
 商标分类
商标分类  商标转让
商标转让 
面向家居CNN分类与特征匹配联合的声纹识别方法与流程
 2021-01-28 16:01:34|
2021-01-28 16:01:34| 430|
430| 起点商标网
起点商标网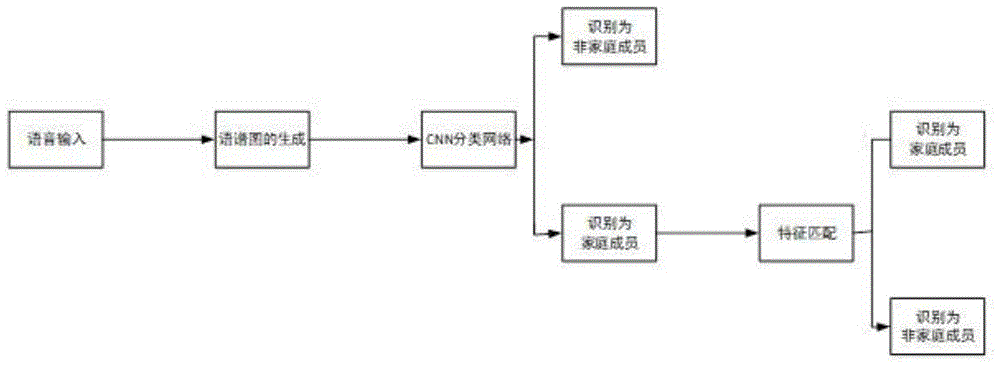
本发明属于声纹识别领域,具体涉及一种面向家居cnn分类与特征匹配联合的声纹识别方法。
背景技术:
声纹识别也称为说话人识别,包括说话人辨认和说话人确认。声纹识别应用领域十分广泛,包括金融领域、军事安全、医疗领域以及家居安全领域等等。在许多声纹识别系统的识别之前,除了预处理操作外,特征参数和模型匹配对识别的准确率至关重要。现有的声纹识别算法无法达到百分之百的识别准确率,误检率和漏检率较高,无法保证家居环境下的人身和财产的绝对安全。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,提供一种面向家居cnn分类与特征匹配联合的声纹识别方法,在保证识别准确率的前提下,降低误检率和漏检率。该方法对现有模型进行改进,从而解决误检率和漏检率较高的问题。
技术方案:为实现上述目的,本发明提供一种面向家居cnn分类与特征匹配联合的声纹识别方法,包括如下步骤:
s1:对语音进行短时傅里叶变换生成语谱图;
s2:将语谱图输入到训练好的卷积神经网络进行分类,若识别为非家庭成员,流程结束,否则,转至步骤s3;
s3:对语音信号提取mfcc特征参数;
s4:将mfcc特征参数和k-means特征模板进行匹配,获取最终识别结果。
进一步的,所述步骤s1中语音在进行短时傅里叶变换之前经过预处理操作。
进一步的,所述步骤s1中预处理操作包括采样量化、预加重、加窗和分帧、端点检测。
进一步的,所述步骤s2中卷积神经网络包括输入层、卷积层、池化层、全连接层和输出层,池化层采用平均池化,输出层采用softmax函数,采用bp算法对卷积神经网络进行训练。
进一步的,所述步骤s3中通过mel滤波器的阶数调整提取mfcc特征参数。
进一步的,所述步骤s3中mfcc特征参数的提取过程为:
a)对输入的语音信号进行预处理,生成时域信号,对每一帧语音信号通过快速傅里叶变换或离散傅里叶变换处理得到语音线性频谱;
b)将线性频谱输入mel滤波器组进行滤波,生成mel频谱,取mel频谱的对数能量,生成相应的对数频谱;
c)使用离散余弦变换将对数频谱转换为mfcc特征参数。
进一步的,所述步骤s4中k-means特征模板的生成过程为:随机选择聚类中心;遍历数据集中所有样本,计算训练数据集分别到各个聚类中心的距离,记录距离最近的中心点,然后把这个点分配到这个聚类内;接着遍历所有的聚类中心,移动聚类中心的新位置到所有属于这个聚类的均值处;重复上面步骤,不断更新聚类中心位置直到不再移动。
进一步的,所述步骤s4中采用余弦相似度方法进行匹配,通过计算两个矢量之间夹角的余弦值来评估相似度。
进一步的,所述步骤s1中语谱图的生成过程为:
a)对语音信号进行分帧处理,得到x(m,n),其中m表示帧的个数,n表示帧长,再通过短时傅里叶变换,转为x(m,n);
b)经过公式x(m,n)×x(m,n)=y(m,n),将x(m,n)变成周期图;
c)对周期图进行取对数处理,m、n分别根据时间和概率刻度变换为m与n,生成二维语谱图。
本发明方法首先对说话人语音进行语谱图的生成,其次语谱图作为输入,输入到卷积神经网络,若识别为非家庭成员,流程结束,否则需再次确认。提取说话语音的mfcc特征,用模板匹配方法和余弦相似度测量,输出最终识别结果。
有益效果:本发明与现有技术相比,基于语谱图的生成、卷积神经网络、k-means算法、余弦相似度测量方法,在保证识别准确率的情况下,有效的降低了语音识别的误检率和漏检率,解决了误检率和漏检率较高的问题,保证了家居环境的绝对安全。
附图说明
图1为本发明方法的总体结构框图;
图2为mfcc特征参数提取流程图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,本发明提供一种面向家居cnn分类与特征匹配联合的声纹识别方法,包括如下步骤:
1)对输入的说话人的语音进行预处理,预处理包括采样量化、预加重、加窗和分帧、端点检测等。预处理目的是消除发声器官和语音采集设备的干扰,提高系统的识别率。
2)对预处理过的语音进行短时傅里叶变换生成语谱图,具体的过程为:
a)对语音信号进行分帧处理,得到x(m,n),其中m表示帧的个数,n表示帧长,再通过短时傅里叶变换,转为x(m,n);
b)经过公式x(m,n)×x(m,n)=y(m,n),将x(m,n)变成周期图;
c)对周期图进行取对数处理,m、n分别根据时间和概率刻度变换为m与n,生成二维语谱图。
