
 商标分类
商标分类  商标转让
商标转让 
声学噪声抑制设备和声学噪声抑制方法与流程
 2021-01-28 16:01:26|
2021-01-28 16:01:26| 296|
296| 起点商标网
起点商标网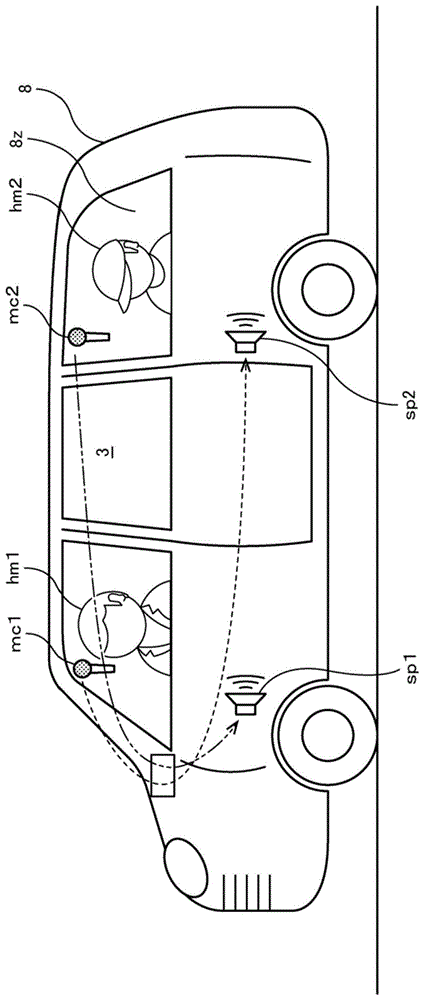
本发明涉及用于抑制环境中的声学噪声的声学噪声抑制设备和声学噪声抑制方法。
背景技术:
例如,研究了诸如厢式旅行车、货车或单厢车等的在前后方向上配置有多个(例如,三排或更多排)座椅的相对大的车辆所用的会话支持系统。具体地,作为该会话支持系统,研究了如下的机构,该机构使用各座椅中所安装的麦克风和扬声器来传输声音,使得坐在驾驶座上的驾驶员和坐在后排座椅的乘员(例如,驾驶员的朋友)可以具有流畅的会话。
在会话支持系统中,驾驶员所发出的声音由驾驶座中所安装的麦克风拾取,并从后排座椅中所安装的扬声器输出。因此,即使当车辆在车辆有可能振动的未铺设道路上行驶或在喧闹的城市中行驶时,后方的乘员也较容易听到驾驶员的声音。另外,由于后方的乘员所发出的声音由后排座椅中所安装的麦克风拾取并从驾驶座中所安装的扬声器输出,因此驾驶员可以容易地听到后方乘员的声音。
在这样的会话支持系统中,从扬声器输出的再生声音可能被麦克风拾取,并且多个人的发声可能同时被麦克风拾取。在这种情况下,麦克风所拾取的声音不同于希望声音被拾取的人的当前声音。在原样从扬声器输出这样的声音的情况下,可能难以听到该声音并进行流畅的会话。由于该原因,希望提高从扬声器输出的声音的质量(音质)。
作为用于解决该问题的技术,已知有如日本特开2009-216835(专利文献1)所述的声音去除设备。在该声音去除设备中,预先假定乘员配置模式作为车厢内的状况,并且针对各配置模式测量声音传输特性。然后,通过使用通过测量获得并存储在存储器等中的各个传输特性来估计并去除从扬声器输出的音频信号中的声音。根据该声音去除设备,只要乘员配置满足这些配置模式中的任意配置模式,就可以去除或抑制声音。
专利文献1:日本特开2009-216835
技术实现要素:
然而,在日本特开2009-216835所述的声音去除设备中,需要预先针对各可想到的乘员配置模式测量声音传输特性,并将该声音传输特性存储在存储器等中,作为车厢内的状况。根据车辆中的乘员配置模式的其它因素(例如,乘员的身高、体形、乘员落座在座椅上、以及乘员打开或关闭车窗或车门),声音传输特性大大改变。还假定会话中的说话者的数量不是恒定的。因此,利用日本特开2009-216835中的结构,不仅考虑到乘员的配置模式、而且考虑到车辆内的环境变化和同时说话的人数,实际上难以准备车辆内的所有状况中的声音传输特性。
此外,例如,在行驶期间乘员打开或关闭窗户、落座在座椅上、或者大幅移动面部的情况下,存在车辆内的声场中的声音传输特性大大改变的情况(换句话说,存在环境的突然变化的情况)。在这些情况中,车辆内的声场中的声音传输特性偏离了预先准备的声音传输特性。也就是说,利用预先准备传输特性的日本特开2009-216835的结构,难以跟随传输特性的变化,使得不能充分去除或抑制声音,并且从扬声器输出的声音的音质劣化。
本发明是有鉴于上述的现有技术中的情形而作出的,并且本发明的非限制方面是提供用于即使在存在突然的环境变化或说话者的同时发声的情况下、也抑制输出声音的音质劣化的声学噪声抑制设备和声学噪声抑制方法。
本发明的一方面提供一种声学噪声抑制设备,其被配置为抑制各个音频信号中所包括的声学噪声,在所述音频信号中,诸如车厢或会议室等的封闭空间中的多个人的发声是由所述封闭空间中与人相对应地布置的多个声音拾取单元拾取的,所述声学噪声抑制设备包括:第一抑制单元,其被配置为输出通过从所拾取的音频信号中减去第一伪噪声信号来抑制所述声学噪声的第一抑制音频信号,所述第一伪噪声信号是基于第一延迟信号、以及利用在多个说话者正在说话的情况下有效的第一算法更新的第一滤波器而生成的,其中所述第一延迟信号是通过使所述声学噪声的声源信号延迟基于所述声学噪声的声源和所述声音拾取单元之间的距离所计算出的时间而获得的;第二抑制单元,其被配置为输出通过从所拾取的音频信号中减去第二伪噪声信号来抑制所述声学噪声的第二抑制音频信号,所述第二伪噪声信号是基于第二延迟信号、以及利用在一个说话者正在说话的情况下有效的第二算法更新的第二滤波器而生成的,其中所述第二延迟信号是通过使所述声学噪声的声源信号延迟基于所述声学噪声的声源和所述声音拾取单元之间的距离所计算出的时间而获得的;以及输出信号选择单元,其被配置为输出所述第一抑制音频信号和所述第二抑制音频信号中的、判断为抑制了所述声学噪声的抑制音频信号。
本发明的另一方面提供一种声学噪声抑制方法,用于抑制各个音频信号中所包括的声学噪声,在所述音频信号中,诸如车厢或会议室等的封闭空间中的多个人的发声是由所述封闭空间中与人相对应地布置的多个声音拾取单元拾取的,所述声学噪声抑制方法包括:第一抑制步骤,用于输出通过从所拾取的音频信号中减去第一伪噪声信号来抑制所述声学噪声的第一抑制音频信号,所述第一伪噪声信号是基于第一延迟信号、以及利用在多个说话者正在说话的情况下有效的第一算法更新的第一滤波器而生成的,其中所述第一延迟信号是通过使所述声学噪声的声源信号延迟基于所述声学噪声的声源和所述声音拾取单元之间的距离所计算出的时间而获得的;第二抑制步骤,用于输出通过从所拾取的音频信号中减去第二伪噪声信号来抑制所述声学噪声的第二抑制音频信号,所述第二伪噪声信号是基于第二延迟信号、以及利用在一个说话者正在说话的情况下有效的第二算法更新的第二滤波器而生成的,其中所述第二延迟信号是通过使所述声学噪声的声源信号延迟基于所述声学噪声的声源和所述声音拾取单元之间的距离所计算出的时间而获得的;以及选择步骤,用于输出所述第一抑制音频信号和所述第二抑制音频信号中的、判断为抑制了所述声学噪声的抑制音频信号。
根据本发明,即使在存在突然的环境变化或者多个人同时说话等的情况下,也可以抑制输出声音的音质劣化。
附图说明
在附图中:
图1是示出根据第一实施例的会话支持系统3的概述的图;
图2是示出根据第一实施例的车厢内的直接波和间接波的传输路径的示例的图;
图3是示出根据第一实施例的声学噪声抑制设备的功能结构的框图;
图4是示出根据第一实施例的声学噪声抑制设备的操作的流程图;
图5a是示出首次启动时的自适应滤波器的成长过程的示例的曲线图;
图5b是示出首次启动时的自适应滤波器的成长过程的示例的曲线图;
图5c是示出首次启动时的自适应滤波器的成长过程的示例的曲线图;
图5d是示出首次启动时的自适应滤波器的成长过程的示例的曲线图;
图5e是示出首次启动时的自适应滤波器的成长过程的示例的曲线图;
图6a是示出环境改变时的自适应滤波器的变化过程的示例的曲线图;
图6b是示出环境改变时的自适应滤波器的变化过程的示例的曲线图;
图6c是示出环境改变时的自适应滤波器的变化过程的示例的曲线图;
图6d是示出环境改变时的自适应滤波器的变化过程的示例的曲线图;
图6e是示出环境改变时的自适应滤波器的变化过程的示例的曲线图;
图7是示出根据第二实施例的车厢内的直接波和间接波的传输路径的示例的图;
图8是示出根据第二实施例的声学噪声抑制设备的功能结构的框图;
图9是示出根据第二实施例的声学噪声抑制设备的操作的流程图;
图10是示出根据第三实施例的声学噪声抑制设备的功能结构的框图;
图11是示出根据第三实施例的声学噪声抑制设备的操作的流程图;
图12是示出根据第四实施例的车厢内的直接波和间接波的传输路径的示例的图;
图13是示出根据第四实施例的车厢内的直接波和间接波的传输路径的示例的图;
图14是示出根据第四实施例的声学噪声抑制设备的功能结构的框图;
图15是示出根据第四实施例的声学噪声抑制设备的操作的流程图;
图16是示出根据第五实施例的车厢内的直接波和间接波的传输路径的示例的图;
