
 商标分类
商标分类  商标转让
商标转让 
语音处理方法、装置和分布式系统与流程
 2021-01-28 16:01:02|
2021-01-28 16:01:02| 312|
312| 起点商标网
起点商标网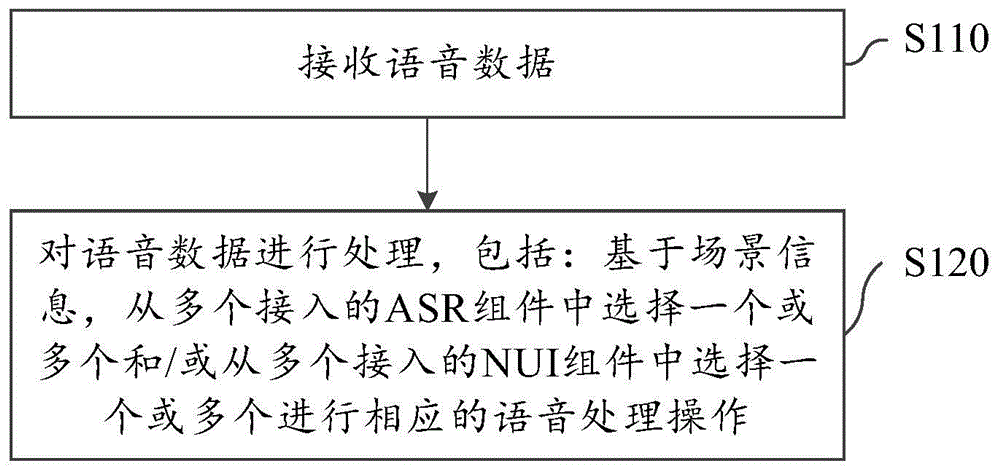
本发明涉及信息处理领域,尤其涉及一种语言处理方法、装置和分布式系统。
背景技术:
一般地,终端的语音交互设备可以将所接收到的语音上传到云端,借助云端强大的处理能力进行语音识别和自然语言理解。或者,在联网条件不佳或是应用场景较为简单的情况下,语音交互设备也可以在本地完成整个语音交互链路。
随着语音交互技术的发展,涉及语音交互的应用场景越来越多,同时语音交互链路比较长,会涉及不同模块单元比如有音频数据采集、前端信号处理、唤醒响应、语音识别、声纹识别、自然语言对话处理、对话结果响应分发,每个场景对语音交互的要求都不一样。
现有的语音交互解决方案都是由某一厂商提供对整条交互链路上所有模块的实现,无法接入或是替换其他厂商的模块,例如亚马逊echo、google音箱等。由于每个厂商的处理模块侧重点不同,因此会导致不同场景下识别率或性能无法同时达标,从而影响语音交互的多场景应用的使用体验。
为此,需要一种能够灵活适用于各种应用场景的语音处理方案。
技术实现要素:
为了解决上述至少一个问题,本发明将语音交互链路中的模块单元进行拆分定义,根据需要接入不同的组件,并且可以根据应用场景的变化按需动态加载不同的组件来形成整条语音交互链路。进一步地,可以为各组件的接入统一的接口,从而方便不同厂商按照统一接口进行组件接入。
根据本发明的一个方面,提出了一种语音处理方法,包括:接收语音数据;对所述语音数据进行语音处理,其中,所述语音处理包括:基于场景信息,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理;和/或基于场景信息,从多个自然语言处理组件中选择一个或多个自然语言处理组件对所述语音数据对应的文本进行处理。由此,实现基于当前场景的动态组件调度,以提升语音识别的能力或是速度。
优选地,该方法还可以包括:与所述语音数据对应的应用或模块对接;以及获取所述应用或模块的相关信息作为场景信息。例如,可以经由第一格式接口切换与多个语音应用或多个语音模块中的一个或多个对接。由此方便对应用场景的切换。优选地,该方法还可以还包括:分别经由第二格式接口接入所述多个语音识别组件;和/或分别经由第三格式接口接入所述多个自然语言处理组件。由此,通过接口的开放和统一,方便第三方模块的接入。
优选地,所述多个语音识别组件包括一个或多个本地语音识别组件以及一个或多个云端语音识别组件,和/或所述多个自然语言处理组件包括一个或多个本地自然语言处理组件以及一个或多个云端识别组件。由此,通过云端和本地的灵活接入,进一步提升对各种场景的应对能力。
优选地,该方法还可以包括:至少基于所述自然语言处理的结果,对所述语音数据进行响应。
优选地,该方法还可以包括:获取场景信息;以及基于获取的场景信息以及配置规则,生成配置信息。优选地,基于场景信息,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理包括:基于与所述场景信息相对应的语音识别配置信息,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理;和/或基于场景信息,从多个自然语言处理组件中选择一个或多个自然语言处理组件对所述语音数据对应的文本进行处理包括:基于与所述场景信息相对应的自然语言处理配置信息,从多个自然语言处理组件中选择一个或多个自然语言处理组件对所述语音数据对应的文本进行处理。
优选地,获取场景信息包括如下至少一项作为场景信息:所述语音数据用于的应用或模块;用户偏好设置;本地和/或云端系统状态;联网状态;以及会话所属场景。
优选地,本方法还可以包括:获取接入的至少部分语音处理组件的相关信息;以及至少基于所述相关信息,制定所述配置规则。
优选地,语音处理还可以包括:基于场景信息,从多个唤醒组件中选择一个唤醒组件对音频数据进行处理。
优选地,语音处理还可以包括:基于场景信息,从多个声纹组件中选择一个或多个声纹组件对所述语音数据进行处理。
优选地,语音处理还可以包括:基于所述场景信息,从多个语音合成组件中选择一个语音合成组件对基于自然语言处理结果生成的数据进行语音合成处理。语音处理还可以包括:向所述语音数据对应的应用或模块发送所述自然语言处理结果;接收所述应用或模块基于所述自然语言处理结果生成的语音合成命令;以及基于所述场景信息和所述语音合成命令,从多个语音合成组件中选择一个语音合成组件进行处理。
根据本发明的另一个方面,提出了一种语音处理装置,包括:第一模块,用于获取采集到的语音输入;第二模块,用于至少基于当前场景对应的当前语音识别配置,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理;第三模块,用于至少基于当前场景对应的当前自然语言处理配置,从多个自然语言处理组件中选择一个或多个自然语言处理组件对识别出的文本话语进行自然语言处理。
优选地,第二模块和第三模块可以用作组件选择模块,并且各自具有能够分别与多个组件相连接的统一接口。在此,多个语音识别组件可以包括一个或多个本地语音识别组件以及一个或多个云端语音识别组件。多个自然语言处理组件可以包括一个或多个本地自然语言处理组件以及一个或多个云端识别组件。
本发明的语音处理装置还可以包括更为全面的语音处理链路,例如如上所述的唤醒、声纹识别和语音合成功能。
优选地,所述语音处理装置还可以包括第四模块,用于至少基于当前场景对应的当前唤醒配置,从多个唤醒组件中选择一个唤醒组件对音频数据进行唤醒逻辑处理,并将识别出的唤醒词发送给所述第一模块。
优选地,所述语音处理装置还可以包括第五模块,用于至少基于当前场景对应的声纹识别配置信息,从多个声纹组件中选择一个或多个声纹组件进行针对所述语音输入的声纹识别,并向所述第一模块返回的声纹识别结果。第六模块至少基于当前场景对应的当前语音合成配置,从多个语音合成组件中选择一个语音合成组件对音频数据进行语音合成处理。
所述语音处理装置可以采用集中式、部分集中式或非集中式处理架构,于是,第一模块可以进一步用于获取每个被选择组件生成的处理结果;以及将所述处理结果发送给语音链路上的下一组件选择模块。
优选地,第一模块或第七模块进一步用于:获取当前场景信息;以及基于获取到的当前场景信息,分别向所述第二模块和所述第三模块下发对应的配置信息。第一模块或第七模块可以基于如下至少一项获取当前场景信息:所述第一模块当前接入的上层应用或功能模块;用户偏好设置;本地和/或云端系统状态;联网状态;以及当前会话所属场景。
