
 商标分类
商标分类  商标转让
商标转让 
一种基于时频域二值掩膜的多通道语音增强方法与流程
 2021-01-28 16:01:24|
2021-01-28 16:01:24| 421|
421| 起点商标网
起点商标网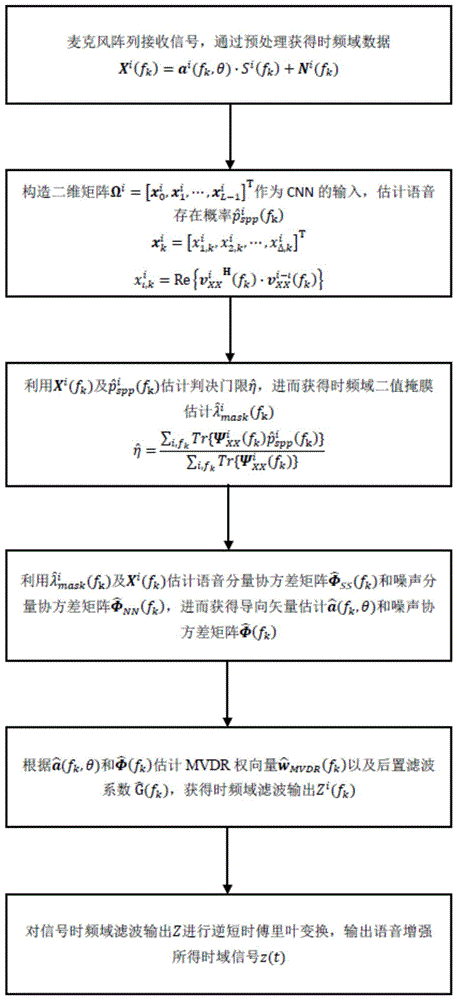
本发明属于波束形成技术,特别涉及时频域二值掩膜估计的多通道语言增强技术。
技术背景
随着模式识别与机器学习的研究与发展,一部分方法被借鉴至语音增强领域,出现了一系列将机器学习和多通道语音增强相结合的语音增强算法。相较于传统的多通道语音增强算法,这些算法通过机器学习模型对接收信号进行特定掩膜估计,进而对波束形成相关参数进行更准确地估计,能够避免对麦克风阵列的空间分布以及目标方向的先验假设,获得更好的语音增强性能。然而机器学习模型种类繁多,语音信号特征复杂,机器学习和多通道语音增强的结合在模型选择、特征选择以及模型输出结果的应用等方面都有待更广泛和深入的探究。因此,研究基于掩膜估计的多通道语音增强问题有重要的意义。
传统的多通道语音增强理论通常假定麦克风阵列的空间分布以及目标方向是确定的,而实际应用中阵列分布可能不确定,且目标方向往往是不确定的。针对阵列分布不确定及目标方向不确定的多通道语音增强问题,t.higuchi,n.ito,t.yoshioka,etal.robustmvdrbeamformingusingtime-frequencymasksforonline/offlineasrinnoise[c].ieeeinternationalconferenceonacoustics.ieee,2016.中公开了一种基于cgmm的(cgmm-based)多通道语音增强算法利用复高斯混合模型(complexgaussianmixturemodel)进行信号时频域后验概率估计,以此作为掩膜估计值计算波束形成相关参数,完成语音增强。掩膜估计值计算波束形成相关参数包括mvdr波束形成器权向量和后置滤波器权系数。受限于模型复杂度,该算法无法对复杂的语音信号时频域特征进行有效的学习。
l.pfeifenberger,m.