图17是示出根据第五实施例的声学噪声抑制设备的功能结构的框图;
图18是示出根据第五实施例的声学噪声抑制设备的操作的流程图;
图19是示出根据第六实施例的声学噪声抑制设备的功能结构的框图;以及
图20是示出根据第六实施例的声学噪声抑制设备的操作的流程图。
具体实施方式
以下将适当地参考附图来详细说明具体公开根据本发明的声学噪声抑制设备和声学噪声抑制方法的实施例。可以省略不必要的详细说明。例如,可以省略对众所周知的事项的详细说明或者对实质上相同的结构的重复说明。这是为了避免以下说明中的不必要冗余、并且便于本领域技术人员理解。应当注意,附图和以下的说明是为了本领域技术人员充分理解本发明而提供的,并且并不意图限制要求保护的主题。
将根据各实施例的声学噪声抑制设备应用于例如支持车厢内的乘员之间的会话的车载会话支持系统。然而,无需说明,以下的各个实施例的声学噪声抑制设备不限于应用于上述的车载会话支持系统。
(第一实施例)
[会话支持系统的概述]
图1是示出根据第一实施例的会话支持系统3的示例的图。第一实施例中的会话支持系统3安装在车辆8上,并且包括布置在驾驶座附近的麦克风mc1和扬声器sp1、布置在后排座椅附近的麦克风mc2和扬声器sp2、以及声学噪声抑制设备05(图1中未示出)。
麦克风mc1拾取驾驶员hm1所发出的声音。扬声器sp1向驾驶员hm1输出声音。麦克风mc2拾取乘员hm2所发出的声音。扬声器sp2向乘员hm2输出声音。麦克风mc1和麦克风mc2是声音拾取单元的示例,并且可以是定向麦克风或非定向麦克风。扬声器sp1和扬声器sp2是声音输出单元的示例,并且可以是定向扬声器或非定向扬声器。
声学噪声抑制设备05抑制在车辆8内产生的声学噪声。这里,声学噪声指除麦克风mc1所要拾取的声音以外的声音。在第一实施例中,假定另一扬声器所输出的声音作为声学噪声。后面将说明声学噪声抑制设备05的详情。
[声音的传输环境]
图2是示出第一实施例中的车厢8z中的声音传输路径的示例的图。驾驶员hm1所发出的声音由麦克风mc1拾取。这里,在还从扬声器sp2输出再生声音的情况下,从扬声器sp2输出的再生声音也与驾驶员hm1的声音同时被麦克风mc1拾取。在图2所示的示例中,从扬声器sp2输出的再生声音经由车厢8z内的传输路径pt1~pt4直接地或间接地由麦克风mc1拾取为声学噪声。
传输路径pt1是从扬声器sp2输出的声音直接到达麦克风mc1的直接波的传输路径。传输路径pt2是从扬声器sp2输出的声音被驾驶座侧的门反射并到达麦克风mc1的间接波的传输路径。传输路径pt3是从扬声器sp2输出的声音被车厢8z内的顶棚反射并到达麦克风mc1的间接波的传输路径。传输路径pt4是从扬声器sp2输出的声音被后排座椅侧的门和驾驶座的侧箱(sidebox)反射并到达麦克风mc1的间接波的传输路径。图2所示的传输路径是示例,并且从扬声器sp2输出的声音经由各种传输路径由麦克风mc1拾取。为了简单起见,假定扬声器sp2和麦克风mc1之间的传输路径为pt1~pt4,但无需说明,实际上存在各种传输路径。此外,这些传输路径(pt1~pt4和未示出的各种传输路径)的整合是第一实施例中的车厢8z内的传输特性。传输特性可能改变。例如,如图2中的驾驶员hm1a的情况那样,在驾驶员hm1大幅移动时,传输路径pt4消失或大大改变,并且车厢8z内的声场的传输特性改变。另外,车厢8z的传输特性可能由于诸如打开窗户等的各种因素而改变。
在第一实施例中,麦克风mc1所拾取的声音不仅包括驾驶员hm1所发出的声音,而且还包括经由传输路径pt1~pt4到达麦克风mc1的扬声器sp2的再生声音。在麦克风mc1所拾取的声音是直接从扬声器sp2输出的情况下,从扬声器sp2输出的再生声音包括声学噪声(扬声器sp2的再生声音)。声学噪声抑制设备05通过抑制在这种状况下产生的声学噪声来提高音质。
[声学噪声抑制设备的结构]
图3是示出根据第一实施例的声学噪声抑制设备05的功能结构的框图。
麦克风mc1和扬声器sp2连接至声学噪声抑制设备05,并且声学噪声抑制设备05主要包括数字信号处理器(dsp)10、存储器50和存储器51。麦克风mc1和扬声器sp2可以包括在声学噪声抑制设备05中。同样,麦克风mc2和扬声器sp1可以包括在声学噪声抑制设备05中。
声学噪声抑制设备05的处理的概述如下。声学噪声抑制设备05生成利用各自通过使用具有不同性质的算法而工作的两个处理系统来抑制声学噪声的信号,并且确定输出信号选择单元53最终要输出的声音。在各处理系统中,通过对过去从扬声器sp2输出的声音进行信号处理来生成再生声学噪声的伪噪声信号。第一实施例中麦克风mc1所拾取的声音中的声学噪声是从扬声器sp2输出并由麦克风mc1拾取的过去声音。因此,可以通过使用从扬声器sp2输出的过去声音来再生声学噪声。然后,通过从麦克风mc1所拾取的声音中去除伪噪声信号来生成声学噪声抑制之后的信号。
以下将参考图3来说明声学噪声抑制设备05的功能结构。
存储器50和存储器51存储过去从扬声器sp2输出的声音的信号。该信号用于各系统中的声学噪声的再生。由于声学噪声抑制设备05对声音进行信号处理,因此要处理声音的信号在下文也被称为音频信号。在下文,存储器50中所存储的参考信号被称为第一参考信号,并且存储器51中所存储的参考信号被称为第二参考信号。
dsp10是如下的处理器,该处理器对麦克风mc1所拾取的声音的音频信号进行利用上述的两个处理系统的声学噪声抑制,并且进行确定要输出的声学噪声抑制之后的音频信号的处理。如图3所示,dsp10在功能上包括分别对应于两个处理系统的第一抑制单元20和第二抑制单元30,并且包括用于确定要输出至扬声器sp2的信号的输出信号选择单元53。
第一抑制单元20包括加法器22、自适应滤波器23、第一滤波器更新单元25和延时器29。第一抑制单元20通过利用加法器22从麦克风mc1所拾取的声音的音频信号中减去自适应滤波器23所生成的伪噪声信号来抑制麦克风mc1所拾取的声音中的声学噪声。然后,将与声学噪声抑制之后的声音相对应的第一声学噪声抑制信号输出至输出信号选择单元53。如上所述,尽管加法器22所进行的处理确切地说是减法,但减去伪噪声信号的处理可以是加上反转的伪噪声信号的处理,并且可以通过减法和加法这两者来实现。因此,在本说明书中,该处理被描述为由加法器22进行。
接着,将基于第一抑制单元20的结构来详细说明利用第一抑制单元20抑制声学噪声的处理。
第一抑制单元20所要抑制的声学噪声是过去从扬声器sp2输出并到达麦克风mc1的声音。该声音经由图2所示的传输路径pt1~pt4到达麦克风mc1。也就是说,麦克风mc1所拾取的声学噪声是通过将从扬声器sp2输出的声音与该声音通过各传输路径所需的时滞混合而获得的声音。因此,目的是通过存储过去从扬声器sp2输出的声音并对该声音进行信号处理来生成再生混合后的声音的伪噪声信号。
自适应滤波器23是进行从第一参考信号生成伪噪声信号的处理的滤波器,并且具体使用专利文献1或日本特开2007-19595等中所述的有限脉冲响应(fir)滤波器。通过在自适应滤波器23中再生扬声器sp2和麦克风mc1之间的传输特性并对第一参考信号进行处理,可以生成伪噪声信号。然而,由于车厢8z内的传输特性不是恒定的,因此自适应滤波器23的特性根据需要而改变。因此,在第一实施例中,通过利用第一滤波器更新单元25控制fir滤波器的系数或抽头数,自适应滤波器23的特性以接近扬声器sp2和麦克风mc1之间的最新传输特性的方式改变。在下文,自适应滤波器的更新可被称为学习。