在配置信息在线生成的情况下,第一模块或第七模块进一步用于:将获取到的场景信息发送给配置中心;获取所述配置中心根据配置规则在线生成的配置信息,并分别向所述第二模块和所述第三模块下发对应的配置信息。
优选地,第一或第八模块可以与所述语音数据所用于的应用或模块对接,并且用于获取所述应用或模块的相关信息作为场景信息。具体地,第一或第八模块可以经由第一格式接口切换与多个应用或模块中的一个或多个对接。
优选地,第八模块可以将所述自然语言处理的结果发送给所述语音数据对应的应用或模块,并接收所述应用或模块生成的语音合成命令,并且第六模块基于所述语音合成命令从多个语音合成组件中选择一个语音合成组件进行处理。
第一模块或第九模块还可用于:至少基于所述自然语言处理的结果,对所述语音数据进行响应,例如,执行与所述语音输入相对应的输出。
优选地,所述语音处理装置可以包括本地的语音处理模块本身,并且可以包括:各自经由统一接口与组件选择模块相连的本地语音处理模块,包括如下至少一项:经由第二接口与第二模块相连的一个或多个本地语音识别模块;经由第三接口与第三模块相连的一个或多个本地自然语言处理模块;经由第四接口与第四模块相连的一个或多个本地唤醒模块;经由第五接口与第五模块相连的一个或多个本地声纹识别模块;经由第六接口与第六模块相连的一个或多个本地语音合成模块。
根据本发明的再一个方面,提出了一种分布式语音处理系统,包括:如上所述的语音处理装置,以及各自经由统一接口,与所述语音处理装置的组件选择模块相连的云端语音处理组件。
优选地,该系统还可以包括云端组件选择模块,用于从多个云端语音处理组件的处理结果中动态选择最优处理结果,并将所述最优处理结果返回给本地组件选择模块。
优选地,该系统还可以包括配置中心,用于:接收所述语音处理装置发送的场景信息;基于配置规则在线生成的配置信息,所述本地组件选择模块基于所述配置信息选择要进行语音处理的组件;以及将所述配置信息下发给所述语音处理装置。
根据本发明的一个方面,提出了一种计算设备,包括:处理器;以及存储器,其上存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器执行如上所述的语音处理方法。
根据本发明的一个方面,提出了一种非暂时性机器可读存储介质,其上存储有可执行代码,当所述可执行代码被电子设备的处理器执行时,使所述处理器执行如上所述的语音处理方法。
本发明的语音处理方案可以将整个语音交互链路进行接口抽象,各个主要模块进行组件化封装,系统可按使用场景对各组件模块进行动态配置,各组件模块择优组合使用组件化的模块,由此灵活应对不同的应用场景,并提供各自最优的使用体验。
附图说明
通过结合附图对本公开示例性实施方式进行更详细的描述,本公开的上述以及其它目的、特征和优势将变得更加明显,其中,在本公开示例性实施方式中,相同的参考标号通常代表相同部件。
图1示出了根据本发明一个实施例的语音处理方法的流程示意图。
图2示出了根据本发明一个实施例的语音处理装置的组成示意图。
图3示出了根据本发明一个实施例的分布式语音处理系统的组成示意图。
图4示出了根据本发明一个实施例可用于实现上述语音处理方法的计算设备的结构示意图。
图5示出了根据本发明的组件化模块动态选择的实现例。
图6示出了根据本发明的组件化模块动态选择的详细实现例。
图7示出了对本发明的各组件进行动态配置的实现例。
图8示出了对本发明的各组件进行动态配置的详细实现例。
具体实施方式
下面将参照附图更详细地描述本公开的优选实施方式。虽然附图中显示了本公开的优选实施方式,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
语音交互链路是指实现语音交互的过程中涉及到音频数据采集、前端信号处理、唤醒响应、语音识别、声纹识别、自然语言处理、语音合成单元模块,这些单元模块共同协作完成语音交互功能。在不同的应用场景中,可以会涉及上述交互链路中的部分或全部模块。例如,在按键唤醒的情况下,基于唤醒词的唤醒响应单元就不是必须的。另外,声纹识别和语音合成功能对于某些应用场景也并非是必须的。
现有的语音交互解决方案比如亚马逊echo、google音箱、百度小度、小爱、天猫精灵中基本上都是整个语音交互模块都由内部自身模块来实现,不能接入或替换成其他厂商的模块。
随着语音交互应用场景变得越来越广泛,某一厂商的解决方案往往无法很好地实现全部场景下的快速准确交互。例如,仅针对车载语音交互情境,语音交互应用的场景也变得越来越多,同时语音交互链路比较长,会涉及不同模块单元比如有音频数据采集、前端信号处理、唤醒响应、语音识别、声纹识别、自然语言对话处理、对话结果响应分发,每个场景对语音交互的要求可能不一样。例如,在无网络的情况下,地图导航场景下要求离线地图相关语音识别率高,而在播放音乐的场景下要求音乐相关内容高识别率;在有网络的情况下,在地图推荐场景下,对诸如“附近3公里以内的酒店”语句的识别要求高,在播放音乐场景下,对诸如“我要听贝多芬的命运交响曲”的音乐相关的语句识别要求高。同时由于识别率的高低跟前端信号处理、语音识别模型相关,如果整个语音交互链路的模块单元由同一家语音厂商的识别模型来实现的话,往往会由于该厂商的处理模型侧重点不一样,这样会导致不同场景下的识别率或性能不能同时达标,从而影响语音交互的多场景应用的使用体验。
在专业场景,例如知识产权庭审、娱乐新闻发布语音识别场景中,在足够带宽使用条件下,对专业方向专有名词的识别率有较高要求,一个厂商的识别引擎往往无法满足现实需求,如果能在云端动态根据当前场景可动态切换到使用不同厂商asr(automaticspeechrecognition,自动语音识别)模块,统一返回符合要求的asr结果给本地,则可让同一套语音系统更加灵活应对不同的应用场景。在比如,在不同应用场景中可动态配置符合当前场景的tts(text-to-speech,语音合成)模型往往可有针对性满足用户的个性化需求,比如有的用户喜欢某一明星的声音合成播报,有的用户喜欢对某些特性如语气进行放大或特别处理等。
在上述描述的需求背景下,单纯使用一家语音厂商解决方案往往不能很好解决上面遇到的问题。为此,本发明提出了一种新的语音处理方案,其能够将整个语音交互链路中的模块单元进行拆分定义,并公开交互接口,不同厂商可按公开的交互接口实现部分组件模块单元,由系统根据应用场景的变化按需动态加载使用不同厂商实现的组件模块来形成整个语音交互链路,并且可对组件模块进行动态配置(比如,唤醒词、切换语音合成模型和语调等的设置)。由此,在不同应用场景下,系统可按照场景的特点以及不同厂商的模块特点来动态组装完成整个实现语音交互链路,以更好应对不同场景下的语音交互要求,提升交互体验。
