所包含的显示部是“第二显示部”的一例。第二显示部也可以包含于与通用通信装置70不同的装置中。
第一显示器22或第二显示器24是“以不限制视认者那样的形态设置的第一显示部”的一例。通用通信装置70是“接受通过声音进行的输入的第一终端”的一例。通用通信装置70的显示部71或未图示的其他显示部是“以将视认者限制为输入了第一终端接受到的声音的利用者那样的形态设置的第二显示部”的一例。
例如,存在乘员不想被其他乘员知道根据自身输入的声音而出现了的智能体、智能体提供的服务的情况。在该情况下,适用下述那样的协作处理。
[协作处理的流程图]
图9是示出由通用终端装置70和智能体装置100执行的处理的流程的一例的流程图(其一)。首先,通用通信装置70判定协作应用79是否启动了(步骤s100)。在协作应用79启动了的情况下,控制部77向智能体装置100要求协作(步骤s102)。
智能体装置100判定是否接收到控制部77的协作的要求(步骤s200)。在接收到控制部77的协作的要求的情况下,智能体装置100根据协作的要求而同意协作,将表示同意了的信息向通用通信装置70发送(步骤s202)。由此,通用通信装置70和智能体装置100协作。通过协作,被输入到通用通信装置70的声音被向智能体装置100发送,或者智能体在通用通信装置70出现。
接着,通用通信装置70判定是否被输入了乘员的讲话(步骤s104)。在判定为被输入了乘员的讲话的情况下,通用通信装置70将基于讲话的信息向智能体装置100发送(步骤s106)。基于讲话的信息,既可以是进行了声响处理的声音流,也可以是声响处理前的信息。在声响处理前的信息被发送的情况下,智能体装置100对基于讲话的信息进行声响处理。智能体装置100在取得了在步骤s106中发送出的基于讲话的信息的情况下,向智能体服务器200发送基于讲话的信息,从智能体服务器200取得响应信息。
基于讲话的信息中,包含表示被输入到通用通信装置70的声音的大小的信息或用于导出声音的大小的信息。既可以是通用通信装置70导出表示声音的大小的信息,也可以是智能体装置100导出表示声音的大小的信息。以下,将表示声音的大小的信息称作“讲话声压d1”。
在取代智能体装置100而在通用通信装置70中取得讲话声压d1的情况下,通用通信装置70将讲话声压d1的信息向智能体装置100发送。然后,智能体装置100如后述那样判定由通用通信装置70发送的讲话声压d1是否是阈值声压th1以上。
智能体装置100判定讲话声压d1是否是阈值声压th1以上(步骤s204)。在讲话声压d1是阈值声压th1以上的情况下,智能体装置100使显示·操作装置20(车室内的显示部)显示智能体图像(步骤s206)。接着,智能体装置100使用扬声器单元30,使智能体输出响应信息(步骤s208)。即,智能体装置100与通用通信装置70协作,根据通用通信装置70接受到的声音,向乘员提供包含使输出部输出通过声音进行的响应的服务。智能体装置100与通用通信装置70协作,根据通用通信装置70接受到的阈值声压th1以上的声音,使车室内的显示部显示智能体,不执行使通用通信装置70出现智能体的控制。以下,存在将智能体装置100如步骤s206及步骤s208那样使智能体出现的控制称作“通常出现控制”的情况。
图10是示出智能体通过通常出现控制而出现了的情形的一例的图。在图示的例子中,在第二显示器24及扬声器单元30中出现了智能体。也可以取代第二显示器24而(或除此之外还)在第一显示器22中出现智能体。即,智能体装置100在执行通常出现控制的情况下(不执行后述的私人出现控制的情况下),使车室内的显示部显示智能体。
例如,智能体装置100也可以使通用通信装置70出现智能体。在该情况下,智能体装置100指示使通用通信装置70出现智能体。图11是示出智能体通过通常出现控制而出现了的情形的另一例的图。在图示的例子中,除了第二显示器24及扬声器单元30之外,还在通用通信装置70的显示部71及扬声器72出现了智能体。