这里,从扬声器sp2作为再生声音输出并由麦克风mc1拾取的声音被延迟了在扬声器sp2和麦克风mc1之间传送所需的时间。另一方面,由于第一参考信号在紧挨从扬声器sp2被输出之前存储在存储器50中,因此未反映扬声器sp2和麦克风mc1之间的延迟。因此,在第一实施例中,该时间差被延时器29吸收,并且获得与麦克风mc1拾取声音的定时匹配的第一参考信号。也就是说,通过利用延时器29将第一参考信号延迟了通过将扬声器sp2和麦克风mc1之间的距离除以声速所获得的时间,来再生在由麦克风mc1实际拾取再生声音的定时的再生声音。可以通过实际测量扬声器sp2和麦克风mc1之间的距离并将该距离除以声速来获得延时器29的值。例如,在车厢内的驾驶座和后排座椅之间的距离为约4米的情况下,延时器29的值为约10msec。
接着,将详细说明第一滤波器更新单元25。第一滤波器更新单元25包括更新量计算单元26、非线性处理单元27和范数计算单元28。
非线性处理单元27对要从扬声器sp2输出的声学噪声的抑制之后的信号进行非线性转换。非线性转换是将声学噪声的抑制之后的信号转换成表示要更新滤波器的方向(正或负)的信息的处理。非线性处理单元27将非线性转换后的信号输出至更新量计算单元26。
范数计算单元28计算过去从扬声器sp2输出的音频信号的范数。扬声器信号的范数是过去的预定时间内的扬声器信号的大小的总和,并且是表示该时间内的信号的大小程度的值。该范数由更新量计算单元26使用以对过去从扬声器sp2输出的声音的音量的影响进行标准化。通常,由于随着音量变大、滤波器的更新量也被计算得更大,因此除非进行标准化,否则自适应滤波器23的特性受到大声音的特性过度影响。因此,在第一实施例中,通过使用范数计算单元28所计算出的范数对从延时器29输出的音频信号进行标准化来使自适应滤波器23的更新量稳定。
更新量计算单元26根据从非线性处理单元27、范数计算单元28和延时器29接收到的信号来计算自适应滤波器23的滤波器特性的更新量(具体为fir滤波器的系数或抽头数的更新量)。具体地,基于范数计算单元28所计算出的范数来对从延时器29接收到的过去从扬声器sp2输出的声音进行标准化。然后,通过将基于从非线性处理单元27获得的信息的正或负的信息添加至对过去从扬声器sp2输出的声音进行标准化的结果来确定更新量。在第一实施例中,更新量计算单元26通过独立分量分析(ica)算法来计算滤波器特性的更新量。
通过根据需要执行更新量计算单元26、非线性处理单元27和范数计算单元28的处理,第一滤波器更新单元25可以使自适应滤波器23的特性接近扬声器sp2和麦克风mc1之间的传输特性。
接着,将详细说明第二抑制单元30。第二抑制单元30包括加法器32、自适应滤波器33、第二滤波器更新单元35和延时器39。第二滤波器更新单元35包括更新量计算单元36、非线性处理单元37和范数计算单元38。由于利用第二抑制单元30抑制声学噪声的原理与利用第一抑制单元抑制声学噪声的原理相同,因此以下将仅说明各组件的操作。
第二抑制单元30通过利用加法器32向(从)麦克风mc1所拾取的声音加上(减去)自适应滤波器33所生成的伪噪声信号,来抑制麦克风mc1所拾取的声音中的声学噪声。
在下文,将基于第二抑制单元30的结构来更详细地说明利用第二抑制单元30抑制声学噪声的处理。
自适应滤波器33是进行从第二参考信号生成伪噪声信号的处理的滤波器,并且具体使用fir滤波器。在第二抑制单元30中,通过利用第二滤波器更新单元35控制fir滤波器的系数或抽头数,自适应滤波器33的特性以接近扬声器sp2和麦克风mc1之间的最新传输特性的方式改变。
接着,将详细说明第二滤波器更新单元35。第二滤波器更新单元35包括更新量计算单元36、非线性处理单元37和范数计算单元38。
非线性处理单元37对要从扬声器sp2输出的声学噪声抑制之后的信号进行非线性转换。非线性处理单元37将表示通过非线性转换所获得的滤波器特性将要改变的方向的信号输出至更新量计算单元36。
范数计算单元38计算过去从扬声器sp2输出的声音的范数。
更新量计算单元36根据从非线性处理单元37、范数计算单元38和延时器39接收到的信号来计算自适应滤波器33的滤波器特性的更新量(具体为fir滤波器的系数或抽头数的更新量)。具体地,基于范数计算单元38所计算出的范数来对从延时器39接收到的过去从扬声器sp2输出的声音的音频信号进行标准化。然后,通过将基于从非线性处理单元27获得的信息的正或负的信息添加至对过去从扬声器sp2输出的声音的音频信号进行标准化的结果来确定更新量。这里,不同于更新量计算单元26,更新量计算单元36通过标准化最小均方(nlms)算法来计算滤波器特性的更新量。
输出信号选择单元53在从包括第一抑制单元20的处理系统输出的音频信号和从包括第二抑制单元的处理系统输出的音频信号中选择与要从扬声器sp2输出的声音相对应的音频信号。例如,输出信号选择单元53将声压较小的音频信号输出至扬声器sp2。这是因为,认为在声学噪声被适当抑制的情况下、声压适当降低。此外,代替基于声压的判断,可以从统计上判断是否抑制了声学噪声。可以通过从统计上进行选择来提高判断的精度。
如上所述,用于更新自适应滤波器23和自适应滤波器33的算法在第一抑制单元20和第二抑制单元30之间是不同的。第一抑制单元20所使用的ica是在车厢8z内多个人正在说话时有效的算法。第二抑制单元30所使用的nlms是在一个人正在说话时有效的算法。因此,可以通过输出通过使用具有不同性质的算法抑制了声学噪声的音频信号中的、声学噪声被进一步抑制的音频信号,来根据环境的变化输出适当的声音。
[声学噪声抑制操作]
图4是详细示出根据第一实施例的声学噪声抑制设备05的声学噪声抑制操作的过程的流程图。在通过例如接通车辆8中所安装的点火钥匙开关来向声学噪声抑制设备供给电力的情况下,利用dsp10重复地执行图4所示的各处理。
dsp10获取麦克风mc1所拾取的声音的音频信号(s1)。
dsp10指示第一抑制单元20和第二抑制单元30各自在时间上并行地执行处理。因此,第一抑制单元20和第二抑制单元30在时间上并行地处理步骤s13~s15和步骤s23~s25(s2)。
第一抑制单元20从存储器50获取第一参考信号(s13)。
第一抑制单元20使用由延时器29延迟了与扬声器sp2和麦克风mc1之间的距离相对应的预定时间的第一参考信号,来利用自适应滤波器23生成伪噪声信号。然后,利用加法器22向麦克风mc1所拾取的声音的音频信号加上伪噪声信号或从麦克风mc1所拾取的声音的音频信号减去伪噪声信号。因此,第一抑制单元20通过从麦克风mc1所拾取的声音的音频信号中减去伪噪声信号来生成声学噪声抑制之后的信号。由于将所生成的声学噪声抑制之后的信号用于滤波器系数的下一更新处理,因此不论该信号是否最终从扬声器sp2输出,该信号都被输出至第一滤波器更新单元25(s14)。
第一滤波器更新单元25根据上述过程计算滤波器特性的更新量并更新自适应滤波器23的特性。这里,第一滤波器更新单元25通过ica计算滤波器特性的更新量(s15)。
另一方面,第二抑制单元30获取存储器51中所存储的第二参考信号(s23)。
第二抑制单元30使用由延时器39延迟了与扬声器sp2和麦克风mc1之间的距离相对应的预定时间的第二参考信号,利用自适应滤波器33生成伪噪声信号。然后,利用加法器32向麦克风mc1所拾取的音频信号加上伪噪声信号或从麦克风mc1所拾取的音频信号减去伪噪声信号。因此,第二抑制单元30通过从麦克风mc1所拾取的音频信号中减去伪噪声信号来生成声学噪声抑制之后的信号。由于将所生成的声学噪声抑制之后的信号用于滤波器系数的下一更新处理,因此不论该信号是否最终从扬声器sp2输出,该信号都被输出至第二滤波器更新单元35(s24)。
第二滤波器更新单元35根据上述过程来计算滤波器特性的更新量并更新自适应滤波器33的特性。这里,第二滤波器更新单元35通过nlms来计算滤波器特性的更新量(s25)。
输出信号选择单元53在从第一抑制单元20输出的声学噪声抑制之后的音频信号和从第二抑制单元30输出的声学噪声抑制之后的音频信号中选择要输出的音频信号。例如,输出信号选择单元53比较各个音频信号的声压,并选择声压较小的音频信号作为要输出至扬声器sp2的音频信号(s3)。
