
 商标分类
商标分类  商标转让
商标转让 
一种基于生成对抗网络的虚拟人声视唱方法和系统与流程
 2021-01-28 16:01:45|
2021-01-28 16:01:45| 413|
413| 起点商标网
起点商标网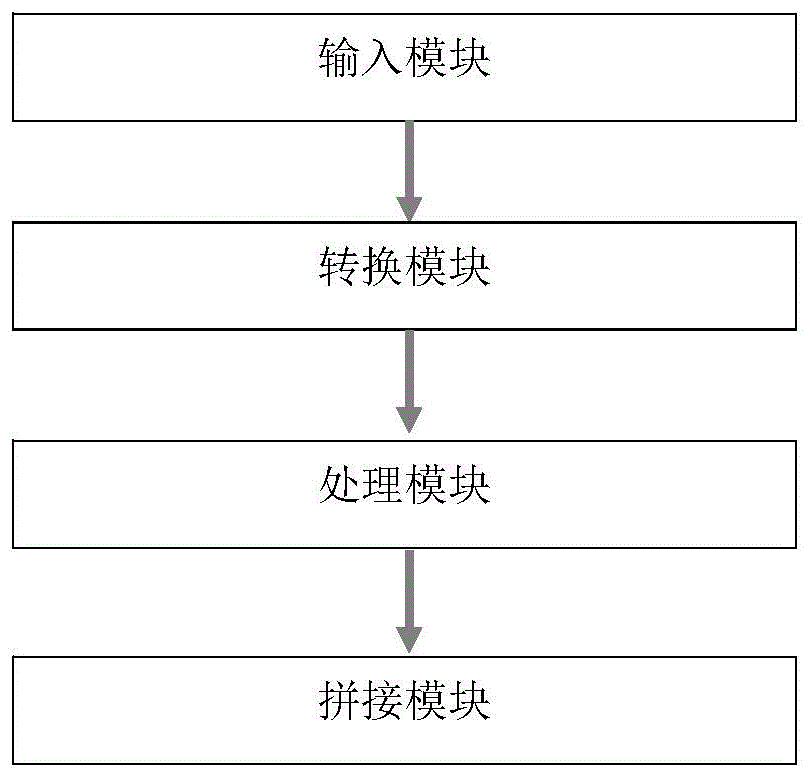
本发明属于计算机领域,具体地,涉及一种基于生成对抗网络的虚拟人声视唱方法和系统。
背景技术:
学习音乐时,看谱并唱出是学习音乐的基础,称为“视唱”。视唱练耳特别重要,然而问题是视唱练耳的课外活动需要大量练习才能达到学习效果。显然,对于绝大多数的普通家庭,教师是无法陪伴学生全天候完成练习。因为学习与练习有着分不开的联系,练习对于唱歌和听力至关重要,所以,可以得知传统的听力训练中的听力训练课程存在一些缺陷,需要对其做出一些改进。“真人唱谱,逼真易学。”虚拟人声视唱乐谱相当于真人唱谱,弥补了诸如钢琴、电子琴等乐器音色与人声不同的短板,大大提高了识谱速度和唱谱能力。当前的音乐相关应用软件发展很快,新增了各种乐器的音色,也可以根据乐谱自动播放,但是没有在音色中加入人声。
传统的模拟人声演唱方法部分或全部采用拼接等方式,比如将每个唱名按时间长度和节拍简单拼接,这类方法虽然操作简单,但是结果生硬,与真人演唱差别较大,效果并不十分理想。如何用真实人声演唱乐谱是一个需要解决的问题。
技术实现要素:
本发明提供了一种基于生成对抗网络的虚拟人声视唱方法和系统,能用虚拟人声演唱乐谱,输出的语音节奏流畅自然,从而使得听者在聆听信息时会感觉自然,而不会感到设备的语音输出带有机械感与生涩感。
为了解决上述问题,本发明提供一种基于生成对抗网络的虚拟人声视唱方法,所述方法包括:
步骤一、输入abc记谱法文件和用vocaloid制作的人声唱谱音频,人声唱谱音频与abc文件相对应;
步骤二、将abc文件转化为自定义格式的文本文件,将自定义文本文件和人声音频作为tacotron-2神经网络模型的输入;
步骤三、在tacotron-2神经网络中,输入的文本文件中的字符通过512维的字符嵌入characterembedding表示,而后通过3个卷积层,卷积层的输出再传递到一个双向lstm层中,同时,使用位置敏感注意力locationsensitiveattention使得模型在输入的过程中始终向前移动,tacotron-2神经网络生成的模型即梅尔频谱将作为melgan模型的输入;
步骤四、将tacotron-2神经网络训练好的模型和原始人声音频文件作为melgan生成对抗神经网络模型的输入,通过生成器和鉴别器,最终将会得到特征图featuremap以及合成的人声唱谱音频文件,完成了虚拟人声波形文件的合成;
步骤五、根据场景将相应的音频片段粘合拼接起来,最终将得到一段完整的虚拟人声视唱音乐。
第二方面,本申请实施例提供了一种基于生成对抗网络的虚拟人声视唱系统,所述系统包括:
输入模块,用于输入abc记谱法文件和用vocaloid制作的人声唱谱音频,人声唱谱音频与abc文件相对应;
转换模块,用于将abc文件转化为自定义格式的文本文件,将自定义文本文件和人声音频作为tacotron-2神经网络模型的输入;
处理模块,用于在tacotron-2神经网络中,输入的文本文件中的字符通过512维的字符嵌入characterembedding表示,而后通过3个卷积层,卷积层的输出再传递到一个双向lstm层中,同时,使用位置敏感注意力locationsensitiveattention使得模型在输入的过程中始终向前移动,tacotron-2神经网络生成的模型即梅尔频谱将作为melgan模型的输入,将tacotron-2神经网络训练好的模型和原始人声音频文件作为melgan生成对抗神经网络模型的输入,通过生成器和鉴别器,最终将会得到特征图featuremap以及合成的人声唱谱音频文件,完成了虚拟人声波形文件的合成;
拼接模块,用于根据场景将相应的音频片段粘合拼接起来,最终将得到一段完整的虚拟人声视唱音乐。
第三方面,本申请实施例提供了一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现本申请实施例描述的方法。