3)将语谱图输入到训练好的卷积神经网络进行分类,若识别为非家庭成员,流程结束,否则,转至步骤4;
4)对语音信号提取mfcc特征参数;
5)将mfcc特征参数和k-means特征模板进行匹配,获取最终识别结果。
本实施例中卷积神经网络包括输入层、卷积层、池化层、全连接层和输出层,池化层采用平均池化,输出层采用softmax函数。
采用bp算法对卷积神经网络进行训练。
由卷积神经网络的结构可知,网络包含的参数有:卷积核、偏置项以及全连接网络的权值等。这些参数的求解需要用到反向传播算法。
约定卷积层k后面跟着层k+1,为了求得l中传输的误差信号,需要现堆下一层中所有对应于该神经元的信号求和,并将这些信号乘上相对应于k+1层的权值。降采样层中的权重都等于β(一个常量,见降采样层的梯度计算),所以只需要将前面一部的结果放大β倍来计算δk。重复这个步骤计算卷积层中每一个图j,并将其和降采样层对应起来:
其中f′(.)表示激活函数的一阶导数,up(.)表示升采样操作,简单的讲输入像素从水平和垂直方向重复复制n次,相当于降采样操作时的因子n。一个简单的实现方法是通过kronecker积:
现在有了给定图的误差信号,可以通过对所有误差中的项目求和来计算出偏差的梯度:
最后,核函数的权重的梯度通过反向传播计算,只不过这里很多连接共享权重。将该权重涉及到的所有梯度求和:
其中
降采样层的梯度计算,降采样层产生输入图的降采样后的结果。如果有n个输入图,就同样有n个输出图,尽管输出图相对于输入图会小一些。
其中down(.)表示降采样函数。
这里的难度在于计算误差信号图。仅有的可学习的参数是β和b。假定采样层的上一层和下一层都是卷积层。如果降采样层后面是全连接网络,那么其误差信号图可以通过反向传播算法直接得到。
在卷积层的梯度计算力,需要找到输入图中哪些块是对应输出图中的某一个像素。这里同样必须找到当前层的敏感图中哪些块对应下一层中的某个像素。显然,输入的输出链接的输出链接所乘于权重就是全集和的权重。同样可以有效地通过下面的公式实现:
现在可以计算β和b的梯度,其中b就是误差信号图中元素对μ,v的求和:
乘子偏差显然和前向传播中当前层的原始降采样图(降采样后没有附加偏差所构成的一个特征图)有关。由此可知,如果在前向传输过程中保存这些图将为后续计算做出有效帮助。据此定义:
所以β的梯度由以下公式给出:
如图2所示,本实施例中提取mfcc特征参数的具体步骤如下:
(1)对输入的语音信号s(n)进行预处理,生成时域信号x(n)(信号序列的长度n=256),接着,对每一帧语音信号通过快速傅里叶变换或离散傅里叶变换处理得到语音线性频谱x(k),可表示为:
(2)将线性频谱x(k)输入mel滤波器组进行滤波,生成mel频谱,接着取它的对数能量,生成相应的对数频谱s(m)。
这里,mel滤波器组是一组三角带同滤波器hm(k),且需满足0≤m≤m,其中m表示滤波器的数量,通常为20~28。带通滤波器的传递函数可以表示为:
f(m)为中心频率。
其中,之所以对mel能量频谱取对数,是为了促进声纹识别系统性能的提升。语音线性频谱x(k)到对数频谱s(m)的传递函数为:
(3)通过使用离散余弦变换(dct)将对数频谱s(m)求解转换为mfcc特征参数,mfcc特征参数的第n维特征分量c(n)的表达式为:
通过上述步骤获得的mfcc特征参数仅反映语音信号的静态特性,可通过求其的一阶、二阶差分得到动态特性参数。
本实施例中k-means特征模板的生成采用k-均值算法(k-means),k均值算法是无监督的机器学习算法,无监督学习的算法不需要标签,因此可以大大减少对数据标记的工作量,可应用的范围更广。k-means算法首先需要选择k,即选择聚类的个数;另一个是训练数据集x(1),x(2),...,x(m)。
首先随机选择聚类中心:μ1,μ2,....μk;遍历数据集m中所有样本,计算x(i)分别到各个聚类中心μ1,μ2,....μk的距离,记录距离最近的中心点μj,然后把这个点分配到这个聚类内。计算距离时通常使用:||x(i)-μj||;接着遍历所有的聚类中心,移动聚类中心的新位置到所有属于这个聚类的均值处,即
本实施例中采用余弦相似度(cosinesimilarity)方法对mfcc特征参数和k-means特征模板进行匹配,通过计算两个矢量之间夹角的余弦值来评估他们的相似度。若向量
若两个方向一致,则夹角接近于零,就认为这两个向量越相似,余弦相似度越接近于1。在声纹识别比对相似度时,若待测语音与目标说话人语音越接近,即余弦相似度值越大,则认为是同一个说话人。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



