
 商标分类
商标分类  商标转让
商标转让 
语音活性检测方法和装置与流程
 2021-01-28 16:01:55|
2021-01-28 16:01:55| 291|
291| 起点商标网
起点商标网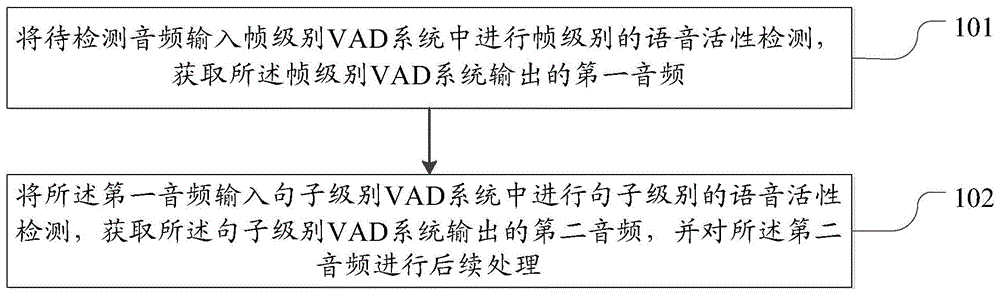
本发明属于语音识别技术领域,尤其涉及语音活性检测方法和装置。
背景技术:
语音活性检测(voiceactivitydetection,vad),也称为speechactivitydetectionorspeechdetection,是一项用于语音处理的技术,目的是检测语音信号是否存在。vad技术主要用于语音编码和语音识别。它可以简化语音处理,也可用于在音频会话期间去除非语音片段:可以在ip电话应用中避免对静音数据包的编码和传输,节省计算时间和带宽。
vad技术使得一些列基于语音的应用程序成为现实。因此,有一系列的vad算法,具有不同的特性和延迟时间、灵敏度、精度和计算成本。有些vad算法也提供了进一步的分析,例如讲话是否浊音、清音或持续。语音活动检测通常是与语言无关的。
vad技术首先被用于时分语言内插法(time-assignmentspeechinterpolation/tasi)系统。
基于传统声学特征如短时能量、频谱能量、过零率等或基于神经网络提取的特征来进行语音活动检测,对每一帧音频都给出是否是语音的判定。这种方法在信噪比较高时拥有很好的性能。
技术实现要素:
本发明实施例提供一种语音活性检测方法及装置,用于至少解决上述技术问题之一。
第一方面,本发明实施例提供一种语音活性检测方法,包括:将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
第二方面,本发明实施例提供一种语音活性检测装置,包括:第一输入检测输出模块,配置为将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;第二输入检测输出模块,配置为将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
第三方面,提供一种计算机程序产品,所述计算机程序产品包括存储在非易失性计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,使所述计算机执行第一方面所述的语音活性检测方法的步骤。
第四方面,本发明实施例还提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行第一方面所述方法的步骤。
本申请实施例提供的方法通过在已有的帧级别vad系统之后附加一个句子级的vad系统,可以实现对前一个系统判定为语音的音频进行进一步的整句级的判定,减少音频的误判定,提高了非语音段的召回率,进一步的节省了后端识别的资源。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一实施例提供的一种语音活性检测方法的流程图;
图2为本发明一实施例提供的另一种语音活性检测方法的流程图;
图3为本发明实施例的语音活性检测的方案一具体实施例的句子级语音活动检测系统的框架图;
图4为本发明实施例的语音活性检测的方案一具体实施例的用于提供原始音频的分类流程图;
图5为本发明一实施例提供的一种语音活性检测装置的框图;
图6为本发明一实施例提供的电子设备的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,其示出了本发明的一种语音活性检测方法的一实施例的流程图。
如图1所示,在步骤101中,将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;
在步骤102中,将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
在本实施例中,对于步骤101,语音活性检测装置将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取帧级别vad系统输出的第一音频,其中,在做帧级别的vad的时候,是基于fsmn(前馈顺序存储网络,feed-forwardsequentialmemorynetwork)模型,其中,fsmn模型使用了在线fsmn模型和离线fsmn模型,在线fsmn模型只向前看几帧,不向后看,也就是只用到了历史的信息没有用未来的信息,离线fsmn模型不仅可以向前看,含可以向后看几帧,用到了历史信息还用到了未来的信息,例如,在获取到待检测音频后,将待检测音频经过特征处理送入帧级别vad系统进行筛选,获取帧级别vad系统判定为语音的第一音频。
对于步骤102,语音活性检测装置将第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取句子级别vad系统输出的第二音频,并对第二音频进行后续处理,例如,将帧级别vad系统判定为语音的第一音频先做提取特征处理,再经过离线fsmn层、通过dnn(深度神经网络),给出最终的第二音频。
在本实施例的方案中,通过在已有的帧级别vad系统之后附加一个句子级的vad系统,可以实现对前一个系统判定为语音的音频进行进一步的整句级的判定,减少音频的误判定,提高了非语音段的召回率,进一步的节省了后端识别的资源。