此外,将作为要输出至扬声器的信号所选择的信号分别作为第一参考信号和第二参考信号存储在存储器50和存储器51中(s4)。
如上所述,dsp10重复执行这一系列处理。
[自适应滤波器的更新示例]
图5a~5e是示出首次启动时的自适应滤波器23的成长过程的示例的曲线图。
各曲线图的纵轴表示声压并且横轴表示频率。在首次启动时的初始状态下,如图5a所示,自适应滤波器23针对麦克风mc1所拾取的声学噪声信号gh1不生成伪噪声信号gh2。
之后,如图5b~5d所示,自适应滤波器23随着时间的经过而成长(换句话说,自适应滤波器23的滤波器系数进行学习),并且自适应滤波器23所生成的伪噪声信号gh2接近麦克风mc1所拾取的声学噪声信号gh1。在稳定状态下,如图5e所示,自适应滤波器23所生成的伪噪声信号gh2与麦克风mc1所拾取的声学噪声信号gh1大致一致。
尽管图5a~5e示出了自适应滤波器23的成长过程的示例,但与自适应滤波器23类似,自适应滤波器33所生成的伪噪声信号也成长以与声学噪声信号gh1大致一致,但是自适应滤波器23和自适应滤波器33在变化速率和与最终声学噪声信号gh1的一致程度上有所不同。
图6a~6e是示出环境改变时的自适应滤波器23的变化过程的示例的曲线图。
在车厢8z内的状况改变(例如,车窗的打开和关闭)并且声场突然改变的情况下、即在声场突然改变的情况下,自适应滤波器23所生成的伪噪声信号gh2大大偏离麦克风mc1所拾取的声学噪声信号gh1。在图6a中,存在伪噪声信号gh2的声压超过声学噪声信号gh1的声压的许多频带。
之后,如图6b~6d所示,自适应滤波器23随着时间的经过而成长(换句话说,学习自适应滤波器23的滤波器系数或抽头数),并且自适应滤波器23所生成的伪噪声信号gh2接近麦克风mc1所拾取的声学噪声信号gh1。在从环境变化开始起经过了一定时间段之后的稳定状态下,如图6e所示,自适应滤波器23所生成的伪噪声信号gh2与麦克风mc1所拾取的声学噪声信号gh1大致一致。
尽管图6a~6e示出自适应滤波器23的成长过程的示例,但与自适应滤波器23类似,自适应滤波器33所生成的伪噪声信号也成长以与声学噪声信号gh1大致一致,但是自适应滤波器23和自适应滤波器33在变化速率和与最终声学噪声信号gh1的一致程度上有所不同。
[第一实施例的概要]
如上所述,在第一实施例的声学噪声抑制设备中,麦克风mc1拾取车厢8z内的驾驶员hm1(人物)的声音。加法器22基于麦克风mc1所拾取的驾驶员hm1的音频信号和存储器50中所存储的扬声器信号(第一参考信号)来输出音频信号中所包括的声学噪声被抑制的第一抑制后的音频信号。加法器32基于麦克风mc1所拾取的驾驶员hm1的音频信号和存储器51中所存储的扬声器信号(第二参考信号)来输出音频信号中所包括的声学噪声被抑制的第二抑制后的音频信号。输出信号选择单元53比较第一抑制后的音频信号和第二抑制后的音频信号的声压,选择声压较小的音频信号,并将所选择的音频信号从扬声器sp2输出。
这里,声学噪声抑制设备05被配置为将不同的算法用于第一滤波器更新单元25和第二滤波器更新单元35。因此,自适应滤波器23和自适应滤波器33可以是具有不同特性的滤波器。因此,即使环境不适合于利用自适应滤波器其中之一抑制声学噪声,也可以利用另一自适应滤波器抑制声学噪声,使得可以抑制音质的劣化。
第一实施例说明了车载会话支持系统3抑制由针对驾驶员hm1的麦克风mc1拾取的声音中所包括的、由扬声器sp2产生的声学噪声的结构。然而,上述实施例所述的结构也可应用于抑制由针对乘员hm2的麦克风mc2拾取的声音中包括的、由扬声器sp2产生的声学噪声的结构。
在第一实施例中,假定车载会话支持系统3支持驾驶员hm1和坐在后排座椅的乘员hm2之间的会话。然而,会话中的乘员的组合是任意的。例如,在前后方向上具有三排座椅的车辆中,将相同的结构应用于坐在乘员座的乘员和坐在中央座的乘员之间的会话。
也就是说,根据第一实施例的声学噪声抑制设备05可被配置为抑制由从环境中安装的任何扬声器输出的再生声音所产生的声音,以提高音质。声学噪声抑制设备05具有与麦克风和扬声器的组合的数量相对应的声学噪声抑制功能。由于仅在上述实施例的结构中所要使用的扬声器和麦克风的组合改变,因此将省略对各组合中的结构和处理过程的说明。
(第二实施例)
在第一实施例中,示出了将从扬声器输出的声音作为声学噪声来抑制的示例。另一方面,在第二实施例中,示出如下的示例:将除被假定为麦克风的声音拾取对象的人物以外的人物所发出的声音(例如,第一实施例中的乘员hm2所发出的声音)作为声学噪声来抑制。
[声音的传输环境]
将参考图7来说明第二实施例中所假定的声音的传输环境。为了简化描述,与第一实施例相同,仅示出传输路径的一部分作为示例。
驾驶员hm1所发出的声音由麦克风mc1拾取。与麦克风mc1所拾取的声音同时,后排座椅的乘员hm2所发出的声音经由车厢8z内的传输路径pt5~pt7直接地或间接地由麦克风mc1拾取为声学噪声。
传输路径pt5是乘员hm2所发出的声音直接到达麦克风mc1的直接波的传输路径。传输路径pt6是乘员hm2所发出的声音被驾驶座侧的门反射并到达麦克风mc1的间接波的传输路径。传输路径pt7是乘员hm2所发出的声音被后排座椅侧的门和驾驶座侧的侧箱反射并到达麦克风mc1的间接波的传输路径。图7所示的传输路径是示例,并且乘员hm2所发出的声音经由各种传输路径由麦克风mc1拾取。为了简单起见,将假定乘员hm2和麦克风mc1之间的传输路径为pt5~pt7来进行以下说明,但无需说明,实际上存在各种传输路径。此外,这些传输路径(pt5~pt7和未示出的各种传输路径)的整合是第二实施例中的车厢8z内的传输特性。传输特性可以以与第一实施例相同的方式改变。
在第二实施例中,麦克风mc1所拾取的声音不仅包括驾驶员hm1所发出的声音,而且还包括经由传输路径pt5~pt7到达麦克风mc1的乘员hm2的声音。在麦克风mc1所拾取的声音直接从扬声器sp2输出的情况下,从扬声器sp2输出的再生声音包括声学噪声(乘员hm2的再生声音)。声学噪声抑制设备05a通过抑制在这种状况下产生的声学噪声来提高音质。
[声学噪声抑制设备的结构]
图8是示出根据第二实施例的声学噪声抑制设备05a的功能结构的框图。与第一实施例中的组件相同的组件由与图3中相同的附图标记表示,并且将省略对这些组件的说明。
由于声学噪声抑制设备05a的基本结构和声学噪声抑制的原理与第一实施例中的声学噪声抑制设备05的结构和声学噪声抑制的原理相同,因此以下将主要说明与声学噪声抑制设备05的不同之处。
尽管第一实施例基于从扬声器sp2输出的声音来再生声学噪声,但在第二实施例中,基于乘员hm2所发出的声音来再生声学噪声。
尽管在第一实施例中将从扬声器sp2输出的声音的音频信号存储在存储器50和存储器51中,但由于在第二实施例中从扬声器sp2输出的声音的音频信号未被作为声学噪声来处理,因此不进行该处理。替代地,在第二实施例中,存储器50a和存储器51a将乘员hm2所发出的声音的音频信号分别存储为第一参考信号和第二参考信号。这里,麦克风mc2用于获取乘员hm2所发出的声音的音频信号。
此外,在将从扬声器sp2输出的声音作为声学噪声来处理的第一实施例中,作为延时器29和延时器39,生成通过将扬声器sp2和麦克风mc1之间的距离除以声速所获得的延迟。另一方面,在将乘员hm2所发出的声音作为声学噪声来处理的第二实施例中,作为延时器29a和延时器39a,使用通过将乘员hm2和麦克风mc1之间的距离除以声速所获得的延迟。这里,乘员hm2和麦克风mc1之间的距离是通过例如实际测量假定乘员hm2坐着的座椅和麦克风mc1之间的距离来获得的。
