
 商标分类
商标分类  商标转让
商标转让 
智能会议记录系统的制作方法
 2021-01-28 16:01:37|
2021-01-28 16:01:37| 321|
321| 起点商标网
起点商标网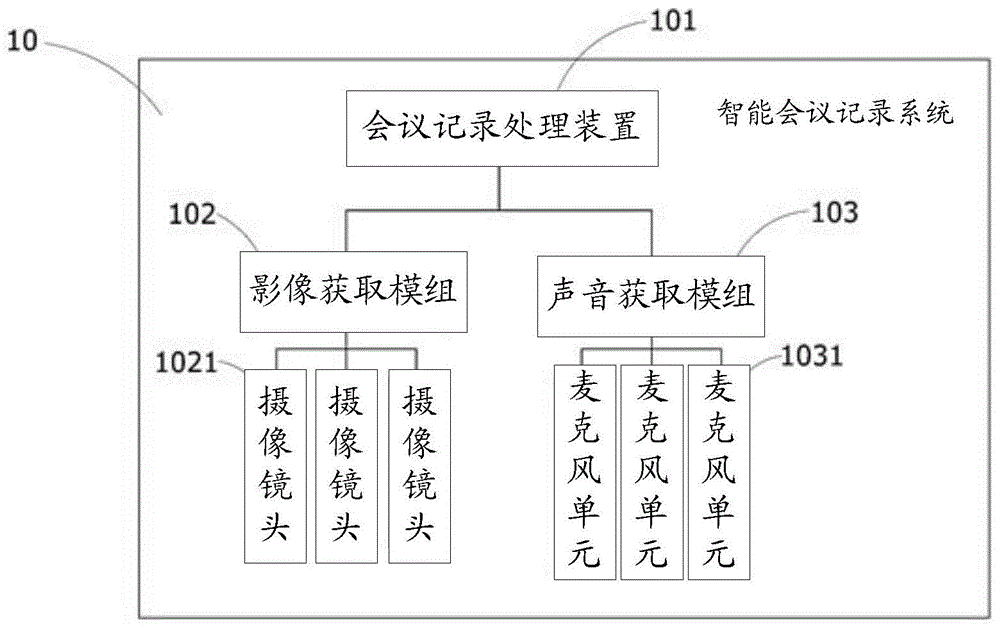
本实用新型涉及一种智能会议记录系统,尤指通过一影像获取模组及一声音获取模组识别出会议中发言人位置后,并将其声音信息编码为文字的会议纪录档案。
背景技术:
过去会议记录方式主要以人工方式,于会议现场即时编辑出文字形式的会议纪录稿,然而,此方式容易因打字人员听漏信息,而造成会议记录不完整,因此,采取人工方式的会议记录手段者,通常打字人员会搭配录音设备,于会议结束后,听取录音档案并打出逐字稿,这个作法容易因不同发言人语调过于近似,而造成打字人员无法识别出谁是真正的发言人,因此也会造成会议记录错误或不完整,拜电脑应用程式便捷之赐,已有应用程式通过语音转文字识别(speechtotext,stt)技术,将语音档案编码为文字档案,以省去会议中打字人员不必要的人力支援,然而,目前语音转文字识别技术仍无法自动识别出发言人身份,最后产出的会议纪录仍需以人工方式校阅,以及在每一段谈话开头标注发言人身份,具此,目前应用在会议记录编辑的技术,仍无法提供完善的解决方案。
技术实现要素:
有鉴于上述的问题,本申请人依据多年来从事相关行业的经验,针对会议记录系统进行研发;缘此,本申请的主要目的在于提供一种可通过语音及影像双重确认发言人身份的智能会议记录系统。
为达上述的目的,本申请的智能会议记录系统,其包含有一会议记录装置一影像获取模组及一声音获取模组,前述的装置设置于会议环境之中,启动智能会议记录系统,所述的声音获取模组可识别数笔不同方向获取到的声音讯号,从多笔声音讯号中识别出一第一音源和一第二音源,其中第一音源为背景杂讯、第二音源为发言人谈话内容,又,影像获取模组将一环景影像传送至会议记录装置进行人脸识别后,会议记录装置通过第二音源及人脸识别双重确认发言人身份后,会议记录装置即可将第二音源编码为文字记载形式的会议纪录档案,据此,本申请通过影像及音讯进行发言人身份的双重比对,使会议纪录档案中所记录的每一段谈话内容,都可以对应到正确的发言人身份,并且,会议记录装置仅需编码第二音讯的内容,可大幅降低会议记录装置的运算负担、及提高会议记录的完整性与正确性。
为使贵审查委员得以清楚了解本申请的目的、技术特征及其实施后的功效,兹以下列说明搭配图示进行说明,敬请参阅。
附图说明
图1为本申请的系统组成示意图;
图2为会议纪录处理装置组成示意图;
图3为本申请的实施示意图(一);
图4为本申请的实施示意图(二);
图5为本申请的实施示意图(三);
图6为本申请的另一实施例(一);
图7为本申请的另一实施例(二);
图8为本申请的另一实施例(三);
图9为本申请的另一实施例(四)。
具体实施方式
请参阅「图1」,图中所示为本申请的系统组成示意图,如图,本申请的智能会议记录系统10,其包含有:一会议纪录处理装置101、一影像获取模组102及一声音获取装置103,所述的会议纪录处理装置101与影像获取模组102及声音获取装置103完成信息连接,其中,会议纪录处理装置101可控制影像获取模组102及声音获取装置103,又,会议纪录处理装置101可对一具有深度信息的环景影像进行分析,以对环景影像进行人脸识别及标注,并且会议纪录处理装置101可获取发言人员的一声音讯号,将声音讯号经过语音识别技术转化为一文字纪录信息,并对文字纪录信息进行标注及编辑为一会议纪录档案,进而将发言人员姓名可标注于每一段讲稿上以供查询;所述的影像获取模组102设置于会议环境之中,其可以为环景摄影机,包含有数个不同摄像方向的摄像镜头1021,并且可进一步将各个摄像镜头1021所获取到的影像合成为环景影像,使环景影像的影像范围可涵盖整个会议环境,再者,影像获取模组102所获取的环景影像更包含有一深度信息;所述的声音获取装置103设置于会议环境之中,其可以为阵列式麦克风,声音获取装置