
 商标分类
商标分类  商标转让
商标转让 
一种基于动机提取模型与神经网络的自动作曲方法与流程
 2021-01-28 16:01:53|
2021-01-28 16:01:53| 443|
443| 起点商标网
起点商标网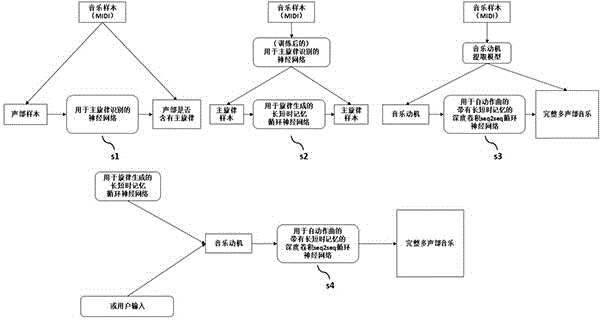
本发明涉及计算机音乐中音乐信息检索领域和计算机作曲领域,尤其涉及一种基于动机提取模型与神经网络的自动作曲方法。
背景技术:
基于神经网络的自动作曲一直是人工智能领域的一个研究热点,由于朴素的神经网络本身结构的缺陷,现有的基于神经网络的自动作曲方法在没有手工后处理的情况下,难以生成可听性较高的多声部音乐。另外,现有的自动作曲方法与音乐理论的结合程度不够,在乐理的角度上,算法的设计不够合理,这也是限制自动作曲方法效果的一个因素。
技术实现要素:
针对现有自动作曲方法中存在的缺陷或不足,本发明提供了一种基于动机提取模型与神经网络的自动作曲方法。所述基于动机提取模型与神经网络的自动作曲方法包括:一种动机提取模型,所述模型包括多个步骤:对于多声部音乐中的每一个独立声部,计算其自相似矩阵,使用高斯核沿对角线对自相似矩阵进行卷积运算,得到新奇度函数,根据新奇度函数将音乐样本分割为多个片段,计算这些片段之间的相似度,选出相似度最大的k个动机,作为提取出的音乐动机。
所述基于动机提取模型与神经网络的自动作曲方法还包括:一种基于神经网络的自动作曲方法。该方法包括:一种主旋律识别模型、一种旋律生成模型,和一个用于自动作曲的带有长短时记忆的深度卷积循环神经网络。
所述的主旋律识别模型包括:一个多层神经网络,输入为多声部音乐中一个声部的多个特征值,输出为对应声部是否为主旋律声部的布尔值。所述多层神经网络的训练样本为手工标注的样本,训练后的神经网络能够根据输入单个声部的多个特征值判断该声部是否包含主旋律。所述主旋律识别模型在所述自动作曲方法中的作用为:使用所述主旋律识别模型对多声部音乐样本中的每一个声部进行判断,将所有使模型输出真值的单声部音乐样本作为用于旋律生成的神经网络的训练样本。
所述用于旋律生成的神经网络为一个双向长短时记忆循环神经网络,其训练样本为所述主旋律识别模型准备好的训练样本。
所述用于自动作曲的带有长短时记忆的深度卷积循环神经网络的训练样本为,将所有midi样本输入动机提取模型,得到动机集合。对应的训练输出为完整多声部音乐。
所述自动作曲方法还包括:用户输入旋律片段,或对用于旋律生成的神经网络进行采样得到旋律片段,输入用于自动作曲的带有长短时记忆的深度卷积循环神经网络,可以得到所述模型的输出。
相对于现有技术,本发明有着输出的音乐可听性较高、符合音乐理论的技术效果,这些效果是由本发明中动机提取方法的使用与神经网络的架构所直接带来的。在实验中,所述基于动机提取模型与神经网络的自动作曲方法能够习得古典音乐写作中广泛使用的动机重用、模进等作曲技巧。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
图1是根据本发明的音乐生成方法的流程图;
图2是本发明主旋律识别模型的方法流程图;
图3是本发明动机提取模型的方法流程图。
具体实施方式
图1是根据本发明实例的一种自动作曲系统的示意图,其中s1、s2、s3表示神经网络训练阶段,s4表示系统应用阶段。
步骤s1,构建并训练用于主旋律识别的神经网络,包括步骤s101,s102,s103和s104。
步骤s101,首先,准备音乐midi数据集,数据集中的每个样本(即每首音乐作品)应包含多个声部。手工为每个样本的每个声部做主旋律标签,若该声部包含主旋律,则标签为“1”,否则为“0”,得到声部样本集。
步骤s102,对于步骤s101中得到的声部样本集进行处理,提取音乐数据中的多个乐理属性,包括:音符密度、平均时值、最大音程、音高分布方差、新奇度函数的积分值(s302)等,与步骤s101中得到的标签结合,得到用于主旋律识别的神经网络的训练集。
步骤s103,将步骤s102中得到的训练集输入神经网络并进行训练,其中,归一化处理后的乐理属性为输入,主旋律标签为目标输出。
步骤s2构建并训练用于旋律生成的长短时记忆循环神经网络。首先将所有音乐样本输入步骤s103中的主旋律识别神经网络,得到主旋律集合。建立一个的双向长短时记忆循环神经网络,将得到的主旋律集合中的的旋律样本输入神经网络并进行训练。
步骤s3实现音乐动机的提取,包括多个子步骤。
步骤s301,计算单个声部midi文件的相似度矩阵s。,其中,为所述midi文件的第i帧与第j帧,i、j的取值范围取决于对midi文件的采样率。
步骤s302,使用高斯核对所述矩阵s沿对角线进行卷积运算,得到新奇度函数n。使用高斯核可以同时捕捉自相似度(高斯核左下与右上部分)与交叉相似度(高斯核左上与右下部分)。
步骤303,使用差分法求新奇度函数n的极大值,对于一阶差分函数中距离小于δ的零点,取对应新奇度函数n值大者。
步骤s304,所得极大值点作为分割点,对midi进行拆分,得到多个动机候选片段。
步骤s305,对所得动机候选片段的midi文件对应的钢琴卷帘矩阵进行高斯模糊处理,从而在后续步骤中容许动机的小幅变化。
步骤s306,计算动机相似度矩阵s’。其中,为所述第i个和第j个动机候选片段,conv_sim()函数定义为:对第i个(模糊后的)动机候选矩阵,以第j个动机候选矩阵为卷积核做fullpadding的卷积运算,取所得矩阵中的最大值作为对应conv_sim()函数的值。卷积操作既容许了分割操作的误差(卷积核的水平方向移动),增加了鲁棒性,又赋予了模型识别转调后的动机的能力(卷积核的垂直方向移动)。
步骤s307,在所得动机相似度矩阵s’中,留取相似度最高的2-4个动机对。在一段音乐中,动机会以相同或相似的形态反复出现,因而这一步骤不仅完成了重复出现的动机的筛选,也滤去了其他噪音,提高了后续神经网络训练集的质量。
步骤s308,最后,将所得2k个动机片段作为神经网络的输入,对应的全声部音乐作为目标输出,训练用于自动作曲的带有长短时记忆的深度卷积循环神经网络。所述神经网络同时曾广泛应用于机器翻译,此处可以看作音乐动机到完整多声部音乐的翻译。
步骤s4为应用阶段,用户输入旋律片段,或对用于旋律生成的神经网络进行采样得到旋律片段,输入用于自动作曲的带有长短时记忆的深度卷积循环神经网络,可以得到所述模型的输出。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