严格来说,尽管在乘员hm2和麦克风mc2之间的距离也包括在测量值中的情况下、可以更准确地计算距离和延迟,但在第二实施例中,由于假定麦克风mc2在乘员hm2的眼睛前面,因此省略了该距离计算。
由于其它结构与第一实施例的结构相同,因此将省略对这些结构的说明。
[声学噪声抑制操作]
图9是示出根据第二实施例的声学噪声抑制设备05a的操作的流程图。与第一实施例中的处理相同的处理由与图4中相同的附图标记表示,并且将省略对该处理的说明。
除了用于生成伪噪声的信号是麦克风mc2所拾取的乘员hm2的声音以外,根据第二实施例的声学噪声抑制操作与第一实施例的声学噪声抑制操作相同。因此,除了与从存储器50a和存储器51a获取到的或者存储器50a和存储器51a中所存储的乘员hm2的声音有关的处理以外,该处理与第一实施例相同。以下将仅说明与第一实施例的不同之处。
在第二实施例中,获取存储器50a和存储器51a中所存储的由麦克风mc2拾取的音频信号作为第一参考信号和第二参考信号(s13a、s23a)。
此外,将由麦克风mc2拾取的音频信号分别作为第一参考信号和第二参考信号存储在存储器50a和存储器51a中(s4a)。
根据第一实施例的处理,在输出信号的选择之后更新存储器50a和存储器51a中所存储的乘员hm2的声音。然而,由于乘员hm2的声音独立于从扬声器sp2输出的声音,因此可以在其它定时更新乘员hm2的声音。
[第二实施例的概要]
如上所述,在第二实施例的声学噪声抑制设备05a中,麦克风mc1拾取车厢8z内的驾驶员hm1(人物)的声音。加法器22基于由麦克风mc1拾取的驾驶员hm1的音频信号和存储器50a中所存储的由麦克风mc2拾取的乘员hm2的声音(第一参考信号),来输出音频信号中所包括的音频噪声被抑制的第一抑制后的音频信号(第一抑制音频信号)。加法器32基于由麦克风mc1拾取的驾驶员hm1的音频信号和存储器51a中所存储的由麦克风mc2拾取的乘员hm2的声音(第二参考信号),来输出音频信号中所包括的音频噪声被抑制的第二抑制后的音频信号(第二抑制音频信号)。输出信号选择单元53比较第一抑制后的音频信号和第二抑制后的音频信号的声压,并且选择声压较小的音频信号并将所选择的音频信号从扬声器sp2输出。
这里,由于声学噪声抑制设备05a将不同的算法用于第一滤波器更新单元25和第二滤波器更新单元35,因此自适应滤波器23和自适应滤波器33可以是具有不同特性的滤波器。因此,即使环境不适合于利用自适应滤波器其中之一来抑制声学噪声,也可以利用另一自适应滤波器来抑制声学噪声,使得可以抑制音质的劣化。
第二实施例说明了车载会话支持系统3抑制由针对驾驶员hm1的麦克风mc1拾取的声音中所包括的、由乘员hm2的发声产生的声学噪声的结构。然而,上述实施例所述的结构也可应用于由针对乘员hm2的麦克风mc2拾取的声音中包括的、由驾驶员hm1的发声产生的声学噪声的结构。
在第二实施例中,假定车载会话支持系统3支持驾驶员hm1和坐在后排座椅的乘员hm2之间的会话。然而,会话中的乘员的组合是任意的。例如,在前后方向上存在三排座椅的车辆中,将相同的结构应用于坐在乘员座的乘员和坐在中央座椅上的乘员之间的会话。
也就是说,第二实施例的声学噪声抑制设备05a可被配置为抑制由环境中存在的任何乘员(包括驾驶员)发出的声音所产生的声学噪声以提高音质。在这种情况下,声学噪声抑制设备05a具有与麦克风和乘员的组合的数量相对应的声学噪声抑制功能。由于仅在上述实施例的结构中所要使用的对象乘员和麦克风的组合改变,因此将省略各组合中的结构和处理过程的说明。
(第三实施例)
在第三实施例中,示出基于识别同时说话的说话者人数的信息来判断是否应更新自适应滤波器的示例。除了使用说话者人数信息来更新自适应滤波器以外,由于其它结构与其它实施例的结构相同,因此省略了说明。
[声学噪声抑制的结构]
图10是示出根据第三实施例的声学噪声抑制设备05b的结构的图。以下将仅说明与第二实施例的不同之处。
信息获取单元70b获取说话者人数信息。这里,说话者人数信息是用于识别同时说话的说话者的人数的信息。该信息是基于麦克风所拾取的声音或照相机等的摄像结果而估计和生成的。具体地,可以通过对多个麦克风中的音量超过预定阈值的麦克风的数量进行计数来估计说话者的人数。在使用照相机的情况下,可以通过对与嘴相对应的部位正在动的乘员的人数进行计数来估计说话者的人数。
第一滤波器更新单元25b和第二滤波器更新单元35b根据说话者的人数来切换是否更新各个自适应滤波器。由于用于更新自适应滤波器的过程与第二实施例中的过程相同,因此将省略对该过程的说明。
[声学噪声抑制操作]
图11是示出根据第三实施例的声学噪声抑制设备05b的操作的流程图。与第二实施例中的处理相同的处理由与图9中相同的附图标记表示,并且将省略对该处理的说明。
信息获取单元70b获取说话者人数信息(s1b)。
第一滤波器更新单元25b和第二滤波器更新单元35b基于步骤s1b中所获取到的说话者人数信息来判断麦克风mc2所获取到的音频信号是否是适合于更新各自适应滤波器的音频信号(s16b、s26b)。更具体地,在说话者人数信息表示一个人或多个人的情况下,第一滤波器更新单元25b判断为音频信号适合于更新自适应滤波器23。此外,在说话者人数信息表示仅一个人的情况下,第二滤波器更新单元35b判断为音频信号适合于更新自适应滤波器33。这是因为,第一滤波器更新单元25b所使用的ica可以在一个人或多个人正在说话的状态下学习,而第二滤波器更新单元35b所使用的nlms可以在仅一个人正在说话的状态下以特别高的精度进行更新。
在第一滤波器更新单元25b和第二滤波器更新单元35b分别判断为麦克风mc2所获取到的音频信号适合于更新自身所管理的自适应滤波器的情况下,更新自适应滤波器(s17b、s27b)。在判断为音频信号不适合于更新的情况下,在不更新自适应滤波器的情况下将声学噪声抑制之后的音频信号输出至输出信号选择单元。
[第三实施例的概要]
如上所述,第三实施例的声学噪声抑制设备05b判断所获取到的参考信号是否是适合于更新自适应滤波器的音频信号,并且仅在判断为音频信号适合的情况下才更新自适应滤波器。结果,特别是对于nlms,尽管与ica相比、更新自适应滤波器的机会减少,但可以进行更准确的更新。
此外,即使环境不适合于利用自适应滤波器其中之一抑制声学噪声,也可以利用另一自适应滤波器抑制声学噪声,使得可以抑制音质的劣化。
在上述说明中,以第二实施例为基准以说明不同之处的形式说明了第三实施例。然而,第三实施例所述的基于说话者人数信息来切换是否更新各自适应滤波器的构思可以应用于第一实施例。也就是说,不论要抑制的声学噪声是从扬声器输出的过去声音还是另一乘员所发出的声音,都可以应用上述构思。
(第四实施例)
在第四实施例中,示出在正在说话的说话者改变的情况下、可以以高精度抑制声学噪声的示例。
[声音的传输环境]
在第四实施例中,假定在图12和图13之间正在说话的人改变的情况。也就是说,假定图12所示的乘员hm2正在说话的环境和图13所示的乘员hm3正在说话的环境的状况被切换。
在图12和图13中,麦克风mc3安装于坐在乘员座的乘员hm3的眼睛的前方,并且拾取乘员hm3所发出的声音。
图12示出乘员hm2所发出的声音由麦克风mc1拾取的示例。麦克风mc1在拾取驾驶员hm1所发出的声音的同时,还拾取由乘员hm2发出并且经由车厢8z内的传输路径pt5、pt6和pt7直接地或间接地到达麦克风mc1的声音。各传输路径的详情与第二实施例中的详情相同,并且将省略对各传输路径的说明。
图13示出乘员hm3所发出的声音由麦克风mc1拾取的示例。麦克风mc1在拾取驾驶员hm1所发出的声音的同时,还拾取由坐在乘员座的乘员hm3发出并且经由车厢8z内的传输路径pt8和pt9直接地或间接地到达麦克风mc1的声音。传输路径pt8是乘员hm3所发出的声音直接到达麦克风mc1的直接波的传输路径。传输路径pt9是乘员hm3所发出的声音被乘员座侧的门反射并且到达麦克风mc1的间接波的传输路径。
