
 商标分类
商标分类  商标转让
商标转让 
英语语音分析和加强学习系统及方法与流程
 2021-01-28 16:01:29|
2021-01-28 16:01:29| 306|
306| 起点商标网
起点商标网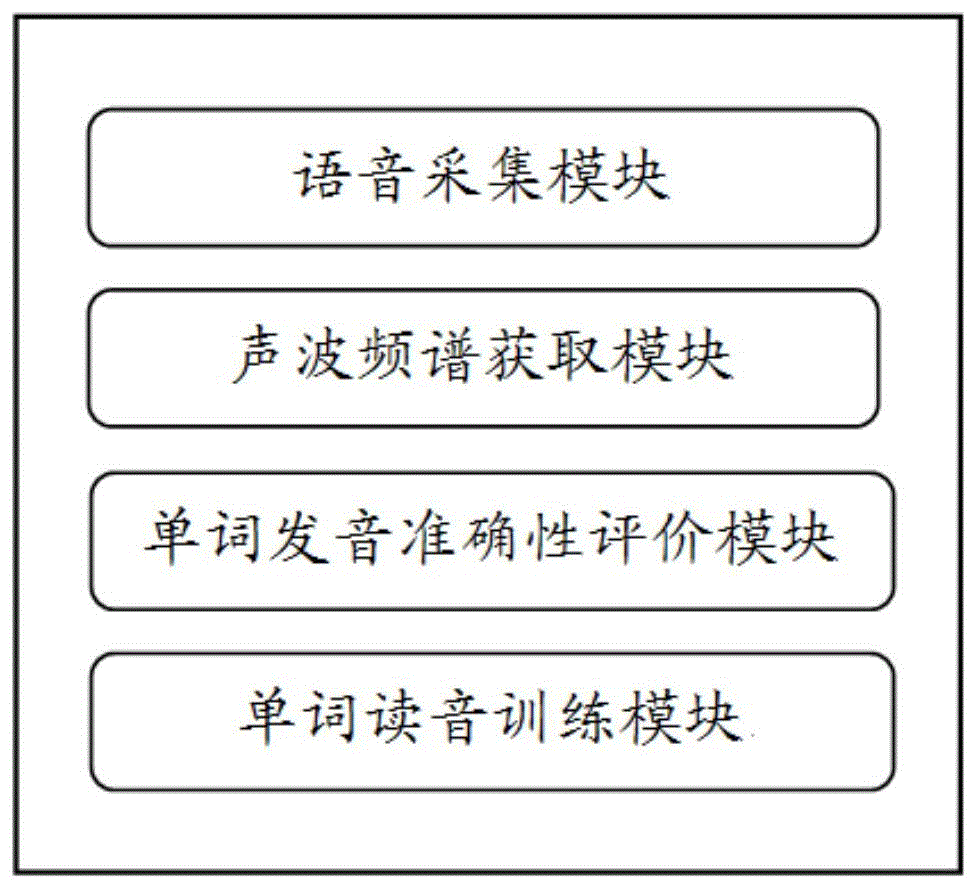
本发明涉及智能教学的技术领域,特别涉及英语语音分析和加强学习系统及方法。
背景技术:
目前,英语发音教学主要是通过教师课堂教学以及多媒体音频教学等方式来实现的,学生通过诵读英语单词或者语句来不断完善自身的英语发音标准性,但是上述英语发音教学方式均存在教学场合和教学灵活性的局限,其并不能提供针对不同学生自身的发音问题进行有针对性分析和加强发音训练的有效方案,这严重地降低了英语发音教学的对不同学生的普适性和有效性。
技术实现要素:
针对现有技术存在的缺陷,本发明提供英语语音分析和加强学习系统及方法,该英语语音分析和加强学习系统及方法通过采集预设对象诵读英语对应的语音声波信号,并对该语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,再对每一个单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱,并通过预设神经网络模型对声波频谱进行分析处理,以此评价预设对象当前诵读英语过程中单词发音标准性,最后根据单词发音标准性的评价结果,向预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练;可见,该英语语音分析和加强学习系统及方法能够从单词发音层面上对预设对象的英语诵读标准性进行精确评价,其不仅能够帮助预设对象纠正特定单词的发音,并且还能够通过推送其他关联单词来对预设对象进行循环加强化的发音训练,从而高效地和全面地改善预设对象的英语发音标准性。
本发明提供英语语音分析和加强学习系统,其特征在于,包括语音采集模块、声波频谱获取模块、单词发音准确性评价模块和单词读音训练模块;其中,
所述语音采集模块用于采集预设对象诵读英语对应的语音声波信号,并对所述语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,所述语音声波信号包括所述预设对象诵读单词和语句的语音声波信号;
所述声波频谱获取模块用于对每一个所述单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱;
所述单词发音准确性评价模块用于通过预设神经网络模型对所述声波频谱进行分析处理,以此评价所述预设对象当前诵读英语过程中单词发音标准性;
所述单词读音训练模块用于根据所述单词发音标准性的评价结果,向所述预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练;
进一步,所述语音采集模块包括语音声波信号采集与判断子模块、声波信号停顿状态确定子模块和语句诵读声波信号划分子模块;其中,
所述语音声波信号采集与判断子模块用于以16000次/s的采样频率采集所述预设对象英语对应的语音声波信号,并判断所述语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号,以及在所述语音声波信号属于单词诵读语音声波信号时,将当前的语音声波信号直接作为一个单词诵读声波信号;
所述声波信号停顿状态确定子模块用于在所述语音声波信号属于语句诵读声波信号时,计算所述语音声波信号对应的所有语音帧能量分布值,并判断每一帧能量分布值是否超过预设能量阈值,若超过,则确定当前语音帧属于诵读状态,若不超过,则确定当前语音帧属于非诵读的停顿状态;
所述语句诵读声波信号划分子模块用于根据所有所述停顿状态,对所述语音声波信号进行单一单词诵读划分处理,以此将所述语音声波信号划分为多个单词诵读语音声波信号;
进一步,所述声波频谱获取模块包括音频向量确定子模块和声波频谱计算子模块;其中,
所述音频向量确定子模块用于根据每一个所述单词诵读语音声波信号生成如下的16000个/s的数列
x1,1,x1,2,x1,3,…,x1,16000,x2,1,x2,2,…,x2,16000,…,xt,1,…,xt,16000,……