如上述那样,乘员能够利用通用通信装置70而使智能体出现,所以,乘员的便利性提高。
返回图9的说明。在讲话声压d1不是阈值声压th1以上的情况下(讲话声压d1小于阈值声压th1的情况下),智能体装置100使通用通信装置70的显示部71显示智能体图像(步骤s210)。即,智能体装置100基于接受通过声音进行的输入的外部终端接受到的声音的大小,使第二显示部显示智能体图像。接着,智能体装置100使通用通信装置70输出响应信息(步骤s212)。换言之,智能体装置100通过通用通信装置70的扬声器72的声音而使智能体出现。例如,智能体装置100对于通用通信装置70,将响应信息、指示输出响应信息的信息、指示使显示部71显示智能体图像的信息向通用通信装置70发送。通用通信装置70基于由智能体装置100发送的信息,进行步骤s210或步骤s212的处理。以下,存在将智能体装置100如步骤s210及步骤s212那样使通用通信装置70出现智能体的控制称作“私人出现控制(特定控制)”的情况。
图12是示出智能体通过私人出现控制而出现了的情形的一例的图。在图示的例子中,在车室内的显示部及扬声器单元30没有出现智能体,在通用通信装置70的显示部71及扬声器72出现了智能体。即,智能体装置100在通用通信装置70接受到的声音的大小小于阈值声压th1的情况下,执行用于使通用通信装置70的显示部71显示智能体图像的私人出现控制。由此,通用通信装置70执行使显示部71显示智能体图像的处理。智能体装置100在通用通信装置70接受到的声音的大小小于阈值声压th1的情况下(执行私人控制的情况下),不使车室内的显示部显示智能体图像。
如上述那样,在乘员例如小声向通用通信装置70输入了声音的情况下,能够抑制被其他乘员知道智能体的出现、响应信息等,所以,对于乘员而言,智能体的使用性能好。
如上所述,在智能体执行了通常出现控制或私人出现控制之后,(1)既可以继续进行通常出现控制或私人出现控制,(2)也可以基于接下来取得的讲话的讲话声压d1的大小是否是阈值声压th1以上的判定的结果,决定智能体以哪一个形态出现。
例如,如上述的(1)那样,假定为私人出现控制继续进行。在该情况下,在执行了私人出现控制的情况下,开始以下的特定指令处理。
图13是示出由通用通信装置70和智能体装置100执行的特定指令处理的流程的一例的流程图(其二)。首先,通用通信装置70判定是否被输入了特定指令(指示信息)(步骤s300)。例如,特定指令的输入通过与特定指令对应的声音的输入或针对通用终端装置70的规定的操作而执行。在判定为被输入了特定指令的情况下,通用通信装置70将表示被输入了特定指令的信息向智能体装置100发送(步骤s302)。
接着,智能体装置100判定是否被输入了特定指令(步骤s400)。在判定为被输入了特定指令的情况下,智能体装置100解除私人出现控制,执行通常出现控制(步骤s402)。即,智能体装置100在使通用通信装置70执行着私人控制的情况下,根据由通用通信装置70发送的特定指令,使车室内的显示部出现智能体。由此,本流程图的处理结束。
通过上述的处理,根据乘员的意思,智能体出现,所以,乘员的满足度提高。
根据以上说明的第一实施方式,智能体装置100在通用通信装置70接受到的声音的大小小于阈值声压th1的情况下,通过执行用于使通用通信装置70的显示部71显示智能体图像的私人控制,能够提高智能体的使用性能。
<第二实施方式>
以下,对第二实施方式进行说明。在第二实施方式中,智能体装置100除了讲话声压d1是否是阈值声压th1以上的判定之外,还判定乘员的讲话是否向车室内的话筒10输入了,使用判定的结果来决定智能体的出现形态。以下,以与第一实施方式的不同点为中心来进行说明。
图14是示出由第二实施方式的通用终端装置70和智能体装置100执行的处理的流程的一例的流程图。对与图9的流程图的处理的不同点进行说明。