103包含有数个不同收音方向的麦克风单元1031,各该麦克风单元1031可获取不同方向的一声音讯号,再者,声音获取装置103可侦测各笔声音讯号的强度,依据强度判断为一第一音源或一第二音源,其中,所述的第一音源为一背景杂讯,所述的第二音源为一人声音讯,人声音讯特别是指发言人员的声音讯息,其中,声音获取装置103可依据一音量强度或一音频范围作为判断,再者,当声音获取装置103判断出第二音源时,可进一步过滤或屏蔽第一音源,即调整被判定为第一音源的麦克风讯号,使第二音源可不受第一音源干扰,并且声音获取装置103也可将运算资源集中在处理第二音源,再者,被判定为第一音源的麦克风设备仍有获取到第二音源,因此声音获取装置103过滤或屏蔽第一音源时,接收第一音源的麦克风设备仍正常运行并持续获取声音讯号;又,影像获取模组102及声音获取装置103也可以组设于会议纪录处理装置101,使影像获取模组102及声音获取装置103可于同一位置,同步获取环景影像及声音讯号。
请参阅「图2」,图中所示为会议纪录处理装置组成示意图,如图,本申请的会议纪录处理装置101,具有一中央处理模组1011,另有一资料储存模组1012、一空间识别模组1013、一影像处理模组1014、一语音处理模组1015与中央处理模组1011完成信息连接,其中:
(1)所述的中央处理模组1011,供以运行会议纪录处理装置101及驱动上述各模组的作动,并具备逻辑运算、暂存运算结果、保存执行指令位置等功能,且其可为一中央处理器(centralprocessingunit,cpu)或一微控制器(microcontrollerunit,mcu);
(2)所述的资料储存模组1012为资料储存元件,例如半导体记忆体等的固态记忆体、一硬碟机(harddiskdrive,hdd)或一固态硬碟机(solidstatedrive,ssd)等可储存电子资料的装置,再者,资料储存模组1012更包含有一人脸识别资料库10121、一人员资料库10122、一会议纪录资料库10123和一影音资料库10124,其中,所述的人脸识别资料库10121可供以储存至少一笔人脸识别资讯信息,所述的人脸识别资讯信息可对应于与会人员,包含有脸部轮廓资料,其可以通过使用者预先载入与更新;所述的人员资料库10122储存有至少一人员信息,且每一笔人员信息可分别与其中一笔人脸识别资讯信息相对应,使每一位与会人员皆储存有一笔相关联的人员信息与人脸识别资讯信息,再者,人员信息可包含有姓名、头衔、年龄或联络资料的其中一种或其组合,其可以通过使用者预先载入与更新;所述的会议纪录资料库10123可供以一会议纪录档案;所述的影音资料库10124供以储存或暂存环景影像、标注信息、及声音讯号;
(3)所述的空间识别模组1013可基于环景影像的深度信息产生一三维座标信息,于三维座标中可定位出各个与会者的位置及第二音源的方位;
(4)所述的影像处理模组1014具有一人脸识别单元10141,所述的人脸识别单元10141可从环景影像中进行人脸识别程序,捕捉环景影像中的一人脸影像,并将人脸影像与人脸识别资讯信息进行比对,进而识别出各个与会者身份,其中,所述的人脸识别作业可通过机器学习或深度学习进行影像比对,例如人脸识别单元10141可基于卷积神经网路(convolutionalneuralnetwork,cnn)进行人脸识别训练,更进一步例如使用fasterrcnn(fasterregion-basedconvolutionalneuralnetwork)的卷积神经网路进行人脸识别训练,并且可通过随机梯度下降演算法(stochasticgradientdescent,sgd)进行迭代训练,又,完成人脸识别作业后,影像处理模组1014可以在所识别出的各个人脸影像周围区域进行标注,其中,影像处理模组1014可将人员信息标注于影像画面,其中,标注的信息可以为一文字、一图像和一条码其中一种或其组合,更进一步说明,影像处理模组1014可于影像中产生至少一标注区块,影像处理模组1014可于标注区块加入标注的信息,又,影像处理模组1014更可以基于第二音源的位置(即发言人位置),比对环景影像的三维座标信息,藉此以识别及所定发言人员,并于发言人员的标注区块中标注为发言人员;