再按照20ms的间隔对所述数列划分为800个音频块,所述800个音频块记为下面音频向量
yi=(yi1,yi2,…,yi800)t;
所述声波频谱计算子模块用于根据下面公式(1),对所述音频向量进行线性插值,
在上述公式(1)中,δt=1/16000,k=1,2…800
对上述公式(1)进行傅里叶展开处理,即如下面公式(2)所示
在上述公式(2)中,j表示单位虚数,系数cn由傅里叶逆变换求得,即
再将所有系数共同组成如下面公式(3)所示的声波频谱x
x=(c1,c2,…,c799,c800)t(3);
进一步,所述单词发音准确性评价模块包括神经网络处理子模块、实际发音评价子模块和字母标注子模块;其中,
所述神经网络处理子模块用于通过预设神经网络模型对声波频谱进行处理,其具体过程为,
a1,将所述声波频谱x=(c1,c2,…,c799,c800)t输入至完成训练的所述预设神经网络模型中,相应地所述预设神经网络模型的输出结果包含800个27维的向量output,每一个向量output具有下面公式(4)表示的数学形式
output=(p1,p2,…,p25,p26,p27)t(4)
在上述公式(4)中,pi表示向量每i维的概率值,并且
a2,设定j=argmaxpi(1≤i≤27),argmax表示取最大值运算,以及设定映射函数map:{1,2,…,27}→{a,b,c,d,…,x,y,z,__},其中__代表空格符号,此时每次向所述预设神经网络模型输入相应的声波频谱x,即可得到相应的数值j,并生成相应数值序列(j1,j2,…,j800)t;
a3,将所述映射函数作用于所述数值序列,并得到如下函数结果
word=map(j)=(map(j1),…,map(j800))t
对所述函数结果word进行如下删除空格的修正处理,以此获得所述预设对象当前诵读英语的实际发音
在上述修正处理中,wordmod表示修成处理的结果,wordiifwordi≠__表示若当前符号不为空格符号,则将当前符号直接作为结果输出,deleteifwordi=__表示当前符号为空格符号,则将当前符号直接删除;
所述实际发音评价子模块用于根据预设评价函数计算所述实际发音的评价函数值value,其具体过程为,
b1,获取所述实际发音对应的频谱z1,以及从标准语音库中获得所述预设对象在英语诵读过程中单词标准发音频谱z2,所述频谱z1与所述单词标准发音频谱z2为具有相同长度n的向量;
b2,根据下面公式(5),计算所述实际发音对应的评价函数值value,并且当评价函数值value越大代表所述实际发音越标准
在上述公式(5)中,
所述字母标注子模块用于对预设对象在当前诵读过程中存在发音问题的字母进行标注,其具体过程为,
根据下面公式(6)定义差值函数diff
diff=argmax(value)(6)
argmax()表示取最大值运算,并且根据所述差值函数diff将所述预设对象在当前诵读过程中存在发音问题的字母进行发音标准与否标注;
进一步,所述单词读音训练模块包括单词提取子模块和单词推送子模块;其中,
所述单词提取子模块用于根据所述预设对象在当前诵读过程中存在发音问题的字母标注结果,从预设单词语音库中提取与目标单词具有相近发音的其他单词;
所述单词推送子模块用于将所述其他单词推送至所述预设对象,以此对所述预设对象单词读音训练。
本发明还提供英语语音分析和加强学习系统,其特征在于,所述英语语音分析和加强学习方法包括如下步骤:
步骤s1,采集预设对象诵读英语对应的语音声波信号,并对所述语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,所述语音声波信号包括所述预设对象诵读单词和语句的语音声波信号;
步骤s2,对每一个所述单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱;
步骤s3,通过预设神经网络模型对所述声波频谱进行分析处理,以此评价所述预设对象当前诵读英语过程中单词发音标准性;
步骤s4,根据所述单词发音标准性的评价结果,向所述预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练;