步骤包括:
(1)搭建并训网络,接收语音信号,通过预处理后获得语音信号的时频域数据,利用该网络对经过预处理后的时频域数据进行接收信号时频域语音存在概率的估计;
(2)利用接收信号及语音存在概率估计结果估计导向矢量及噪声协方差矩阵;
(3)利用导向矢量及噪声协方差矩阵估计出mvdr波束形成器权向量和后置滤波器权系数,从而进行mvdr波束形成以及后置滤波处理;
(4)通过逆短时傅里叶变换将滤波结果还原为时域信号。
上述方案在接收信号信噪比持续较高或较低的情况下,该算法对波束形成相关参数的估计严重失真,使得语音增强效果下降。
技术实现要素:
本发明所要解决的技术方案是,提供一种在接收语音信号出现信噪比持续较高或较低的情况下,尽可能消除噪声部分对波束形成的影响的一种波束形成参数估计方法。
本发明为解决上述技术问题所采用的技术方案是,一种基于时频域二值掩膜的多通道语音增强方法,包括以下步骤:
1)搭建并训练网络模型,利用阵列接收语音信号,对接收的语音信号进行预处理获得接收的语音信号的时频域数据xi(fk);利用训练完成的网络模型对经过预处理后的时频域数据xi(fk)进行接收信号时频域的语音存在概率
2)利用时频域数据xi(fk)和语音存在概率估计值
其中,
再基于判决门限
3)利用时频域二值掩膜估计
3-1)先利用二值掩膜估计值
若
3-2)利用时频域二值掩膜估计值
若
4)对mvdr波束形成器权向量和后置滤波器权系数进行估计,并完成对时频域数据xi(fk)的滤波:
4-1)若
4-2)若
4-3)若
其中,中间量
滤波结果
5)通过逆短时傅里叶变换将滤波结果还原为时域信号,得到增强后的时域语音信号。
本发明利用时频域二值掩膜估计值对信号时频域是否为语音进行判断,再利用二值掩膜估计值计算语音分量协方差矩阵估计值与噪声分量协方差矩阵估计值,当语音分量协方差矩阵估计值不满秩,则认为这部分接收信号分量全为噪声,为持续低信噪比的情况,直接滤除;当噪声分量协方差矩阵估计值不满秩,则认为这部分接收信号分量全为语音,为持续高信噪比的情况;当语音分量协方差矩阵估计值与噪声分量协方差矩阵估计值均不满秩,则认为这部分接收信号分量不是持续低信噪比或持续高信噪比的情况,根据时频域二值掩膜估计值得到导向矢估计值及噪声协方差矩阵估计值,再根据导向矢估计值及噪声协方差矩阵估计值计算并设置mvdr波束形成器权向量和后置滤波器权系数。
本发明的有益效果是,能对接收信号持续低信噪比或持续高信噪比的情况进行区分,从而尽可能消除噪声部分对波束形成的影响,获得更高的语音增强效果。
附图说明
图1为本发明的流程图;
图2为本算法与cgmm-based算法和dnn-based算法的输出信噪比随输入信噪比变化的比较图;
图3为本算法与cgmm-based算法和dnn-based算法输出信号的主观语音质量评估(perceptualevaluationofspeechquality,pesq)随输入信噪比变化的比较图。
具体实施方式
本发明的基本思想是通过构造一种基于时频域语音存在概率估计值的二值掩膜估计,创造一种新的波束形成参数估计方法,利用二值掩膜估计对信号时频分量进行分类,尽可能消除噪声部分对波束形成的影响。
实施例步骤如图1所示:
步骤1、根据语音信号数据生成卷积神经网络cnn输入特征,估计语音存在概率。
假设时频域接收信号为:
xi(fk)=ai(fk,θ)·si(fk)+ni(fk)
其中si(fk)为第i帧频率为fk的声源信号分量,ai(fk,θ)∈cm×1表示阵列对fk频率信号的导向矢量,ni(fk)∈cm×1为零均值加性高斯白噪声在第i帧fk频率处的噪声分量,m为麦克风阵元数量。
令
对其做特征分解,用主特征向量
其中l为信号帧数,
cnn模型由六层卷积层与三层池化层外加一层全连接层构成,其中每两层卷积层后连接一层池化层以压缩二维数据量,重复三次后最后连接全连接层,获得一维输出语音存在概率估计
cnn的训练以训练集数据计算得到ωi作为输入特征,标签(lable)为对应的时频域语音存在概率理论值序列
步骤2、利用接收信号及语音存在概率估计结果计算判决门限
设置判决门限为语音分量平均功率与接收信号平均功率的比值,即:
其中,
其中,m为阵元数,tr{·}表示求迹,
综上,二值掩膜判决门限估计
利用语音存在概率估计结果
步骤3、利用时频域二值掩膜估计导向矢量
利用二值掩膜估计值
若
利用二值掩膜估计值
若
步骤4、利用两项参数估计结果进行mvdr波束形成以及后置滤波处理。
根据最小均方误差准则,多通道维纳滤波可分解为一个mvdr波束形成器与一个单通道后置滤波器的级联,即:
其中,wmvdr为mvdr波束形成器权向量,即:
g为后置滤波器权系数:
其中,
估计mvdr滤波器权向量
根据步骤3所得结果,若
后置滤波器权系数估计:
滤波所得zi(fk)=0。
若
后置滤波器权系数估计:
滤波所得
若
后置滤波器权系数估计:
其中,
滤波所得
步骤5、通过逆短时傅里叶变换将时频域滤波结果zi(fk)还原为时域信号z(t)。
根据步骤4对接收信号时频域所有分量进行滤波可得:
其中γ为该段语音的帧数,l为窄带频段数。
对z进行逆短时傅里叶变换,即将其每帧信号进行逆傅里叶变换:
zp=[z(tp),z(tp+1),...,z(tp+l-1)]
其中tp为该帧时域信号的起始时刻,z(tp+i)为:
将所有zp进行拼接合并,得到增强后的时域语音信号z(t)。
如图2所示,在-5db到10db输入信噪比环境下,本算法所得语音增强输出信噪比始终高于cgmm-based算法和dnn-based算法。图3显示在同样的输入信噪比环境下,本算法所得语音增强结果相较于cgmm-based算法和dnn-based算法同样有明显较高的pesq得分。图2及图3的结果显示本算法相较于两种对比算法具有较明显的语音增强性能提升。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