图12所示的传输路径是示例,并且乘员hm2或乘员hm3所发出的声音经由各种传输路径由麦克风mc1拾取。为了简单起见,将假定乘员hm2和麦克风mc1之间的传输路径为pt5~pt7并且乘员hm3和麦克风mc1之间的传输路径为pt8和pt9来进行以下说明,但无需说明,实际上存在各种传输路径。车厢8z内的传输特性针对各乘员而变化。例如,对于乘员hm2,pt5~pt7以及(未示出的)传输路径的组合是车厢8z内的传输特性;并且对于乘员hm3,pt8和pt9以及(未示出的)传输路径的组合是车厢8z内的传输特性。可以以与其它实施例相同的方式改变传输特性。
在第四实施例中,麦克风mc1所拾取的声音不仅包括驾驶员hm1所发出的声音,而且还包括经由传输路径pt5~pt7到达麦克风mc1的乘员hm2的声音、或者经由传输路径pt8和pt9到达麦克风mc1的乘员hm3的声音。在将麦克风mc1所拾取的声音原样从扬声器sp2输出的情况下,乘员hm2所发出的声音或乘员hm3所发出的声音被作为声学噪声包括在从扬声器sp2输出的再生声音中。声学噪声抑制设备05c通过抑制这样的声学噪声来提高音质。
以下将说明声学噪声抑制设备05c所进行的处理的概述。在图12和图13各自中,用于声学噪声抑制的自适应滤波器在各传输环境中学习。因此,在如图12和图13所示切换说话者的情况下,如果在一个环境中学习的自适应滤波器用作另一环境中的学习的基础,则在声学噪声被抑制之前,可能需要时间。因此,声学噪声抑制设备05c存储在各种环境中学习的自适应滤波器的滤波器系数,并且每当说话者改变时再生存储的自适应滤波器的滤波器系数,并进行声学噪声抑制和自适应滤波器学习。
[声学噪声抑制设备的结构]
图14是示出根据第四实施例的声学噪声抑制设备05c的结构的图。以下将仅说明与第二实施例的不同之处。
信息获取单元70c获取说话者识别信息。这里,说话者识别信息是用于识别正在说话的说话者的信息。该信息是基于麦克风所拾取的声音或照相机等的摄像结果而估计并生成的。具体地,在存在音量超过预定阈值的麦克风的情况下,可以估计出麦克风所假定的说话者正在讲话。此外,通过使用照相机,可以通过识别与嘴相对应的部位正在动的乘员的位置来识别说话者。
第一滤波器更新单元25c和第二滤波器更新单元35c根据由说话者识别信息表示的说话者来切换自适应滤波器的滤波器系数。具体地,自适应滤波器的滤波器系数是与说话者识别信息相关联地存储在存储器50c和存储器51c中的,并且根据当前说话者识别信息而被读出。然后,在将所读取的系数恢复到自适应滤波器23和自适应滤波器33之后,利用各自适应滤波器进行学习。每当自适应滤波器的学习进行时,更新各存储器中所存储的滤波器系数。
延时器29c和延时器39c将延迟时间切换到与说话者识别信息相对应的延迟时间。也就是说,在由说话者识别信息表示的说话者为hm2的情况下,使用与hm2和麦克风mc1之间的距离相对应的延迟时间,并且在由说话者识别信息表示的说话者为hm3的情况下,使用与hm3和麦克风mc1之间的距离相对应的延迟时间。因而,使参考信号延迟了与各说话者相对应的时间。
由于自适应滤波器自身的学习的操作和其它组件的操作与其它实施例的这些操作相同,因此省略了对这些操作的说明。
[声学噪声抑制操作]
图15是示出根据第四实施例的声学噪声抑制设备05c的操作的流程图。与第二实施例中的处理相同的处理由与图9中相同的附图标记表示,并且将省略对该处理的说明。
信息获取单元70c获取说话者识别信息(s1c)。
第一滤波器更新单元25c和第二滤波器更新单元35c分别从存储器50c和51c获取第一参考信号和第二参考信号。此时,延时器29c和延时器39c中的延迟时间被切换到与由说话者识别信息表示的说话者相对应的延迟时间。从存储器50c和存储器51c分别获取自适应滤波器23和自适应滤波器33的过去滤波器系数中的、与所获取到的说话者识别信息相对应的滤波器系数。然后,第一滤波器更新单元25c和第二滤波器更新单元35c将所获取到的滤波器系数反映在自适应滤波器23和自适应滤波器33中(s13c、s23c)。
在更新各自适应滤波器并选择输出信号之后,dsp10将第一参考信号和第二参考信号分别存储在存储器50c和51c中。dsp10将自适应滤波器23和自适应滤波器33的最新滤波器系数与当前说话者识别信息相关联地存储在存储器50c和存储器51c中(s4c)。
因此,在存储器50c和51c中分别始终存储有与说话者识别信息相对应的最新滤波器系数。因此,通过根据所获取到的说话者识别信息读取并恢复滤波器系数,即使在说话者改变的情况下,也可以利用具有与各说话者相对应的系数的自适应滤波器来抑制声学噪声。
[第四实施例的概要]
如上所述,根据第四实施例的声学噪声抑制设备基于说话者识别信息来切换作为滤波器系数和参考信号所要参考的麦克风。针对各说话者存储滤波器系数,并且使用拾取说话者的声音的麦克风的音频信号来进行声学噪声抑制和自适应滤波器的更新。因此,可以针对各说话者恰当地使用滤波器系数,并且滤波器可以使用与各说话者相对应的音频信号来学习。
此外,尽管在上述示例中说明了每次均将自适应滤波器的滤波器系数存储在存储器中的结构,但可以每数次或者在检测到说话者改变时,进行一次滤波器系数的存储。因此,由于可以减少将自适应滤波器的滤波器系数存储在存储器中的次数,因此可以减轻处理负荷。
尽管在上述示例中说明了针对各说话者存储并恰当地使用自适应滤波器的滤波器系数的结构,但可以针对各说话者存储并恰当地使用自适应滤波器的抽头数等。也就是说,参数的类型并不重要,只要可以针对各说话者恰当地使用自适应滤波器的参数即可。
(第五实施例)
在第五实施例中,示出通过使用三个麦克风来抑制由除被假定为麦克风的声音拾取对象的人以外的人发出的声音的示例。
[声音的传输环境]
将参考图16来说明第五实施例中所假定的声音的传输环境。除了添加了麦克风mc4以外,与第二实施例中的组件相同的组件由与图7中相同的附图标记表示,并且将省略对这些组件的说明。
在第五实施例中,麦克风mc4安装在车辆中的某处。作为示例,假定麦克风mc4安装在右侧的后排座椅的前方。结果,乘员hm2所发出的声音也记录在麦克风mc4中。
[声学噪声抑制设备的结构]
图17是示出根据第五实施例的声学噪声抑制设备05d的功能结构的框图。与第二实施例中的组件相同的组件由与图8中相同的附图标记表示,并且将省略对这些组件的说明。
由于声学噪声抑制设备05d的基本结构和声学噪声抑制的原理与第二实施例中的声学噪声抑制设备05a的基本结构和声学噪声抑制的原理相同,因此将主要说明与声学噪声抑制设备05a的不同之处。
在第五实施例中,分别将麦克风mc2所获取到的乘员hm2的音频信号作为第一参考信号存储在存储器50d中,并且将麦克风mc4所获取到的乘员hm4的音频信号作为第二参考信号存储在存储器51d中。也就是说,声学噪声抑制设备05d基于麦克风mc2和麦克风mc4所拾取的乘员hm2的声音来抑制声学噪声。
延时器29d使第一参考信号延迟。具体地,延时器29d使第一参考信号延迟了与乘员hm2和麦克风mc1之间的距离相对应的延迟时间x。延迟时间x与第二实施例中的延时器29a的延迟时间类似,并且将省略对延迟时间x的说明。
延时器39d使第二参考信号延迟。延迟时间是基于麦克风mc1和乘员hm2之间的距离以及麦克风mc4和乘员hm2之间的距离的时间。具体地,利用延时器39d延迟了通过从上述的延迟时间x中减去乘员hm2和麦克风mc4之间的延迟时间y所获得的时间。以下将说明使用这样的延迟时间的原因。由于麦克风mc4是原本不打算用来拾取乘员hm2的声音的麦克风,因此不能忽略麦克风mc4和乘员hm2之间的距离中的延迟。因此,在延时器39d使用延迟时间x的情况下,延迟了延迟时间y的额外时间。为了匹配用于抑制声学噪声的参考信号的定时,在第五实施例中,将麦克风mc4所拾取的声音延迟了通过从延迟时间x中减去延迟时间y所获得的时间。