第四方面,本申请实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序用于:所述计算机程序被处理器执行时实现如本申请实施例描述的方法。
附图说明
图1是本发明基于生成对抗网络的虚拟人声视唱流程图;
图2是本发明真人唱谱音频波形图;
图3是本发明基于生成对抗网络的虚拟人声视唱框架图。
具体实施方式
为了能够使得本发明的发明目的、技术流程及技术创新点进行更加清晰的阐述,以下结合附图及实例,对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
为达到以上目的,本发明提供了一种基于生成对抗网络的虚拟人声视唱方法。主流程如图3所示,该方法包括:
步骤一、输入abc记谱法文件和用vocaloid制作的人声唱谱音频,人声唱谱音频与abc文件相对应;
步骤二、将abc文件转化为自定义格式的文本文件,将自定义文本文件和人声音频作为tacotron-2神经网络模型的输入;
步骤三、在tacotron-2神经网络中,输入的文本文件中的字符通过512维的字符嵌入characterembedding表示,而后通过3个卷积层,卷积层的输出再传递到一个双向lstm层中,同时,使用位置敏感注意力locationsensitiveattention使得模型在输入的过程中始终向前移动,tacotron-2神经网络生成的模型即梅尔频谱将作为melgan模型的输入;
步骤四、将tacotron-2神经网络训练好的模型和原始人声音频文件作为melgan生成对抗神经网络模型的输入,通过生成器和鉴别器,最终将会得到特征图featuremap以及合成的人声唱谱音频文件,完成了虚拟人声波形文件的合成;
步骤五、根据场景将相应的音频片段粘合拼接起来,最终将得到一段完整的虚拟人声视唱音乐。
优选的,步骤二具体包括:将乐谱信息带入到每一个音符,从而使得乐谱可以像文字一样被神经网络读出来,使用三个关键点:音高、时长和发音来表达乐谱中的音节;用自定义的规则将abc记谱法转化为另一种语言形式化的记谱法,保存在txt文件中,即乐谱语音,生成的文件为乐谱解析文件,乐谱解析文件第一项为音符和音调信息;‘b’表示降半调;‘#’表示升半调;‘r’表示空音,将数字和特殊符号如“#”用纯英文进行代替,具体的,将表示音高的原符号3、4、5分别用n、o、p代替,将表示时长的1/8拍、1/4拍、3/8拍、1/2拍、3/4拍、1拍分别用q、r、s、t、u、v代替,将表示音符的c、c#、d、d#、e、f、f#、g、g#、a、a#、b分别用a、b、c、d、e、f、g、h、i、j、k、l代替。
优选的,步骤三还包括:
使用位置敏感注意力使得模型在输入的过程中始终向前移动,将预测结果通过一个包含2个完全连接层的前置网络pre-net,而后,前置网络的输出和注意力上下文向量attentioncontextvector将传递到2个单向的lstm层,lstm层的输出和注意力上下文向量经过线性投影后,生成梅尔频谱,最后,将预测出的特征结果传递给一个包含5层卷积层的后置网络中,改善总体重建。
优选的,还包括将对抗网络进行改进,具体包括:
在生成器放置一个感应偏差,即音频时间步长之间存在长范围相关性,在每个上采样层之后添加了具有膨胀的剩余块,因此每个后续层的时间远的输出激活具有显著的重叠输入,一堆膨胀卷积层的接收场随层数呈指数增长,增加每个输出时间步骤的诱导接收场,在远距离时间步长的诱导感受场中更大的重叠,导致更好的长程相关性;
使用内核大小作为跨度的倍数,确保膨胀随核大小的增长而增长,以使堆栈的接受场是一个完全平衡和对称树,核大小作为分支因子;
在生成器和鉴别器的所有层中使用权重归一化;
采用具有3个鉴别器d1,d2,d3的多尺度架构,3个鉴别器具有相同的网络结构,在不同的音频尺度上运行,d1以原始音频的规模运行,d2,d3以分别以降频2倍和4倍的原始音频进行运行,下采样使用内核大小为4的跨步平均池执行;选择了基于窗口的鉴别器,因为它们已经被证明可以捕获基本的高频结构,仅需要更少的参数,运行更快,并且可以应用于可变长度的音频序列。
使用特征匹配目标来训练生成器。
作为另一方面,本申请还提供了一种基于生成对抗网络的虚拟人声视唱系统,如图1所示所述系统包括:
输入模块,用于输入abc记谱法文件和用vocaloid制作的人声唱谱音频,人声唱谱音频与abc文件相对应;