图1示出了根据本发明一个实施例的语音处理方法的流程示意图。该方法至少包括采集语音数据的获取、语音识别和自然语言处理,涉及最为基础的语音处理链路。
在步骤s110,接收语音数据。例如,可以直接从所在设备的音频采集模块(例如,麦克风阵列)获取其采集的到音频数据。
随后,在步骤s120,对接收的语音数据进行语音处理,所述语音处理至少包括asr和nui处理。在这其中,asr和nui处理中的至少一个涉及基于场景信息,从多个接入组件中动态选择一个组件进行处理。具体地,所述语音处理包括:基于场景信息,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理;和/或基于场景信息,从多个自然语言处理组件中选择一个或多个自然语言处理组件对所述语音数据对应的文本进行处理。
具体地,针对不同的语音处理模块,可以获取场景信息,并基于获取的场景信息以及配置规则,生成配置信息。配置信息可以按照语音处理功能进行分割,分配给对应的模块。
针对asr,可以至少基于场景信息对应的当前语音识别配置信息,从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理,例如,进行语音识别处理。在不同的实施例中,可以直接从音频采集模块中获取或经由转发获取音频数据,并根据当前语音识别配置(即,当前的模块匹配规则),选择一个或多个组件进行语音识别。
针对nui,可以至少基于场景信息对应的当前自然语言处理配置信息,从多个自然语言处理组件中选择一个或多个自然语言处理组件对语音数据对应的文本进行处理,例如,对识别出的文本话语进行自然语言处理。在不同的实施例中,可以直接获取从上一处理步骤得到的经语音识别的数据(例如,文本话语数据)或经由转发获取,并根据当前自然语言处理配置(即,当前的模块匹配规则),选择一个或多个组件进行自然语言处理。
由此,本发明的语音处理方案适用于灵活应对多种场景。该方案尤其适用于实现为一种操作系统级的方案。例如,该方案可以内嵌在移动设备或是车载设备的操作系统中,并且与操作系统中安装的各种具有语音交互或是语音控制功能的应用(或是应用所包含的各种语音交互或控制功能)相接(例如,经由统一数据格式相接,如下将详述),并且基于当前对接的应用种类(例如,音乐播放器或地图导航app),选择合适且可用的语音处理组件来进行完整语音处理链路的动态实现。在其他实施例中,该方案也可以适用于实现一种支持多目的语音处理的硬件语音交互设备,例如,智能音箱。在另一些实施例中,针对整合了多语音应用场景的多功能应用,该方案也可以在一个应用中实现。
在此,语音识别也被称为自动语音识别(asr),是一种将语音(例如,用户输入的语音)转换为文本的技术。例如,经由asr,可以将用户输入的语音“打开电视”转换为文字意义上的“打开电视”。自然语言处理(naturallanguageprocessing,nlp)则可包括自然语言理解(naturallanguageunderstanding,nlu),后者是用于让计算机理解人类语言的技术,即,通过语法、语义、语用的分析,获取自然语言的语义表示。例如,文本“打开电视”的语义是需要对“家电-电视”进行“打开”的操作。在本发明中,自然语言处理组件指代能够对经asr转换的文本话语进行语义理解的组件,在某些情况下,也可以被称为自然用户界面(nui)组件。
在此,本发明的语音处理方案首先将语音交互链路按功能分解成不同的组件,例如,语音处理中最为基础的asr组件和nui组件。上述组件可以经由预先定义好的接口来与组件选择模块相连接,由此方便例如系统框架层对各个组件的动态加载、卸载和替换使用。
各个组件(例如,asr组件和nui组件)指的是可以独立完成语音交互链路中的某一特定功能的组件。例如,多个asr组件可以经由统一的第二格式接口接入(在此,显然是软件意义上的耦合)。这多个asr组件中的每一个,可以由不同的厂商以不同的处理模型但遵循相同的接口标准实现,并且每个asr组件都具备对输入语音进行单独asr处理的能力。在不同的实施例中,接入的asr组件可以包括一个或多个本地asr组件,以及一个或多个云端asr组件。这些组件针对不同的应用场景具有不同的处理能力,并且可以通过基于配置的选择而被动态接入语音处理链路,从而更好应对不同场景下的语音处理(例如,语音交互)要求,提升使用体验。
类似地,多个nui组件可以经由统一的第三格式接口接入。这多个nui组件中的每一个,可以由不同的厂商以不同的处理模型但遵循相同的接口标准实现,并且每个nui组件都具备对输入语音进行单独nui处理的能力。在不同的实施例中,接入的nui组件可以包括一个或多个本地nui组件,以及一个或多个云端nui组件。这些组件针对不同的应用场景具有不同的处理能力,并且可以通过基于配置的选择而被动态接入语音处理链路,从而更好应对不同场景下的语音处理(例如,语音交互)要求,提升使用体验。
由此,在对语音交互链路上的各个功能模块进行组件化后,可按需加载使用不同语音组件模块,特别是针对不同的应用场景,可以有针对性地选择动态切换使用指定厂商的组件模块,从性能和功能上择优组合语音链路模块,可为用户提供更优质的语音交互体验。
在某些实施例中,可以通过点击虚拟或实体按钮来进入语音交互状态。例如,可以点击地图导航上的麦克风按钮来开启语音交互流程。在更为复杂或是功能更为全面的语音处理链路中,还可以包括唤醒(wakeup)组件,以提供语音唤醒功能。在此,“语音唤醒”指代设备(手机、家电、车载系统等)在休眠或锁屏状态下也能检测到用户的声音(设定的语音指令,即唤醒词),让处于休眠状态下的设备直接进入到等待指令状态的功能。于是,本发明的语音处理方案还可以包括针对唤醒组件的动态配置。该方法可以包括:至少基于当前场景对应的当前唤醒配置,从多个唤醒组件中选择一个唤醒组件对音频数据进行处理,例如基于唤醒逻辑的识别或操作处理。识别出的唤醒词可发送以供进行相应的操作或是启动后续语音交互。
类似地,唤醒组件的接入可有经由公开的接口(例如,第四接口),用于接入原配或是其他厂商生产的唤醒组件。鉴于唤醒组件需要对语音进行即时的采样与分析,因此多个语音唤醒组件优选都是位于本地的唤醒模块,例如,分别针对地图导航和歌曲播放控制的唤醒组件。在一个实施例中,更为复杂的唤醒组件还可以包括直接针对快捷词的识别。例如,在歌曲播放场景中,暂停播放、继续播放、下一首、上一首等可以作为唤醒语音链路的唤醒词,同时也是可以在唤醒之后直接对音乐播放进行控制的快捷词。
