
 商标分类
商标分类  商标转让
商标转让 
一种基于深度神经网络的哭声检测方法和系统与流程
 2021-01-28 16:01:49|
2021-01-28 16:01:49| 336|
336| 起点商标网
起点商标网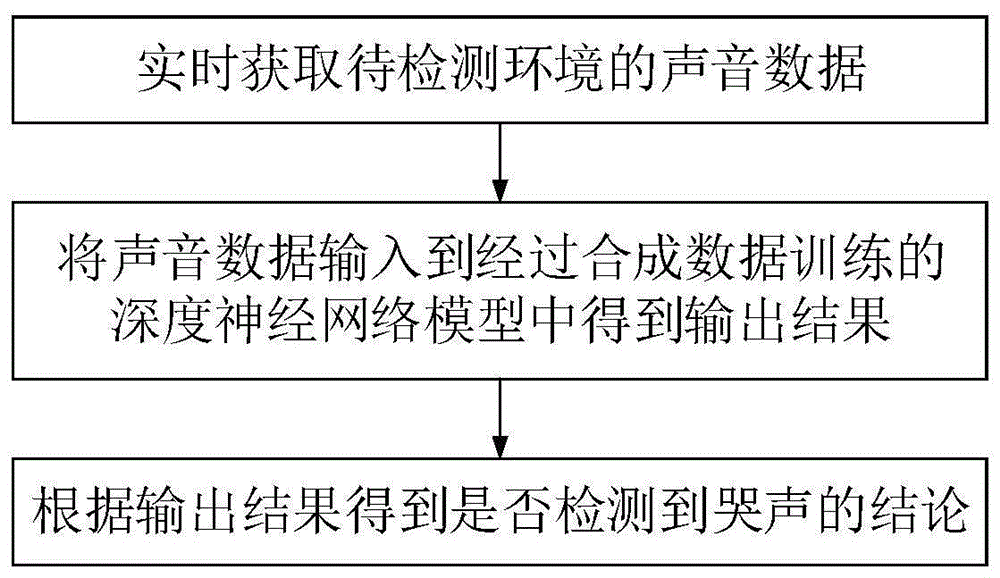
本发明涉及声音检测领域,特别地,涉及一种基于深度神经网络的哭声检测方法和系统。
背景技术:
婴幼儿是祖国的希望,但是保姆虐婴,幼师打骂儿童事件屡见不鲜,从而引起父母深深的担忧。所以实时检测婴幼儿哭声事件,并能及时反馈给父母或者报警系统,显得尤为重要。目前婴幼儿哭声检测技术,大多是对于家居环境下的婴儿进行哭声检测,卧室、家居环境一般较安静,底噪比较低。而对于环境比较复杂的非家居环境比如幼儿园、公园等,这些检测的准确率会明显降低,容易出现误报、漏报现象。同时对于一些易混淆的声音,与哭声类似,容易误检测成哭声,如喵喵叫、笑声)、叽叽喳喳谈话声、吱吱叫、尖声喊叫等。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于深度神经网络的、能够在环境比较复杂的场景应用且能够区分易混淆声音的哭声检测方法和系统。
本发明解决其技术问题所采用的技术方案是:
一方面,
一种基于深度神经网络的哭声检测方法,包括以下步骤:
获取待检测环境的声音数据;
将所述声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;
根据所述输出结果得到是否检测到哭声的结论。
进一步地,所述获取待检测环境的声音数据包括:
采用拾音器对待检测环境进行录音获得音频信号;
对所述音频信号进行音频特征提取和数据增强得到声音数据。
进一步地,所述经过合成数据训练的深度神经网络模型为采用纯净哭声数据、场景声音数据和易混声音数据合成的数据集训练得到的深度神经网络模型。
进一步地,所述深度神经网络模型的训练步骤为:
获取合成的数据集,所述数据集包括合成的音频信号;
根据所述合成的音频信号进行音频特征提取并进行数据增强得到深度神经网络的输入;
根据所述输入对深度神经网络模型进行训练。
进一步地,所述进行音频特征提取包括:
将音频信号进行预加重、分帧和加窗以及通过快速傅里叶变换得到频谱;
将所述频谱通过mel滤波器得到mel频谱;
对所述mel频谱取对数得到对数mel频谱特征。
进一步地,所述数据增强的方法包括:mixup、缩放和遮盖,所述数据增强用于消除模型的过拟合现象。
进一步地,所述获取合成的数据集包括:
分别获取纯净哭声数据、易混声音数据以及场景声音数据;
对所述纯净哭声数据、易混声音数据以及场景声音数据使用基于svm的半监督分类进行注释,并标注开始时间和结束时间形成样本标签;
将所述开始时间和所述结束时间内的纯净哭声数据的音频片段与易混声音数据以及场景声音数据进行混合,形成混合样本以及混合样本标签,即合成的数据集。
进一步地,所述输出结果为预设帧数内的音频信号是哭声的概率。
进一步地,根据所述输出结果得到是否检测到哭声的结论包括:
将所述概率与预设概率值进行比较;
若所述概率不小于所述预设概率值,则得出检测到哭声的结论;若所述概率小于所述预设概率值,则得出未检测到哭声的结论。
另一方面,
一种基于深度神经网络的哭声检测系统,包括:
数据获取模块,获取待检测环境的声音数据;
模型输出模块,用于将所述声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;
结论获取模块,用于根据所述输出结果得到是否检测到哭声的结论。
本申请采用以上技术方案,至少具备以下有益效果:
本发明技术方案公开了一种基于深度神经网络的哭声检测方法和系统,通过实时获取待检测环境的声音数据,再将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果,最后根据输出结果得到是否检测到哭声的结论。实时的获取声音数据进行检测,能够及时发出警告;同时将获取的声音数据通过经过合成数据训练的深度神经网络模型,能够在不同的场景中检测到哭声,同时也能够将易混淆的声音区分出来。大大提高了检测的准确率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种基于深度神经网络的哭声检测方法的流程图;
图2是本发明实施例提供的另一种基于深度神经网络的哭声检测方法的流程图;