进一步,在所述步骤s1中,采集预设对象诵读英语对应的语音声波信号,并对所述语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,所述语音声波信号包括所述预设对象诵读单词和语句的语音声波信号具体包括,
步骤s101,以16000次/s的采样频率采集所述预设对象英语对应的语音声波信号,并判断所述语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号;
步骤s102,若属于单词诵读声波信号,则将当前的语音声波信号直接作为一个单词诵读声波信号;
步骤s103,若属于语句诵读声波信号,则计算所述语音声波信号对应的所有语音帧能量分布值,并判断每一帧能量分布值是否超过预设能量阈值,若超过,则确定当前语音帧属于诵读状态,若不超过,则确定当前语音帧属于非诵读的停顿状态;
步骤s104,根据所有所述停顿状态,对所述语音声波信号进行单一单词诵读划分处理,以此将所述语音声波信号划分为多个单词诵读语音声波信号;
进一步,在所述步骤s2中,对每一个所述单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱具体包括,
步骤s201,根据每一个所述单词诵读语音声波信号生成如下的16000个/s的数列
x1,1,x1,2,x1,3,…,x1,16000,x2,1,x2,2,…,x2,16000,…,xt,1,…,xt,16000,……
再按照20ms的间隔对所述数列划分为800个音频块,所述800个音频块记为下面音频向量
yi=(yi1,yi2,…,yi800)t;
步骤s202,根据下面公式(1),对所述音频向量进行线性插值,
在上述公式(1)中,δt=1/16000,k=1,2…800
对上述公式(1)进行傅里叶展开处理,即如下面公式(2)所示
在上述公式(2)中,j表示单位虚数,系数cn由傅里叶逆变换求得,即
再将所有系数共同组成如下面公式(3)所示的声波频谱x
x=(c1,c2,…,c799,c800)t(3);
进一步,在所述步骤s3中,通过预设神经网络模型对所述声波频谱进行分析处理,以此评价所述预设对象当前诵读英语过程中单词发音标准性具体包括,
步骤s301,将所述声波频谱x=(c1,c2,…,c799,c800)t输入至完成训练的所述预设神经网络模型中,相应地所述预设神经网络模型的输出结果包含800个27维的向量output,每一个向量output具有下面公式(4)表示的数学形式
output=(p1,p2,…,p25,p26,p27)t(4)
在上述公式(4)中,pi表示向量每i维的概率值,并且
步骤s302,设定j=argmaxpi(1≤i≤27),argmax表示取最大值运算,以及设定映射函数map:{1,2,…,27}→{a,b,c,d,…,x,y,z,__},其中__代表空格符号,此时每次向所述预设神经网络模型输入相应的声波频谱x,即可得到相应的数值j,并生成相应数值序列(j1,j2,…,j800)t;
步骤s303,将所述映射函数作用于所述数值序列,并得到如下函数结果
word=map(j)=(map(j1),…,map(j800))t
对所述函数结果word进行如下删除空格的修正处理,以此获得所述预设对象当前诵读英语的实际发音
在上述修正处理中,wordmod表示修成处理的结果,wordiifwordi≠__表示若当前符号不为空格符号,则将当前符号直接作为结果输出,deleteifwordi=__表示当前符号为空格符号,则将当前符号直接删除;
步骤s304,获取所述实际发音对应的频谱z1,以及从标准语音库中获得所述预设对象在英语诵读过程中单词标准发音频谱z2,所述频谱z1与所述单词标准发音频谱z2为具有相同长度n的向量;
步骤s305,根据下面公式(5),计算所述实际发音对应的评价函数值value,并且当评价函数值value越大代表所述实际发音越标准
在上述公式(5)中,
步骤s306,根据下面公式(6)定义差值函数diff
diff=argmax(value)(6)
argmax()表示取最大值运算,并且根据所述差值函数diff将所述预设对象在当前诵读过程中存在发音问题的字母进行发音标准与否标注;