请参考图2,其示出了本发明一实施例提供的另一种语音活性检测方法的流程图,该流程图主要是针对流程图图1中步骤102“将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测”进一步限定的步骤的流程图。
如图2所示,在步骤201中,将所述第一音频切分成多段音频,利用所述句子级别vad系统分别对所述多段音频进行语音活性检测;
在步骤202中,若检测到所述多段音频中任一段音频中包含语音,将所述第一音频整段输出。
在本实施例中,对于步骤201,语音活性检测装置将帧级别vad系统判定为语音的第一音频切分成多段音频,利用句子级别vad系统分别对多段音频进行语音活性检测,例如,一段音频为“*你*好**小*驰”。其中,*是噪音部分,你好小驰是用户语音部分,语音活性检测装置将其切分成多段音频,例如,**你*、好**、小驰*,再利用句子级别vad系统分别对**你*、好**、小驰*进行语音活性检测,其中,音频可以按照一个确切的时间或者长度来切分成段,例如,一个音频长度特别短的可以不用把音频切分,而音频长度特别长的可以把音频切分成更多的分段,本申请在此没有限制。
对于步骤202,语音活性检测装置若检测到所述多段音频中任一段音频中包含语音,将所述第一音频整段输出,例如,检测到将切分成音频段的**你*、好**、小驰*中的任一分段中包含语音,例如,检测到“**你”这一分段音频中包含语音,则停止其他分段的检测,直接判定为整段音频中包含语音,然后将整段音频输出。
在本实施例的方案中,通过对一整条音频切分成段,分别对每段进行判定,只要有一个分段判定是语音,便认为该条音频含语音,可以省去音频剩下的分段的判定。
在一些可选的实施例中,所述帧级别vad系统用于判断待检测音频中每一帧音频是否为语音帧,输出所述待检测音频中判定为语音帧的音频构成的第一音频;若判断所述待检测音频中不包含语音帧,则不进行后续处理。
在一些可选的实施例中,所述句子级别vad系统用于判断所述第一音频整句是否为语音,若是,则将所述第一音频输入只语音识别系统进行语音识别;若否,则不进行后续处理。
在一些可选的实施例中,所述句子级别vad系统为基于fsmn的模型,所述基于fsmn(前馈顺序记忆网络,feed-forwardsequentialmemorynetwork)的模型包括特征提取层、多个离线fsmn层和dnn层。
在上述实施例所述的方法中,所述帧级别vad系统也为基于fsmn的模型。
需要说明的是,以上实施例中虽然采用了步骤101、步骤102等具有明确先后顺序的数字,限定了步骤的先后顺序,但是在实际的应用场景中,有些步骤是可以并列执行的,有些步骤的先后顺序也不受到以上数字的限定,本申请在此没有限制,在此不再赘述。
下面对通过描述发明人在实现本发明的过程中遇到的一些问题和对最终确定的方案的一个具体实施例进行说明,以使本领域技术人员更好地理解本申请的方案。
发明人在实现本发明的过程中发现这些相似技术的缺陷:
信噪比较低、背景噪声较大时,系统容易将非语音片段判定为语音片段,送到后端识别系统,造成资源的浪费。
asr识别系统一般是基于vad来控制音频的输入和输出,一旦vad控制的不够好,会把噪音音频或其他非人声音频送进识别系统,会造成误触发识别,识别结果混乱或者是误触发识别这个动作,尤其是在交互场景中,整个系统一直在不停的打断,并等待客户输入,对客户体验很不好。
对每一帧音频都进行判定,持续时间太短,给出的结果局部性太强,无法对整句进行准确的判断。
发明人在实现本发明的过程中发现为什么不容易想到原因:
通常会采用调高门限的方法,简单直接,或者是找反例数据去训练,降低模型的误触发概率。
想不到本方案的原因:没有考虑到将解决方案与已有的vad系统剥离开,一直在已有的帧级别系统上进行改进,很难有实质性的改善。
本申请实施例的方案通过以下方案解决上述现有技术中存在的技术问题:
通过在已有的帧级别vad系统之后,附加一个句子级的vad系统,对前一个系统判定为语音的音频进行进一步的整句级的判定,减少非语音段错误流向后端识别。
本发明的技术创新点:
图3是句子级语音活动检测系统的框架图。
图4是用于提供原始音频的分类流程图。
对于图3,系统的输入是经过帧级别vad系统筛选过的音频(即帧级别vad系统判定为语音的音频),对该音频进行提取特征、经过离线fsmn层、再通过dnn,给出最后结果。
对于图4,流程图展示了句子级vad系统与帧级别vad系统的关系。
发明人在实现本发明的过程中发现的备用方案:
利用svm和dnn做分类器来对音频进行分类,它们的优点是系统易搭建、分类速度快,缺点是模型的表达能力不强,在测试集上的表现不好,放弃;
针对系统的输入,最开始的输入是整条音频,即一条音频只做一次是否是语音的判定,这种方法的优点是对于全局性来说是最好的,缺点是满足不了线上流式数据的实时性,会带来严重的滞后。所以后来改成分段式判定,即将一整条音频分成几段,分别对每段进行判定,并且只要有一段判定是语音,便认为该条音频含语音,可省去音频剩下的段的判定。
在做帧级别的vad的时候,我们也是基于fsmn的模型,不仅使用了在线fsmn模型(即fsmn只向前看几帧,不向后看,只用了历史的信息,没有用未来的信息),而且使用了离线的fsmn模型,(即fsmn不仅可以向前看,还可以向后看几帧,用到了历史和未来的信息),离线的fsmn模型,虽然延迟比在线的要差,但是性能上比在线的好很多。所以,如果遇到不考虑延时的场景,我们可以把离线的fsmn训出来的vad用起来。
