
 商标分类
商标分类  商标转让
商标转让 
一种针对语音识别系统的黑盒对抗样本攻击方法与流程
 2021-01-28 16:01:51|
2021-01-28 16:01:51| 506|
506| 起点商标网
起点商标网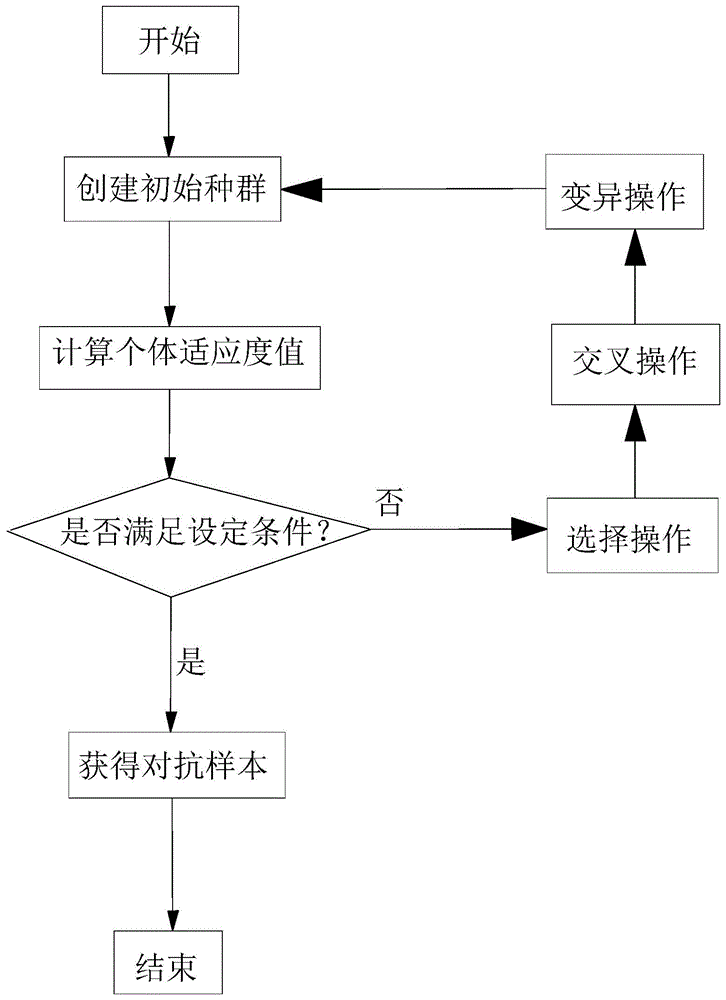
本发明涉及语音识别技术领域,尤其涉及一种针对语音识别系统的黑盒对抗样本攻击方法。
背景技术:
语音对抗样本是指一种被攻击者有目的的向语音信号中加入细微扰动后的样本,其主要目的是使目标语音识别系统对该对抗样本做出错误的识别,甚至识别成攻击者指定的结果。在听觉感受上,语音对抗样本与其被修改前的样本相似;在作用上,却能使语音识别系统输出错误的识别结果。现有的主流攻击方法按攻击者是否能够利用目标网络信息可以分为两种:白盒攻击和黑盒攻击。白盒攻击是假设攻击者能够获得目标语音识别系统的模型信息(包括网络模型和参数等),而黑盒攻击是假设攻击者无法获得模型信息,但能够获得目标语音识别系统对输入语音的输出。
当前语音识别系统攻击的研究中,taori利用遗传算法迭代寻找满足对抗样本条件的最优个体,carlini假设攻击者能够获得目标语音识别系统的信息,并根据目标识别系统的输出设计了目标函数,对该目标函数进行优化,最终获得最优的对抗样本。taroi使用遗传算法寻找最优个体从而获得对抗样本,在适应度计算中利用了目标语音识别网络最后一层的输出,使得该方法无法应用于实际场景的对抗样本攻击;此外,仅在变异算子中添加均匀分布的随机扰动,这导致算法搜索最优个体的时间代价较高。carlini利用目标语音识别网络最后一层的输出与目标文本的稀疏编码设计了优化目标函数,利用梯度反传算法,不断地优化目标函数,最终使语音样本被目标语音识别系统识别为目标文本,该方法生成的语音样本虽然能使目标语音识别网络识别错误,但其假设攻击者能够获得目标语音识别网络的参数信息使其也无法应用于实际对抗样本攻击。此外,目前存在的对抗样本方法仅对单个语音识别系统有效。不难看出,现有的语音对抗样本攻击方法中,大部分方法都假攻击者能够获得目标模型的参数,这使得这些方法无法应用于实际物理世界的攻击。
技术实现要素:
鉴于上述问题,本发明的目的在于提供一种针对语音识别系统的黑盒对抗样本攻击方法,该方法无需假设攻击者能够获得目标模型的信息即可生成语音对抗样本。
为了实现上述目的,本发明的技术方案为:一种针对语音识别系统的黑盒对抗样本攻击方法,其特征在于:包括,
s1,种群初始化;
s2,计算种群中个体的适应度值;
s3,判断个体的适应度值是否满足设定条件,若是,则获得对抗样本,若否,则执行s4;
s4,对种群中的个体进行选择操作获取精英个体;
s5,对种群中获取精英个体后的剩余个体进行交叉操作;
s6,对剩余个体执行变异操作;
s7,将执行变异操作后的剩余个体与精英个体构成下一代并返回执行s1。
进一步的,所述s1中的种群的个体由如下公式获得:
pi=x+ri×wi,i=1,2,…,n,
其中x为待修改的音频样本,n表示种群规模,ri为向第i个个体中添加的随机扰动,wi为根据待修改的音频样本x计算的扰动权重向量;
ri,j由如下公式获得:
ri,j=r(-b,b),j=1,2,…m,
其中m表示单个个体的基因数,ri,j表示第i个个体中的第j个基因,b表示扰动的取值范围b=256;r()是随机函数,该函数从[-b,b]范围内随机选择一个整数;
wi,j由如下公式获得:
其中wi,j表示第i个个体的第j个基因的权重,qmin,q,qmax分别表示权重的取值范围,其中qmin,=0.6,q=1,qmax=2;r′()是随机函数,该函数在区间[qmin,q](或[q,qmax])内生成一个随机数作为当前基因的权重;|·|表示绝对值函数;函数sort()表示对变量进行从大到小的排序。
进一步的,所述s2中适应度值采用如下公式进行计算:
其中f()是目标语音识别网络的函数,该函数接收个体p作为输入,输出相应的翻译结果s;levenshtein(s,t)是指将个体的文本识别结果s通过插入、删除或替换转换成目标文本t所需要的最小单字符编辑次数;h是指目标文本t的字符个数。
进一步的,所述s3中的设定条件为,wer值为0。
进一步的,所述s4中选择操作包括,对个体的适应度值进行降序排序,得到排完序的种群p′=(p1′,p2′,…,pn′),取前topk个个体作为精英个体p′topk。
进一步的,所述s5中的剩余个体为n-topk个,所述s5中交叉操作包括,
首先,随机从n-topk个剩余个体p′n-topk中取两个个体作为父代1和父代2;然后,生成个体基因长度的随机数向量λ,其中随机数向量λ的范围为[0,1],最后子代的取值基于随机数向量λ,规则如下公式所示:
上式中子代offspring的第i个基因的值根据随机向量中λ第i个值决定;若λi小于0.5,子代第i个值取自父代1中第i个基因parent1i的值;否则,子代第i个值取自父代2中第i个基因parent2i的值,最终生成n-topk个子代。
进一步的,所述s6中变异操作采用如下公式进行,
new_pi=offspring+ri×wi,i=1,2,…,n-topk。
与现有技术相比,本发明的优点在于:
本申请的方法在攻击者无法获得目标语音识别网络的条件下,仅利用目标语音识别网络提供的语音到文本的翻译功能,通过使用改进的传统遗传算法中的适应度函数和初始化及变异算法,能够成功地生成目标语音识别系统的对抗样本,从而使得该方法具有很好的实用性。
附图说明
图1本申请的方法流程图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
如图1为本申请的方法流程图,如图所示,该种针对语音识别系统的黑盒对抗样本攻击方法,包括如下步骤:
s1,种群初始化;
s2,计算种群中个体的适应度值;
s3,判断个体的适应度值是否满足设定条件,若是,则获得对抗样本,若否,则执行s4;
s4,对种群中的个体进行选择操作获取精英个体;
s5,对种群中获取精英个体后的剩余个体进行交叉操作;
s6,对剩余个体执行变异操作;
s7,将执行变异操作后的剩余个体与精英个体构成下一代并返回执行s1。
具体而言,该方法的详细流程如下:
种群初始化:
假设音频x为待修改的样本,种群中个体通过如下公式(1)获得:
pi=x+ri×wi,i=1,2,…,n(1)
其中n表示种群规模,ri为向第i个个体中添加的随机扰动,其由公式(2)获得。wi为根据待修改的样本x计算的扰动权重向量,其由公式(3)获得。在使用遗传算法生成语音对抗样本的问题中,个体是语音采样值序列,是一个1维向量,基因的规模取决于语音序列的长度(1秒音频16000个采样点,即16000个基因)。若通过添加随机扰动使目标语音识别系统做出错误的识别结果,则需要较大的时间代价,算法的收敛速度也慢。为了解决该问题,本发明提出扰动权重方法,即对语音内容部分赋予更大的权重,增加对语音内容部分采样点的修改能够更快地改变目标语音识别系统的识别结果。扰动权重的方法由公式(3)给出。
ri,j=r(-b,b),j=1,2,…m(2)
其中m表示单个个体的基因数,ri,j表示第i个个体中的第j个基因,b表示扰动的取值范围,本实施例中b=256;r()是随机函数,该函数从[-b,b]范围内随机选择一个整数。通过公式(3)为个体生成扰动,每个个体的扰动都不同,这保证了种群的多样性。