更新量计算单元26d基于从延时器29d接收到的由麦克风mc2拾取的乘员hm2的延迟后的声音,来计算自适应滤波器23的更新量。更新量的计算的详情与其它实施例中的这些详情相同,并且将省略对这些详情的说明。
更新量计算单元36d基于从延时器39d接收到的由麦克风mc4拾取的乘员hm2的声音,来计算自适应滤波器33的更新量。更新量的计算的详情与其它实施例中的这些详情相同,并且将省略对这些详情的说明。
由于其它结构与第二实施例的这些结构相同,因此将省略对这些结构的说明。
[声学噪声抑制操作]
图18是示出根据第五实施例的声学噪声抑制设备05d的操作的流程图。与第二实施例中的处理相同的处理由与图9中相同的附图标记表示,并且将省略对该处理的说明。
第一滤波器更新单元25获取由延迟器29d延迟的、存储器50d中所存储的由麦克风mc2拾取的声音作为第一参考信号(s13d)。
第二滤波器更新单元35获取由延迟器39d延迟的、存储器51d中所存储的由麦克风mc4拾取的声音作为第二参考信号(s23d)。
第一滤波器更新单元25基于第一参考信号来计算滤波器特性的更新量(s15d)。
第二滤波器更新单元35基于第二参考信号来计算滤波器特性的更新量(s25d)。
将麦克风mc2所拾取的音频信号作为第一参考信号存储在存储器50d中,并且将麦克风mc4所拾取的音频信号作为第二参考信号存储在存储器51d中(s4d)。
在上述说明中,在输出信号的选择之后更新存储器50d和存储器51d中所存储的乘员hm2的声音。然而,由于乘员hm2的声音独立于从扬声器sp2输出的声音,因此可以在另一定时更新乘员hm2的声音。
[第五实施例的概要]
如上所述,在第五实施例的声学噪声抑制设备05d中,可以输出基于麦克风mc2所拾取的声音来抑制声学噪声的结果和基于麦克风mc4所拾取的声音来抑制声学噪声的结果中的适当声音。在麦克风mc2不能始终最佳地拾取乘员hm2的声音的情况下,例如在麦克风mc2和乘员hm2之间有可能存在障碍物的情况下,该结构是有效的。
也就是说,第五实施例的声学噪声抑制设备05d可被配置为抑制由环境中存在的任何乘员(包括驾驶者)发出的声音而产生的声学噪声,以提高音质。在这种情况下,声学噪声抑制设备05d具有与麦克风和乘员的组合的数量相对应的声学噪声抑制功能。由于仅在上述实施例的结构中要使用的对象乘员和麦克风的组合改变,因此将省略对各组合中的结构和处理过程的说明。
在第五实施例的声学噪声抑制设备05d中,用于更新自适应滤波器的算法可以相同或不同。
(第六实施例)
在上述各个实施例中,说明了各抑制单元更新自适应滤波器的参数的示例。然而,在自适应滤波器的安装方法与上述实施例的各实施例中相同(上述各实施例中的fir滤波器)的情况下,可以将这些自适应滤波器中的一个自适应滤波器的参数反映在另一自适应滤波器中。因此,在第六实施例中,示出将多个自适应滤波器中的可以抑制声学噪声的自适应滤波器的参数应用于下一声学噪声抑制的示例。此外,声音传输环境与第一实施例的声音传输环境相同,并且将省略对该声音传输环境的说明。在以下的说明中,将滤波器系数作为自适应滤波器的参数的示例来进行说明,但可以以与其它实施例相同的方式使用诸如抽头数等的其它参数。
以下将说明根据第六实施例的声学噪声抑制设备05e所进行的处理的概述。声学噪声抑制设备05e存储多个自适应滤波器中的可以抑制声学噪声的自适应滤波器的滤波器系数,并且在进行声学噪声抑制之前、将所存储的自适应滤波器的滤波器系数恢复到各自适应滤波器。通过基于所恢复的自适应滤波器进行自适应滤波器的学习,可以使用在先前抑制声学噪声时能够抑制声学噪声的自适应滤波器的参数作为其它自适应滤波器的学习的基础。
[声学噪声抑制的结构]
图19是示出根据第六实施例的声学噪声抑制设备05e的结构的图。以下将仅说明与第一实施例的不同之处。
如图19所示,存储器50e包括滤波器系数存储单元60e和参考信号存储单元61e。
滤波器系数存储单元60e存储要恢复到自适应滤波器23和自适应滤波器33的滤波器系数。滤波器系数存储单元60e基于来自输出信号选择单元53e的声学噪声抑制结果,来获取并存储进一步抑制声学噪声所经由的自适应滤波器的滤波器系数。这里,声学噪声抑制结果可以是进一步抑制声学噪声所经由的自适应滤波器的信息,或者可以是进一步抑制声学噪声的抑制单元的信息。也就是说,可以使用任何信息,只要该信息可以识别进一步抑制噪声所经由的自适应滤波器即可。在本实施例中,存储器50e中的滤波器系数存储单元60e基于声学噪声抑制结果来判断要存储的滤波器系数,但该判断可以由诸如dsp10等的存储器外部的结构进行。
参考信号存储单元61e存储要发送至延时器29和延时器39的参考信号。在根据第六实施例的参考信号存储单元61e中,将过去从扬声器sp2输出的声音信号存储为参考信号。在本实施例中,由于第一参考信号和第二参考信号是相同的,因此将假定将同一参考信号作为单个参考信号存储在同一存储单元中来进行说明。与其它实施例相同,第一参考信号和第二参考信号可以是单独存储的。
除了从扬声器sp2要输出的音频信号的选择之外,输出信号选择单元53e还将上述的声学噪声抑制结果输出至滤波器系数存储单元60e。
[声学噪声抑制操作]
图20是示出根据第六实施例的声学噪声抑制设备05e的操作的流程图。与第一实施例中的处理相同的处理由与图4中相同的附图标记表示,并且将省略对该处理的说明。
自适应滤波器23和自适应滤波器33获取滤波器系数存储单元60e中所存储的滤波器系数,并将所获取到的滤波器系数恢复到自身(s1e)。
延时器29获取参考信号存储单元61e中所存储的参考信号作为第一参考信号(s13e)。
延时器39获取参考信号存储单元61e中所存储的参考信号作为第二参考信号(s23e)。
第一滤波器更新单元25计算滤波器特性的更新量并更新自适应滤波器23的特性。这里,第一滤波器更新单元25通过ica来计算滤波器特性的更新量(s14e)。
第二滤波器更新单元35计算滤波器特性的更新量并更新自适应滤波器33的特性。这里,第二滤波器更新单元35通过nlms来计算滤波器特性的更新量(s24e)。第一抑制单元20通过使用由延时器29延迟了与扬声器sp2和麦克风mc1之间的距离相对应的预定时间的第一参考信号、以及更新后的自适应滤波器23,来生成伪噪声信号。然后,利用加法器22向(从)麦克风mc1所拾取的声音的音频信号加上(减去)伪噪声信号。因此,第一抑制单元20通过从麦克风mc1所拾取的声音的音频信号中减去伪噪声信号来生成声学噪声抑制之后的信号。由于将所生成的声学噪声抑制之后的信号用于滤波器系数的下一更新处理,因此不论该信号是否最终从扬声器sp2输出,该信号都被输出至第一滤波器更新单元25(s15e)。在本实施例中,在步骤s1e中,自适应滤波器23和自适应滤波器33的滤波器特性变为相同。因此,为了在所生成的伪噪声信号和声学噪声抑制之后的信号之间提供差,在伪噪声信号的生成之前更新自适应滤波器23和自适应滤波器33。
第二抑制单元30通过使用由延时器39延迟了与扬声器sp2和麦克风mc1之间的距离相对应的预定时间的第二参考信号、以及更新后的自适应滤波器33,来生成伪噪声信号。然后,利用加法器32向(从)麦克风mc1所拾取的音频信号加上(减去)伪噪声信号。因此,第二抑制单元30通过从麦克风mc1所拾取的音频信号中减去伪噪声信号来生成声学噪声抑制之后的信号。由于将所生成的声学噪声抑制之后的信号用于滤波器系数的下一更新处理,因此不论该信号是否最终从扬声器sp2输出,该信号都被输出至第二滤波器更新单元35(s25e)。
滤波器系数存储单元60e基于从输出信号选择单元53e报告的声学噪声抑制结果,来获取并存储自适应滤波器23或自适应滤波器33的滤波器系数(s3e)。