发明人在实现本发明的过程中发现达到更深层次的效果:
本方案最直接的效果就是减少了音频的误判定,提高了非语音段的召回率;进一步的节省了后端识别的资源;提高了整个语音识别系统对于噪声的鲁棒性;提高了用户的使用体验,由于之前会有非语音段流到识别系统,识别出的结果往往是些无意义的“嗯、啊”或者null,在语音交互系统中,往往会被这些误识别造成误打断,会明显降低用户的体验感受。
请参考图5,其示出了本发明一实施例提供的一种语音活性检测装置的框图。
如图5所示,第一输入检测输出模块510和第二输入检测输出模块520。
其中,第一输入检测输出模块510,配置为将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;第二输入检测输出模块520,配置为将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
应当理解,图5中记载的诸模块与参考图1和图2中描述的方法中的各个步骤相对应。由此,上文针对方法描述的操作和特征以及相应的技术效果同样适用于图5中的诸模块,在此不再赘述。
值得注意的是,本申请的实施例中的模块并不用于限制本申请的方案,例如第一输入检测输出模块可以描述为将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频的模块,另外,还可以通过硬件处理器来实现相关功能模块,例如第一输入检测输出模块可以用处理器实现,在此不再赘述。
在另一些实施例中,本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的语音活性检测方法;
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;
将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据语音活性检测装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至语音活性检测装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
本发明实施例还提供一种计算机程序产品,计算机程序产品包括存储在非易失性计算机可读存储介质上的计算机程序,计算机程序包括程序指令,当程序指令被计算机执行时,使计算机执行上述任一项语音活性检测方法。
图6是本发明实施例提供的电子设备的结构示意图,如图6所示,该设备包括:一个或多个处理器610以及存储器620,图6中以一个处理器610为例。用于语音活性检测方法的设备还可以包括:输入装置630和输出装置640。处理器610、存储器620、输入装置630和输出装置640可以通过总线或者其他方式连接,图6中以通过总线连接为例。存储器620为上述的非易失性计算机可读存储介质。处理器610通过运行存储在存储器620中的非易失性软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例用于语音活性检测装置方法。输入装置630可接收输入的数字或字符信息,以及产生与用于语音活性检测装置的用户设置以及功能控制有关的键信号输入。输出装置640可包括显示屏等显示设备。
上述产品可执行本发明实施例所提供的方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明实施例所提供的方法。
作为一种实施方式,上述电子设备应用于语音活性检测装置中,包括:
至少一个处理器;以及,与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够:
将待检测音频输入帧级别vad系统中进行帧级别的语音活性检测,获取所述帧级别vad系统输出的第一音频;
将所述第一音频输入句子级别vad系统中进行句子级别的语音活性检测,获取所述句子级别vad系统输出的第二音频,并对所述第二音频进行后续处理。
本申请实施例的电子设备以多种形式存在,包括但不限于:
(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机、多媒体手机、功能性手机,以及低端手机等。
(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:pda、mid和umpc设备等。
(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器,掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
(4)服务器:提供计算服务的设备,服务器的构成包括处理器、硬盘、内存、系统总线等,服务器和通用的计算机架构类似,但是由于需要提供高可靠的服务,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高。
(5)其他具有数据交互功能的电子装置。
以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