进一步,在所述步骤s4中,根据所述单词发音标准性的评价结果,向所述预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练具体包括,
根据所述预设对象在当前诵读过程中存在发音问题的字母标注结果,从预设单词语音库中提取与目标单词具有相近发音的其他单词,并将所述其他单词推送至所述预设对象,以此对所述预设对象单词读音训练。
相比于现有技术,该英语语音分析和加强学习系统及方法通过采集预设对象诵读英语对应的语音声波信号,并对该语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,再对每一个单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱,并通过预设神经网络模型对声波频谱进行分析处理,以此评价预设对象当前诵读英语过程中单词发音标准性,最后根据单词发音标准性的评价结果,向预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练;可见,该英语语音分析和加强学习系统及方法能够从单词发音层面上对预设对象的英语诵读标准性进行精确评价,其不仅能够帮助预设对象纠正特定单词的发音,并且还能够通过推送其他关联单词来对预设对象进行循环加强化的发音训练,从而高效地和全面地改善预设对象的英语发音标准性。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的英语语音分析和加强学习系统的结构示意图。
图2为本发明提供的英语语音分析和加强学习方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参阅图1,为本发明实施例提供的英语语音分析和加强学习系统的结构示意图。该英语语音分析和加强学习系统包括语音采集模块、声波频谱获取模块、单词发音准确性评价模块和单词读音训练模块;其中,
该语音采集模块用于采集预设对象诵读英语对应的语音声波信号,并对该语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,该语音声波信号包括该预设对象诵读单词和语句的语音声波信号;
该声波频谱获取模块用于对每一个该单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱;
该单词发音准确性评价模块用于通过预设神经网络模型对该声波频谱进行分析处理,以此评价该预设对象当前诵读英语过程中单词发音标准性;
该单词读音训练模块用于根据该单词发音标准性的评价结果,向该预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练。
该英语语音分析和加强学习系统能够对语音声波信号进行单词诵读语音层面的声波频谱分析处理,以此确定预设对象在单个单词上的发音评价状态,并将该发音评价状态与标准发音状态进行比对,从而将预设对象存在发音问题的字母进行标注,并对预设对象推送相关联的其他不同单词,以帮助预设对象加强对单词发音的训练强度和训练针对性。
优选地,该语音采集模块包括语音声波信号采集与判断子模块、声波信号停顿状态确定子模块和语句诵读声波信号划分子模块;其中,
该语音声波信号采集与判断子模块用于以16000次/s的采样频率采集该预设对象英语对应的语音声波信号,并判断该语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号,以及在该语音声波信号属于单词诵读语音声波信号时,将当前的语音声波信号直接作为一个单词诵读声波信号;
该声波信号停顿状态确定子模块用于在该语音声波信号属于语句诵读声波信号时,计算该语音声波信号对应的所有语音帧能量分布值,并判断每一帧能量分布值是否超过预设能量阈值,若超过,则确定当前语音帧属于诵读状态,若不超过,则确定当前语音帧属于非诵读的停顿状态;
该语句诵读声波信号划分子模块用于根据所有该停顿状态,对该语音声波信号进行单一单词诵读划分处理,以此将该语音声波信号划分为多个单词诵读语音声波信号。