在某些实施例中,语音交互链路中还可以包括声纹识别组件。声纹(voiceprint,简称vp)识别是一种提取说话人声音特征和说话内容信息,自动核验说话人身份的技术。例如在需要相对较高安全性的应用情境下,可以通过声纹识别来使得系统听从特定说话人发出的语音命令。于是,本发明的语音处理方案还可以包括针对声纹组件的动态配置。该方法可以包括:基于当前场景对应的声纹识别配置信息,从多个声纹组件中选择一个或多个声纹组件对语音数据进行处理,例如声纹识别处理。声纹识别结果可被返回用于后续的操作。
类似地,各个厂商的声纹识别组件可以通过统一的格式接口(例如,第五格式接口)接入。基于声纹识别的比对特性,因此多个声纹识别组件优选都是位于云端声纹识别组件。如果需要进行声纹识别处理,可以通过第五接口加载指定厂商提供的云端声纹识别组件(或是包括多个组件的组件库),并向其提交获取的语音输入,获取被选组件的识别结果,并且根据配置信息进行仲裁过滤处理返回经过滤的声纹识别结果。
如前所述,本发明的语音处理方案尤其适用于实现为一个操作系统级的解决方案,在其他实施例中,也可以实现为某应用的内嵌功能,无论哪种实现,本发明的处理方案都需要与涉及多种场景的应用(或应用包含的各种语音功能)相连接。在与多个应用相连接的情况下,这些应用是与操作系统的语音处理功能或框架相连的“上层”应用。在与多种语音功能对接的情况下,本发明的语音处理方案可以与这些语音功能位于同一个应用内,但实现为不同的功能模块。
语音处理涉及对例如用户输入的语音数据进行的处理,而在更为完整的语音处理链路中,还可以包括tts(语音合成)功能,由此实现与用户的对话,或是报告执行结果,从而真正实现语音的“交互”。在某些实施例中,tts的生成需要上层语音应用或语音功能模块通过tts命令来触发。此时,可以向上层语音应用或语音功能模块发送语音交互链路中在前组件的处理结果,例如,发送nui结果,或是发送包括nui结果在内的各个组件的在前处理结果。由所述上层语音应用或功能模块发出的语音合成命令可被获取并用于tts的生成。在其他实施例中,tts的生成可以无需上层语音应用或语音功能模块的介入直接进行,于是可以直接获取自然语言处理的结果,并基于当前场景对应的语音合成配置,从多个语音合成组件中选择一个语音合成组件对音频数据进行语音合成处理,接收被选组件生成的语音合成信息并进行输出。
在一个功能完整的语音交互链路中,包括唤醒、asr、nui、vp和tts功能。在一个优选实施例中,本发明的语音处理方案可以涉及对这五个组件的动态配置,例如,可以动态选择各自经由统一接口连接至组件选择模块的多个本地或云端模块中的一个或多个,以实现基于当前场景的最佳语音交互。
如上介绍了本发明的语音处理方案(优选地,语音交互方案)中可以包括经由统一的格式接口接入的多个组件。如下将详细介绍,各个组件选择模块是以何种标准从多个连接组件中进行动态选择的。
如上所述,本发明的语音处理方案尤其适于实现为操作系统内嵌的语音处理框架,或是与应用内各语音功能相连的语音处理模块,无论是哪种实现,本发明的语音处理方案都可以根据其当前连接的语音应用或功能模块的应用场景,来确定至少部分的当前场景信息。
在此,“场景”指的是接收到语音输入时所处的情境,包括但不限于:应用场景,这可由当前对接的上层应用或功能模块确定,由此确定是需要进行例如地图导航相关识别还是音乐播放相关识别;当前用户场景,如用户偏好设置,例如,优选选择当前用户喜爱的声音或是语调进行语音合成;联网场景,如联网状态,云端组件只有在联网状态下才可被访问;以及本地和/或云端系统状态,比如,本地和云端的各个组件当前是否处于正常可用的状态等。在另一个实施例中,“场景信息”还可以包括当前会话所属场景信息,该信息可以通过对用户前一轮或几轮输入的语音识别结果确定,并且用于同主题会话中的后续语音识别。例如,用户可以在前一轮的对话中输入“告诉我一些植物学知识”,系统在识别出“植物学”这一主题之后,可以将其作为场景信息通知各个组件选择模块(尤其是asr组件选择模块),以方便其切换至植物学相关asr组件来对后续输入的语音进行识别。
在获取了上述场景信息之后,则可针对现有各个接入模块的属性进行配置(也可称为“匹配”),以选择属性符合当前场景要求的模块。可以在本地自行进行例如基于本地系统状态和云端系统状态的配置,也可以通过云端的配置中心来进行针对各个组件选择模块的配置信息生成操作(例如,基于场景应用的配置)。具体地,可以将获取到的场景信息发送给配置中心;所述配置中心根据配置规则,在线生成配置信息;获取所述配置信息,并分别向各个组件选择模块下发对应的配置信息。配置中心可以在先获取接入各个模块的每个组件的相关信息,并至少基于所述相关信息,制定上述配置规则。
一旦确定的配置有变更,可以及时地发起配置请求通知,以更新针对各个组件选择模块的配置信息。
举例而言,配置请求通知可以包括:本地唤醒配置<wakeupconfig>,涉及本地静音检测时间长vad阀值、去噪设置阀值、定向拾音的方位、唤醒词以及其触发阀值;云端语音识别配置<asrconfig>,涉及当前asr应用场景及定制的热词,asr模块厂商组件或使用云端asr代理服务器来聚合到其他asr厂商;声纹识别配置<vpconfig>,涉及当前vp应用场景及vp模块厂商组件及其阀值;自然语言处理配置<nuiconfig>,其中涉及使用哪家nui厂商组件、是否需要本地nui,以及本地和云端nui结果仲裁配置规则;语音合成tts配置<ttsconfig>,其中涉及使用哪家tts厂商组件、以及语音合成的音调、模型比如可指定使用名人a声音模型或者名人b的声音模型;在配置中心向各模块发起config配置通知后,各组件选择模块(比如wakeup、asr、vp、nlu、tts)会根据当前厂商组件能力,进行自动适配无缝调整,还可以在调整完成后会通知配置中心各模块的适配状态。
在一个实施例中,当前配置仅为每个功能选择一个组件进行语音处理,例如,选择本地唤醒组件1进行唤醒操作,在线asr组件6进行语音识别操作,在线nui组件3进行语义理解操作,本地tts组件1进行语音合成操作。此时,由于动态链路中每个语音处理功能仅涉及一个模块,因此可以直接适于被选模块的处理结果并进行后续处理。
在其他实施例中,语音链路中可能存在选择多于一个组件进行某一语音处理的情况。例如,基于配置选择在线asr组件1和5,以及本地asr组件1同时对某一输入语音进行识别。在此,这三个组件各自生成的识别结果可以基于特定规则(例如,置信阈值)进行比较和选择,或者,可以在云端对在线asr组件1和5首先进行比较和选择。在某一实施例中,还可以利用不同的支链进行语音处理。例如,可以将两个asr组件生成的不同asr结果同时下发给一个或多个nui组件(asr和nui组件之间也可以具有对应关系),以生成一个或多个nui结果,并且基于nui结果进行判定。