在步骤s204中讲话声压d1不是阈值声压th1以上的情况下(讲话声压d1小于阈值声压th1的情况下),智能体装置100判定车室内的话筒10是否识别到声音(步骤s209)。所谓车室内的话筒10(“接受部”的一例),既可以是设置于车室内的任意话筒,也可以是规定的话筒10。
例如,规定的话筒10也可以是设置于向通用通信装置70输入了讲话的乘员所就座的座位附近的话筒。例如,智能体装置100基于乘员识别装置80的就座传感器的检测获知的结果和通用通信装置70与智能体装置100的通信的结果,来确定乘员的就座位置。所谓通信的结果,是基于通用通信装置70输出的电波而推定的通用通信装置70存在的方向。智能体装置100基于通用通信装置70输出的电波的接收的结果,确定电波的输出源即通用通信装置70存在的方向。
在步骤s209中车室内的话筒10识别到声音的情况下,进入步骤s206的处理。即,智能体装置100即便在通用通信装置70接受到的声音的大小小于阈值声压th的情况下,在接受声音的输入的车室内的话筒10接受到声音时,也使车室内的显示部显示智能体图像。在步骤s209中,在车室内的话筒10没有识别到声音的情况下,进入步骤s210的处理。
在步骤s209中,也可以取代车室内的话筒10是否识别到声音的判定,智能体装置100判定是否基于经由车室内的话筒10取得的声音而识别到乘员向通用通信装置70输入的讲话的内容。例如,设为乘员向通用通信装置70输入了“告诉我关于○○”。设为该输入的讲话的讲话声压d1小于阈值声压th1。在该情况下,智能体装置100经由车室内的话筒10取得乘员的讲话的声音,在基于所取得的声音而识别到“告诉我关于○○”这一讲话的内容的情况下,进入步骤s206的处理,在没有识别到讲话的内容的情况下,也可以进入步骤s210的处理。
例如,存在协作应用79启动了的状态的通用通信装置70存在于距乘员第一距离的位置,接受声音的话筒10存在于距乘员第二距离的位置的情况。第一距离是比第二距离短的距离。这样的情况下,即便是乘员向话筒10输入声音而打算执行通常出现控制时,也会存在通用通信装置70接受到的声音的大小小于阈值声压th1且话筒10接受声音的情况。此时,智能体装置100由于执行通常出现控制,所以乘员所打算的通常出现控制得以实现。
根据以上说明的第二实施方式,智能体装置100即便在通用通信装置70接受到的声音的大小小于阈值声压th1的情况下,在话筒10接受到声音时,也使车室内的显示部显示智能体图像,由此,能够提高智能体的使用性能。
<第三实施方式>
以下,对第三实施方式进行说明。在第三实施方式中,智能体装置100基于向为了供所着眼的乘员使用而设置的话筒输入的声音,决定智能体的出现形态。以下,以与第一实施方式及第二实施方式的不同点为中心进行说明。
图15是示出第三实施方式的车辆m1的话筒10及显示器的配置的一例的图。例如,在车辆m1的车室内,除了第一实施方式及第二实施方式的功能结构之外,还设置有话筒10-1、话筒10-2及显示器29。话筒10-2是“接受部”的另一例。
第一显示器22或第二显示器24是“以不限制视认者那样的形态设置的第一显示部”的一例。智能体装置100或话筒10-1是“接受通过声音进行的输入的第一终端”的另一例。显示器29或未图示的其他显示部是“以将视认者限制为输入了第一终端接受到的声音的利用者那样的形态设置的第二显示部”的另一例。
话筒10-1是为了供所着眼的乘员使用而设置的话筒。话筒10-1例如设置于所着眼的乘员就座的座位附近。在图15的例子中,设为乘员就座于左侧后部座位bs2。在该情况下,设置于左侧后部座位bs2的附近的话筒是话筒10-1。例如,在就座于副驾驶员座as的乘员是所着眼的乘员的情况下,设置于副驾驶员座as2的附近的话筒是话筒10-1。话筒10-1例如设置于离所着眼的乘员就座的座位最近的车门附近、所着眼的乘员就座的座位的前方、所着眼的乘员就座的座位的顶棚等。话筒10-1也可以通过线缆而连接于车辆,以使话筒接近乘员的嘴边。由此,乘员能够使话筒10-1接近嘴附近,输入讲话。