图3是本发明实施例提供的一种基于深度神经网络的哭声检测系统的结构图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面结合附图和实施例对本发明的技术方案进行详细的描述说明。显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本申请所保护的范围。
参照图1,本发明实施例提供了一种基于深度神经网络的哭声检测方法,包括以下步骤:
实时获取待检测环境的声音数据;
将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;
根据输出结果得到是否检测到哭声的结论。
本发明实施例提供的一种基于深度神经网络的哭声检测方法,通过实时获取待检测环境的声音数据,再将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果,最后根据输出结果得到是否检测到哭声的结论。实时的获取声音数据进行检测,能够及时发出警告;同时将获取的声音数据通过经过合成数据训练的深度神经网络模型,能够在不同的场景中检测到哭声,同时也能够将易混淆的声音区分出来。大大提高了检测的准确率。
作为对上述实施例的进一步改进说明,本发明实施例提供了另一种基于深度神经网络的哭声检测方法,如图2所示,包括训练部分和预测部分,其中预测部分包括以下步骤:
实时获取待检测环境的声音数据;
具体的,采用拾音器对待检测环境进行录音获得音频信号;一些可选实施例中,拾音器包括但不限于:手机麦克风或者需要做哭声检测的产品麦克风。
对音频信号进行音频特征提取和数据增强得到声音数据。音频特征提取和数据增强详见下文。
将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;
其中,经过合成数据训练的深度神经网络模型为采用纯净哭声数据、场景声音数据和易混声音数据合成的数据集训练得到的深度神经网络模型。
进一步地,输出结果为预设帧数内的音频信号是哭声的概率。优选地,将提取得到的音频特征输入到训练好的神经网络模型,从而得到预测结果,该结果是299帧(3.5s)音频信号是哭声的概率p,0<=p<=1。这样避免了只考虑单帧而引起的预测结果不稳定的问题。
根据输出结果得到是否检测到哭声的结论。
由于在实时检测中,得到的结论只能是检测到哭声和没有检测到哭声两种情况,而根据深度神经网络模型得到的概率只是一个数值,因此必须根据这个概率得到其是否检测到哭声的结论。
示例性的,实时预测时,可以设置预测频率即每隔多久输出一次预测结果。当采集音频长度小于299帧时,会进行数据填充操作,输出预测结果。当超过299帧时,会根据设置的预测频率,输出当前时刻前299帧的预测结果。优选地,本发明实施例中预测频率为0.5s。
得到每299帧的状态预测概率为0~1的概率值,而最终需要的结果是有婴幼儿哭声或正常的判断结果。因此需要选择合适的阈值,将概率p转化为二值化的判断结果。
可选地,将概率与预设概率值进行比较;
若概率不小于预设概率值,输出值为1,得出检测到哭声的结论;若概率小于预设概率值,输出值为0,得出未检测到哭声的结论。
其中,训练部分主要为度神经网络模型的训练步骤,包括:
获取合成的数据集,数据集包括合成的音频信号;
一些可选实施例中,获取合成的数据集包括:
分别获取纯净哭声数据、易混声音数据以及场景声音数据;具体地,纯净的哭声数据包括日常安静环境录制以及网络收集,采样频率一般为44.1khz;场景声音数据选择了一些典型的发生场景,如校园、教室、小型室内、办公室、公园、广场、商场、图书馆等等,数据获取方式同样包含自行录制和网络搜集。
对纯净哭声数据、易混声音数据以及场景声音数据使用基于svm的半监督分类进行注释,并标注开始时间和结束时间形成样本标签;一些可选实施例中,进一步地,对于收集的音频进行人工确认标注,确认标签。
将开始时间和结束时间内的纯净哭声数据的音频片段与易混声音数据以及场景声音数据进行混合,形成混合样本以及混合样本标签,即合成的数据集。
具体地,将哭声和易混声音数据与不同场景声音数据进行混合。具体操作为将纯净哭声数据和易混声音数据样本,根据标注的开始和结束时间,截取出相应的音频片段,然后与场景声音数据进行混合,形成新的混合样本和样本标签。控制合成样本的参数包括:样本与背景的信噪比(可选地,信噪比为-6db/0db/6db中的任意一个),音频片段插入位置与长度(示例性的,位置随机,长度不超过3s),生成合成样本的个数与标签(示例性的,合成哭声样本10000个,非哭声样本20000个。哭声合成样本标签为“哭声”,易混声音数据合成样本和场景音频的标签为“正常”),合成音频的采样率和长度(示例性的,采样率为44.1khz,合成音频长度是4s,其中插入音频最长为3s,背景音频长度为4s)。