另外,应该理解的是,在基于本发明的实现中,并不要求每个语音处理功能都接入多个组件,例如,唤醒功能可以仅由本地的一个唤醒模块实现,而是只要语音链路上存在能够基于公开接口接入的组件,并能够基于当前场景被动态接入即可。
另外,针对本地和云端组件,可以基于不同的接口标准或是接口格式进行接入。例如,云端asr组件和本地asr组件可以基于相同的第二格式接口接入,也可以分别基于第二格式云端接口和第二格式本地接口接入。
为了提升处理效率,本发明的语音处理方案可以使用集中式架构实现。可以使用一个中心模块对语音处理链路上的各个模块进行中心管理,例如,使用第一模块用于整体语音处理方案的中心节点,负责中间处理数据在各个模块之间的流转。
同时,各个组件选择模块用作针对该功能的管理模块。由此,第二模块可以从与其相连接的多个asr组件中选择一个或多个asr组件进行语音识别之后,可以接收来自一个或多个asr组件的识别结果,并将所有识别结果或是经筛选的一个识别结果发送给第一模块。随后,第一模块可以直接将识别结果(即,识别出的文本)发送给第三模块,也可以在存在多个识别结果的情况下,进行结果筛选,再将结果发送给第三模块。第三模块可以从与其相连接的多个nui组件中选择一个或多个nui组件,由着一个或多个nui组件针对识别出的文本进行自然语言理解处理,接收来自一个或多个nui组件的处理结果,并将所有处理结果或是经筛选的一个处理结果发送给第一模块。
第一模块随后可以至少基于所述自然语言处理的结果,对所述语音数据进行响应,例如,执行与所述语音输入相对应的输出。由此,本发明的上述方案就实现了针对语音输入的动态语音处理。上述处理结果例如可以直接用于对目标设备的操作,例如,上述处理结果可被输出给智能家居管理模块,后者直接进行打开电视的操作。上述处理结果也可以进一步用于用后续的语言处理,例如,tts操作。
在语音处理链路中包括更多功能的情况下,组件选择模块还可以包括分别用于动态选取唤醒组件、声纹识别组件和语音合成组件的第四、第五和第六模块中的一个或多个。具体地,第四模块可以基于场景信息,从多个唤醒组件中选择一个唤醒组件对音频数据进行处理,例如唤醒处理。第五模块可以基于场景信息,从多个声纹组件中选择一个或多个声纹组件对所述语音数据进行处理,例如,声纹识别。第六模块可以基于所述场景信息,从多个语音合成组件中选择一个语音合成组件对基于自然语言处理结果生成的数据进行处理,例如,语音合成处理。在不同的实施例中,第六模块可以直接获取第三模块的自然语言处理结果(或经由第一模块转发获取),也可基于上层应用或模块发出的语音合成命令,进行tts组件的选择及相应的处理。
在此,用作组件选择模块的第二至第六模块可以分别经由统一的格式接口(例如,第二至第六格式接口)与各自对应的语音处理组件相连接,由此,使得语音处理链路上每个语音处理功能都能够方便地接入各自原配或是第三方组件,使得处理链路的动态选择有着更大的灵活性,并且能够更好地适配各种场景。另外,第一模块也可以用作在各个组件选择模块之间进行数据传递的中转模块。
在集中式架构的实施例中,可以使用第一模块经由第一接口与上层应用或功能模块相连接,因此第一模块将自然语言处理的结果发送给所述上层应用或功能模块。在其他实施例中,第一模块可以将各个语音处理模块中进行语音处理结果都发送给上层应用或功能模块。例如,可以将经asr的文本数据、经nui的语义数据、声纹识别结果、唤醒词识别结果等一并或是按照接收顺序逐个发送给上层应用或功能模块,以方便上层应用或功能模块的后续处理。
在集中式架构中,可由第一模块获取当前场景信息,并且该第一模块可以基于获取到的场景信息,分别向各个组件选择模块(例如,第二至第六模块)下发对应的配置信息。
在某些实施例中,执行本发明的语音处理方案的装置也可以具有非集中式或是部分集中式的架构。在这些实施例中,并非使用第一模块作为中心节点来实现信息的集中获取与分配,而是可以经由不同的模块来与例如包括第二至第六模块的语音处理模块以及上层应用或功能模块进行交互。
于是,在一个实施例中,第七模块可以获取场景信息,并且基于获取的场景信息和配置规则,生成配置信息。优选地,配置信息的生成可以包括:所述第七模块将获取到的场景信息发送给配置中心;所述配置中心根据配置规则,在线生成配置信息;所述第七模块获取所述配置信息,并分别向所述第二模块和所述第三模块下发对应的配置信息。
在一个实施例中,第八模块与所述语音数据所用于的应用或模块对接;以及所述第八模块获取所述应用或模块的相关信息作为场景信息。所述第八模块可以经由统一格式接口切换与多个语音应用或多个语音模块中的一个或多个对接。
在一个实施例中,第九模块基于所述自然语言处理的结果,对所述语音数据进行响应。
可以由单个模块执行所述第一模块、所述第七模块、所述第八模块和所述第九模块中至少两个模块的功能。在由单个模块执行全部模块功能的情况下,即是如上的集中式架构。
图2示出了根据本发明一个实施例的语音处理装置的组成示意图。该语音处理装置可以用于实现图1所述的语音处理方法,并且在不同的实施例中,该装置可以实现为软件上的功能模块,或是硬件上的实体模块,或是其任一组合。例如,在内嵌为操作系统的语音处理功能时,该装置可以实现为由多个功能模块组成的系统框架。在实现为智能音箱时,该装置的各个功能模块可由不同的物理模块所实现,或是软件结合的实现。本发明对此不做限制。
如图2所示,装置200可以包括第一模块210、第二模块220和第三模块230。
第一模块210用于接收语音数据。第二模块220用于基于场景信息(例如,基于当前场景对应的当前语音识别配置信息),从多个语音识别组件中选择一个或多个语音识别组件对所述语音数据进行处理。第三模块230用于基于场景信息(例如,基于当前场景对应的当前自然语言处理配置信息),从多个自然语言处理组件中选择一个或多个自然语言处理组件对识别出的文本话语进行自然语言处理。
第二模块220和第三模块230可以用作组件选择模块,并且各自具有能够分别与多个组件相连接的统一接口。在此,多个语音识别组件可以包括一个或多个本地语音识别组件以及一个或多个云端语音识别组件。多个自然语言处理组件可以包括一个或多个本地自然语言处理组件以及一个或多个云端识别组件。在此,多个接入的本地asr组件可以组成本地asr组件库,多个接入的云端asr组件可以组成云端asr组件库。多个接入的本地nui组件可以组成本地nui组件库,多个接入的云端nui组件可以组成云端nui组件库。
本发明的语音处理装置还可以包括更为全面的语音处理链路,例如如上所述的唤醒、声纹识别和语音合成功能。
在一个实施例中,本发明的语音处理装置还可以包括第四模块,用于至少基于当前场景对应的唤醒配置,从多个唤醒组件中选择一个唤醒组件对音频数据进行唤醒处理,并将识别出的唤醒词发送给所述第一模块。
