
 商标分类
商标分类  商标转让
商标转让 
一种声纹识别的特征参数提取系统及方法与流程
 2021-01-28 16:01:52|
2021-01-28 16:01:52| 287|
287| 起点商标网
起点商标网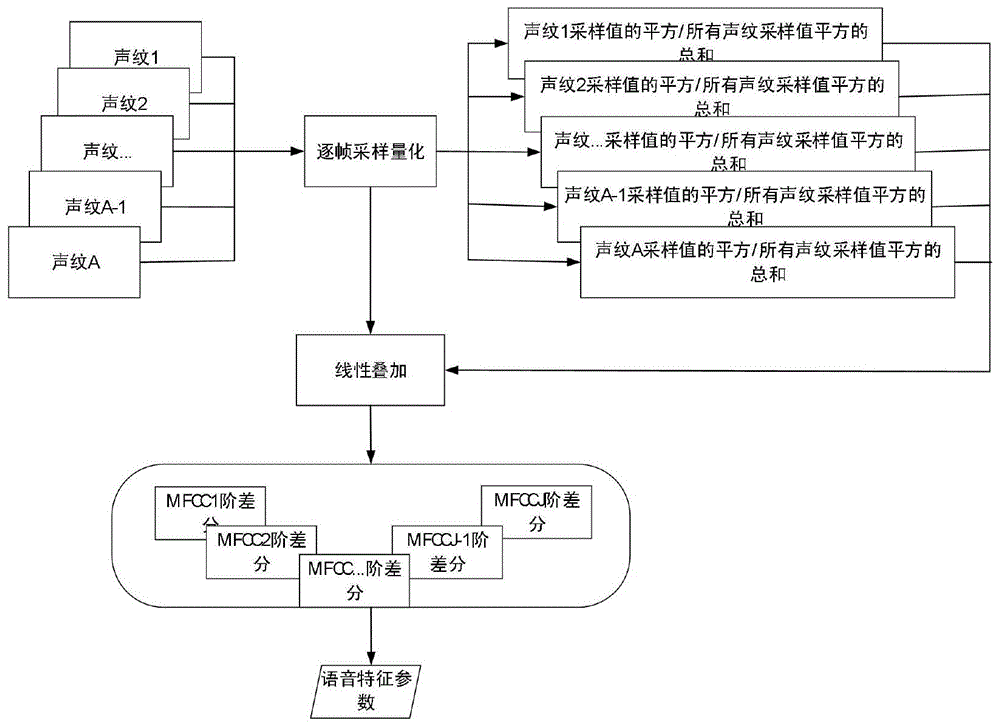
本发明涉及语音识别技术领域,具体为一种声纹识别的特征参数提取系统及方法。
背景技术:
随着信息技术的快速发展,个人身份信息的安全性越来越重要,为了有效的验证个人身份信息,人类的生物特征信息包括声纹特征信息、指纹特征信息、人脸特征信息、虹膜特征信息等认证技术得到了快速发展,然而其中的声纹特征信息凭借着简单、便捷、准确等特点,作为人脸自然身份属性之一,其在身份识别、信息安全等领域受到越来越多的关注。声纹识别技术是通过对声音特征信息进行提取并结合特征模式相似性匹配的一项技术,其中声纹特征信息提取,即是提取出声音信号频率中能够唯一展现出该声音的个性特征参数,因此在进行声纹识别过程中,有效的提取声纹特征信息,直接决定着声纹识别的精度性、时效性。
“声纹”这个概念首次被bell实验室提出,使得声音识别技术得到了初步发展,紧接着s.pruzansky等人提出了将模式匹配结合概率统计对声音进行特种分析识别,实现对声音的辨别;随着声纹识别技术的发展,作为声音的个性化特征参数的提取技术得到了快速发展,如基于人耳听觉特性的梅尔倒谱参数的提出使得声纹识别技术迈入了新的篇章。然而国内关于声纹识别技术研究的起点较缓慢,目前中国的各大高校也逐渐的扩展声纹识别技术领域。
由于声纹识别过程中,声音信号频率本身具有随机性,如声音的快慢、声音的音调高低、共振峰的变化等因素,使得声音的极易受到外界噪声的干扰,而且当声音信号在传播过程中,极易受到信道的干扰,使得声音信号的频率谱发生变化,从而导致提取的声纹特征信息出现不稳定性。
基于此,本发明提出了一种声纹识别的特征参数提取系统及方法。
技术实现要素:
本发明的目的在于提供一种声纹识别的特征参数提取系统及方法,以解决上述背景技术中的问题。
为实现上述目的,本发明提供如下技术方案:一种声纹识别的特征参数提取系统,该系统包括有同步控制器、麦克风阵列和计算机,所述同步控制器通过电缆与计算机进行连接,所述麦克风阵列通过电缆与计算机进行连接。
优选的,同步控制器的型号为百灵达bcd3000。
一种声纹识别的特征参数提取方法,包含以下步骤:
s1、利用同步控制器同时控制a个麦克风构成的麦克风阵列进行多路信号的采集,得到a个声纹信号,分别为声纹信号v1,v2…,va;
s2、针对声纹信号vn,其中1≤n≤a,其经过采样后的声纹信号在第t个采样点时刻的信号为vn(t),为了提升采样信号的数据的有效性,根据公式:vn‘(t)=vn(t)-0.96*vn(t-1)t≥2;
vn‘(t)=vn(t)t=1;
对声纹信号进行预处理,得到处理后的声纹信号用vn‘(t)表示;
s3、由于采集到的声纹信号是非平稳分布,但是声纹信号其在短时间p内,其语音特征信息具有平稳性,语音信号的大小l一般远高于短时间p,以短时间p的语音段对采集的语音信号进行分段处理,得到m=l/p个语音帧,称这m个语音帧为分析处理帧,为了防止吉布斯效应以及保持语音信号处理的连续性,需保持各个分析处理帧之间具有重叠部分,其中重叠部分一般取值为短时间p的1/2或者1/3,定义下式的窗口函数win(t)对语音信号进行平滑的移动处理,其中n表示窗口的长度,对预加重处理后的信号vn‘(t)进行加窗处理以后得到vn‘’(t)=vn‘(t)*win(t),其中:
s4、a个声纹信号进行加窗处理以后进行线性叠加处理,也即是对第n个采样声纹信号进行vn”’(t)=(vn”(t))2/sum;其中sum=(v1”(t))2+(v2”(t))2+…(va’(t))2,再对处理的声纹信号vn”’(t)进行叠加处理,也即是f(t)=b1*v1”’(t)+b2*v2”’(t)+···ba*va”’(t);
s5、对声纹信号线性叠加后的时域信号f(t)利用公式:
进行快速傅立叶变换,得到语音信号的频谱y(k);
s6、对语音信号频谱y(k)进行频谱转换到mel域上的频谱,也即是利用mel滤波器对其进行转换处理,设mel滤波器具有m个三角带通滤波器,其对应的中心频率为h(m),m=1,2,…m,其值为:h(m)=(n/s)*q-1(q(hl)+m*((q(hh)-q(hl))/(m+1)));而q-1(x)=700*(e(x-1125)-1),其中s为采样频率,q(hl)和q(hh)分别为mel滤波器组内的最低频率和最高频率,通过中心频率为h(m),定义每个m个三角带通滤波器的传递函数fbm(k),当h(m)<k<=h(m+1)时,fbm(k)=(h(m+1)-k)/(h(m+1)-h(m));当h(m-1)<=k<=h(m)时,fbm(k)=(k-h(m-1))/(h(m)-h(m-1));当h(m-1)<k或者k<h(m-1)时,fbm(k)=0;
s7、为了减少噪声以及频率谱估计误差造成的干扰,对mel频率谱进行对数能量处理,也即是用
s8、通过对mel频率谱中的对数能量s(m)进行离散余弦变换,其中采用
s9、对mel频率谱系数进行j阶差分处理,也即是当i<j时,gi=d(i+1)-d(i);当i>=t-j时,gi=d(i)-d(i)+1;当i>j或者i<t-j时,
优选的,s1中,为了保持采集的信号的完整性,采样频率取大于语音信号的最高频率的两倍,本发明采用逐帧采样等间隔抽样方式,其中采样频率为8khz,量化幅度为8bit。
与现有技术相比,本发明的有益效果是:本发明中采样频率取大于语音信号的最高频率的两倍,保住了采集信号的完整性,通过对采样的语音信号进行预加重处理,有效的提高了语音信号的高频信息,通过对mel频率谱进行对数能量处理,能够有效减少噪声以及频率谱估计误差造成的干扰,通过对mel频率谱中的对数能量进行离散余弦变换,可以使得得到的语音特征向量之间具有独立性,同时也能够减少语音特征参数的维度,本发明能够使得提取的声纹特征信息更加稳定可靠,使得识别正确率得到提高。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为纹识别的特征参数提取框架图;
图2为声纹识别的特征参数提取所需设备结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明提供一种技术方案:本发明提供如下技术方案一种声纹识别的特征参数提取系统,该系统包括有同步控制器1、麦克风阵列2和计算机3,同步控制器1通过电缆与计算机3进行连接,麦克风阵列2通过电缆与计算机3进行连接。
进一步的,同步控制器1的型号为百灵达bcd3000。
一种声纹识别的特征参数提取方法,包含以下步骤:
步骤1、利用同步控制器同时控制a个麦克风构成的麦克风阵列进行多路信号的采集,为了保持采集的信号的完整性,采样频率取大于语音信号的最高频率的两倍,本发明采用逐帧采样等间隔抽样方式,其中采样频率为8khz,量化幅度为8bit,得到a个声纹信号,分别为声纹信号v1,v2…,va;
步骤2、针对声纹信号vn,其中1≤n≤a,其经过采样后的声纹信号在第t个采样点时刻的信号为vn(t),为了提升采样信号的数据的有效性,根据公式:vn‘(t)=vn(t)-0.96*vn(t-1)t≥2;
vn‘(t)=vn(t)t=1;
对声纹信号进行预处理,得到处理后的声纹信号用vn‘(t)表示;
步骤3、由于采集到的声纹信号是非平稳分布,但是声纹信号其在短时间p内,其语音特征信息具有平稳性,语音信号的大小l一般远高于短时间p,本发明取p为20ms,以短时间p的语音段对采集的语音信号进行分段处理,得到m=l/p个语音帧,称这m个语音帧为分析处理帧,为了防止吉布斯效应以及保持语音信号处理的连续性,需保持各个分析处理帧之间具有重叠部分,其中重叠部分一般取值为短时间p的1/2或者1/3,本发明中的采用的重叠部分为10。定义下式的窗口函数win(t)对语音信号进行平滑的移动处理,其中n表示窗口的长度,本发明取值为20。对预加重处理后的信号vn‘(t)进行加窗处理以后得到vn‘’(t)=vn‘(t)*win(t),其中:
步骤4、a个声纹信号进行加窗处理以后进行线性叠加处理,也即是对第n个采样声纹信号进行vn”’(t)=(vn”(t))2/sum;其中sum=(v1”(t))2+(v2”(t))2+…(va’(t))2,再对处理的声纹信号vn”’(t)进行叠加处理,也即是f(t)=b1*v1”’(t)+b2*v2”’(t)+···ba*va”’(t);
步骤5、对声纹信号线性叠加后的时域信号f(t)利用公式:
进行快速傅立叶变换,得到语音信号的频谱y(k);
步骤6、对语音信号频谱y(k)进行频谱转换到mel域上的频谱,也即是利用mel滤波器对其进行转换处理,设mel滤波器具有m个三角带通滤波器(本发明取m为15),其对应的中心频率为h(m),m=1,2,.…m,其值为:h(m)=(n/s)*q-1(q(hl)+m*((q(hh)-q(hl))/(m+1)));而q-1(x)=700*(e(x-1125)-1),其中s为采样频率(s=8khz),q(hl)和q(hh)分别为mel滤波器组内的最低频率和最高频率,通过中心频率为h(m),定义每个m个三角带通滤波器的传递函数fbm(k),当h(m)<k<=h(m+1)时,fbm(k)=(h(m+1)-k)/(h(m+1)-h(m));当h(m-1)<=k<=h(m)时,fbm(k)=(k-h(m-1))/(h(m)-h(m-1));当h(m-1)<k或者k<h(m-1)时,fbm(k)=0;
步骤7、为了减少噪声以及频率谱估计误差造成的干扰,对mel频率谱进行对数能量处理,也即是用
步骤8、通过对mel频率谱中的对数能量s(m)进行离散余弦变换,其中采用
步骤9、对mel频率谱系数进行j阶差分处理(本发明取j=4),也即是当i<j时,gi=d(i+1)-d(i);当i>=t-j时,gi=d(i)-d(i)+1;当i>j或者i<t-j时,
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