根据合成的音频信号进行音频特征提取并进行数据增强得到深度神经网络的输入;作为本发明实施例中一种优选的实现方式,模型网络结构采用inception模块,该模块同一层级有多个尺寸的卷积核,从而拓宽网络的宽度,充分利用图像的信息。并且使用尺寸为1的卷积核,使得模型参数大大降低。训练损失函数为二分类交叉熵,采用adam优化器进行梯度下降运算。最终哭声检测模型测试集准确率为99%以上,实时预测时误报很少,而且预测概率值稳定在1左右。
根据输入对深度神经网络模型进行训练。对深度神经网络模型进行训练为本领域常用技术手段,在此不再详述。
需要说明的是,在训练部分和预测部分都包括的进行音频特征提取和数据增强,其中,音频特征提取包括:
将音频信号进行预加重、分帧和加窗以及通过快速傅里叶变换得到频谱;
将频谱通过mel滤波器得到mel频谱;
对mel频谱取对数得到对数mel频谱特征。
具体地,参数设置一般为:采样率44.1khz,窗长2048个采样点,窗移512个采样点,选用汉明(hamming)窗,从而降低fft时矩形窗的频谱泄露,帧数是299,mel滤波器个数为128。为了匹配神经网络模型,本发明实施例将音频三个相同的对数mel频谱特征进行拼接,得到音频特征的维度为(128,299,3)。
一些可选实施例中,数据增强的方法包括但不限于:mixup、缩放和遮盖,数据增强用于消除模型的过拟合现象。
本发明实施例提供的另一种基于深度神经网络的哭声检测方法,采用哭声事件和易混事件与背景声混合的方式,形成鲁棒性更好的数据集,并训练得到能够适用于多种场景的卷积神经网络模型。该模型可以实时的对各种场景的哭声事件进行检测,而且更充分的利用了音频信号的信息,从而具有更强的鲁棒性和更高的准确率。相比于只针对特定环境分析、基音频率分析、svm分类等方法,本发明具有更广泛的适用性,而且实时性好,精度高。本方法通过纯净的哭声事件和哭声相似事件与多种生活场景数据混合方式得到数据集、训练深度卷积神经网络,对生活中的哭声事件进行检测。相对于已有方案有两方面优点:一是选用的数据集鲁棒性强,训练的模型适用于多数场景而且误报率低;二是建立inception模块的卷积神经网络,模型参数少,精度高,方便应用到所需设备上。哭声检测模型在测试集上的准确率为99%以上,实时预测时误报很少,而且预测概率值很稳定,接近1。
一个实施例中,如图3所示,本发明还提供了一种基于深度神经网络的哭声检测系统300,包括:
数据获取模块301,用于实时获取待检测环境的声音数据;
一些实施例中,数据获取模块采用拾音器对待检测环境进行录音获得音频信号;对音频信号进行音频特征提取和数据增强得到声音数据。
模型输出模块302,用于将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;经过合成数据训练的深度神经网络模型为采用纯净哭声数据、场景声音数据和易混声音数据合成的数据集训练得到的深度神经网络模型。
结论获取模块303,用于根据输出结果得到是否检测到哭声的结论。其中,输出结果为预设帧数内的音频信号是哭声的概率。
具体地,结论获取模块用于将概率与预设概率值进行比较;
若概率不小于预设概率值,则得出检测到哭声的结论;若概率小于预设概率值,则得出未检测到哭声的结论。
本发明实施例提供的一种基于深度神经网络的哭声检测系统,数据获取模块实时获取待检测环境的声音数据;模型输出模块将声音数据输入到经过合成数据训练的深度神经网络模型中得到输出结果;结论获取模块根据输出结果得到是否检测到哭声的结论。通过适用于多种场景的卷积神经网络模型,可以实时的对各种场景的哭声进行检测,而且更充分的利用了音频信号的信息,从而具有更强的鲁棒性和更高的准确率。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本申请的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本申请的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本申请的实施例所属技术领域的技术人员所理解。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