通过判断采集得到的语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号,并根据预设对象诵读过程中的停顿状态来对语句诵读声波信号划分为多个单词诵读语音声波信号,从而保证后续语音声波信号的处理始终维持在单个单词语音信号的层面上,这不仅能够降低对单一语音声波信号的数据处理量和处理难度,并且还能够提高后续对语音声波信号的处理精确性。
优选地,该声波频谱获取模块包括音频向量确定子模块和声波频谱计算子模块;其中,
该音频向量确定子模块用于根据每一个该单词诵读语音声波信号生成如下的16000个/s的数列
x1,1,x1,2,x1,3,…,x1,16000,x2,1,x2,2,…,x2,16000,…,xt,1,…,xt,16000,……
再按照20ms的间隔对该数列划分为800个音频块,该800个音频块记为下面音频向量
yi=(yi1,yi2,…,yi800)t;
该声波频谱计算子模块用于根据下面公式(1),对该音频向量进行线性插值,
在上述公式(1)中,δt=1/16000,k=1,2…800
对上述公式(1)进行傅里叶展开处理,即如下面公式(2)所示
在上述公式(2)中,j表示单位虚数,系数cn由傅里叶逆变换求得,即
再将所有系数共同组成如下面公式(3)所示的声波频谱x
x=(c1,c2,…,c799,c800)t(3)。
对该音频向量进行上述过程的声波频谱的计算,能够将该语音声波信号转换为便于进行不同数据运算处理的声波频谱,从而便于后续在频域上对该语音声波信号进行评价处理,并且在实际操作中,该声波频谱x可为连续谱或者离散谱,其中连续谱能够最大限度地真实反映声波频率的分布状态,而离散谱能够有效地降低后续计算处理的工作量,其在实际计算中较为常用。
优选地,该单词发音准确性评价模块包括神经网络处理子模块、实际发音评价子模块和字母标注子模块;其中,
该神经网络处理子模块用于通过预设神经网络模型对声波频谱进行处理,其具体过程为,
a1,将该声波频谱x=(c1,c2,…,c799,c800)t输入至完成训练的该预设神经网络模型中,其中该预设神经网络模型为mozilla开源语音识别框架,相应地该预设神经网络模型的输出结果包含800个27维的向量output,每一个向量output具有下面公式(4)表示的数学形式
output=(p1,p2,…,p25,p26,p27)t(4)
在上述公式(4)中,pi表示向量每i维的概率值,并且
a2,设定j=argmaxpi(1≤i≤27),argmax表示取最大值运算,以及设定映射函数map:{1,2,…,27}→{a,b,c,d,…,x,y,z,__},其中__代表空格符号,此时每次向该预设神经网络模型输入相应的声波频谱x,即可得到相应的数值j,并生成相应数值序列(j1,j2,…,j800)t;
a3,将该映射函数作用于该数值序列,并得到如下函数结果
word=map(j)=(map(j1),…,map(j800))t
对该函数结果word进行如下删除空格的修正处理,以此获得该预设对象当前诵读英语的实际发音
在上述修正处理中,wordmod表示修成处理的结果,wordiifwordi≠__表示若当前符号不为空格符号,则将当前符号直接作为结果输出,deleteifwordi=__表示当前符号为空格符号,则将当前符号直接删除;
该实际发音评价子模块用于根据预设评价函数计算该实际发音的评价函数值value,其具体过程为,
b1,获取该实际发音对应的频谱z1,以及从标准语音库中获得该预设对象在英语诵读过程中单词标准发音频谱z2,该频谱z1与该单词标准发音频谱z2为具有相同长度n的向量;
b2,根据下面公式(5),计算该实际发音对应的评价函数值value,并且当评价函数值value越大代表该实际发音越标准
在上述公式(5)中,
该字母标注子模块用于对预设对象在当前诵读过程中存在发音问题的字母进行标注,其具体过程为,
根据下面公式(6)定义差值函数diff
diff=argmax(value)(6)
argmax()表示取最大值运算,并且根据该差值函数diff将该预设对象在当前诵读过程中存在发音问题的字母进行发音标准与否标注。
具体地,在标注发音标准与否时,可以按照如下标准来标注:当diff的值小于预设的一个基准值时,标注为发音标准;当diff的值大于或等于基准值时,标注为发音不标准。