在一个实施例中,本发明的语音处理装置还可以包括第五模块,用于至少基于当前场景对应的声纹识别配置信息,从多个声纹组件中选择一个或多个声纹组件进行针对所述语音输入的声纹识别,并向所述第一模块返回的声纹识别结果。第六模块至少基于当前场景对应的当前语音合成配置,从多个语音合成组件中选择一个语音合成组件对音频数据进行语音合成处理。
如图2所示,本发明的语音处理装置优选采用集中式处理架构,即,由第一模块用作数据收集和分发的中心节点。于是,第一模块210可以进一步用于获取每个被选择组件生成的处理结果;以及将所述处理结果发送给语音链路上的下一组件选择模块。
第一模块210还可用于:至少基于所述自然语言处理的结果,执行与所述语音输入相对应的输出。
在一个实施例中,第一模块210进一步用于:获取当前场景信息;以及基于获取到的当前场景信息,分别向所述第二模块和所述第三模块下发对应的配置信息。第一模块可以基于如下至少一项获取当前场景信息:所述第一模块当前接入的上层应用或功能模块;用户偏好设置;本地和/或云端系统状态;联网状态;以及当前会话所属场景。
在配置信息在线生成的情况下,第一模块210进一步用于:将获取到的场景信息发送给配置中心;获取所述配置中心根据配置规则在线生成的配置信息,并分别向所述第二模块和所述第三模块下发对应的配置信息。
在一个实施例中,本发明的语音处理装置可以包括本地的语音处理模块本身,于是该装置还可以包括:各自经由统一接口与组件选择模块相连的本地语音处理模块,包括如下至少一项:经由第二接口与第二模块相连的一个或多个本地语音识别模块;经由第三接口与第三模块相连的一个或多个本地自然语言处理模块;经由第四接口与第四模块相连的一个或多个本地唤醒模块;经由第五接口与第五模块相连的一个或多个本地声纹识别模块;经由第六接口与第六模块相连的一个或多个本地语音合成模块。
在语音处理装置实现为某具体物理设备(例如,智能音箱)的情况下,该装置还可以包括音频收集模块(例如,麦克风阵列)和扬声器模块等。
在本发明中,如上所述用作组件选择模块的第二至第六模块可以包括被抽象定义为中间层。第二模块对应于asrsi<asrserviceinterface>(即,asr服务接口);第三模块对应于nuissi<nuiserviceinterface>(即,nui服务接口);第四模块对应于wsi<wakeupserviceinterface>(即,唤醒服务接口);第五模块对应于vpsi<voiceprintserviceinterface>(即,声纹服务接口);第六模块对应于ttssi<ttsserviceinterface>(即,语音识别服务接口)。第一模块可以对应于中心节点voicesrv(即,语音服务模块)。voicesrv模块以及分别用作asr、nui、tts中间层模块的第二、第三和第六模块可以根据网络状态、当前应用场景动态决定是否使用本地asr、云端asr、本地nui、云端nui、本地tts、云端tts,不管选择本地asr还云端asr或本地nui还是云端nui,对上层语音应用或是语音功能模块透明,向上层返回数据的接口保持一致;
抽象定义可对接不同厂商的引擎接口。即,接入的多个组件可以具有规定的接口,以方便接入各自的中间层模块。在此,接入的唤醒组件可以具有wakeuplei<wakeuplocalengineinterface>(即,唤醒本地引擎接口);接入的asr组件可以具有asrlei<asrlocalengineinterface>(即,asr本地引擎接口)或asrcei<asrcloudengineinterface>(即,asr云端引擎接口);接入的声纹识别组件可以具有vpcei<vpcloudengineinterface>(即,声纹云端引擎接口);接入的nui识别组件可以具有nuicei<nuicloudengineinterface>(即,nui云端引擎接口)或nuilei<nuilocalengineinterface>(即,nui本地引擎接口),不同厂商可根据自身逻辑实现满足指定接口定义的模块组件,并例如以第三方组件库的形式配置到系统中。
系统中间层可根据系统应用场景以及已提供的第三方组件库的特性,动态的加载使用不同的语音组件库,语音组件库类型包括本地wakeup、本地asr、云端asr、本地tts、云端tts、云端vp、本地nui、云端nui。虽然基于现有技术的限制,唤醒处理需要在本地实现,而声纹识别则需要在云端实现,但本发明不排除技术发展后在云端实现唤醒处理和在本地实现声纹处理的可能性。
系统中间层可以通过voiceconfigurecenter(语音配置中心)来收集来场景应用发起的config配置请求,也可自动根据本地系统状态及云端运行状态来进行voiceconfig配置,一旦确定config配置有变更,则向不同模块发起配置请求通知。
虽然图2示出了由第一模块执行信息收集和分发的集中式架构的方案,但在某些实施例中,本发明的语音处理装置也可以具有非集中式或是部分集中式的架构。在这些实施例中,并非使用第一模块作为中心节点来实现信息的集中获取与分配,而是可以经由不同的模块来与例如包括第二至第六模块的语音处理模块以及上层应用或功能模块进行交互。
于是,在一个实施例中,第七模块可以获取场景信息,并且基于获取的场景信息和配置规则,生成配置信息。优选地,配置信息的生成可以包括:所述第七模块将获取到的场景信息发送给配置中心;所述配置中心根据配置规则,在线生成配置信息;所述第七模块获取所述配置信息,并分别向所述第二模块和所述第三模块下发对应的配置信息。
在一个实施例中,第八模块与所述语音数据所用于的应用或模块对接;以及所述第八模块获取所述应用或模块的相关信息作为场景信息。所述第八模块可以经由第一格式接口切换与多个语音应用或多个语音模块中的一个或多个对接。
在一个实施例中,第九模块基于所述自然语言处理的结果,对所述语音数据进行响应。
可以由单个模块执行所述第一模块、所述第七模块、所述第八模块和所述第九模块中至少两个模块的功能。在由单个模块执行全部模块功能的情况下,即是如上的集中式架构。
图3示出了根据本发明一个实施例的分布式语音处理系统的组成示意图。该系统300可以包括如上所述的语音处理装置,以及各自经由统一接口,与所述语音处理装置的组件选择模块相连的云端语音处理组件。例如,图中示出了与第二至第六模块相连的多个本地和云端语音处理组件。
在一个实施例中,该系统还可以包括云端组件选择模块,用于从多个云端语音处理组件的处理结果中动态选择最优处理结果,并将所述最优处理结果返回给本地组件选择模块。