参考信号存储单元61e将被输出信号选择单元53e选择作为要从扬声器输出的信号的信号存储为参考信号(s4e)。
[第六实施例的概要]
如上所述,第六实施例的声学噪声抑制设备05e存储多个自适应滤波器中的、可以进一步抑制声学噪声的自适应滤波器的滤波器系数,恢复所存储的滤波器系数,并将该滤波器系数用于下一声学噪声抑制。因此,可以提高自适应滤波器的滤波器系数的学习速度。
此外,第六实施例的声学噪声抑制设备05e更新并存储多个自适应滤波器中的、可以进一步抑制声学噪声的自适应滤波器的滤波器系数。在将所存储的滤波器系数应用于第一抑制单元20和第二抑制单元30这两者的自适应滤波器之后,自适应滤波器通过各自的抑制单元进行学习以抑制声学噪声。因此,由于基于进一步抑制声学噪声的先前结果来抑制声学噪声,因此可以高效地抑制声学噪声。
第六实施例的声学噪声抑制设备05e将不同的算法用于更新自适应滤波器的第一滤波器更新单元25和第二滤波器更新单元35。因此,第一滤波器更新单元25和第二滤波器更新单元35具有可以适当地更新自适应滤波器的不同环境。因此,即使环境不适合于一个滤波器更新单元对滤波器进行更新,另一滤波器更新单元也可以适当地对滤波器进行更新,使得可以抑制自适应滤波器的劣化。
在第六实施例的声学噪声抑制设备05e中,存储器50e将第一参考信号和第二参考信号存储为同一参考信号,并且延时器获取到同一参考信号作为第一参考信号或第二参考信号。因此,无需单独存储第一参考信号和第二参考信号,使得可以抑制参考信号的数据量。注意,存储器50e的结构是示例,并且可以从其它元件获取各种信息,并且可以临时地或永久地存储这些信息。
在上述说明中,以第一实施例为基准以说明差异的形式说明了第六实施例。然而,如第六实施例所述,将多个自适应滤波器中的能够进一步抑制声学噪声的滤波器系数适用于下一声学噪声抑制的构思可应用于第二实施例至第五实施例。然而,在应用于第二实施例至第五实施例时,如上述对该操作的说明那样,需要改变声学噪声抑制和滤波器更新的处理顺序。
此外,如第六实施例所述,将第一参考信号和第二参考信号作为一个参考信号存储在存储器中并且在延时器中获取该一个参考信号作为第一参考信号或第二参考信号这一构思可应用于其它实施例。在如第二实施例和第三实施例那样、第一参考信号和第二参考信号相同的情况下,存储器可以将第一参考信号和第二参考信号存储为一个参考信号。此外,在如第四实施例那样、参考信号针对各说话者而不同的情况下,存储器可以针对各说话者识别信息存储一个参考信号。也就是说,第六实施例所示的各种构思可应用于如各个实施例所示的声学噪声抑制设备,即在更新滤波器之后抑制声学噪声的声学噪声抑制设备。
(其它变形例)
在上述的第一实施例至第四实施例中,用于更新自适应滤波器的算法被描述为ica和nlms。然而,可以使用算法的其它组合。此外,还可以使用相同的算法,但可以使用不同的参数。例如,在第一处理系统和第二处理系统中,可以使用更新周期不同的nlms。这里,在更新周期长的nlms中,代替缓慢地跟随环境变化,自适应滤波器的特性是稳定的。这里,在更新周期短的nlms中,代替快速地跟随环境变化,自适应滤波器的特性是不稳定的。因此,通过从这些处理系统中选择声学噪声被进一步抑制的输出结果,可以在变化大的环境和变化小的环境这两者中抑制声学噪声。顺便提及,除非另外说明,否则参数不同的相同算法可被视为不同的算法。
尽管已经使用两个处理系统说明了上述实施例,但可以使用三个或更多个处理系统。例如,在第一处理系统中,使用ica来更新滤波器,并且在第二处理系统和第三处理系统中,使用更新周期不同的nlms来更新滤波器。结果,可以响应于同时说话的说话者的人数的变化和环境的突然变化来抑制声学噪声。
在上述各个实施例中,已经通过使用针对麦克风mc1所获取到的音频信号进行一次声学噪声抑制的结构进行了说明。然而,针对麦克风mc1所获取到的音频信号,声学噪声被抑制了一次以上。例如,在通过使用自适应滤波器23抑制声学噪声之后,可设想通过使用自适应滤波器33来抑制声学噪声。在这种情况下,通过利用具有不同特性的自适应滤波器,通过一个滤波器不能抑制的声学噪声可以由另一滤波器抑制。作为使自适应滤波器的特性不同的方法,如上述的各个实施例那样,即使在用于计算更新量的算法不同或者使用相同算法的情况下,也可以考虑区分自适应滤波器的学习环境或更新周期的方法。此外,可以使用具有相同特性的自适应滤波器来多次抑制声学噪声。结果,利用自适应滤波器来抑制声学噪声的效果更为显著。这样,通过对音频信号多次进行声学噪声抑制处理,可以在更广泛的环境中抑制声学噪声。
在上述实施例中,已经说明了车辆内部中的声学噪声的抑制作为示例,但本发明不限于此。上述实施例也可应用于诸如会议室等的其它环境。在上述实施例中,由于基于实际测量来计算延时器的值,因此期望测量声学噪声的声源和麦克风之间的距离。然而,如果延时器没有极大地改变,则可以通过自适应滤波器的学习来吸收一定程度的误差,使得即使在难以测量距离的环境中,也可以获得根据各实施例的声学噪声抑制的效果。
在上述实施例中,通过利用延时器延迟参考信号,根据各扬声器和麦克风之间的距离来调整定时。然而,如果参考信号可以以足够的长度存储在存储器中,则可以提取所存储的参考信号中的与适当定时相对应的部分。
在各实施例中,用于更新自适应滤波器的算法仅仅是示例。作为用于更新自适应滤波器的算法,已知有除ica和nlms以外的各种算法。在不背离实施例的精神的情况下,可以通过其它已知算法来更新自适应滤波器。
在第一实施例至第五实施例中,各处理系统在抑制声学噪声之后更新滤波器,但可以在更新滤波器之后抑制声学噪声。即使顺序改变,也可以抑制声学噪声。
本发明可被表现为声学噪声抑制设备或在控制装置中执行的声学噪声抑制方法。此外,本发明还可被表现为用于使得计算机执行这样的方法的程序。此外,本发明还可被表现为将这样的程序以由计算机可读取的状态记录的记录介质。也就是说,本发明可以以装置、方法、程序和记录介质中的任何类别表现。
此外,在各个实施例(包括变形例)的说明中所使用的各功能块被部分地或全部地实现为作为集成电路的lsi,并且上述实施例中所述的各处理可以部分地或全部地由单个lsi或lsi的组合来控制。lsi可以设置有各个芯片,或者可以设置有一个芯片以包括功能块的一部分或全部。lsi可以包括数据输入和输出。lsi根据集成程度可被称为ic、系统lsi、超级lsi或超大lsi。
电路集成的方法不限于lsi,并且可以由专用电路或通用处理器实现。可以使用在lsi的制造之后可以编程的现场可编程门阵列(fpga)、或者可以再配置lsi内的电路单元的连接和设置的可重构处理器。本发明可被实现为数字处理或模拟处理。
此外,在作为半导体技术的进步或其它派生技术的结果、出现了取代lsi的集成电路技术的情况下,该技术自然可用于集成功能块。可以应用生物技术等。
此外,在作为半导体技术的进步或其它派生技术的结果、出现了取代lsi的集成电路技术的情况下,其它技术自然也可用于集成功能块。可以应用生物技术等。
此外,在本说明中,构件的类型、配置和数量等不限于上述实施例,并且在未背离本发明的精神的情况下,可以通过使用具有相同操作效果的组件适当地替换这些组件来适当地改变这些组件。
此外,根据本发明的装置的结构是示例,并且可以由将各组件划分到不同装置中的系统来实现。例如,处理负荷重的功能可以由云服务器等实现,并且处理负荷小的功能可以由边缘服务器来实现。
本发明用于在存在突然的环境变化的情况下或者在多个人同时说话的情况下,能够抑制输出声音的音质劣化的声学噪声抑制设备和声学噪声抑制方法等。
相关申请的交叉引用
本申请基于并要求2019年4月8日提交的日本专利申请2019-73493的优先权,其内容通过引用而被全部包含于此。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