通过mozilla开源语音识别框架这一神经网络模型对该声波频率进行相应的分析处理,能够实现在字母层面上对该声波频率的发音标准性进行评价判断,此外该公式(5)计算得到的实际发音评价函数值能够最大限度地反应该实际发音的发音标准程度;此外还通过对该差异函数diff的结果进行最大取值,以此标定预设对象在当前诵读过程中存在发音问题的字母,以便于后续进行适应性的发音校正。
优选地,该单词读音训练模块包括单词提取子模块和单词推送子模块;其中,
该单词提取子模块用于根据该预设对象在当前诵读过程中存在发音问题的字母标注结果,从预设单词语音库中提取与目标单词具有相近发音的其他单词;
该单词推送子模块用于将该其他单词推送至该预设对象,以此对该预设对象单词读音训练。
通过从预设单词语音库中提取与目标单词具有相近发音的其他单词,能够实现对预设对象的举一反三发音训练,从而高效地和全面地改善预设对象的英语发音标准性。
参阅图2,为本发明实施例提供的英语语音分析和加强学习方法的流程示意图。该英语语音分析和加强学习方法包括如下步骤:
步骤s1,采集预设对象诵读英语对应的语音声波信号,并对该语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,该语音声波信号包括该预设对象诵读单词和语句的语音声波信号;
步骤s2,对每一个该单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱;
步骤s3,通过预设神经网络模型对该声波频谱进行分析处理,以此评价该预设对象当前诵读英语过程中单词发音标准性;
步骤s4,根据该单词发音标准性的评价结果,向该预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练。
该英语语音分析和加强学习方法能够对语音声波信号进行单词诵读语音层面的声波频谱分析处理,以此确定预设对象在单个单词上的发音评价状态,并将该发音评价状态与标准发音状态进行比对,从而将预设对象存在发音问题的字母进行标注,并对预设对象推送相关联的其他不同单词,以帮助预设对象加强对单词发音的训练强度和训练针对性。
优选地,在该步骤s1中,采集预设对象诵读英语对应的语音声波信号,并对该语音声波信号进行单词诵读语音提取处理,以此获得一个或者多个单词诵读语音声波信号,其中,该语音声波信号包括该预设对象诵读单词和语句的语音声波信号具体包括,
步骤s101,以16000次/s的采样频率采集该预设对象英语对应的语音声波信号,并判断该语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号;
步骤s102,若属于单词诵读声波信号,则将当前的语音声波信号直接作为一个单词诵读声波信号;
步骤s103,若属于语句诵读声波信号,则计算该语音声波信号对应的所有语音帧能量分布值,并判断每一帧能量分布值是否超过预设能量阈值,若超过,则确定当前语音帧属于诵读状态,若不超过,则确定当前语音帧属于非诵读的停顿状态;
步骤s104,根据所有该停顿状态,对该语音声波信号进行单一单词诵读划分处理,以此将该语音声波信号划分为多个单词诵读语音声波信号。
通过判断采集得到的语音声波信号属于单词诵读语音声波信号还是语句诵读声波信号,并根据预设对象诵读过程中的停顿状态来对语句诵读声波信号划分为多个单词诵读语音声波信号,从而保证后续语音声波信号的处理始终维持在单个单词语音信号的层面上,这不仅能够降低对单一语音声波信号的数据处理量和处理难度,并且还能够提高后续对语音声波信号的处理精确性。
优选地,在该步骤s2中,对每一个该单词诵读语音声波信号进行音频向量分析,以此获得对应的声波频谱具体包括,
步骤s201,根据每一个该单词诵读语音声波信号生成如下的16000个/s的数列
x1,1,x1,2,x1,3,…,x1,16000,x2,1,x2,2,…,x2,16000,…,xt,1,…,xt,16000,……
再按照20ms的间隔对该数列划分为800个音频块,该800个音频块记为下面音频向量
yi=(yi1,yi2,…,yi800)t;
步骤s202,根据下面公式(1),对该音频向量进行线性插值,
在上述公式(1)中,δt=1/16000,k=1,2…800