在一个实施例中,该系统还可以包括配置中心,用于:接收所述语音处理装置发送的场景信息;基于配置规则在线生成的配置信息,所述本地组件选择模块基于所述配置信息选择要进行语音处理的组件;以及将所述配置信息下发给所述语音处理装置。配置中心可以进一步用于:获取接入的至少部分组件的相关信息;以及基于所述相关信息,制定所述配置规则。
图4示出了根据本发明一个实施例可用于实现上述语音处理方法的计算设备的结构示意图。
参见图4,计算设备400包括存储器410和处理器420。
处理器420可以是一个多核的处理器,也可以包含多个处理器。在一些实施例中,处理器1020可以包含一个通用的主处理器以及一个或多个特殊的协处理器,例如图形处理器(gpu)、数字信号处理器(dsp)等等。在一些实施例中,处理器1020可以使用定制的电路实现,例如特定用途集成电路(asic)或者现场可编程逻辑门阵列(fpga)。
存储器410可以包括各种类型的存储单元,例如系统内存、只读存储器(rom),和永久存储装置。其中,rom可以存储处理器420或者计算机的其他模块需要的静态数据或者指令。永久存储装置可以是可读写的存储装置。永久存储装置可以是即使计算机断电后也不会失去存储的指令和数据的非易失性存储设备。在一些实施方式中,永久性存储装置采用大容量存储装置(例如磁或光盘、闪存)作为永久存储装置。另外一些实施方式中,永久性存储装置可以是可移除的存储设备(例如软盘、光驱)。系统内存可以是可读写存储设备或者易失性可读写存储设备,例如动态随机访问内存。系统内存可以存储一些或者所有处理器在运行时需要的指令和数据。此外,存储器410可以包括任意计算机可读存储媒介的组合,包括各种类型的半导体存储芯片(dram,sram,sdram,闪存,可编程只读存储器),磁盘和/或光盘也可以采用。在一些实施方式中,存储器410可以包括可读和/或写的可移除的存储设备,例如激光唱片(cd)、只读数字多功能光盘(例如dvd-rom,双层dvd-rom)、只读蓝光光盘、超密度光盘、闪存卡(例如sd卡、minsd卡、micro-sd卡等等)、磁性软盘等等。计算机可读存储媒介不包含载波和通过无线或有线传输的瞬间电子信号。
存储器410上存储有可执行代码,当可执行代码被处理器420处理时,可以使处理器420执行上文述及的语音处理方法。
上文中已经参考附图详细描述了根据本发明的语音处理方法、装置和分布式系统。本发明的语音处理方案可以将整个语音交互链路进行接口抽象,各个主要模块进行组件化封装,系统可按使用场景对各组件模块进行动态配置,各组件模块择优组合使用组件化的模块,由此灵活应对不同的应用场景,并提供各自最优的使用体验。
[应用例1]
图5示出了根据本发明的组件化模块动态选择的实现例。图5示出了采用语音服务(voicesrv)中心节点对接应用或模块,以基于场景从包括多个wakeup、asr、tts、vp、nui组件的语音处理模块中动态选择语音交互链路的集中式处理方案。在图中,音频采集服务(audiosrv)和音频输出服务可以分别与语音处理模块相连接。音频采集服务可以实现为音频采集的麦克风阵列和初步的音频处理模块,例如模数转换电路等。音频输出服务可以实现为模数转换电路和扬声器等。
图6示出了根据本发明的组件化模块动态选择的详细实现例。图6详细示出了语音链路中的各个功能模块及其间数据的传递。在此,asr模块包括asrsi<asrserviceinterface>(即,asr服务接口);nui模块包括nuissi<nuiserviceinterface>(即,nui服务接口);wakeup模块包括wsi<wakeupserviceinterface>(即,唤醒服务接口);vp模块包括vpsi<voiceprintserviceinterface>(即,声纹服务接口);tss模块包括ttssi<ttsserviceinterface>(即,语音识别服务接口)。中心节点voicesrv(即,语音服务模块)用作语音应用与语音链路的信息传输中介,其中,语音服务模块可以包括vmpi<voicemodelproviderinterface>(即,语音模型提供方接口)来与各种语音或模块(图中示出为语音应用)对接。
如图所示,系统中间层包括asr模块、nui模块、wakeup模块、vp模块和tts模块(分别对应于上述第二至第六模块),并且可以根据系统应用场景以及已提供的第三方组件库的特性,动态的加载使用不同的语音组件库,语音组件库类型包括本地wakeup、本地asr、云端asr、本地tts、云端tts、云端vp、本地nui、云端nui。虽然基于现有技术的限制,唤醒处理需要在本地实现,而声纹识别则需要在云端实现,但本发明不排除技术发展后在云端实现唤醒处理和在本地实现声纹处理的可能性。
抽象定义可对接不同厂商的引擎接口。即,接入的多个组件可以具有规定的接口,以方便接入各自的中间层模块。在此,接入的唤醒组件可以具有wakeuplei<wakeuplocalengineinterface>(即,唤醒本地引擎接口);接入的asr组件可以具有asrlei<asrlocalengineinterface>(即,asr本地引擎接口)或asrcei<asrcloudengineinterface>(即,asr云端引擎接口);接入的声纹识别组件可以具有vpcei<vpcloudengineinterface>(即,声纹云端引擎接口);接入的nui识别组件可以具有nuicei<nuicloudengineinterface>(即,nui云端引擎接口)或nuilei<nuilocalengineinterface>(即,nui本地引擎接口),不同厂商可根据自身逻辑实现满足指定接口定义的模块组件,并例如以第三方组件库的形式配置到系统中。
6.1.首先,wakeup(唤醒)模块向audiosrv(音频服务)发起录音,audiosrv向wakeup不断提供audiodata(音频数据)①,wakeup根据系统配置信息,按照wakeuplei接口定义加载由厂商提供的本地wakeup组件库并创建指定wakeup实例,并向wakeup组件实例提交audiodata②;
6.2.wakeup组件实例根据audiodata以及唤醒逻辑处理,按照wakeuplei接口返回触发的kws/voicedata(关键词服务/语音数据)③,并向voicesrv(语音服务)提交kws/voicedata④;