转换模块,用于将abc文件转化为自定义格式的文本文件,将自定义文本文件和人声音频作为tacotron-2神经网络模型的输入;
处理模块,用于在tacotron-2神经网络中,输入的文本文件中的字符通过512维的字符嵌入characterembedding表示,而后通过3个卷积层,卷积层的输出再传递到一个双向lstm层中,同时,使用位置敏感注意力locationsensitiveattention使得模型在输入的过程中始终向前移动,tacotron-2神经网络生成的模型即梅尔频谱将作为melgan模型的输入,将tacotron-2神经网络训练好的模型和原始人声音频文件作为melgan生成对抗神经网络模型的输入,通过生成器和鉴别器,最终将会得到特征图featuremap以及合成的人声唱谱音频文件,完成了虚拟人声波形文件的合成;
拼接模块,用于根据场景将相应的音频片段粘合拼接起来,最终将得到一段完整的虚拟人声视唱音乐。
优选的,转换模块还用于:将乐谱信息带入到每一个音符,从而使得乐谱可以像文字一样被神经网络读出来,使用三个关键点:音高、时长和发音来表达乐谱中的音节;
用自定义的规则将abc记谱法转化为另一种语言形式化的记谱法,保存在txt文件中,即乐谱语音,生成的文件为乐谱解析文件,乐谱解析文件第一项为音符和音调信息;‘b’表示降半调;‘#’表示升半调;‘r’表示空音,将数字和特殊符号如“#”用纯英文进行代替,具体的,将表示音高的原符号3、4、5分别用n、o、p代替,将表示时长的1/8拍、1/4拍、3/8拍、1/2拍、3/4拍、1拍分别用q、r、s、t、u、v代替,将表示音符的c、c#、d、d#、e、f、f#、g、g#、a、a#、b分别用a、b、c、d、e、f、g、h、i、j、k、l代替。
优选的,处理模块还用于:
使用位置敏感注意力使得模型在输入的过程中始终向前移动,将预测结果通过一个包含2个完全连接层的前置网络pre-net,而后,前置网络的输出和注意力上下文向量attentioncontextvector将传递到2个单向的lstm层,lstm层的输出和注意力上下文向量经过线性投影后,生成梅尔频谱,最后,将预测出的特征结果传递给一个包含5层卷积层的后置网络中,改善总体重建。
优选的,处理模块还用于:
在生成器放置一个感应偏差,即音频时间步长之间存在长范围相关性,在每个上采样层之后添加了具有膨胀的剩余块,因此每个后续层的时间远的输出激活具有显著的重叠输入,一堆膨胀卷积层的接收场随层数呈指数增长,增加每个输出时间步骤的诱导接收场,在远距离时间步长的诱导感受场中更大的重叠,导致更好的长程相关性;
使用内核大小作为跨度的倍数,确保膨胀随核大小的增长而增长,以使堆栈的接受场是一个完全平衡和对称树,核大小作为分支因子;
在生成器和鉴别器的所有层中使用权重归一化;
采用具有3个鉴别器d1,d2,d3的多尺度架构,3个鉴别器具有相同的网络结构,在不同的音频尺度上运行,d1以原始音频的规模运行,d2,d3以分别以降频2倍和4倍的原始音频进行运行,下采样使用内核大小为4的跨步平均池执行;
使用特征匹配目标来训练生成器。
作为另一方面,本申请还提供了一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如描述于本申请实施例描述的方法。
作为另一方面,本申请还提供了一种计算机可读存储介质,该计算机可读存储介质可以是上述实施例中前述装置中所包含的计算机可读存储介质;也可以是单独存在,未装配入设备中的计算机可读存储介质。计算机可读存储介质存储有一个或者一个以上程序,前述程序被一个或者一个以上的处理器用来执行描述于本申请实施例描述的方法。
应当理解,本申请的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。如,如果用硬件来实现和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(programmablegatearray;以下简称:pga),现场可编程门阵列(fieldprogrammablegatearray;以下简称:fpga)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