话筒10-2是与为了供所着眼的乘员使用而设置的话筒不同的话筒。话筒10-2例如设置于与所着眼的乘员就座的座位附近不同的部位。在图15的例子中,话筒10-2设置于车辆m1的仪表板中的驾驶员座ds与副驾驶员座as的中间附近。
显示器29设置于所着眼的乘员能够视认且其他乘员难以视认的位置。显示器29例如在图14的例子中,设置于副驾驶员座as的座位的靠背的后侧且在乘员就座于左侧后部座位bs2时与乘员面对面的位置。
图16是示出由第三实施方式的智能体装置100执行的处理的流程的一例的流程图。首先,智能体装置100判定智能体功能部150是否启动了(步骤s500)。在智能体功能部150启动了的情况下,智能体装置100判定是否向与所着眼的乘员对应地设定的话筒10-1输入了讲话(步骤s502)。在判定为向话筒10-1输入了讲话的情况下,智能体装置100判定所输入的讲话的讲话声压d1是否是阈值声压th1以上(步骤s504)。
在所输入的讲话的讲话声压d1是阈值声压th1以上的情况下,智能体装置100使第一显示器22或第二显示器24显示智能体图像(步骤s506),使用扬声器单元30而使智能体输出响应信息(步骤s508)。例如,使扬声器单元30的一部分或全部出现智能体,以使得车室内的乘员识别智能体的出现。步骤s506及步骤s508的处理是“通常出现控制”的另一例。
在讲话声压d1不是阈值声压th1以上的情况下(讲话声压d1小于阈值声压th1的情况下),智能体装置100判定是否向不同于与所着眼的乘员对应地设定的话筒10-1的话筒10-2输入了讲话(步骤s510)。在判定为向话筒10-2输入了讲话的情况下,进入步骤s506的处理。
在没有向话筒10-2输入讲话的情况下,智能体装置100使显示器29显示智能体图像(步骤s512),使用与所着眼的乘员对应地设定的扬声器单元30而使智能体输出响应信息(步骤s514)。与所着眼的乘员对应地设定的扬声器单元30例如是扬声器30f。图17是示出在第三实施方式中进行了私人出现控制的情形的一例的图。步骤s512及步骤s514的处理是“私人出现控制”的另一例。例如,扬声器30f输出的声音是就座于左侧后部座位bs2的乘员能听到而就座于其他座位的乘员不能听到的程度的大小的声音。扬声器30f输出的声音也可以是就座于其他座位的乘员无法识别声音所包含的信息的意思那样的大小的声音。
根据以上说明的第三实施方式,智能体装置100基于向为了供所着眼的乘员使用而设置的话筒输入了的声音,来决定智能体的出现形态,由此,即便不使用通用通信装置70,也能够起到与第一实施方式同样的效果。
<第四实施方式>
以下,对第四实施方式进行说明。在第四实施方式中,智能体装置设置于乘员的自己家、规定的设施、规定的位置等与车辆不同的位置。以下,以与第一实施方式的不同点为中心进行说明。
图18是示出设置于自己家的智能体装置100a的一例的图。智能体装置100a例如是设置于乘员的自己家、规定的设施或规定位置的固定设置型的装置。即,智能体装置100a所包含的后述的显示部105(“第一显示部”的一例)或后述的话筒102(“接受部”的另一例)是设置于设施或规定的位置的固定设置型。所谓固定设置型,前提是虽然能够移动但是在设施内等有限的范围内被使用。后述的话筒102是“接受部”的一例。
后述的显示部105是“以不限制视认者那样的形态设置的第一显示部”的另一例。通用通信装置70是“接受通过声音进行的输入的第一终端”的一例。通用通信装置70的显示部71或未图示的其他显示部是“以将视认者限制为输入了第一终端接受到的声音的利用者那样的形态设置的第二显示部”的一例。