6.3.voicesrv根据当前网络状态及系统配置信息,检查是否需要asr处理,如果需要asr,则按照asrsi接口将audiodata⑤发给asr,如果需要云端asr,asr按照应用场景及识别率要求,根据asrcei接口加载指定厂商提供的云端asr组件库,并向其提交voicedata⑥,cloud(云端)asr组件库进行云端语音识别,并返回asrresult(asr结果)⑦给asr;如果需要本地asr,asr按照应用场景及识别率要求,根据asrlei接口加载指定厂商提供的本地asr组件库,并向其提交voicedata⑧,本地asr组件库进行本地语音识别,并返回asrresult⑨给asr;asr根据配置信息进行仲裁处理向voicesrv返回asrevents/asrresult(asr事件/asr结果)⑩;
6.4.voicesrv根据场景将asr识别结果textutterance(文本话语)
6.5.voicesrv根据系统配置信息,检查是否需要voiceprint(声纹)处理,如果需要voiceprint,则按照vpsi接口将
6.6.voicesrv将收到的kwsevents/asrevents/asrresult/vpresutl/dailog
6.7.语音应用根据场景向voicesrv发起ttscommand(tts命令)
应该理解的是,在每一次的语音处理中,涉及的组件会有所不同。例如,在经由唤醒词唤醒和声纹识别之后,同一会话中的后续语音输入通常无需再进行wakeup和vp处理。另外,tts处理也不是每次都必须的。
图7示出了对本发明的各组件进行动态配置的实现例。在配置中,无需麦克风和扬声器的参与,但是语音服务模块可以通过voiceconfigurecenter(语音配置中心)来收集来场景应用发起的config配置请求,并自动根据本地系统状态及云端运行状态来进行voiceconfig配置,一旦确定config配置有变更,则向不同模块发起配置请求通知。
图8示出了对本发明的各组件进行动态配置的详细实现例。
8.1.在一例中,上层语音应用发起一次voiceconfig(语音配置)①,比如进入有声读物应用、电台应用,其中会包含电台带数字或中英文混合的常用电台名,并且用户往往处在在线状态,voicesrv接收到voiceconfig后,通过向configcenter(配置中心)发起setvoiceconfig(设置语音配置)②,configcenter根据在线、热词配置设置,则会发起notifyvoiceconfig(通知语音配置)③,voicesrv分解voiceconfig,分别向wakeup、asr、voiceprint、nlu、tts发起notifywakeupconfig(通知唤醒配置)④<比如配置跟播放相关的快捷词暂停播放、继续播放、上一首、下一首等>、notifyasrconfig(通知asr配置)⑥<比如选择对数字、中英文混合识别率高的云端asr厂商模块,并配置对应电台或有声读物的热词>、notifynuiconfig(通知nui配置)⑧<比如无须使用本地nlu模块,只使用cloudnlu模块>,wakeup处理完配置后,通知voicesrv事件adaptivewakeupfinished(自适应唤醒完成)⑤,asr处理完配置后,通知voicesrv事件adaptiveasrfinished(自适应asr完成)⑦,nui处理完配置后,通知voicesrv事件adaptivenuifinished(自适应nui完成)⑨,voiceprint处理完配置后,通知voicesrv事件adaptivevpfinished(自适应vp完成)
8.2.在另一例中,语音应用发起一次voiceconfig①,比如进入地图导航应用,其中期望名人a优雅版音调,voicesrv接收到voiceconfig后,通过向configcenter发起setvoiceconfig②,configcenter根据当前tts引擎状态以及支持的声调信息,则会发起notifyvoiceconfig③,voicesrv分解voiceconfig,分别向tts发起notifyttsconfig(通知tts配置)
8.3.在特定应用场景下,语音应用发起一次voiceconfig①,比如进入比如全双工模式,voicesrv接收到voiceconfig后,通过向configcenter发起setvoiceconfig②,configcenter会根据系统状态处于在线状态,并且要求较高cloudasr和cloudnlu能力,并且往往一家厂商服务未必能满足实时的并行处理请求,configcenter则会发起notifyvoiceconfig③,voicesrv分解voiceconfig,则会发起notifyvoiceconfig③,voicesrv分解voiceconfig,分别向asr、nlu发起notifywakeupconfig④<比如激活全时唤醒能力>、notifyasrconfig⑥<比如选择支持asrproxy能力的云端asr厂商模块,并指定可在云端proxy的云端厂商服务地址信息,让其可根据asr提供的对话场景、适配选择对应的云端语音厂商>、notifynuiconfig⑧<比如无须使用本地nlu模块,只使用cloudnlu模块,并配置对应的asr厂商信息>,wakeup处理完配置后,通知voicesrv事件adaptivewakeupfinished⑤,asr处理完配置后,通知voicesrv事件adaptiveasrfinished⑦,nlu处理完配置后,通知voicesrv事件adaptivenuifinished⑨。
此外,根据本发明的方法还可以实现为一种计算机程序或计算机程序产品,该计算机程序或计算机程序产品包括用于执行本发明的上述方法中限定的上述各步骤的计算机程序代码指令。
或者,本发明还可以实施为一种非暂时性机器可读存储介质(或计算机可读存储介质、或机器可读存储介质),其上存储有可执行代码(或计算机程序、或计算机指令代码),当所述可执行代码(或计算机程序、或计算机指令代码)被电子设备(或计算设备、服务器等)的处理器执行时,使所述处理器执行根据本发明的上述方法的各个步骤。
本领域技术人员还将明白的是,结合这里的公开所描述的各种示例性逻辑块、模块、电路和算法步骤可以被实现为电子硬件、计算机软件或两者的组合。
附图中的流程图和框图显示了根据本发明的多个实施例的系统和方法的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标记的功能也可以以不同于附图中所标记的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
起点商标作为专业知识产权交易平台,可以帮助大家解决很多问题,如果大家想要了解更多知产交易信息请点击 【在线咨询】或添加微信 【19522093243】 与客服一对一沟通,为大家解决相关问题。
与客服一对一沟通,为大家解决相关问题。
此文章来源于网络,如有侵权,请联系删除

 热门咨询
热门咨询