(5)所述的语音处理模组1015可将声音讯号转换为文字纪录信息,特别指声音获取装置103判断为第二音源的声音讯号,其中,语音处理模组1015具有一语音资料库10151,语音资料库10151储存有至少一笔语音分析资料,语音处理模组1015可获取一段声音讯号,并比对于语音分析资料,使语音处理模组1015可将声音讯号编码为文字纪录信息,其中,语音处理模组1015是以语音转文字识别(speechtotext,stt)技术、语意分析(semanticanalysis)技术达成,此外,语音处理模组1015更可以通过语意分析(semanticanalysis)技术修正转化后的文字,又,语音处理模组1015并可以对文字纪录信息进行标注,将第二音源相对应的人员信息(例如发言人姓名)标注于文字纪录信息,语音处理模组1015可再进一步将完成标记的文字纪录信息编辑为会议纪录档案,使用者调阅会议纪录档案时,即可比对发言对象及发言内容。
请参阅「图3」,图中所示为本申请的实施示意图(一),请搭配参阅「图2」,如图,本申请的智能会议记录系统10,实施时,使用者可于会议进行前启动智能会议记录系统10,使会议纪录处理装置101可驱动影像获取模组102及声音获取装置103,当会议进行时,影像获取模组102可获取一包含有深度信息的环景影像d1,并将环景影像d1传送至会议纪录处理装置101,又,声音获取装置103的各麦克风单元1031分别获取一声音讯号d2后,声音获取装置103依据各笔声音讯号d2的强度,识别各笔声音讯号d2为一第一音源(背景杂讯)或一第二音源d21(发言人声源),再者,声音获取装置103过滤掉第一音源后,可将第二音源d21传送至会议纪录处理装置101,又,会议纪录处理装置101可进一步将接收到的环景影像d1、第二音源d21暂存于影音资料库10124。
请参阅「图4」,图中所示为本申请的实施示意图(二),请搭配参阅「图2」~「图3」,如图,人脸识别单元10141从影音资料库10124中获取环景影像d1,人脸识别单元10141可对环景影像d1进行人脸识别程序,从环景影像d1捕捉出至少一人脸影像d11,并且将各人脸影像d11比对储存于人脸识别资料库10121的人脸识别资讯信息,进而识别出各个人脸影像d11的身份,完成人脸识别作业后,空间识别模组1013可基于三维座标信息比对第二音源d21的位置,并藉此识别出第二音源d21的方位,以确认出发言人员的位置,再者,影像处理模组1014可基于第二音源d21,于其对应位置的人脸影像d11进行一人员信息的标注作业,又,影像处理模组1014可以进一步于发言人员的人脸影像d11周围区域嵌入有一标注区块d12,所述的标注区块d12可供输入人员信息,例如,发言人员的头衔、姓名或联络信息等,本实施例中标注区块d12仅标注头衔与姓名,在其他实施例中,也可以依据需求增列其他信息,并不以此为限,特先陈明。
请参阅「图5」,图中所示为本申请的实施示意图(三),请搭配参阅「图4」,如图,当影像处理模组1014判断出发言人员位置及标注发言人员后,语音处理模组1015可从影音资料库10124中获取第二音源d21,并通过比对语音分析资料,使语音处理模组1015可将声音讯号编码为一文字纪录信息d3,又,语音处理模组1015并可以对文字纪录信息d3进行标注,将第二音源d21相对应的一人员信息d4(例如发言人姓名)标注于文字纪录信息d3,使用者调阅文字纪录信息d3时,即可比对发言对象及发言内容,再者,完成标注的文字纪录信息d3,语音处理模组1015可将文字纪录信息d3、人员信息d4全部汇入于一会议纪录档案d5之中,并将会议纪录档案d5储存于会议纪录资料库10123以供备查。
承「图5」,当同一时间内有多组发言人时,语音处理模组1015系可以查询各笔文字纪录信息d3的人员信息d4,按照不同的人员信息进行识别,按照时间序列规则汇入于会议纪录档案d5,当使用者从会议纪录处理装置101调阅会议纪录档案d5时,使用者即可清楚的对应每一位发言人员的文字稿内容。