智能体装置100a例如具备话筒102、显示·操作部104、扬声器单元106、管理部110、智能体功能部150、配对应用执行部152。声响处理部112对向话筒102输入了的声音进行声响处理。显示控制部116根据由智能体功能部150作出的指示而使显示·操作部104所包含的显示部105显示图像。声音控制部118根据由智能体功能部150作出的指示,使扬声器单元106所包含的扬声器中的一部分或全部输出声音。
在判定为向通用通信装置70输入了乘员的讲话的情况下,通用通信装置70将基于讲话的信息向智能体装置100发送。智能体装置100判定从通用通信装置70取得的讲话的讲话声压d1是否是阈值声压th1以上。在讲话声压d1是阈值声压th1以上的情况下,智能体装置100使显示·操作装置104的显示部105显示智能体图像,使扬声器单元106出现智能体。即执行“通常出现控制”。
在讲话声压d1不是阈值声压th1以上的情况下(讲话声压d1小于阈值声压th1的情况下),智能体装置100使通用通信装置70的显示部71显示智能体图像,使通用通信装置70输出响应信息。即执行“私人出现控制”的处理。
根据以上说明的第四实施方式,即便在智能体装置100被在车辆以外的场所使用的情况下,也能够起到与第一实施方式同样的效果。
<第五实施方式>
以下,对第五实施方式进行说明。在第五实施方式中,取代智能体装置,通用通信装置70判定讲话声压d1是否是阈值声压th1以上,基于判定的结果来决定智能体的出现形态。以下,以与第二实施方式的不同点为中心进行说明。
图19是示出由通用终端装置70和智能体装置100执行的处理的流程的一例的流程图。图19的步骤s600~s604、步骤s700、s702的处理与图9的步骤s100~s104、步骤s200、s202的处理是同样的,所以省略说明。
在步骤s604中判定为被输入了乘员的讲话的情况下,通用通信装置70取得被输入的讲话的讲话声压d1(步骤s606)。接着,通用通信装置70将基于讲话的信息向智能体装置100发送(步骤s608)。
智能体装置100判定话筒102是否识别到声音(步骤s704)。在话筒102识别到声音的情况下,智能体装置100使车室内的显示部显示智能体图像(步骤706),使用扬声器单元30而使智能体输出响应信息(步骤s708)。即执行“通常出现控制”。
在话筒102没有识别到声音的情况下,智能体装置100将步骤s704的判定的结果向通用通信装置70发送(步骤s710)。在步骤s710中,例如除了步骤s704的判定的结果之外,还将响应信息向通用通信装置70发送。智能体装置100在取得在步骤s608中发送的信息之后,从智能体服务器200取得与所取得的信息相应的响应信息。
通用通信装置70基于通过步骤s710发送的判定的结果,判定话筒102是否识别到声音(步骤s610)。在话筒102识别到声音的情况下,跳过步骤s612~s616的处理。
在话筒102没有识别到声音的情况下,通用通信装置70判定讲话声压d1是否是阈值声压th1以上(步骤s612)。在讲话声压d1是阈值声压th1以上的情况下,通用通信装置70将输出指示向智能体装置100发送,智能体装置100进行步骤s706、s708的处理。
在讲话声压d1不是阈值声压th1以上的情况下(讲话声压d1小于阈值声压th1的情况下),通用通信装置70使通用通信装置70的显示部71显示智能体图像(步骤s614),使用通用通信装置70的扬声器72而使智能体输出响应信息(步骤s616)。即执行“私人出现控制”。
根据以上说明的第五实施方式,通用通信装置70进行讲话声压d1是否是阈值声压th1以上的判定,由此,智能体装置100中的处理负荷减轻。
上述的各实施方式的功能的一部分既可以包含于其他装置,上述的各流程图的处理的一部分也可以省略,各处理的顺序还可以替换。各实施方式的处理、功能结构也可以组合而适用。
以上使用实施方式说明了本发明的具体实施方式,但本发明丝毫不被这样的实施方式限定,在不脱离本发明的主旨的范围内能够施加各种变形及替换。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