其中wi,j表示第i个个体的第j个基因的权重,qmin,q,qmax分别表示权重的取值范围,其中qmin,=0.6,q=1,qmax=2,;r′()是随机函数,该函数在区间[qmin,q](或[q,qmax])内生成一个随机数作为当前基因的权重;i·i表示绝对值函数;函数sort()表示对变量进行从大到小的排序。扰动权重方法的详细过程为:首先,对个体进行一阶差分操作|xj-xj-1|,个体基因长度变为;为使一阶差分后个体的基因个数不发生变化,在一阶差分后向量的第一个位置插入原始基因的值,从而得到长度为m的向量{x1,x2-x1,...,xj-xj-1};然后,对该向量中的元素取绝对值,并进行从大到小排序。最后,排序前50%的采样点覆盖大部分语音内容,因此赋予更高的权重;在排序后50%的采样点静音段较多,因此赋予更低的权重。
适应度值计算:
适应度值是判断的个体是否满足对抗样本唯一依据。适应度函数的设计也关乎算法能够应用于实际攻击。因此,为了使算法能够应用于实际攻击,本发明使用基于levenshtein距离(编辑距离)的词错误率(wer)作为个体的适应度值。如公式(4)所不:
其中f()是目标语音识别网络的函数,该函数接收语音(个体p)作为输入,输出相应的翻译结果s;levenshtein(s,t)距离是指将个体的文本识别结果s通过插入、删除或替换转换成目标文本t所需要的最小单字符编辑次数;h是指目标文本t的字符个数。wer越小越好,当个体的识别结果s与目标文本t完全一样时,wer值为0,即生成了对抗样本。
如果通过适应度值计算不能生成对抗样本,则继续执行选择操作,选择操作的执行如下:
对个体的适应度值进行降序排序,得到排完序的种群p′=(p1′,p2′,...,pn′)。取前topk个个体作为精英个体p′topk,不参与交叉和变异,对剩余的n-topk个个体p′n-topk进行交叉和变异。
交叉操作:
对上述剩余的n-topk个个体执行交叉操作,本申请使用的交叉操作规则如下所示:
如上表所示,本发明采用的交叉算子为,首先,随机从n-topk个个体p′n-topk中取两个个体作为父代1和父代2,然后生成个体基因长度的随机数向量λ,其中随机数的范围为[0,1],最后子代的取值基于随机数向量λ,规则如公式(5)所示:
其中,子代offspring的第i个基因的值根据随机向量中λ第i个值决定;若λi小于0.5,子代第i个值取自父代1中第i个基因parent1i的值;否则,子代第i个值取自父代2中第i个基因parent2i的值。通过这种方式,生成n-topk个子代。
变异操作:
对完成交叉操作的n-topk个子代依变异概率进行变异操作,本发明使用的变异算子如公式(6)所示:
new_pi=offspring+ri×wi,i=1,2,…,n-topk
本发明使用的变异算子将初始化算子中的音频x更改为完成交叉操作的子代offspring,相应地将公式(3)中的变量x修改为offspring就成了本利使用的变异算子。最终将执行完变异操作的n-topk子代new_pi与topk个精英个体构成n个下一代作为一个新的种群继续进行计算。
尽管已经示出和描述了本发明的实施例,本领域技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变形,本发明的范围由权利要求及其等同物限定。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