对上述公式(1)进行傅里叶展开处理,即如下面公式(2)所示
在上述公式(2)中,j表示单位虚数,系数cn由傅里叶逆变换求得,即
再将所有系数共同组成如下面公式(3)所示的声波频谱x
x=(c1,c2,…,c799,c800)t(3)。
对该音频向量进行上述过程的声波频谱的计算,能够将该语音声波信号转换为便于进行不同数据运算处理的声波频谱,从而便于后续在频域上对该语音声波信号进行评价处理,并且在实际操作中,该声波频谱x可为连续谱或者离散谱,其中连续谱能够最大限度地真实反映声波频率的分布状态,而离散谱能够有效地降低后续计算处理的工作量,其在实际计算中较为常用。
优选地,在该步骤s3中,通过预设神经网络模型对该声波频谱进行分析处理,以此评价该预设对象当前诵读英语过程中单词发音标准性具体包括,
步骤s301,将该声波频谱x=(c1,c2,…,c799,c800)t输入至完成训练的该预设神经网络模型中,其中该预设神经网络模型为mozilla开源语音识别框架,相应地该预设神经网络模型的输出结果包含800个27维的向量output,每一个向量output具有下面公式(4)表示的数学形式
output=(p1,p2,…,p25,p26,p27)t(4)
在上述公式(4)中,pi表示向量每i维的概率值,并且
步骤s302,设定j=argmaxpi(1≤i≤27),argmax表示取最大值运算,以及设定映射函数map:{1,2,…,27}→{a,b,c,d,…,x,y,z,__},其中__代表空格符号,此时每次向该预设神经网络模型输入相应的声波频谱x,即可得到相应的数值j,并生成相应数值序列(j1,j2,…,j800)t;
步骤s303,将该映射函数作用于该数值序列,并得到如下函数结果
word=map(j)=(map(j1),…,map(j800))t
对该函数结果word进行如下删除空格的修正处理,以此获得该预设对象当前诵读英语的实际发音
在上述修正处理中,wordmod表示修成处理的结果,wordiifwordi≠__表示若当前符号不为空格符号,则将当前符号直接作为结果输出,deleteifwordi=__表示当前符号为空格符号,则将当前符号直接删除
步骤s304,获取该实际发音对应的频谱z1,以及从标准语音库中获得该预设对象在英语诵读过程中单词标准发音频谱z2,该频谱z1与该单词标准发音频谱z2为具有相同长度n的向量;
步骤s305,根据下面公式(5),计算该实际发音对应的评价函数值value,并且当评价函数值value越大代表该实际发音越标准
在上述公式(5)中,
步骤s306,根据下面公式(6)定义差值函数diff
diff=argmax(value)(6)
argmax()表示取最大值运算,并且根据该差值函数diff将该预设对象在当前诵读过程中存在发音问题的字母进行发音标准与否标注。
通过mozilla开源语音识别框架这一神经网络模型对该声波频率进行相应的分析处理,能够实现在字母层面上对该声波频率的发音标准性进行评价判断,此外该公式(5)计算得到的实际发音评价函数值能够最大限度地反应该实际发音的发音标准程度;此外还通过对该差异函数diff的结果进行最大取值,以此标定预设对象在当前诵读过程中存在发音问题的字母,以便于后续进行适应性的发音校正。
优选地,在该步骤s4中,根据该单词发音标准性的评价结果,向该预设对象推送与单词读音相关联的若干单词,以此进行单词读音训练具体包括,
根据该预设对象在当前诵读过程中存在发音问题的字母标注结果,从预设单词语音库中提取与目标单词具有相近发音的其他单词,并将该其他单词推送至该预设对象,以此对该预设对象单词读音训练。
通过从预设单词语音库中提取与目标单词具有相近发音的其他单词,能够实现对预设对象的举一反三发音训练,从而高效地和全面地改善预设对象的英语发音标准性。
从上述实施例的内容可知,该英语语音分析和加强学习系统及方法能够从单词发音层面上对预设对象的英语诵读标准性进行精确评价,其不仅能够帮助预设对象纠正特定单词的发音,并且还能够通过推送其他关联单词来对预设对象进行循环加强化的发音训练,从而高效地和全面地改善预设对象的英语发音标准性。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