请参阅「图6」,图中所示为本申请的另一实施例(一),如图,声音获取装置103也可以数支移动式麦克风1032组成,其中,各移动式麦克风1032分别具有一定位单元1033,可供定位各移动式麦克风1032并产生一麦克风定位信息,当声音获取装置103筛选出第二音源时,声音获取装置103可将第二音源及其麦克风定位信息传送至会议纪录处理装置101,再者,空间识别模组1013可以麦克风定位信息快速定位于三维座标信息,其中,所述的定位单元1033可以为全球定位系统(globalpositioningsystem,gps)技术或蓝芽定位技术实现;据此,本申请除定置式麦克风设备外,也可以通过移动式麦克风设备实现会议记录手段。
请参阅「图7」,图中所示为本申请的另一实施例(二),请搭配参阅「图4」如图,人脸识别单元10141完成人脸识别作业后,可进一步产生一会议名单信息d6,人脸识别单元10141可依据比对结果,将可识别出的人脸识别资讯信息罗列于会议名单信息d6之中,例如,人脸识别单元10141完成识别人脸作业后,人脸识别单元10141可从人脸识别资讯信息中获取全部或部分信息,将信息汇入于会议名单信息d6,并汇入于会议纪录档案内,以供使用者存取该笔会议名单信息d6。
请参阅「图8」,图中所示为本申请的另一实施例(三),如图,影像处理模组1014更包含有一影像监控单元10142,所述的影像监控单元10142可对环景影像中的各人脸影像进行监控,其中,影像监控单元10142可通过开源计算机视觉库opencv(opensourcecomputervisionlibrary)技术实现影像动态追踪,追踪各人脸影像的一嘴部区域,通过追踪人脸影像的嘴部区域,使影像处理模组1014可进一步通过识别嘴部区域,更加精准的判断出第二音源的位置(即发言人位置)。
请参阅「图9」,图中所示为本申请的另一实施例(四),如图,会议纪录处理装置101更包含有一信息连接模组1016,所述的信息连接模组1016与中央处理模组1011完成信息连接,并且一行动信息装置可通过无线传输技术与信息连接模组1016完成信息连接,实施时,使用者可通过行动信息装置连接至会议纪录处理装置101,并且从会议纪录处理装置101下载或调阅会议纪录档案,其中,信息连接模组1016可以为蓝芽、wifi模组。
综上可知,智能会议记录系统,其包含有一会议记录装置一影像获取模组及一声音获取模组,前述的装置设置于会议环境之中,启动智能会议记录系统,所述的声音获取模组可识别数笔不同方向获取到的声音讯号,从多笔声音讯号中识别出一第二音源,另外,影像获取模组将一环景影像传送至会议记录装置进行人脸识别后,会议记录装置通过第二音源及人脸识别双重确认发言人身份后,会议记录装置即可将第二音源编码为文字记载形式的会议纪录档案;依此,本申请其据以实施后,确实可达到提供一种可通过语音及影像双重确认发言人身份的智能会议记录系统的目的。
以上所述者,仅为本申请的较佳的实施例而已,并非用以限定本申请实施的范围;任何熟习此技艺者,在不脱离本申请的精神与范围下所作的均等变化与修饰,皆应涵盖于本申请的专利范围内。
【符号说明】
10智能会议记录系统
101会议纪录处理装置
1011中央处理模组1012资料储存模组
10121人脸识别资料库
10122人员资料库
10123会议纪录资料库
10124影音资料库
1013空间识别模组1014影像处理模组
10141人脸识别单元
10142影像监控单元
1015语音处理模组1016信息连接模组
10151语音资料库
102影像获取模组
1021摄像镜头
103声音获取装置
1031麦克风单元1032移动式麦克风
1033定位单元
d1环景影像d2声音讯号
d11人脸影像d21第二音源
d12标注区块
d3文字纪录信息d4人员信息
d5会议纪录档案d6会议名单信息
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



