
 商标分类
商标分类  商标转让
商标转让 
一种基于生成式对抗网络的语音生成方法与流程
 2021-01-28 16:01:25|
2021-01-28 16:01:25| 325|
325| 起点商标网
起点商标网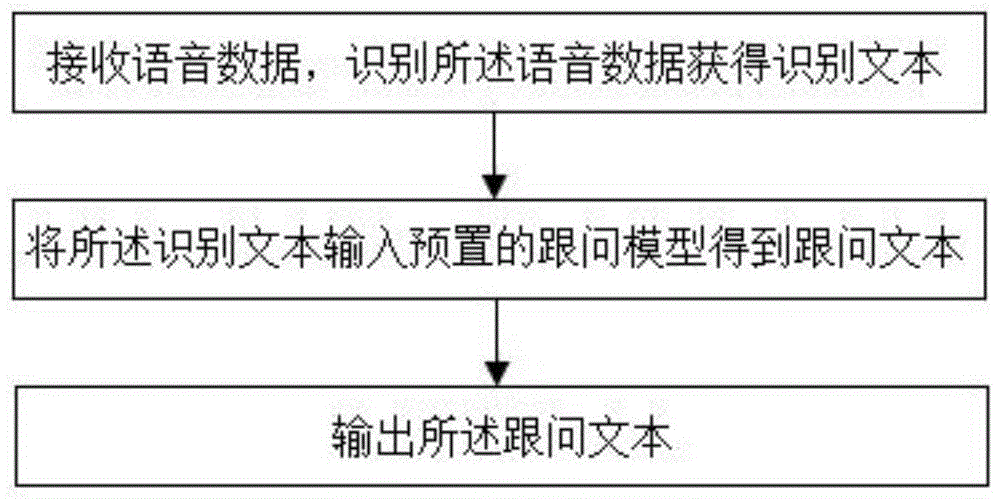
本发明涉及图像信息处理技术领域,具体为一种基于生成式对抗网络的语音生成方法。
背景技术:
随着计算机技术的不断发展,音频处理技术也已经相当成熟,其中的声纹识别技术是用于识别用户身份的常用技术。声纹识别技术的关键在于语音特征的提取和语音数据库的构建。
现在的对话系统多数只能做单轮对话,可以帮助用户完成一些简单的任务,如问天气、查路线。而实际上,人们在生活中需求场景并非是这样简单且单一的,而是多样化且复杂的。在实际使用中,现有的对话系统识别对于用户意图的识别能力不高,经常会出现因为无法判别用户意图而出现无法回答用户的情况,或者出现答非所问或重复回答的情况,使得对话系统的构建对话的内容太过局限和死板,用户体验不高。
技术实现要素:
本发明的目的在于提供一种基于生成式对抗网络的语音生成方法,以解决目前火焰检测方法抗干扰能力较差、稳定性较差的问题。
为实现上述目的,本发明提供如下技术方案:一种基于生成式对抗网络的语音生成方法,所述方法包括如下步骤:
接收语音数据,识别所述语音数据获得识别文本;
将所述识别文本输入预置的跟问模型得到跟问文本;
输出所述跟问文本。
进一步地,所述跟问模型为生成式对抗网络中的生成模型。
进一步地,所述生成模型通过如下方式进行训练:
从跟问语句库中抽取训练语句及所述训练语句对应的跟问语句;
将所述训练语句输入所述生成模型得到模拟语句;
通过判别模型对比所述跟问语句与所述模拟语句,得到所述跟问语句与所述模拟语句的对比值,将所述对比值反馈至所述生成模型,以使所述生成模型和所述判别模型基于互相对抗过程循环更新;
当所述对比值不大于预设的判别阈值时,通过所述生成模型生成所述识别文本的所述跟问文本。
进一步地,其特征在于,循环更新所述生成模型包括:
采用第一目标函数和随机梯度下降法循环更新所述生成模型,所述第一目标函数为:
进一步地,其特征在于,循环更新所述判别模型包括:
采用第二目标函数和随机梯度上升法循环更新所述判别模型,所述第二目标函数为:
进一步地,其特征在于,θ的计算公式为:
进一步地,其特征在于,采用第一损失函数训练所述生成模型,所述第一损失函数为:
与现有技术相比,本发明的有益效果是:本发明通过跟问模型输出跟问文本,提高了与用户的多轮交流能力,通过生成式对抗网络循环更新跟问模型以提高跟问能力,提高用户的体验。
附图说明
图1为本发明的流程框图;
图2为本发明中跟问模型的训练步骤流程框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种基于生成式对抗网络的语音生成方法,包括:
步骤s101,接收语音数据,识别所述语音数据获得识别文本,并执行步骤s102;当接收到用户输入的语音数据时,本发明实施例将对于该语音数据进行识别,得到识别文本,其中使用的识别方法为现有技术,在此不详述其具体方法。
步骤s102,将识别文本输入预置的跟问模型得到跟问文本,并执行s103;
其中,如图2所示,跟问模型为生成式对抗网络中的生成模型,其训练方法具有如下步骤:
步骤s201,从跟问语句库中抽取训练语句及训练语句对应的跟问语句,并执行步骤s202;
步骤s202,将训练语句输入生成模型得到模拟语句,并执行步骤s203;
步骤s203,通过判别模型对比跟问语句与模拟语句,得到跟问语句与模拟语句的对比值,将对比值反馈至生成模型并更新判别模型,并执行步骤s204;
需要说明的是,跟问语句的数据分布与跟问语句的数据分布和模拟语句的数据分布的和的比值,该比值可以代表跟问语句的数据分布和模拟语句的数据分布的差别。
具体的,判别模型为可迭代更新的深度神经网络模型,其判别能力随着一次次的迭代更新逐渐增强。将跟问语句和模拟语句输入该判别模型,可计算出跟问语句的数据分布和模拟语句的数据分布的差别,即得到跟问语句和模拟语句的对比值。
步骤s204,判断跟问语句和模拟语句的对比值是否不大于预设的判别阈值;若是,则执行步骤s205;若否,则执行s206;
步骤s205,通过生成模型生成识别文本的跟问文本;
步骤s206,根据跟问语句和模拟语句的对比值更新生成模型,并通过更新后的生成模型生成模拟语句,并执行步骤s204。
需要说明的是,循环更新生成模型包括:
采用第一目标函数和随机梯度下降法循环更新所述生成模型,第一目标函数为:
需要说明的是,循环更新判别模型包括:
采用第二目标函数和随机梯度上升法循环更新所述判别模型,第二目标函数为:
进一步地,本实施例中采用增强学习的方法对生成模型进行训练,其中,θ的计算公式为:
其中,c为生成模型的输入,x为生成模型的输出,p为生成模型的概率分布函数,r为判别模型的输出。
基于上述任意实施例,采用第一损失函数训练生成模型,第一损失函数为:
基于上述任意实施例,需要说明的是,当跟问语句和模拟语句的对比值不大于预设的阈值时,判别模型停止更新,但生成模型依然保持循环更新状态。当然,也可以为生成模型设置停止更新的阈值,使其在满足预设条件时停止更新。
具体的,跟问语句和模拟语句的对比值为:跟问语句数据分布pdata(x)与跟问语句数据分布pdata(x)和模拟语句数据分布pg(x)的和的比值,可用下述公式进行表示:
其中,
步骤s103,输出跟问文本。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



